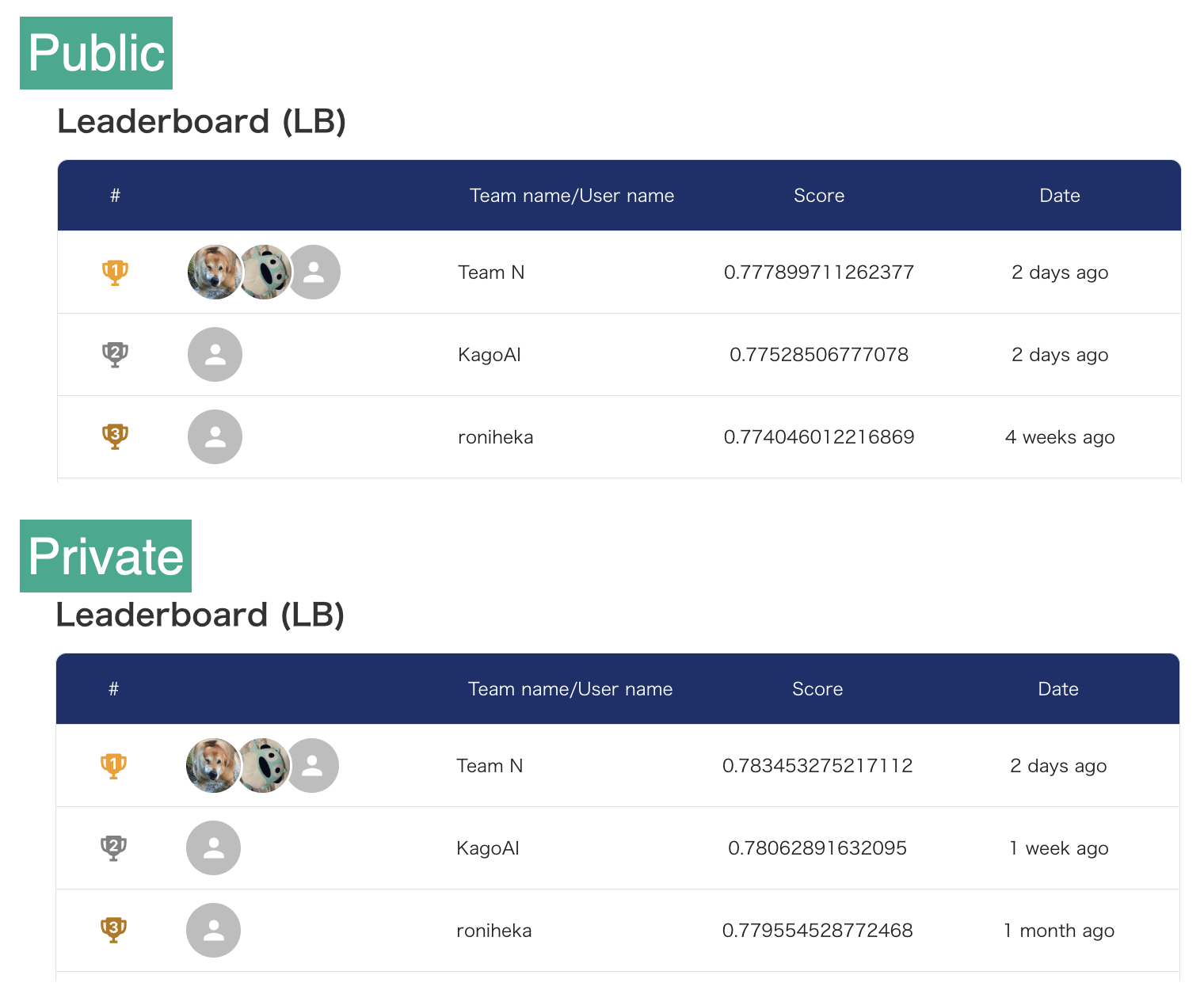
solafune 5x Super-resolution
solafuneの衛星画像の5倍超解像度化のコンペに参加しました。
private 2nd - KagoAIのsolution。modelはRCAN。
名前変えられなくなりました...。
outline
MODEL : RCAN
CV : 5fold
BATCH_SIZE : 4
Augmentation :
1 ~ 200epoch - Hflip,Vflip,Rotate,ChannelShuffle,ColorJitter
201 ~ 400epoch - Hflip,Vflip,Rotate
SCHEDULER :
1 ~ 200epoch - TanhLRScheduler(WarmUp)
201 ~ 400epoch - CosineAnealing
OPTIMIZER : MADGRAD
TTA : Vflip+Hflip+rotate 8pattern
Data : only given tiff images
RCAN
RCAN(Residual Channel Attention Networks - 2018)
RCAN(pretrained) - torchSR
Change from torchSR : replaced x4scaling(default) with x5scaling
other
x4scaleup -> x5scaleup
torchsrのRCANは4倍SRがデフォルトなので、5倍SRするように書き換えます。
torchsrのRACNで4倍を担当している部分は
import torch
import torch.nn as nn
import torchsr
import math
net = torchsr.models.rcan(scale=4, pretrained=True)
print(net.tail)
Sequential(
(0): Upsampler(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): PixelShuffle(upscale_factor=2)
(2): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): PixelShuffle(upscale_factor=2)
)
(1): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
ここだけ取ってきて、(B,C,H,W)を入れれば
net_ = net.tail
sample_ = torch.rand(1,64,130,130)
print(f"input : {sample_.shape}")
output = net_(sample_)
print(f"output : {output.shape}")
input : torch.Size([1, 64, 130, 130])
output : torch.Size([1, 3, 520, 520])
ここが4倍scaleupを担当。
convとPixelShuffleだけなので
input:(B,64,130,130) → (B,256,130,130) → (B,256/2**2,130*2,130*2)
→ (B,64,260,260) → (B,256,260,260) → (B,64,520,520) → output:(B,3,520,520)
5倍scaleupは
PixelShuffleを2回引き継ぐように考え、以下のように実現することにしました。
(B,64,130,130) → (B,256,130,130) → (B,256/2**2,130*2,130*2)
→ (B,64,260,260) → (B,64,325,325)→ (B,256,325,325)→ (B,64,650,650) → output:(B,3,650,650)
Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): PixelShuffle(upscale_factor=2)
(2): AdaptiveAvgPool2d(output_size=(325, 325))
(3): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): PixelShuffle(upscale_factor=2)
(5): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
妥当性は不明ですが、こんな流れでとりあえず5倍SRは実現できそうです。
PixelShuffleは同じ位置で2回使いたいので、(B,64,260,260) → (B,64,325,325) というupsampleを途中に挟んでいます。AdaptiveAvgPoolingで無理やり広げてます。
強引に拡張する方法として、
3つを試して、AdaptiveAvgPoolingでの拡張が精度が良かったのでこれを採用しました。
短絡的ですが、とりあえず5倍はこれで実現できます。
これを踏まえて、RCANをまとめて書き直すと以下の通りです。
(もっとスマートな書き方があると思います...)
def RCAN_():
net = torchsr.models.rcan(scale=4, pretrained=True)
### x4 -> x5
m = list()
conv1 = nn.Conv2d(in_channels=64, out_channels=256, kernel_size=3, stride=1, padding=1, bias=False)
ps1 = nn.PixelShuffle(2)
aap = nn.AdaptiveAvgPool2d((325,325))
conv2 = nn.Conv2d(in_channels=64, out_channels=256, kernel_size=3, stride=1, padding=1, bias=False)
ps2 = nn.PixelShuffle(2)
conv_last = nn.Conv2d(in_channels=64, out_channels=3, kernel_size=3, stride=1, padding=1, bias=False)
m.append(conv1)
m.append(ps1)
m.append(aap)
m.append(conv2)
m.append(ps2)
m.append(conv_last)
tail_re = nn.Sequential(*m)
for m in tail_re.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
net.tail = tail_re ### 付け替え
return net
net = RCAN_()
sample_ = torch.rand(1,3,130,130)
print(f"input : {sample_.shape}")
output = net(sample_)
print(f"output : {output.shape}")
input : torch.Size([1, 3, 130, 130])
output : torch.Size([1, 3, 650, 650])
SSIM:torchmetric
SR前の画像とSR後の画像をMSEで比較するなら、
criterion = nn.MSELoss()
net.train()
for low_imgs, high_imgs in tqdm(train_dataloader):
optimizer.zero_grad()
outputs = net(low_imgs)
train_loss = criterion(outputs, high_imgs)
train_loss.backward()
optimizer.step()
今回はSSIMで評価されるので、torchmetricsのSSIMでlossを計上して、SSIMを使ってパラメータ更新をするようにします。
from torchmetrics import StructuralSimilarityIndexMeasure # ssim
ssim = StructuralSimilarityIndexMeasure(data_range=1.0).to(device)
net.train()
for low_imgs, high_imgs in tqdm(train_dataloader):
ssim.reset() # torch metrics
optimizer.zero_grad()
outputs = net(low_imgs)
loss = 1 - ssim(outputs, high_imgs) # criterion with GPU
loss.backward()
optimizer.step()
0 ≦ ssim ≦ 1(good) で 1に向けて更新したい。
loss.backward()はlossの値の減少方向に更新する仕様なので、loss = 1-ssim にして、(good)0 ≦ 1-ssim ≦ 1 で仕様に合わせる。
RCANが遅い
計算量が多いためRCANが遅い...。
実験の時は、Kfoldではなくtrain_test_splitで、modelはCascading Residual Network で比較的早く動くCARN(torchsrから使える)を使って実験して、最後にRCANでKfoldで5models作成。
より良いだろうmodel
surveyを読んだりすると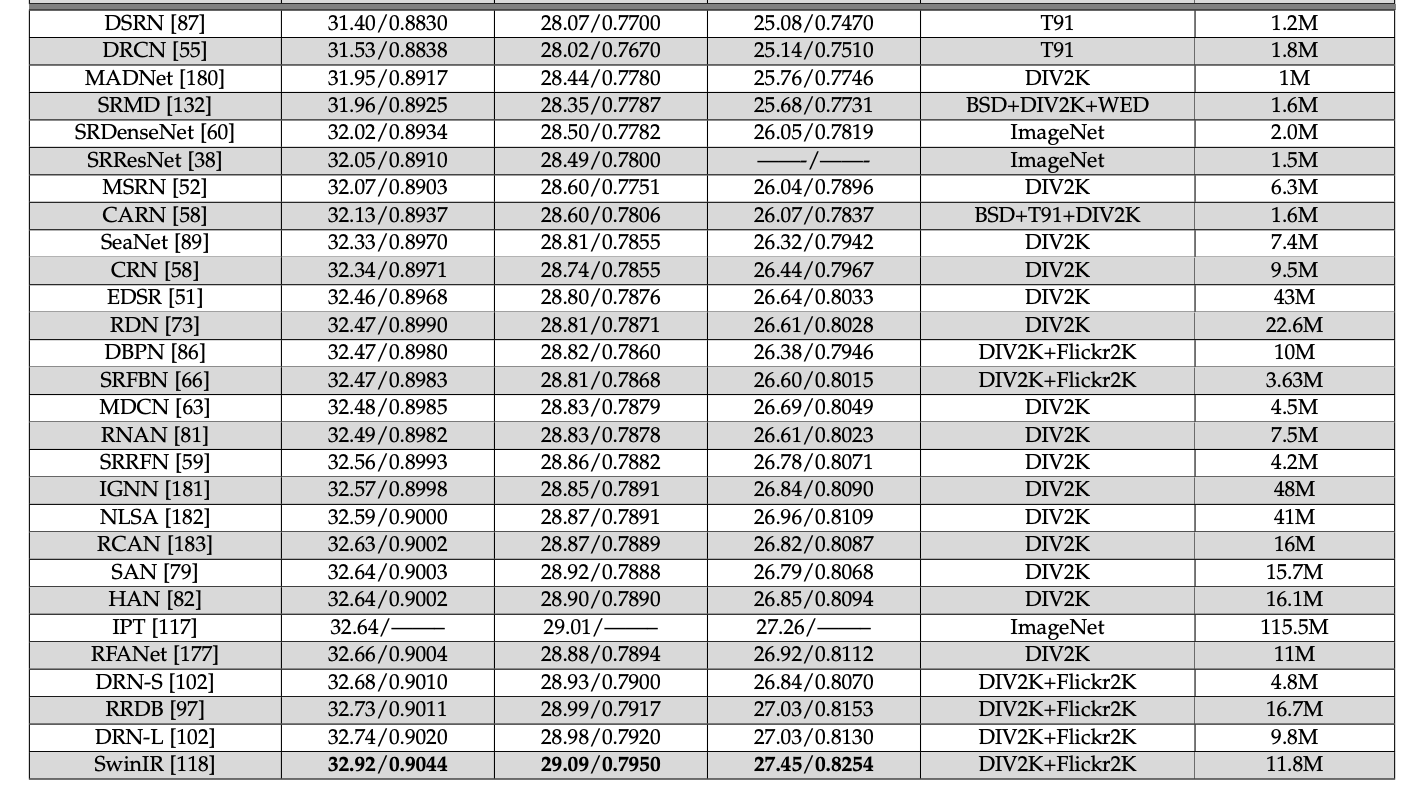
こんな感じなので swinTransformer系の SwinIR を実装できた方が良いスコアが出ることが期待されます。
swinTransformerV2系のSwin2SRはそれよりさらに良いかもしれません。
HuggingFaceでmodelが公開されてます。
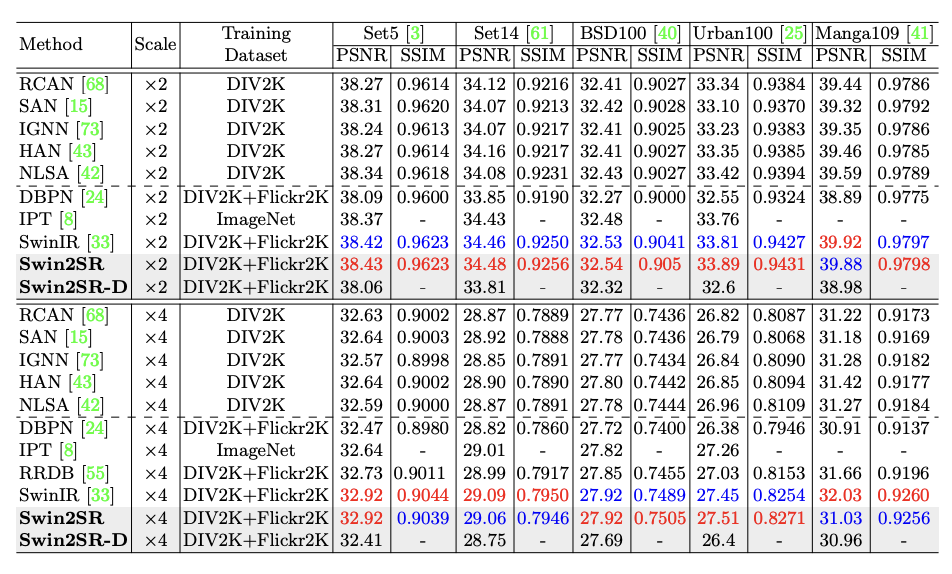
Transformer系を使っても、RCANと同様にx4からx5へ変更が必要だと思うのですが、理解が曖昧なままでの杜撰な書き換えでは動いてくれなかったので、最後までRCANでした。
コンペ終盤には transformer系に駆逐されると思っていましたが、運良く 2nd place に留まれました。
コード
.ipynb が投下してあるだけですが。