matplotlibで模擬試験の5教科・合計点の記録から、ヒストグラムを作りました。
・matplotib
・ヒストグラム(plt.hist)
・for文でグラフ出力
・patchesでヒストグラムの棒に対する色分け
模擬試験のヒストグラム
・対象は国語、数学、英語、社会、理科、合計点。
・国語、数学、英語、社会、理科は各100点満点
・csv https://drive.google.com/file/d/1EzctLYN5-UvkmkOgZ7usPgtsQn7bdq5y/view?usp=sharing
・合計点は500点満点

ライブラリを積み込んで
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
データフレームを作る。1~6列目にnameを与える。
(csvはpythonの.ipynbと同じディレクトリにあれば「〜〜〜.csv」でいけます。)
df = pd.read_csv("honmachi.csv", names=['国語','数学','英語','社会','理科','合計'])
格納状況を確認。(これで先頭の行が見れる。)
df.head()
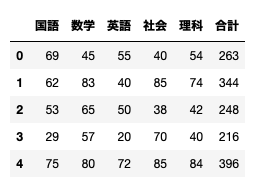
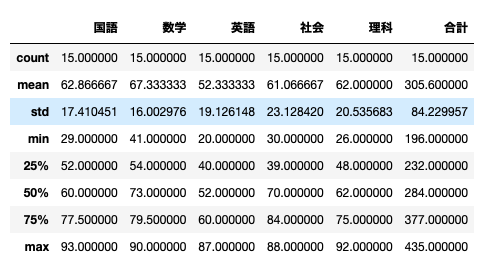
今回は分析するわけではないが、describe()で全体像も。
df.describe()
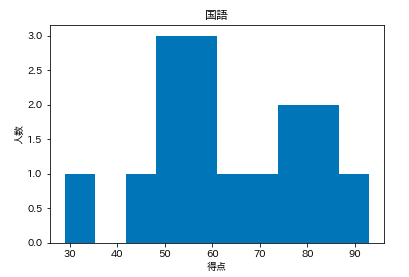
matplotlibに、まずはデフォルトで df['国語'] のヒストグラムを書いてもらいます。
plt.hist(df['国語'])
plt.title('国語')
plt.xlabel('得点')
plt.ylabel('人数')
plt.show()
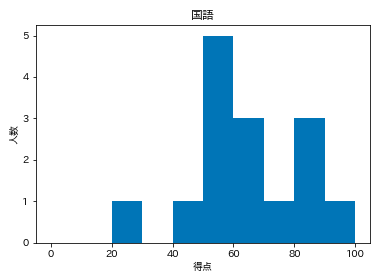
デフォルトだと微妙。
テストの点数という性質上
・0~100点の範囲 range=(0, 100)
・棒が10本 bins=10
くらいが見やすいか。
というわけで、rangeとbinsをmatplotlibのhistの()の中に注文する。
# hist()内に追加
plt.hist(df['国語'], range=(0,100), bins=10,)
plt.title('国語')
plt.xlabel('得点')
plt.ylabel('人数')
plt.show()
次は軸。
・x軸
0~100なので plt.xlim(0, 100)
・y軸
科目によって高さが揺らぐと比較し辛い。
今回は15人分なので、とりあえず8人で **plt.ylim(0,8)**とします。
ここで指定しておけば、8人オーバーした際も、ここで調節可能。
plt.hist(df['国語'], range=(0,100), bins=10,)
# ここに追加
plt.xlim(0,100)
plt.ylim(0,8)
plt.title('国語')
plt.xlabel('得点')
plt.ylabel('人数')
plt.show()
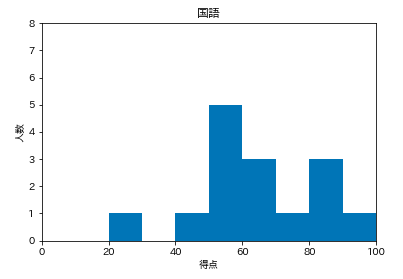
原型はこんな感じにします。
少し細かいデザインを調整します。
1.目盛りを読むグリッド線が欲しい
2.点数が半分以下の色を変えてみる
1.人数に横線を引く。
plt.grid(True)
plt.hist(df['国語'], range=(0,100), bins=10)
plt.xlim(0,100)
plt.ylim(0,8)
# 追加
plt.grid(True)
plt.title('国語')
plt.xlabel('得点')
plt.ylabel('人数')
plt.show()
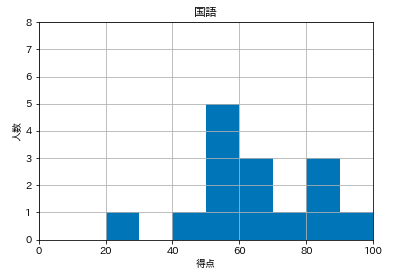
2.点数が半分以下の色を変える。
手こずりました。
plt.hist()の中で
if(49点以下):
range=(0,50), bins=5
else(50点以上):
range=(51,100), bins=5
で色分けを考えるも、ハードそう。
データフレームの各科目に対して毎回50点以下と50点以上に分割し直すようなこともできるでしょうか。
ただ、今回は性質上、綺麗に固定の棒が生えるので、棒に対して色分けできないか。
つまり、棒に対して、1~5本目を赤くしたい。
ここでは、histにある戻り値を使いました。
参考
n, bins, patches = hist(○○)
n :Y軸の値のデータ
bins :X軸の値のデータ
patches :patchのリスト
(patch = ヒストグラムの各棒のオブジェクト)
このpatchの1〜5本目に対して色分けがしたい。
# 1本目のpatch(棒)を対象にして、facecolor(棒の色)にredをset(塗る)
patches[0].set_facecolor('red')
これを1本目から5本目まで繰り返せばいいのでfor文を使いました。
for i in range(0, 5):
patches[i].set_facecolor('red')
これで色分けの準備が完了したので、このfor文を追記します。
plt.hist(df['国語'], range=(0,100), bins=10)
plt.xlim(0,100)
plt.ylim(0,8)
plt.grid(True)
plt.title('国語')
plt.xlabel('得点')
plt.ylabel('人数')
# 追記
for i in range(0, 5):
patches[i].set_facecolor('red')
plt.show()

patches が定義されていないと出てしまいます。
どこかにpathchesを置く必要があるのか?
先ほどのを拝借して
n, bins, patches = hist( ) を付けたら上手くいきました。
# ここに追加
n, bins, patches = plt.hist(df['国語'], range=(0,100), bins=10)
plt.xlim(0,100)
plt.ylim(0,8)
plt.grid(True)
plt.title('国語')
plt.xlabel('得点')
plt.ylabel('人数')
for i in range(0, 5):
patches[i].set_facecolor('red')
plt.show()
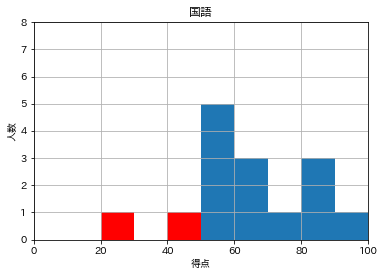
完成。
血のような赤というのも縁起が悪いので、透明度(alpha)を調整します。alpha=0.5
これはhist()の中に追加で注文しておきます。
# hist()の中にalphaも追加
n, bins, patches = plt.hist(df['国語'], range=(0,100), bins=10, alpha=0.5)
plt.xlim(0,100)
plt.ylim(0,8)
plt.grid(True)
plt.title('国語')
plt.xlabel('得点')
plt.ylabel('人数')
for i in range(0, 5):
patches[i].set_facecolor('red')
plt.show()
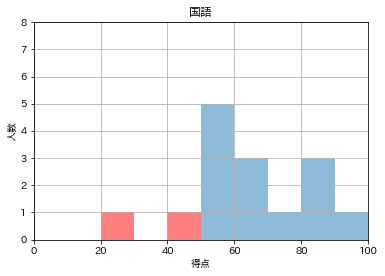
あとはfor文で一気に回します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("honmachi.csv", names=['国語','数学','英語','社会','理科','合計'])
# subject という変数を設定して、1科目ずつ処理していきます。
for subject in ['国語','数学','英語','社会','理科']:
# df[ ]の中身はsubjectに合わせて変わるようにしています。
n, bins, patches = plt.hist(df[subject], range=(0,100), bins=10, alpha=0.5)
plt.xlim(0,100)
plt.ylim(0,8)
plt.grid(True)
# title( ) の中身もsubjectになっているとタイトルラベルも自動で変わります。
plt.title(subject)
plt.xlabel('得点')
plt.ylabel('人数')
for i in range(0, 5):
patches[i].set_facecolor('red')
plt.show()
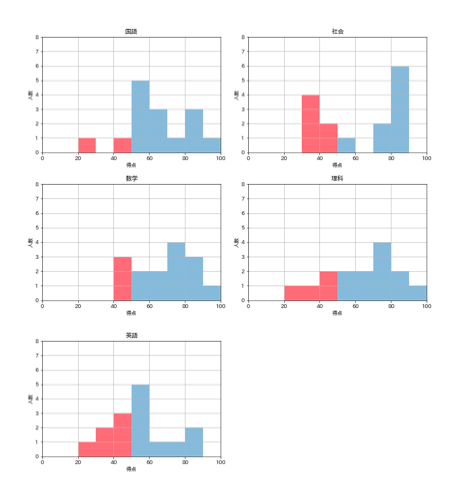
これで5枚一気に出てこれました。
これで残りは、合計得点。500点満点にするだけです。
データフレームの合計を拾って
・range=(0,500)
・plt.xlim(0,500)
に変更して終わりです。
最後に、注釈なしで今回の要件で使ったコードをまとめて置いておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("honmachi.csv", names=['国語','数学','英語','社会','理科','合計'])
for subject in ['国語','数学','英語','社会','理科']:
n, bins, patches = plt.hist(df[subject], range=(0,100), bins=10, alpha=0.5)
plt.xlim(0,100)
plt.ylim(0,8)
plt.grid(True)
plt.title(subject)
plt.xlabel('得点')
plt.ylabel('人数')
for i in range(0, 5):
patches[i].set_facecolor('red')
plt.show()
n, bins, patches = plt.hist(df['合計'], range=(0,500), bins=10, alpha=0.5)
plt.xlim(0,500)
plt.ylim(0,8)
plt.grid(True)
plt.title('合計')
plt.xlabel('得点')
plt.ylabel('人数')
for i in range(0, 5):
patches[i].set_facecolor('red')
plt.show()
pythonでから出力するだけならば、これで問題なさそうですが、現実的に使ってもらうとなると、ユニバーサルなものにするにはネットワークで動く、最終的な実装の仕組みに出来ないとなと思いました。