この記事は Fujitsu Advent Calendar 2024 の 17日目 の記事です。
はじめに
OpenMP で GPU を動かす OpenMP Offload は日本語の解説記事が非常に少なく普及率も低いです。しかし、NVIDIA や AMD、Intel などの各社 GPU は OpenMP Offload を正式サポート1しているため、プログラムのポータビリティを考えると必要な技術だと思っています。
そのため、少しでも OpenMP Offload の普及に寄与すれば、という思いで本記事を書きます。
OpenMP Offload とは
OpenMP(Open Multi-Processing)は並列プログラミング向けのディレクティブベース API です。もともとは共有メモリ型マルチプロセッサ(主にマルチコア CPU)の並列処理を簡単に記述するために利用されていましたが、OpenMP 4.0 からデバイスへのオフロード(OpenMP Offload)もサポートしました2。この機能追加により、OpenMP だけで CPU と GPU 両方の並列計算を簡単かつポータビリティを保った記述ができるようになりました。
上述のようなメリットがある一方で、この記事の冒頭に書いたような使い方の説明や普及率に加えて性能に課題があります。性能に関しては基本的に各 GPU 向けの低レベル API(CUDA、HIP など)に軍配が上がりますが3、これは簡単に記述できることとのトレードオフなので仕方ない部分ではあります。そのため、まずは OpenMP Offload で GPU 向け並列化を記述し、それでも性能に満足できなければ CUDA や HIP で本格的に GPU カーネルを記述するなどの方針が良いと思います。
動作環境
以降で OpenMP Offload の記述の仕方や動作確認した結果を記載するので、それに利用した動作環境を以下に示します。記事を読んだ方が手軽に OpenMP Offload を試せるように、Windows の WSL2 からノート PC の Intel 内蔵 GPU を動かしてみました。ご興味がある方はお手元でも OpenMP Offload を試してみてください。
| 型番・バージョン | |
|---|---|
| CPU | Intel(R) Core(TM) i7-8550U CPU |
| GPU | Intel(R) UHD Graphics 620 |
| OS (host) | Windows 11 Home 23H2 |
| OS (WSL2) | Ubuntu 22.04 |
| Intel Graphics Driver | 第 7 世代から第 10 世代インテル® プロセッサー・グラフィックス - Windows ドライバー(31.0.101.2130) |
| Intel oneAPI Toolkit | latest |
WSL や Intel Graphics Driver、Intel oneAPI Toolkit のインストールは以下を参考に実施してください。
- WSL コマンドのインストール
-
インテル® グラフィックス用のドライバー一覧
- 動作環境に記載したドライバーはこれです
- Intel® oneAPI Toolkits Installation Guide for Linux* OS
Intel oneAPI Toolkit インストール後、以下を実行して icpx が使えることを確認してください。
$ source /opt/intel/oneapi/setvars.sh
:: initializing oneAPI environment ...
-bash: BASH_VERSION = 5.1.16(1)-release
args: Using "$@" for setvars.sh arguments:
:: advisor -- latest
:: ccl -- latest
:: compiler -- latest
:: dal -- latest
:: debugger -- latest
:: dev-utilities -- latest
:: dnnl -- latest
:: dpcpp-ct -- latest
:: dpl -- latest
:: ipp -- latest
:: ippcp -- latest
:: mkl -- latest
:: mpi -- latest
:: pti -- latest
:: tbb -- latest
:: umf -- latest
:: vtune -- latest
:: oneAPI environment initialized ::
$ icpx --version
Intel(R) oneAPI DPC++/C++ Compiler 2025.0.1 (2025.0.1.20241113)
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /opt/intel/oneapi/compiler/2025.0/bin/compiler
Configuration file: /opt/intel/oneapi/compiler/2025.0/bin/compiler/../icpx.cfg
以下のようなエラーが出る場合は Intel Graphics Driver を再インストールしてみてください。
$ clinfo
Abort was called at 56 line in file:
./shared/source/os_interface/windows/wddm/create_um_km_data_translator.cpp
Aborted (core dumped)
OpenMP Offload の使い方
必要最低限の使い方を説明するために、簡単な行列積のプログラムを使います4。
以下の通り、#pragma omp から始まる呪文を1行書くだけで OpenMP による GPU 実行ができます。
この呪文を解説します。
#include <iostream>
#include <omp.h>
int main() {
constexpr int N = 5e3;
double *A = new double[N*N];
double *B = new double[N*N];
double *C = new double[N*N];
#pragma omp target teams distribute parallel for map(to: A[0:N*N], B[0:N*N]) map(tofrom: C[0:N*N])
for (int i=0; i<N; i++) {
for (int j=0; j<N; j++) {
for (int k=0; k<N; k++) {
C[i*N+j] += A[i*N+k] * B[k*N+j];
}
}
}
std::cout << C[0] << std::endl;
delete [] A;
delete [] B;
delete [] C;
}
簡単のために、以下の説明では反復数 128 のループを対象に、4 つの計算ブロック、各ブロック内に 4 つのスレッドを持つ GPU を仮定します。
-
target構文- 以降の処理を GPU に移します
- 特に並列化されず、CPU で実行されていた処理が単に GPU で実行されます

-
teams構文- 直後のループが各ブロックに分散されず割り当てられます
- 各ブロックが同じデータに対して同じ処理をしている状態です

-
distribute構文- 直後のループが各ブロックに分散されて割り当てられます
- CPU で実行する OpenMP の
parallel forと同じ状態です

-
parallel for構文- 直後のループが各ブロック、スレッドに分散されて割り当てられます
- これで GPU リソースにちゃんと処理を割り当てることができます
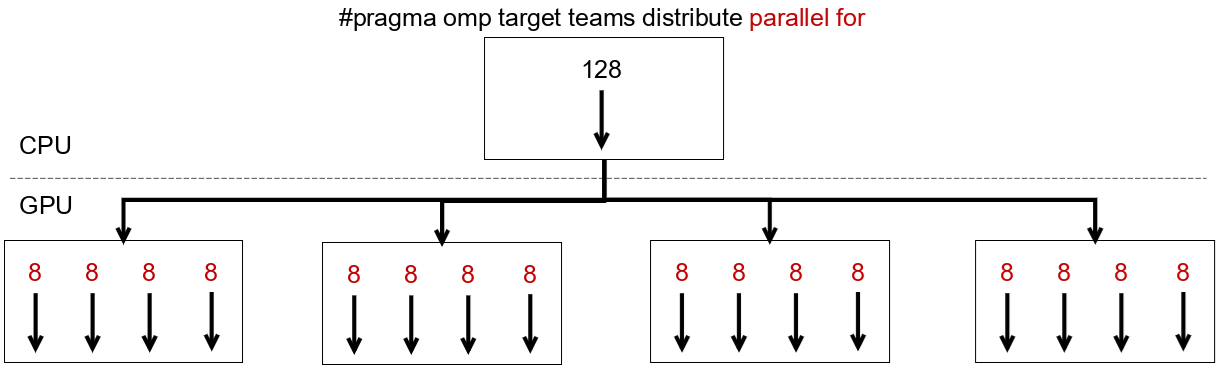
-
map(to: A[0:N*N], B[0:N*N])- CPU から GPU へのデータ転送する指示です
- CPU 側で設定したデータも引き継ぎます
- 配列は転送範囲を指定する必要があります
-
map(tofrom: C[0:N*N])- CPU から GPU へデータ転送し、GPU 処理後にデータを CPU に書き戻す指示です
- CPU から GPU へデータを転送する必要がなければ
map(from: C[0:N*N])で充分です
実行
以下のコマンドでプログラムをコンパイルします。
$ icpx -O3 -fiopenmp -fopenmp-targets=spir64 gemm.cpp -o run_gpu.out
これは icpx で Intel GPU 向けにコンパイルするときのオプション指定なので、他コンパイラや他 GPU 向けには適宜オプションの変更が必要です。
実行してタスクマネージャ-で GPU 使用率を確認すると、ちゃんと GPU が使われていることがわかります。実行時間ですが、ノート PC 内蔵 GPU を使っているのでそれなりにかかりますし、なんなら CPU 実行より遅いです。今回はまず OpenMP Offload を使ってみることが目的なので、そこはご愛嬌ということで...
$ ./run_gpu.out

さいごに
OpenMP Offload を簡単に紹介しました。そのうち続きも書こうと思います。
-
GPU 向けディレクティブ言語として有名な OpenACC は NVIDIA のみ正式サポートしています。 ↩
-
OpenMP 4.0 Complete Specifications に仕様が記述されています。 ↩
-
簡単なループであれば OpenMP Offload でも CUDA や HIP と同等の性能は出せますが、実アプリになるとやはり性能面では一歩か二歩劣るように見えています。 ↩
-
今回の説明に不要な処理は省いてます。初期値の設定とか。 ↩