2021.3.18 直接のdf作成・取得などを追記
直接df
df = pd.DataFrame({
"col1" : [1,2,3,4,5],
"col2" : [6,7,8,9,10],
"col3" : ["A","B","C","D","E"]
})

# 同じデータフレームをnumpyのarrayを使って作成
import numpy as np
array1 = np.array([1,2,3,4,5])
array2 = np.array([6,7,8,9,10])
df = pd.DataFrame({
"col1" : array1,
"col2" : array2,
"col3" : ["A","B","C","D","E"]
})
dictからdf
df = pd.DataFrame(dict_data.values(), index=dict_data.keys())
# 初期のcolumn名が0になるので変更
df = df.rename(columns={0:"count"})
名称変更
column名の変更(rename)
df = df.rename(columns={"before1":"after1","before2": "after2"})
取得
列名からデータを取得する
df.y
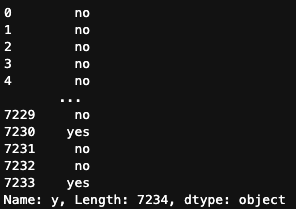
df["y"]

df[["y"]]

複数取得
行列で取得することになる
df[["column1","column2"]]

[ ]と型
df[ ]
type(df["y"])
# pandas.core.series.Series
df[[ ]]
type(df[["y"]])
# pandas.core.frame.DataFrame
seriesで取得しておくとnumpyのarrayと同様に扱うことができる。
seriesをnp.arrayに変換する
import numpy as np
np.array(df.column1)
# .values としても変換可能
df.column1.values
行の取得
query関数を使う。
# 0行目を取得
df.query("index == 0")
# query で条件を指定して抽出
df.query("category2 == 'married'")
# queryでorで条件指定して抽出
df.query("category2 == 'married'| category2 == 'single'")
# query関数でandで条件指定して抽出
df.query("category2 == 'married'& y == 'yes'")
# 行に条件付与した上で抽出列を指定
df.query("category2 == 'married'")[["column2","y"]]
削除
欠損値を含む行の削除(dropna)
# category1、category3 に欠損値を含む行を削除
df = df.dropna(subset=['category1','category3'])
列の欠損数を指定して削除(dropna)
# 欠損数が2400個以上のcolumnを除外
df = df.dropna(thresh=2400, axis=1)
列(columns)の削除(drop)
df = df.drop(columns="column5")
補完
カテゴリーデータの補完(fillna)
# 欠損値を「unknown」で置換
df = df.fillna({'category1':'unknown'})
# 欠損値を最頻のカテゴリーで補完
df['category1'] = df['category1'].fillna(df['category1'].mode()[0])
# 2番目に頻出で埋めたい場合があれば .mode()[1]
量的変数の補完(fillna)
# 平均値で埋める
df['column1'] = df['column1'].fillna(df['column1'].mean())
除外
# column1について 18以下、100以上を外れ値としたい。
# dfのcolumn1 18以上を抽出
df = df[df["column1"] >= 18]
# dfのcolumn1 100以下を抽出
df = df[df["column1"] <= 100]
# 絞り込むことで除外を実現する
# df[抽出条件]
データ変換
条件置換(where)
df = pd.DataFrame({
"col1" : [1,2,3,4,5],
"col2" : [6,7,8,9,10],
"col3" : [0,20,50,0,0]
})
df
# col3に対して 0以外を1にしたい
# Trueは放置、Falseに対して指定の置換
df["col3"] = df['col3'].where(df['col3'] == 0, 1)
df
2値分類の変換(replace)
# 本当に2値分類か確認
print(df["category5"].value_counts(ascending=False, normalize=False))
# 特定の列に対して、2値(yes/no)の変換
df["category5"] = df["category5"].replace("yes",1)
df["category5"] = df["category5"].replace("no",0)
# yes/no 項目が複数なら一括変換も可能
df = df.replace("yes", 1)
df = df.replace("no", 0)
多値分類の変換(pd.get_dummies)
# 本当に多値分類か確認
print(df["category2"].value_counts(ascending=False, normalize=False))
# dummy変数を使って変換する
df_category2 = pd.get_dummies(df['category2'])
# 先頭から5行目まで表示
df_category2.head()
# category2 1列 から vfalue_countsの数分の列が作成される

変換後に結合が必要になる。
結合(concat)
column1~3,category5 + category2(dummy) + y
# column1,column2,column3,category5を抽出
tmp1 = df[["column1","column2","column3","category5"]]
# category2のダミー変数変換
df_category2 = pd.get_dummies(df['category2'])
# 結合
# new_df = column1~3,category5 + category2
new_df = pd.concat([tmp1, df_category2],axis=1)
# 右端にyを結合
new_df = pd.concat([new_df, df[["y"]]],axis=1)
書き出し
# 新しいdfをCSVファイルで出力
new_df.to_csv('file_name.csv', index=False)
カウント(value_counts)
# category2の値の比率を計算
df['category2'].value_counts(ascending=False, normalize=True)
# ascending ascending True:昇順 / False:降順
# normalize True:割合 / False:頻度
並び替え(sort_values)
df = df.sort_values("category2", ascending = False)
# ascending ascending True:昇順 / False:降順
量的データでもカテゴリーデータでも並び替えは可能
転置(.T)
df.T
クロステーブル
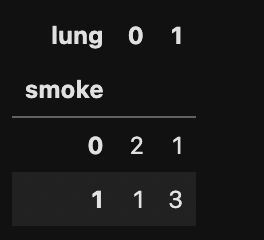
その1
df = pd.DataFrame({
"smoke" : [0,0,0,1,1,1,1],
"lung" : [0,0,1,0,1,1,1],
})
df

pd.crosstab(df['smoke'], df['lung'])
その2
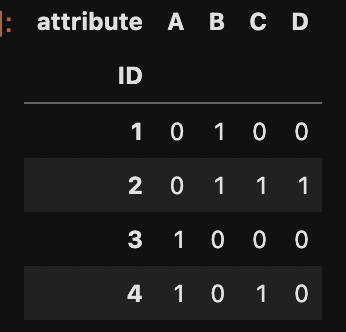
IDに対して重複なしで複数属性持つ時にはダミー変換も兼ねた使い方ができる
df = pd.DataFrame({
"ID" : [1,2,2,2,3,4,4],
"attribute" : ["B","C","D","B","A","A","C"],
})
df

pd.crosstab(df['ID'], df['attribute'])