APIキーを入手する
Voice Text Web APIのページの無料利用登録をクリックし、メールアドレスなどを入力して、APIキーを入手します。
動かしてみる
コマンドライン上で動かします。Ubuntuの場合、最初にcurlがインストールされていないので、インストイールします。
sudo apt-get -y install curl
curlがインストールできると、実際に動かしてみます。
任意のディレクトリに移動し、curlコマンドで通信します。音声合成エンジンとして、ヒカリを選択しました。
curl "https://api.voicetext.jp/v1/tts" -o "test.wav" -u "上記で入手したAPIキー:" -d "text=ホヤ、ボイステキストの実験です。" -d "speaker=hikari"
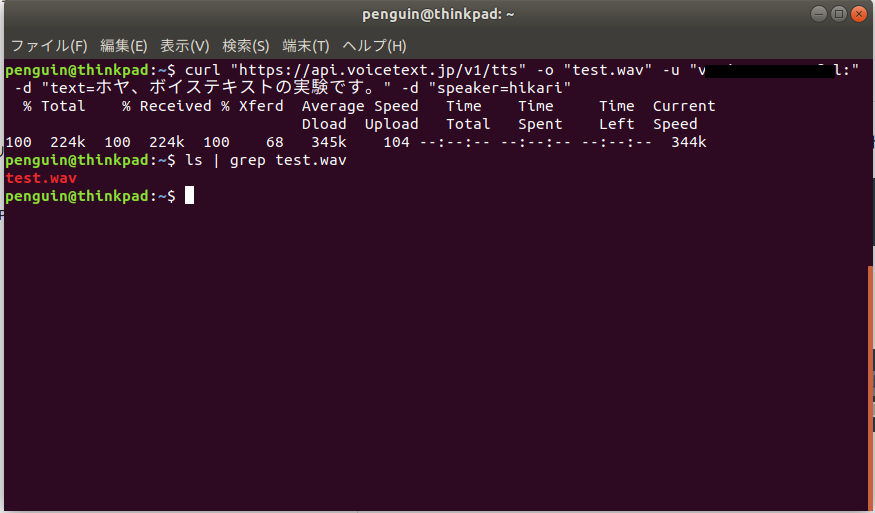
実行すると、wavファイルがダウンロードされたことがわかります。
Webアプリの作成
便利に音声合成を行うために、Webアプリを作ります。Pythonを使用して、サーバーと通信を行います。ブラウザ上で操作しやすいように、Flaskを使用して、Webアプリ化します。
Python3用のpipをインストール
Ubuntuでは、Python3-pipがインストールされていないので、インストールします。
sudo apt-get -y install python3-pip
Flaskのインストール
pip3 install flask
HTMLの作成
表面となるHTMLを作成します。最初に表示去れるindex.htmlと音声合成の結果を表示するresult.htmlを作成します。
index.html
<body>
<h1>Voice Text音声合成</h1>
<div id="index-form">
<form action="/" method="POST">
<div>
<span>APIキー:</span>
<span><input type="text" name="apiKey" class="input-box"></span>
</div>
<div>
<span>テキスト:</span>
<span><input type="text" name="setText" class="input-box" id="text"></span>
</div>
<div>
<span>音声エンジン:</span>
<select name="setVoice" id="voice">
<option value="null" disabled selected>選択して下さい</option>
<option value="show">ショウ</option>
<option value="haruka">ハルカ</option>
<option value="hikari">ヒカリ</option>
<option value="takeru">タケル</option>
<option value="santa">サンタ</option>
<option value="bear">クマ</option>
</select>
</div>
<div>
<span>感情 ※ショウ以外に設定できます:</span>
<select name="setEmotion" id="emotion">
<option value="null" disabled selected>選択して下さい</option>
<option value="happiness">喜</option>
<option value="anger">怒</option>
<option value="sadness">悲</option>
</select>
</div>
<div>
<span>感情レベル:</span>
<span>
<input type="range" name="setEmotionLevel" value="2" min="1" max="4" step="1" oninput="document.getElementById('feedbackEmotionLevel').value=this.value">
<output id="feedbackEmotionLevel">2</output>
</span>
</div>
<div>
<span>ピッチ:</span>
<span>
<input type="range" name="setPitch" value="100" min="50" max="200" step="1" oninput="document.getElementById('feedbackPitch').value=this.value">
<output id="feedbackPitch">100</output>
</span>
</div>
<div>
<span>スピード:</span>
<span>
<input type="range" name="setSpeed" value="100" min="50" max="400" step="1" oninput="document.getElementById('feedbackSpeed').value=this.value">
<output id="feedbackSpeed">100</output>
</span>
</div>
<div>
<span>ボリューム:</span>
<span>
<input type="range" name="setVolume" value="100" min="50" max="200" step="1" oninput="document.getElementById('feedbackVolume').value=this.value">
<output id="feedbackVolume">100</output>
</span>
</div>
<div id="sendBtn">
<input type="submit" value="送信" id="send">
</div>
</form>
</div>
</body>
result.html
<body>
<h1>Voice Text音声合成</h1>
<div id="result">
<audio src="../static/result/result.wav" controls></audio>
</div>
<p id="back"><a href="./">戻る</a></p>
</body>
バックグラウンド側の作成
index.py
from flask import Flask, render_template, request
import sys
import SpeechSynthesis
app = Flask(__name__)
@app.route("/")
def index():
return render_template("index.html")
@app.route('/', methods=['POST'])
def post():
key = request.form['apiKey']
text = request.form['setText']
voice = request.form['setVoice']
emotion = request.form['setEmotion']
emotion_level = request.form['setEmotionLevel']
pitch = request.form['setPitch']
speed = request.form['setSpeed']
volume = request.form['setVolume']
speechSynthesis = SpeechSynthesis.SpeechSynthesis(key, text, voice, emotion, emotion_level, pitch, speed, volume)
speechSynthesis.getVoice()
return render_template('result.html')
if __name__ == "__main__":
app.run(host="0.0.0.0", debug=True)
SpeechSynthesis.py
import sys
import requests
class SpeechSynthesis():
def __init__(self, key, text, voice, emotion, emotion_level, pitch, speed, volume):
self.key = key
self.text = text
self.voice = voice
self.emotion = emotion
self.emotion_level = emotion_level
self.pitch = pitch
self.speed = speed
self.volume = volume
def getVoice(self):
adress = 'https://api.voicetext.jp/v1/tts'
Parameters = {
'text': self.text,
'speaker': self.voice,
'emotion': self.emotion,
'emotion_level': self.emotion_level,
'pitch': self.pitch,
'speed': self.speed,
'volume': self.volume
}
send = requests.post(adress, params = Parameters, auth = (self.key,''))
result = open("static/result/result.wav", 'wb')
result.write(send.content)
result.close()
実行
上記で作成したindex.pyを実行します。
python3 index.py
ブラウザに127.0.0.1:5000を入力します。APIキー、喋らせたいテキスト、音声合成エンジンを選択し、送信をクリックすると、音声が帰ってきます。


プログラム
GitHubからプログラムをダウンロードできます。
おわりに
Voice Textのパラメータには、感情やピッチ、スピードが選択できるので、調整次第では、自然な喋り方にできるのではないかと思います。喋らせられる文字数が200字以内と制約がありますが、無料で利用できるので、十分だと思います。