![[導入初心者向け] Windows10へ無料提供! 定型作業を自動化しましょう。のコピー (1).png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F140547%2F8cd780f4-2d7e-dc58-554a-87fccef171ef.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=0bc4f20bb2289d7789998c4975a3ff77)
今回は、オフィスの業務課題を想定して、Power Automate for desktop(RPA)で、月末営業から届く大量の請求書(PDF)の内容をOCRを使って文字認識させて、エクセルに転機して売上一覧を作成することを自動化します。
この自動化は、PDFから取得する文字の位置が違うとデータが取れませんので、レイアウトが基本同じであることが条件です。よくあるのは、合計金額を表示する位置が、見積もりの項目数により位置が変わる場合などは取得が難しいです。
Power Automate for desktopはWindows10や11に無償で提供されていますが、時間で定期的に起動したり、何かをきっかけにして作業が始まるような場合には、有償のプランが必要になりますのでご注意ください。
それでは、初めてみましょう!
まずはOCRをインストール!
PCにより環境が違いますが、基本的に今回Power Automate for desktopで使用する、OCRの機能はTesseract
(テッセラクト)光学式文字認識エンジンを利用します。
日本語を認識するためには、日本語の学習データが必要です。
下記のリンク先に移動して、どちらかのインストラーをダウンロードしてください。
https://github.com/UB-Mannheim/tesseract/wiki/
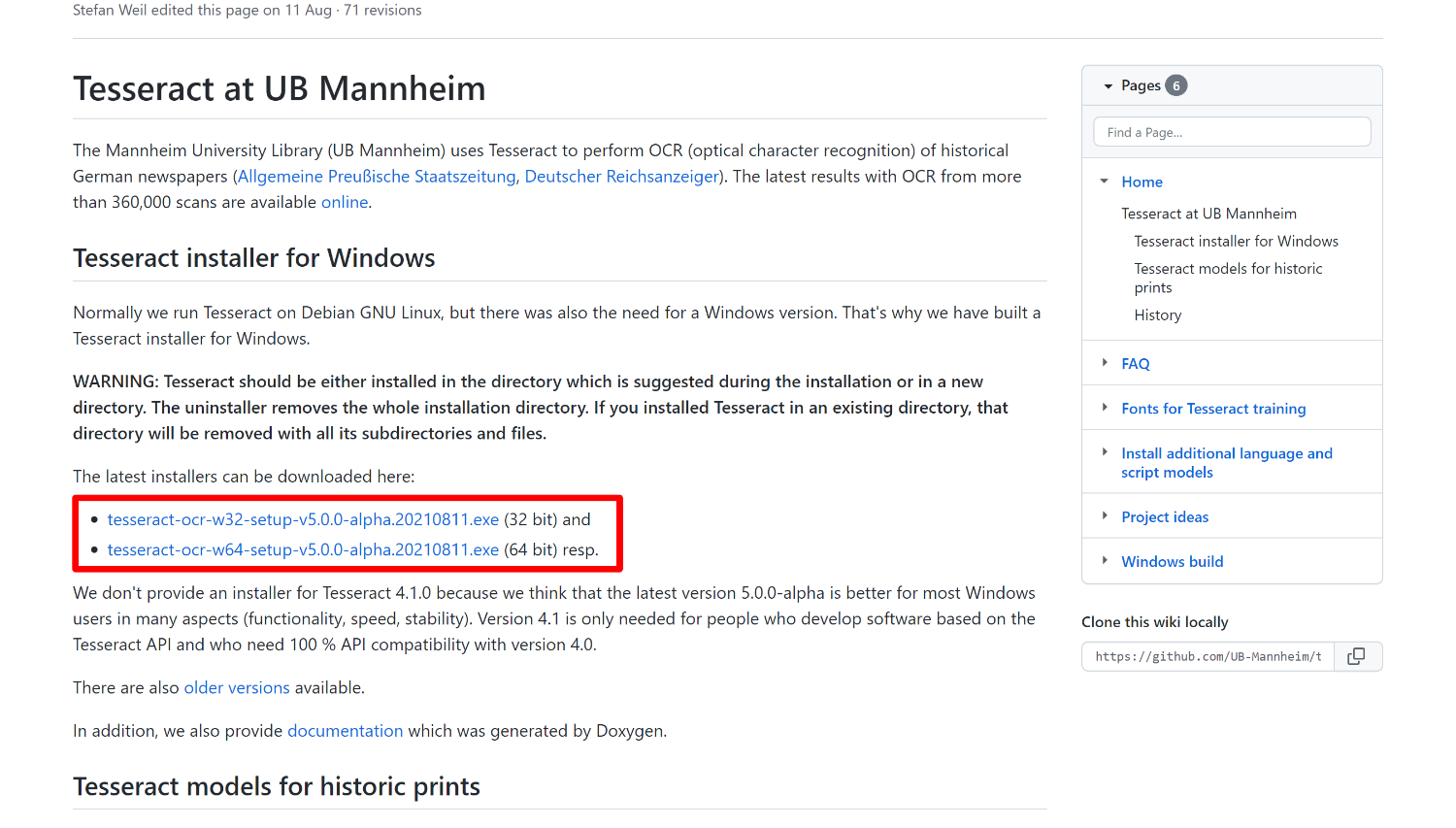
ダウンロードしたインストーラーをクリックして起動。デフォルトのままインストールを進めます。

インストールの変更点は、追加コンポーネントのインストールで
- Addtional script data
- Addtional language data
この2点にチェックを入れてインストールしてください。

インストールが完了するまで、少しお待ち下さい。
作成するデスクトップフローの全体像把握
初めに作成するフローの全体像を説明します。
大まかな流れとしては、フォルダに保存した請求書のPDFファイルを開き、指定した箇所の文字認識を行いテキストを抽出。雛形のエクセルファイルを開いて転記します。

■転記するエクセルファイルの雛形

今回は、取込日時、見積番号、件名、金額、クライアント名、見積日をPDFから取り込んでいます。
Power Automate for desktopの設定
Power Automate for desktopを起動します。
新しいフローを作成
画面左上の「新しいフロー」を選んで、新規に作成をおこないます。

名前を「請求書をOCRでエクセルへ変換」として、「作成」ボタンを押してください。

1.Excelの起動

※ドキュメントパスは、雛形として利用するエクセルファイルです。
2.Excelワークシートから最初の空の列や行を取得
書き込むエクセルファイルの内容を調べて、初めの空の列や行などを調べてくれます。

3.フォルダ内のファイルを取得

フォルダ:請求書を保存したフォルダを指定します。
ファイルフィルタ:対象にするファイルの拡張子などを指定します。
4.現在の日時を取得します
後でファイル名に使用するために、現在の日時を取得します。

5.変数の設定
Power Automate for desktopをアップデートしたら「Set variable」になりましたが、「変数の設定」です。
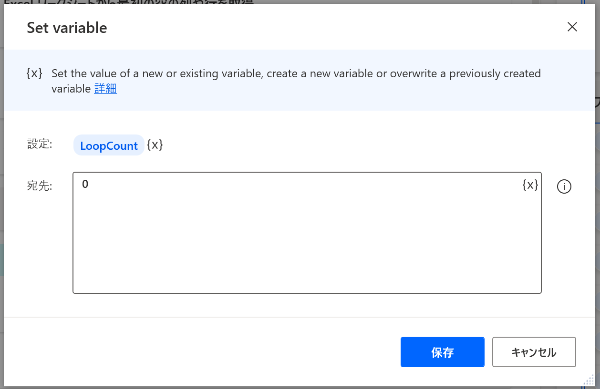
OCRで指定した箇所を取り出したり、エクセルに書き込んだりするのに、ループをおこないます。そのループした回数をカウントするのに、変数を作成します。
設定:NewVarとなっている変数名をLoopCountに変更
宛先:0 ※宛先は初めに変数に入れる値です。
6.For each
For eachを利用して、取得したファイル数分、反復処理(ループ)をおこないます。

入力ボックスの最後にある[X]を押して、Filesを選んでください。
Filesには、「3.フォルダ内のファイルを取得」で取得したファイル数が記録されているので、反復処理をおこなう値に指定することにより、回数を指定することが出来ます。
7.アプリケーションの実行(For each内に設置)
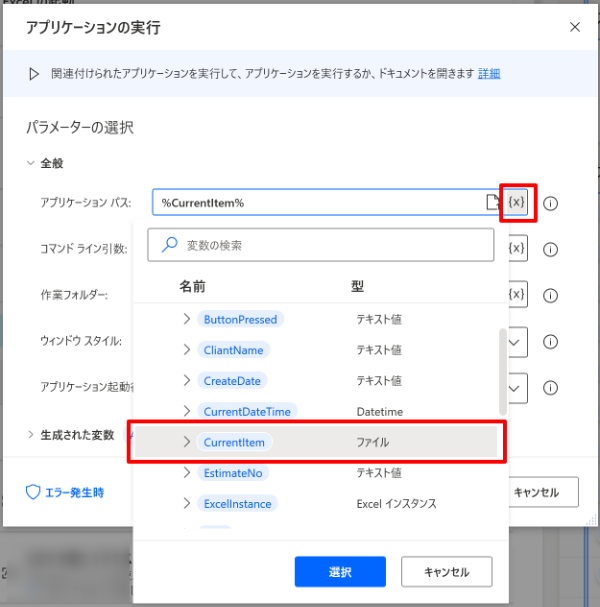
フォルダに保存した請求書のPDFファイルを開くために、「アプリケーションの実行」を使います。
アプリケーションパスの入力ボックスの最後にある[X]を押して、「CurrentItem」を選択します。
変数CurrentItemには、For eachで1回づつループする際に、変数Filesから取り出した請求書ファイルまでのパスが入っていますので、ループする毎にPDFファイルを一つ開くことが出来ます。
9-13.OCRを使ってテキストを抽出(For each内に設置)
※本来は「画像を待機」ですが、作成の都合上、先に「OCRをつかってテキスト抽出」を作成します。
PDFファイル内の文字をOCRで画像認識して取り出す設定をおこないます。
まず取り出す請求書のPDFファイルを1つ開いておきます。
Power Automate for desktopの画面にある「デスクトップデコーダー」ボタンを押し、表示されたウィンドウにある「画像記録」をオンにして、「レコード」ボタンをクリックします。
請求書のPDFファイルのウィンドウを選択して、請求書のどこでも良いので右クリックすると、「画像からテキストを抽出する」が表示されるので選択します。
「テキスト領域を指定する」になるので、請求書の読み込みたい文字部分を囲って選択します。
続いて「アンカー領域を定義する」に切り替わりますので、読み込んだ値が、後でわかるように、項目名が表示された部分を囲って選択します。
動画の説明がわかりやすいので、下記を参照してください。
■[日本語認識ついて] OCRで日本語部分を指定すると下記画像の様に文字化けすると思います。この時点では日本語の解析をおこなっていないので、値は気にしないで、そのまま進めてください。  今回は、見積番号、件名、金額、クライアント名、見積日をPDFファイルから取得しているので、この作業を4回繰り返していますが、ご自身で取り込みたい箇所は自由に設定してください。 作業中に誤って他のボタンを押してしまって記録される場合がありますが、ゴミ箱ボタンで削除してもらって構いません。
終わったら「終了」ボタンを押してください
フロー設定画面に戻ったら、取り込み指定した回数分の「OCRを使ってテキストを抽出」が出来ていると思います。For each内に設定しているか確認して、各項目を開いて、以下の様に設定します。
OCRソース:フォアグラウンドウィンドウ
■OCRエンジンの設定
他の言語を使う:オン
言語コード:jpn
言語データパス:C:\Program Files\Tesseract-OCR\tessdata
※インストール先を変更していなければここにあると思います。
■生成された変数
エクセルへ書き込む際に変数として利用します。
写真では顧客名を保存しているので「CliantName」としています。
取り込んだ内容に合わせて変数名は変更してください。

14-19.Excel ワークシートに書き出し(For each内に設置)
OCRで取り込みを行った値をエクセルに書き出ししていきます。
書き込む値:入力ボックスの最後にある[X]を押して、指定した変数名を選んでください。
私は、Excelテンプレートを下記の様に作成したので、
取込日時(%CurrentDateTime%)※「4.現在の日時を取得します」で取得した日時
見積番号(%EstimateNo%)
件名(%ProjectTitle%)
金額(%TotalPrice%)
クライアント名(%CliantName%)
見積日(%CreateDate%)
と指定していますので、6個の「Excel ワークシートに書き出し」を作成しています。
列:書き込む列を数字で指定します。
行:%FirstFreeRow + LoopCount%
「FirstFreeRow」は、「Excelワークシートから最初の空の列や行を取得」で保存した場所を指定しています。
「LoopCount」は、「変数を作成」で作成した反復処理を行う回数をカウントします。「FirstFreeRow + LoopCount」と指定していますので、反復処理が進むごとに、LoopCountが足されていく形になります。

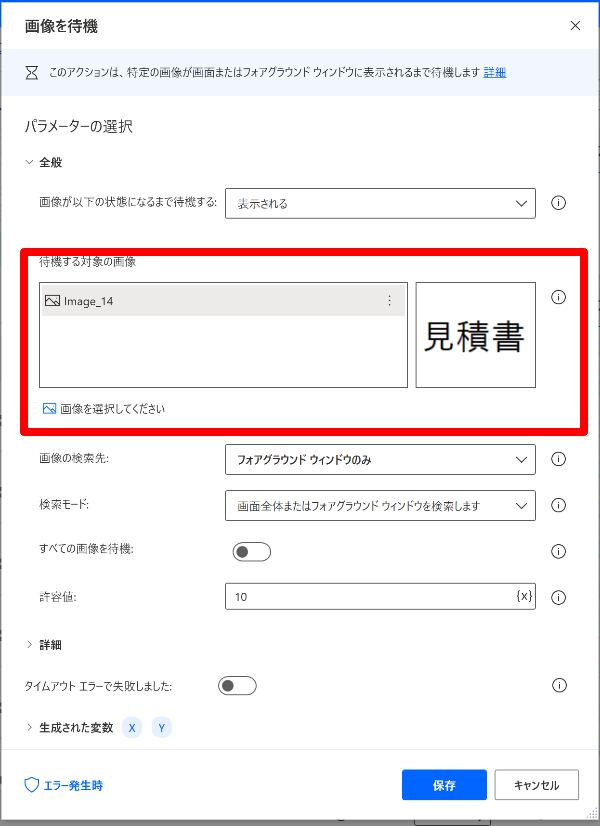
8.画像を待機(For each内に設置)
開発の順番を優先しましたので、ここで説明しますが、「7.アプリケーションの実行」の前に設置してください。
繰り返しPDFファイルを開くと、Power Automate Desktopの処理が早すぎて、エラーを起こしますので、フォアグラウンドに特定の画像が表示されるまで待機します。
指定する画像は、「画像を選択してください」から、前のセクションで「OCRを使ってテキストを抽出」のアンカーに指定した画像を指定してください。
20.変数を大きくする(For each内に設置)
反復処理(ループ)処理をするごとに、1づつ大きくして、回数をカウントします。
カウントする理由は、エクセルに書き込む時に1回目の列を書き込み終わったら、次の行に書き込む必要があるからです。
変数名:入力ボックスの最後にある[X]を押して、LoopCountを選んでください。
大きくする数値:1
21.プロセスを終了する(For each内に設置)
「7.アプリケーションの実行」で起動したPDFファイルを閉じるのに利用します。
プロセスの指定方法:プロセスID
プロセスID:入力ボックスの最後にある[X]を押して、AppProcessIdを選んでください。
ここでFor each(ループ)は終了です。
23.DateTimeをテキストに変換
エクセルを保存する為に、ファイル名に利用したいので日付を取得したものを、テキスト形式(2021年10月26日)に変換します。

24.エクセルを閉じる
開いたエクセルを閉じます。閉じる際に、別名で取り込みした日付をつけて保存します。
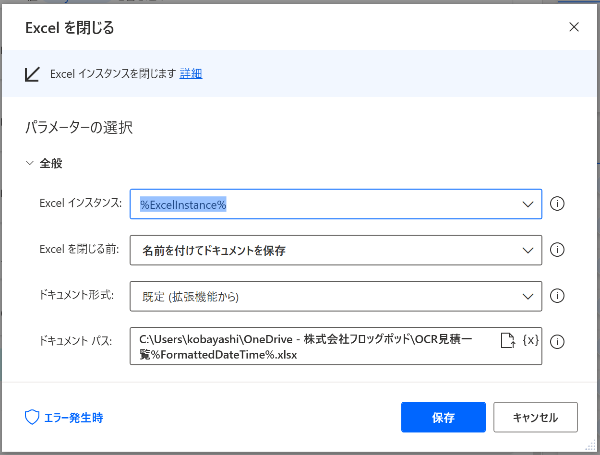
Excelを閉じる前:名前をつけてエクセルを保存
ドキュメントパス:保存する場所とファイル名を指定します。今回は取り込み日をファイル名につけたいので、「23.DateTimeをテキストに変換」で作った変数「FormattedDateTime」をファイル名に入れています。
C:\Users\kobayashi\OneDrive - 株式会社フロッグポッド\OCR見積一覧%FormattedDateTime%.xlsx
25.メッセージを表示
作業が完了した時にメッセージを表示します。
メッセージボックスのタイトル:終了
表示するメッセージ:作業完了です
メッセージボックスアイコン:情報
メッセージボックスを常に手前に表示する:オン
以上で設定は完了です。
再生ボタンでプレイバックしてみて、自動的に処理がされるか確認してみてください。
最後に
ブログの都合で、一気に作成方法を説明していますが、For eachの反復処理のところは、「25.メッセージを表示」の「表示するメッセージ」に、OCRで読み込んで保存した変数を表示させて、キチンと値を取れているのか、確認しながら作っていくと良いと思います。
少しでも皆さんのルーチンワークが解消されると嬉しいです。