はじめに
こんにちは!データサイエンス系オタク会社員のroadricefieldです!今日はggplot2のお話です.
世はDX(デジタルトランスフォーメーション)大戦国時代!アカデミアのあなたも,企業研究者のあなたも,営業のあなたも,マーケティングのあなたも,家計簿をつける主婦のあなたも,高校生のあなたも,そこの社長さんも!データをグラフにして可視化する機会はたくさんあるのではないでしょうか?
グラフを描くツールとしてはExcelが便利です.プログラミングをしなくても使えるし,工夫をすればきれいなグラフを誰でもかんたんに描くことができます.しかも最近の義務教育ではExcelの使い方は授業で教えてもらえるのではないでしょうか.
Excelは確かに便利です.しかし,以下のような困りごとはありませんか?
- マウスでいろんなボタンをポチポチクリックするのは大変!時間がかかる!
- 同じグラフを違うデータでたくさん描きたいけどコピペ作業が大変!
上記のようなお悩みを抱えているそこのあなた!ぜひ,この記事を読んでggplot2という素晴らしい武器を身に着けてきれいなグラフを素早く,効率的に描けるようになりましょう!!
この記事はどんな人向け?
この記事は以下の方々に向けて書きます.
- きれいなグラフを素早く,効率的に描きたい方
- プログラミング言語Rをある程度使えてデータの解析を始めたい方
- ggplot2の存在は知っているけどなんだか使いこなせていない方
なお,プログラミングの経験がない方はこちらの記事でパパっとRというプログラミング言語を習得してください.ggplot2はR用のツールです.
サンプルデータの置き場所
この記事で使用する表データとスクリプトはすべてこちらに置きましたので必要に応じてダウンロードしてください.
レベル1 とにかくプロット!
早速以下のデータを使ってグラフを描いていきますよ!
| day | time |
|---|---|
| 1 | 156 |
| 2 | 109 |
| 3 | 92 |
| 4 | 113 |
| 5 | 39 |
| 6 | 13 |
| 7 | 66 |
このデータは何でしょう?そうですね,僕がある一週間でウマ娘プリティーダービーをプレイした時間(単位: 分)ですね!横軸に日を,縦軸にプレイ時間を取った折れ線グラフをggplot2で描くには以下のようなスクリプトになります.
library(ggplot2)
df <- read.csv("https://github.com/roadricefield/Qiita_ggplot2_-/raw/main/level1.csv")
g <- ggplot(df, aes(x = day, y = time)) + #グラフオブジェクト
geom_line()
plot(g) #作ったグラフを画面に表示
ggsave(plot = g, file = "level1.png", w = 3.1, h = 2.4, dpi = 600) #pngでグラフを保存
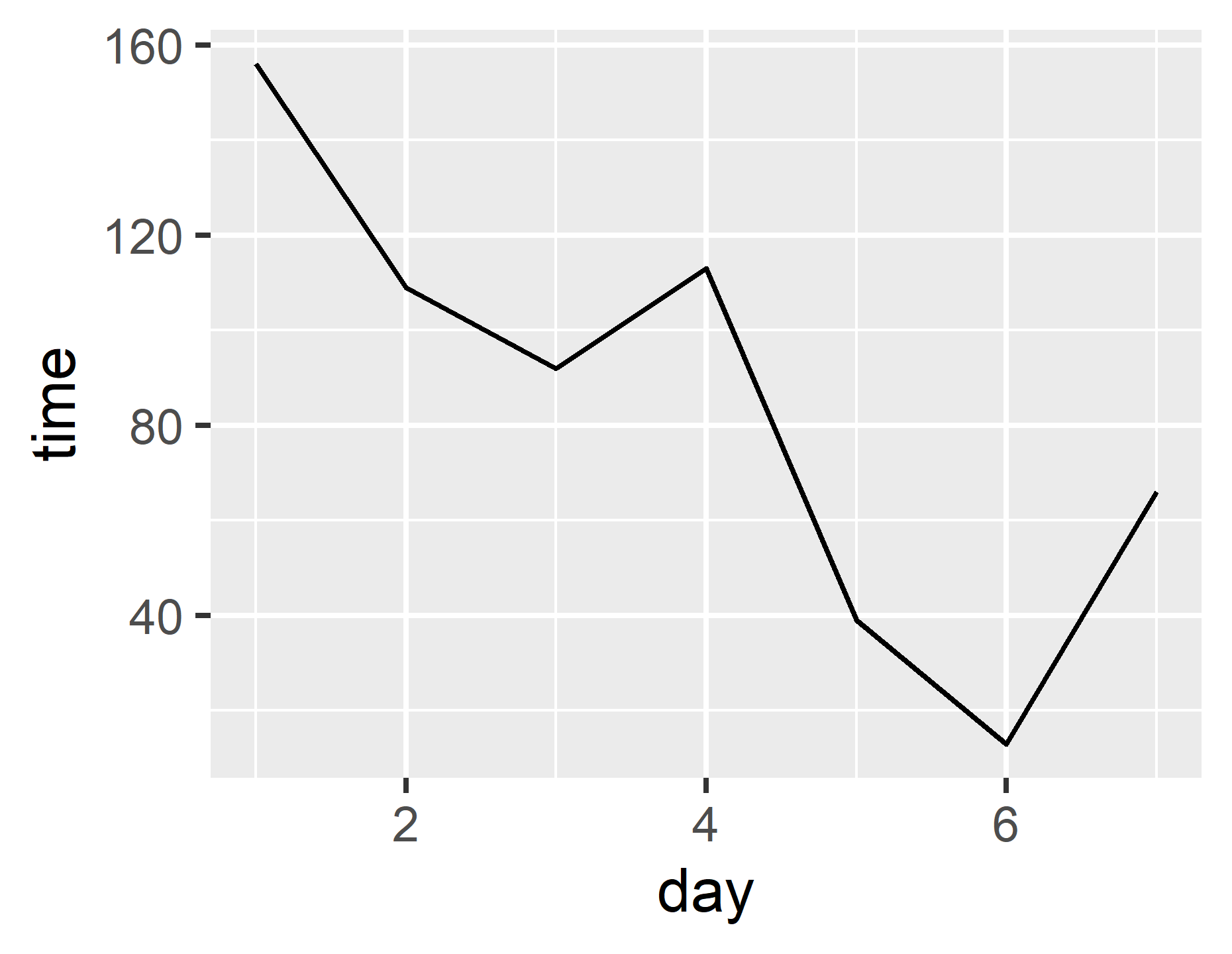
ちょっと見た目があれですがレベル2で一気に改善するのでここではggplot2の基本のキを説明しますね.
一番大事なのはggplot(データ, aes(x = x軸に取りたいデータの列名, y = y軸に取りたいデータの列名))です!このggplot()がプロットするデータの形式を指定するものです.今回は僕のある一週間でウマ娘プリティーダービーをプレイした時間のデータを変数dfに格納しました.これはデータフレームとなっており,日付がday列に,プレイ時間がtime列に格納されています.データdfを使ってx軸にday,y軸にtimeを取るグラフを作成するのでggplot(df, aes(x = day, y = time))となります.
ggplot()を作っただけではまだデータの形式を指定しただけで折れ線グラフを描くのか,棒グラフを描くのか,はたまた円グラフを描くのかは指定できていません.今回は折れ線グラフを描きたかったです.それを指定するのがgeom_line()の部分です.これをggplot()での指定に足し算で付け加えます.するとggplotは**「dfというデータの中のdayをx軸,timeをy軸に取って折れ線グラフ(geom_line())を作成ですね」**と理解してグラフをプロットしてくれます.
ということで例えばggplot(df, aes(x = time, y = day))とすればx軸とy軸が入れ替わります.
レベル2 グラフをカッコよくしよう!
先程レベル1でプロットしたグラフはダサいのでこれをもっとかっこよくしていきましょう.ここで大事なことを言います(書きます).よく聞いて(読んで)くださいね.
ggplot要素を足し算
ggplot要素を足し算
while(1) print("ggplot要素を足し算")
大事なことなので無限に言いました(出力しました).
軸ラベルを変える
まずは軸ラベルを変更しましょう.dfの列名を変更しても良いのですがここでは軸ラベルという要素を足し算します.
g <- ggplot(df, aes(x = day, y = time)) +
geom_line() +
xlab("Date") + #x軸の軸ラベルを指定
ylab("Play time (min)") #y軸の軸ラベルを指定
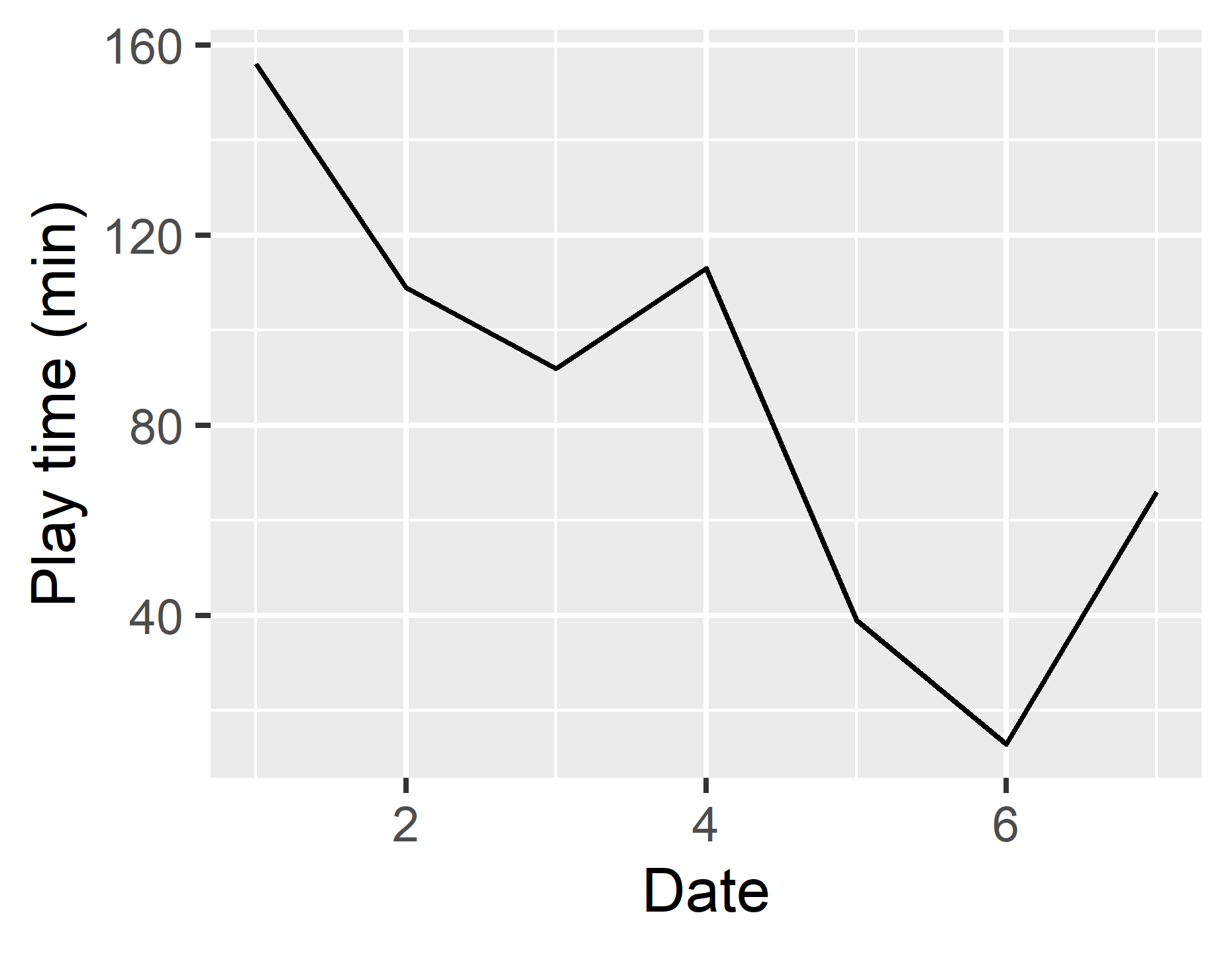
x軸,y軸のラベルを指定する要素はそれぞれxlab(),ylab()です.それぞれの括弧の中にラベルにしたい文字を書くだけ!かんたんでしょ?
軸目盛りの間隔を変える
今,横軸の目盛りが2, 4, 6となっていますがこれを1から7まで1刻みにしましょう.
g <- ggplot(df, aes(x = day, y = time)) +
geom_line() +
xlab("Date") +
ylab("Play time (min)") +
scale_x_continuous(breaks = seq(1,7,1)) #x軸の目盛り間隔を指定.もちろんbreaks = c(1,2,3,4,5,6,7)
#などでもOK!
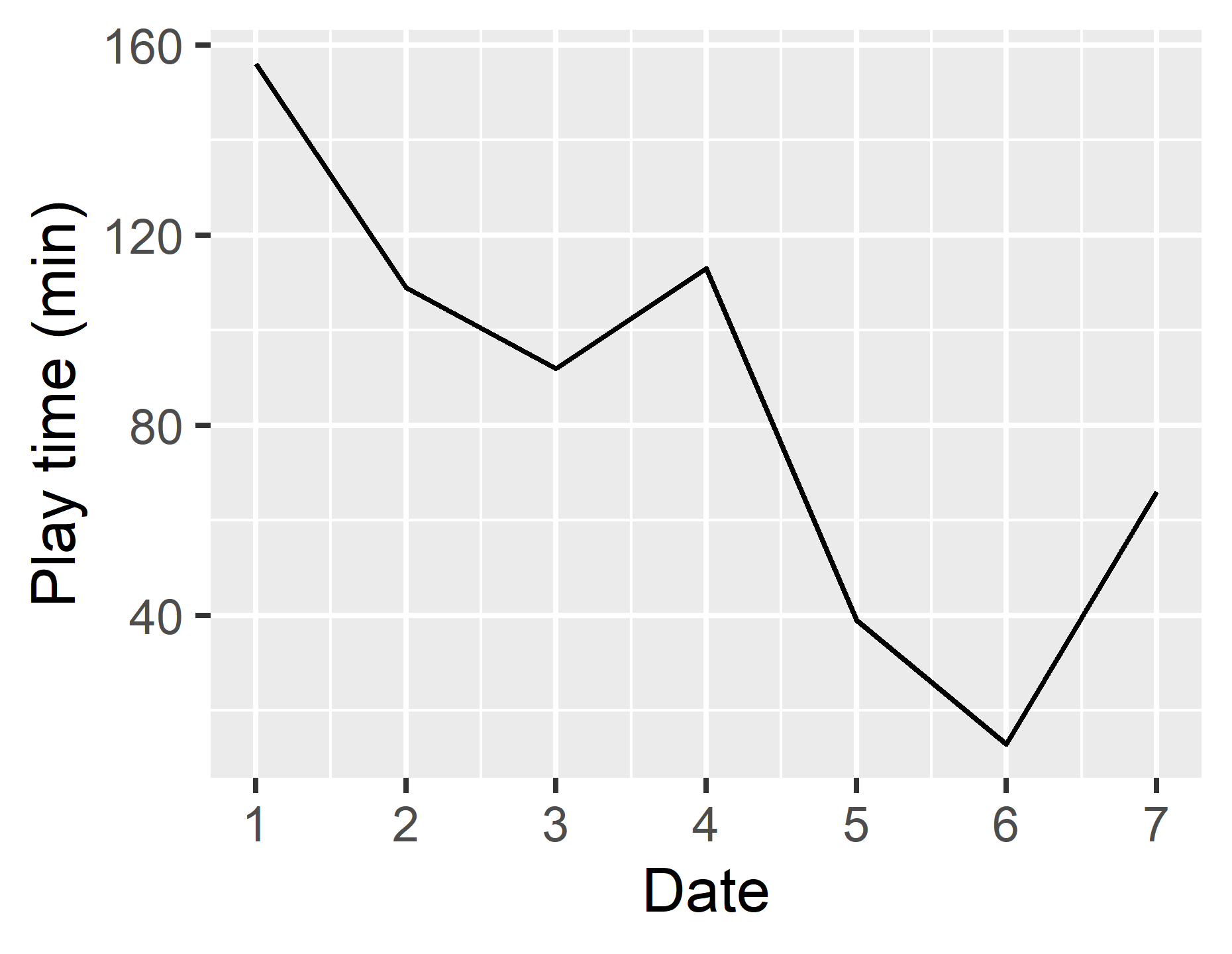
x軸の目盛りの指定はscale_x_continuous()のbreaksという引数で行います.もちろんy軸の目盛りの指定はscale_y_continuous()のbreaksで行えます.
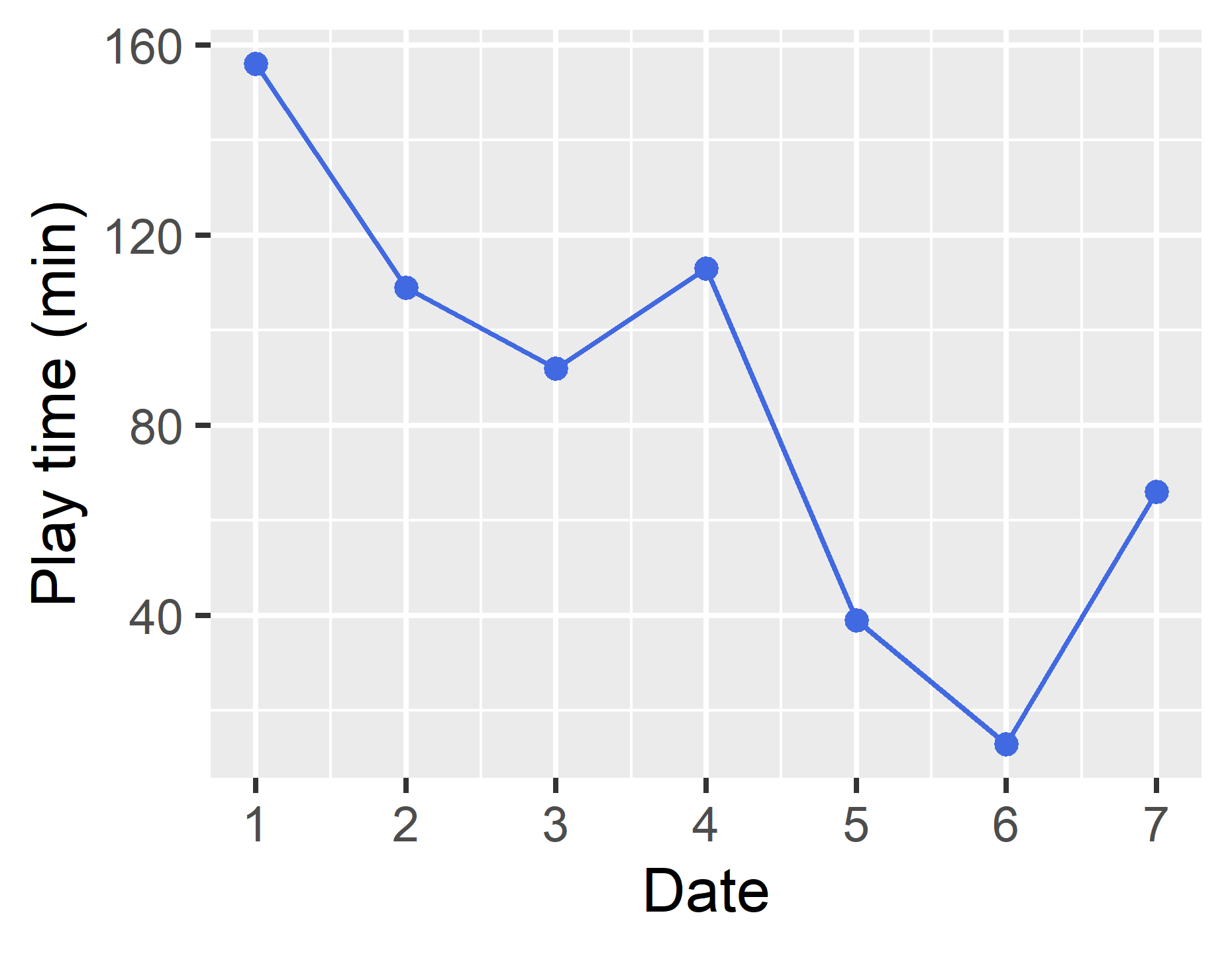
線の色を変えて点もプロットする
どんどん行きます.次は先の色を変えて各日付の位置に点もプロットしましょう.
g <- ggplot(df, aes(x = day, y = time)) +
geom_line(color = "royalblue") + #geom_line()のcolor引数に色を指定.
geom_point(color = "royalblue") + #geom_point()は点を打つ要素.color引数に色を指定.
xlab("Date") +
ylab("Play time (min)") +
scale_x_continuous(breaks = seq(1,7,1))
ちなみにRで使用できる色の名前はこちら.
この調子でお好みにカスタマイズする
g <- ggplot(df, aes(x = day, y = time)) +
geom_line(color = "royalblue") +
geom_point(color = "royalblue") +
xlab("Date") +
ylab("Play time (min)") +
scale_x_continuous(breaks = seq(1,7,1)) +
theme_classic() + #背景を白くして上と右の枠線を描かないようにする要素
theme(panel.grid = element_blank()) + #背景のグリッド線を消す
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) #目盛り,軸ラベルの文字の大きさを指定
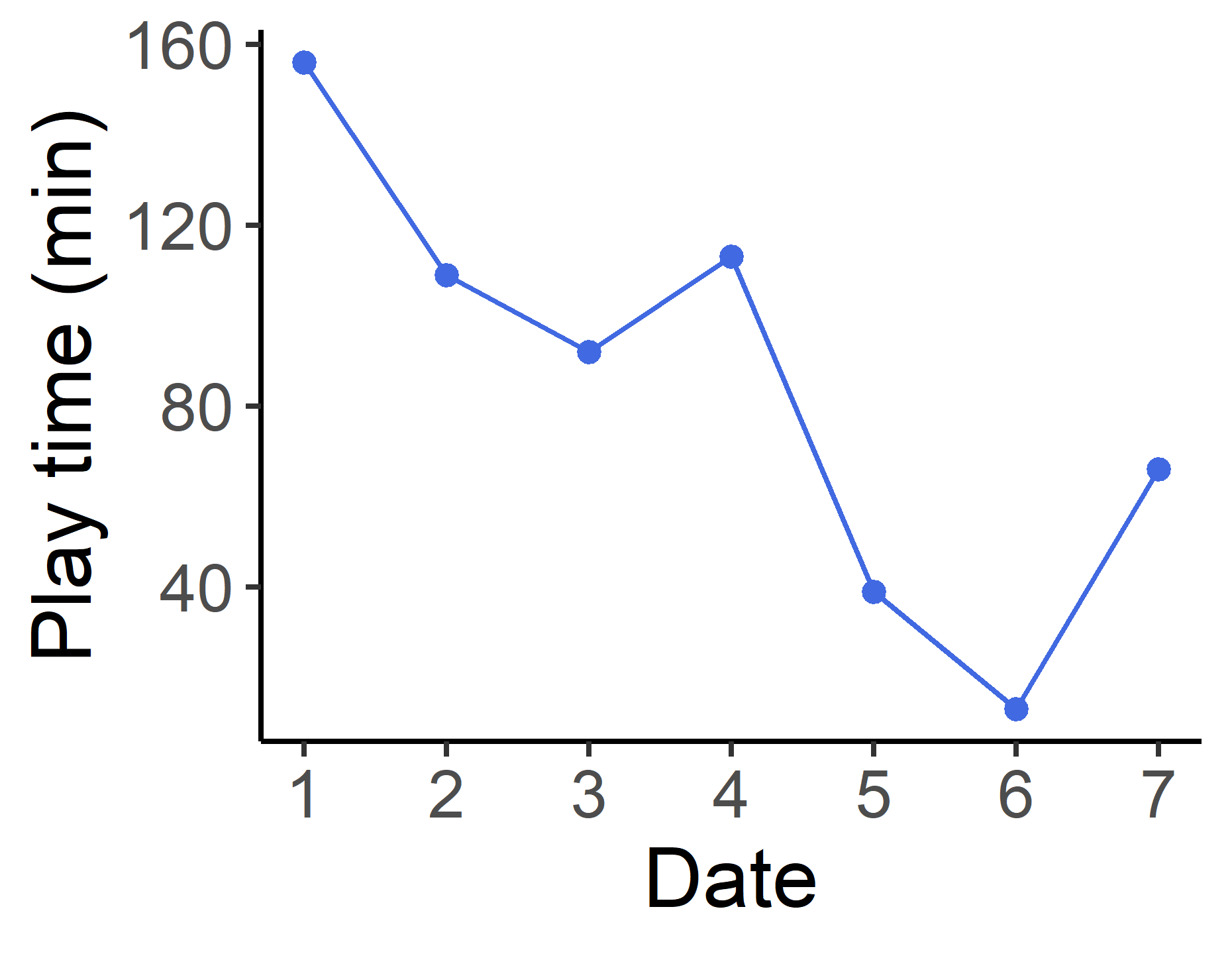
これで論文クオリティのきれいなグラフになりました.グラフの見た目の細かい調整はtheme()という要素を足していくことでできます.例えばtheme(panel.grid = element_blank())の表すところは背景のグリッド線(panel.grid)はいらない(element_blank())ということです.theme(axis.text = element_text(size = 12))は軸のテキスト,つまり目盛り(axis.text)はサイズ12の文字(element_text(size = 12))にしてくださいということを表します.
軸目盛りとして表示するテキストを変更する
現在,x軸の目盛りは1から7まで1ずつの間隔で1~7までの数字は表示されていますがこれを曜日に上書きしてみましょう.
week <- c("Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat") #目盛りに使用する文字のベクトル
g <- ggplot(df, aes(x = day, y = time)) +
geom_line(color = "royalblue") +
geom_point(color = "royalblue") +
scale_x_continuous(breaks = seq(1,7,1), labels = week) + #lables引数に目盛りとして使う文字を指定.
#1~7まで1ずづの間隔で"Sun"~"Sat"の文字列を軸ラベルに書く.
xlab("Day") + #曜日なので"Day"としておく.
ylab("Play time (min)") +
theme_classic() +
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15))
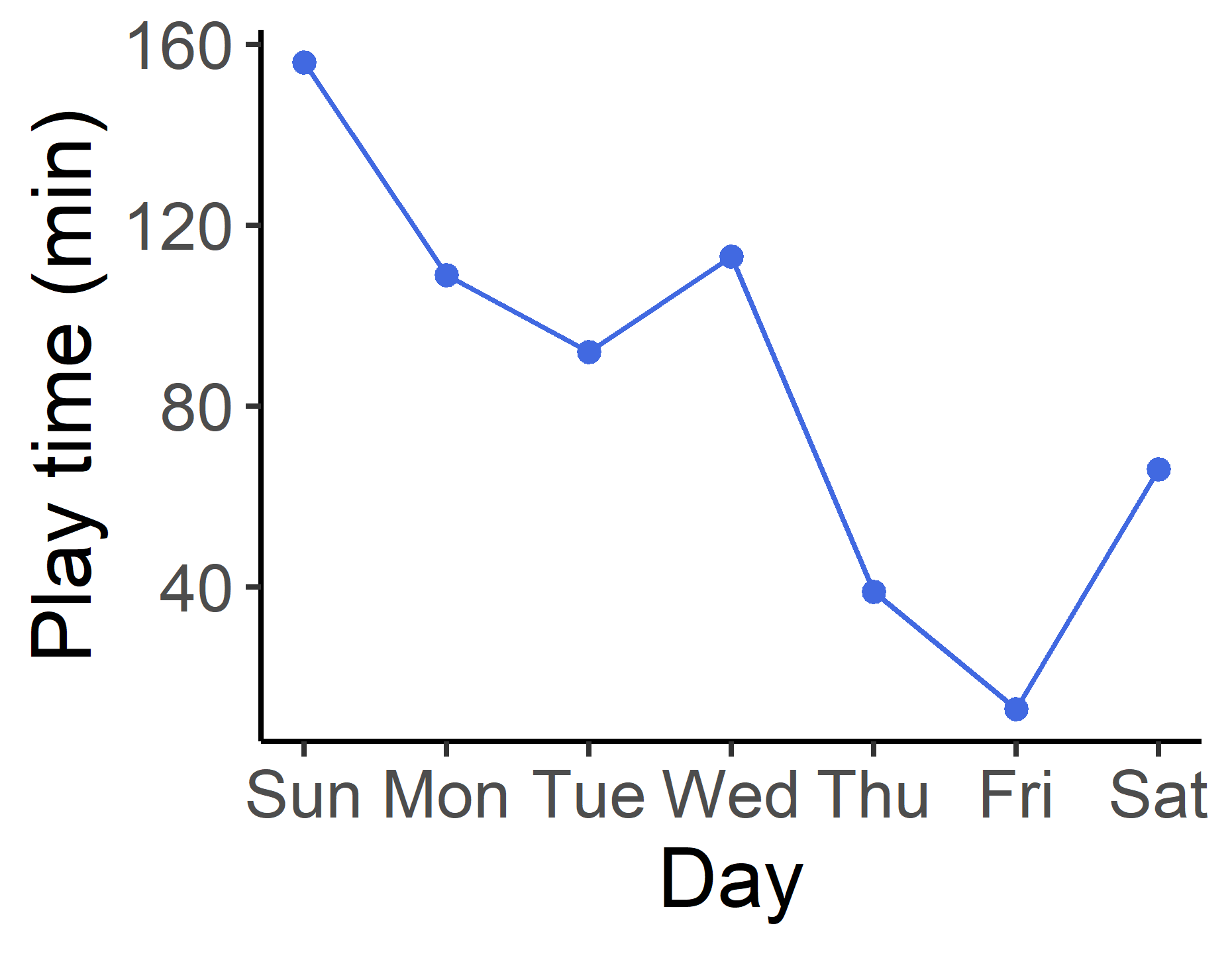
レベル3 複数の系統のデータをプロットする
レベル1とレベル2では以下の僕のウマ娘のプレイ時間だけをプロットしてきました.
| day | time |
|---|---|
| 1 | 156 |
| 2 | 109 |
| 3 | 92 |
| 4 | 113 |
| 5 | 39 |
| 6 | 13 |
| 7 | 66 |
次はこれに加えて同じ週に僕がTwitterをしていた時間も一緒にプロットしてみましょう.以下がそのデータです.
| day | time |
|---|---|
| 1 | 94 |
| 2 | 108 |
| 3 | 41 |
| 4 | 105 |
| 5 | 103 |
| 6 | 86 |
| 7 | 124 |
これからこんなグラフを描きましょう!
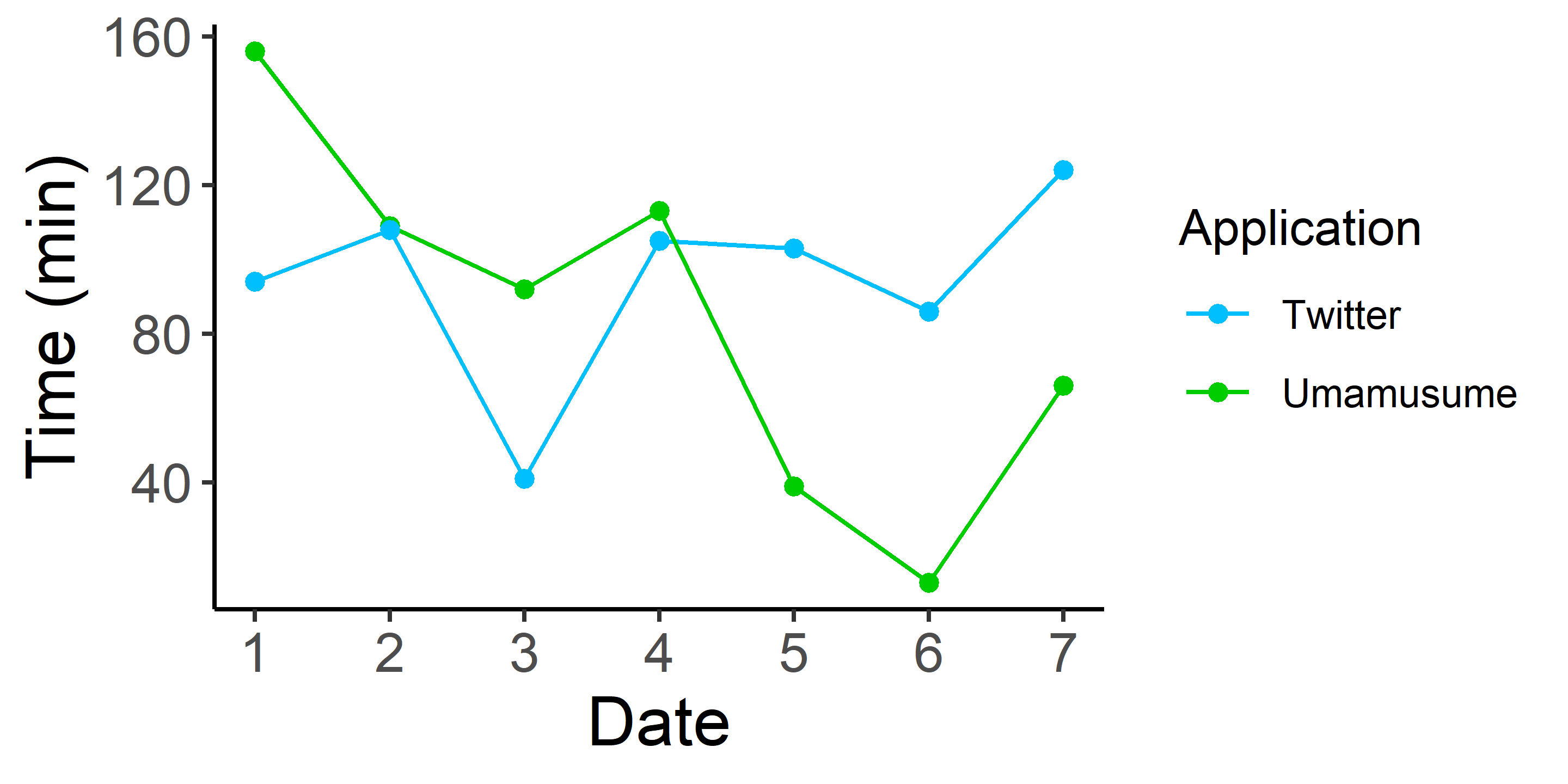
上のグラフではx軸で日付を,y軸でアプリの起動時間を表していますね.そして色でアプリの種類を表しています.つまり,色はx軸でもy軸でもない新しい軸であるという考え方をします.
実際にプロットして一緒に考えましょう!まず,ウマ娘とTwitterのデータをあわせて以下のようなデータフレームを作ります.
| day | time | application |
|---|---|---|
| 1 | 156 | Umamusume |
| 2 | 109 | Umamusume |
| 3 | 92 | Umamusume |
| 4 | 113 | Umamusume |
| 5 | 39 | Umamusume |
| 6 | 13 | Umamusume |
| 7 | 66 | Umamusume |
| 1 | 94 | |
| 2 | 108 | |
| 3 | 41 | |
| 4 | 105 | |
| 5 | 103 | |
| 6 | 86 | |
| 7 | 124 |
day列をx軸,time列をy軸に取り,色でapplication列を表すのでggplot()内のaes()にはaes(x = day, y = time, color = application)と書きます.
df <- read.csv("https://github.com/roadricefield/Qiita_ggplot2_-/raw/main/level3.csv")
g <- ggplot(df, aes(x = day, y = time, color = application)) + #色でapplication列を指定
geom_line() +
geom_point() +
scale_color_manual(values = c("deepskyblue1", "green3")) + #グラフの色を順に指定
scale_x_continuous(breaks = seq(1,7,1)) +
xlab("Date") +
ylab("Time (min)") +
labs(color = "Application") + #凡例のタイトルを指定.今回は色に関する凡例のタイトルなので
theme_classic() + #color = "Application"と指定する必要がある.
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15))
plot(g)
このスクリプトで上のグラフを描くことができます.scale_color_manual()のvalues引数に色をベクトルで指定することでグラフの色を変更できます.ちなみに凡例はguides(color = F)と要素を足し算すれば消えます.また,色ではなく点の形と線の種類(shapeとlty)でアプリの種類を表現することもできます.
g <- ggplot(df, aes(x = day, y = time, shape = application, lty = application)) +
geom_line() +
geom_point(size = 2) + #点を少し大きくした.
scale_x_continuous(breaks = seq(1,7,1)) +
xlab("Date") +
ylab("Time (min)") +
labs(shape = "Application", lty = "Application") + #めんどいがshapeとlty両方で書く必要がある.
theme_classic() + #書かないとどうなるかは試してみてください.
theme(panel.grid = element_blank())
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15))
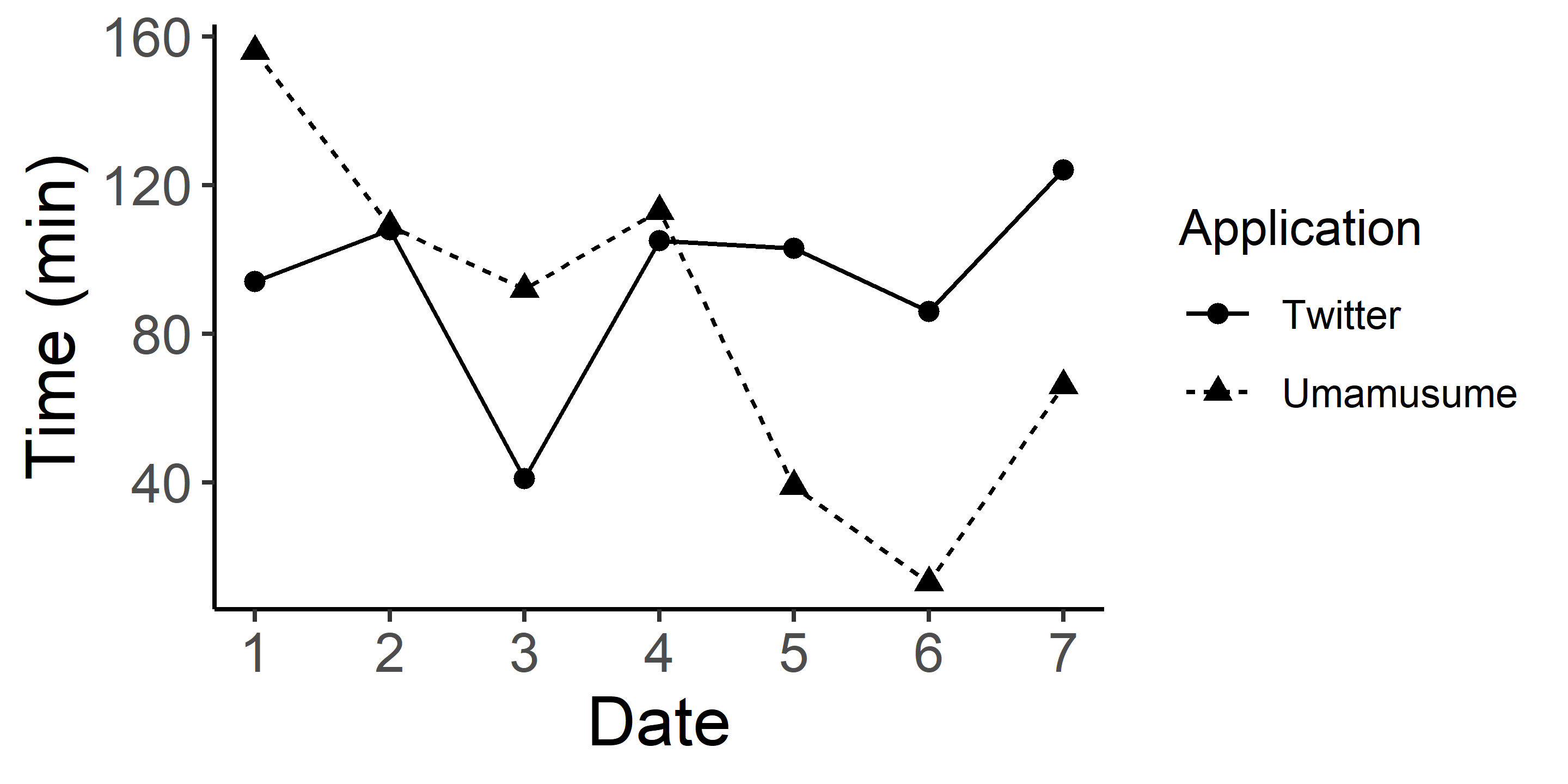
お医者さんの論文でよく見るタイプのグラフになりました.
2つの系統のグラフを分けてプロットするには?
facet_wrap()という要素を使用します.以下のように書きます.
g <- ggplot(df, aes(x = day, y = time, color = application)) +
geom_line() +
geom_point() +
facet_wrap(~application, ncol = 1) + #applicationごとにグラフを分けて縦一列で表示する.
scale_color_manual(values = c("deepskyblue1", "green3")) +
scale_x_continuous(breaks = seq(1,7,1)) +
xlab("Date") +
ylab("Time (min)") +
theme_bw() + #theme_classic() -> theme_bw()
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
guides(color = F) + #これを書かないと各colorがどのapplicationを指すのかを示す凡例が残ってしまいます.
theme(strip.background = element_blank(), strip.text = element_text(size = 15)) #下記で説明.
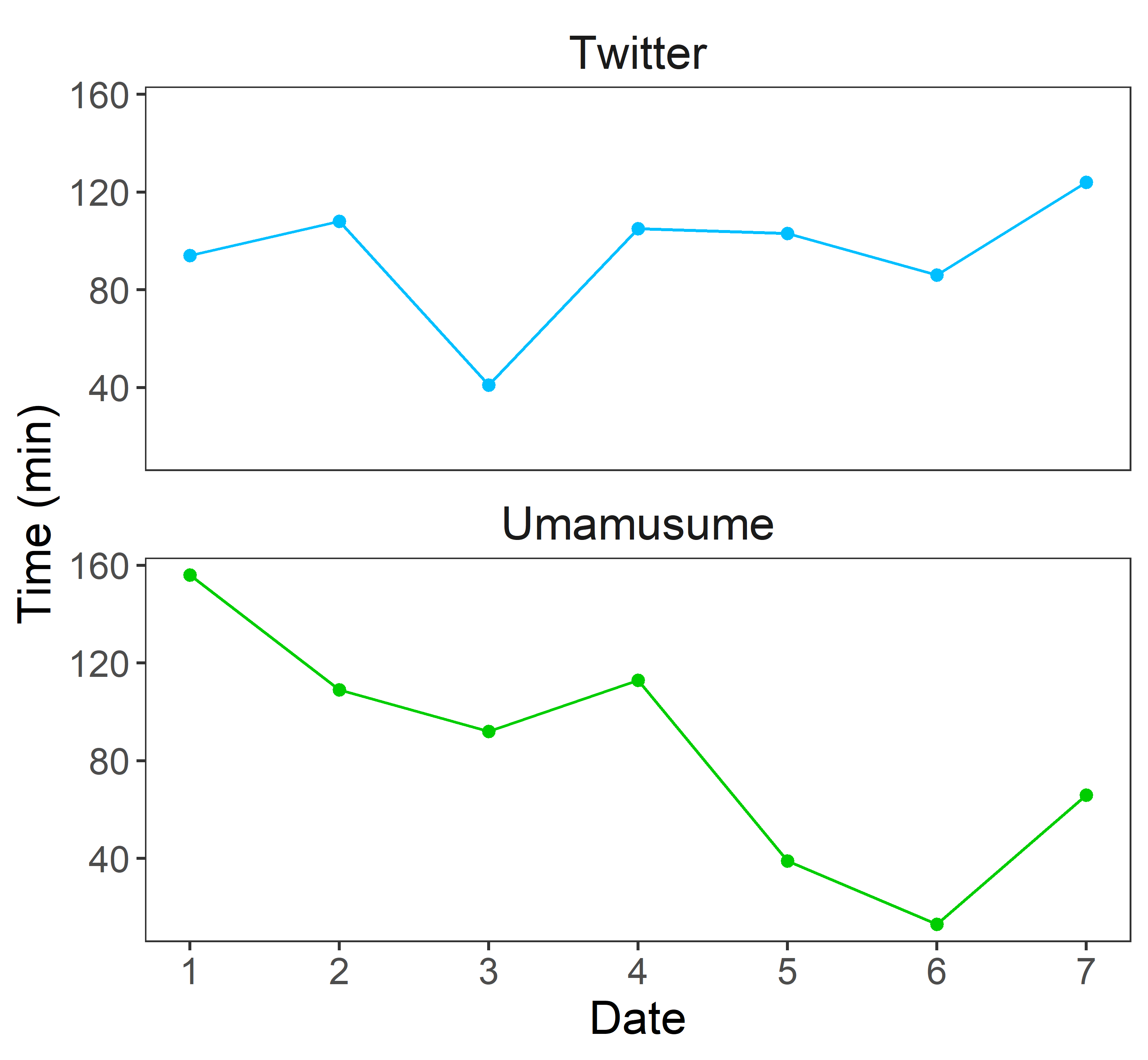
facet_wrap()ではグラフの分割に使用するデータのデータフレームの上の列名を~(チルダ)をつけて指定します.ncol,nrow引数で分割したグラフを表示するときの列数,行数をそれぞれ指定できます.ちなみにfacet_wrap(~application, ncol = 1, scales = "free_y")とするとy軸の目盛りを分割後それぞれのグラフに合わせて調整してくれます.theme_classic() -> theme_bw()としたのには理由があります.ためしにtheme_classic()に戻してみてください.軸に関して困ったことが起こります.最後に追記したtheme()のstrip.backgroundとstrip.textは分割したグラフのタイトル(今回は"Twitter"と"Umamusume")に関する要素です.これを消したりしていじってみてください.
レベル4 棒グラフ
レベル4では棒グラフを例にggplotの設定方法をお伝えします.使うデータは以下です.
| Subject | Average | SD |
|---|---|---|
| Mathematics IA | 51.88 | 18.43 |
| Mathematics IIB | 49.03 | 22.63 |
| Chemistry | 54.79 | 22.59 |
| Physics | 60.68 | 21.64 |
| Biology | 57.56 | 20.06 |
| Earth science | 39.51 | 17.69 |
このデータは令和2年度大学入試センター試験の理系科目の受験者平均点と標準偏差です.(出典)
とりあえず棒グラフをプロット
棒グラフはgeom_bar()という要素で描きます.とりあえず描いてみましょう.
df <- read.csv("https://github.com/roadricefield/Qiita_ggplot2_-/raw/main/level4.csv")
g <- ggplot(df, aes(x = Subject, y = Average)) +
geom_bar(stat = "identity") + #stat = "identity"はおまじないです.
theme_classic() +
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15))
plot(g)
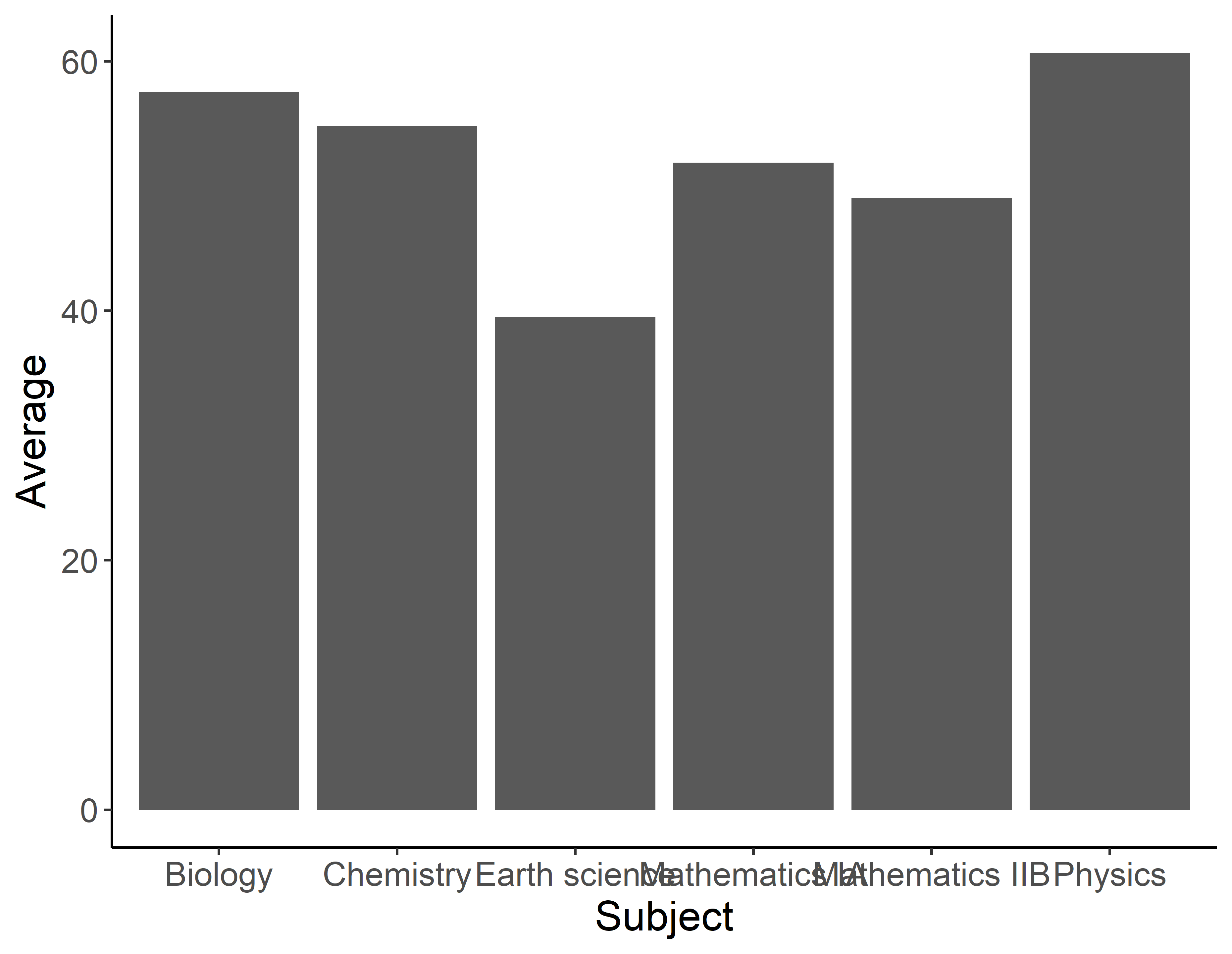
ひどい......折れ線グラフと同様にきれいにしていきたいですが実は棒グラフは色々とややこしいです.それではひとつひとつ直していきましょう!
横軸のラベルの角度を変更する
今のままでは横軸のラベルが重なってしまっているのでこれを回転させましょう.軸ラベルの回転にはtheme()のelement_text()のangleという引数を使用します.
g <- ggplot(df, aes(x = Subject, y = Average)) +
geom_bar(stat = "identity") +
theme_classic() +
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
theme(axis.title.x = element_blank()) + #"Subject"は消しちゃう.
theme(axis.text.x = element_text(angle = 30, hjust = 1, size = 15)) #横軸のテキスト(axis.text.x)を30度回転させて
#ついでに文字の大きさを15 ptに変更する.
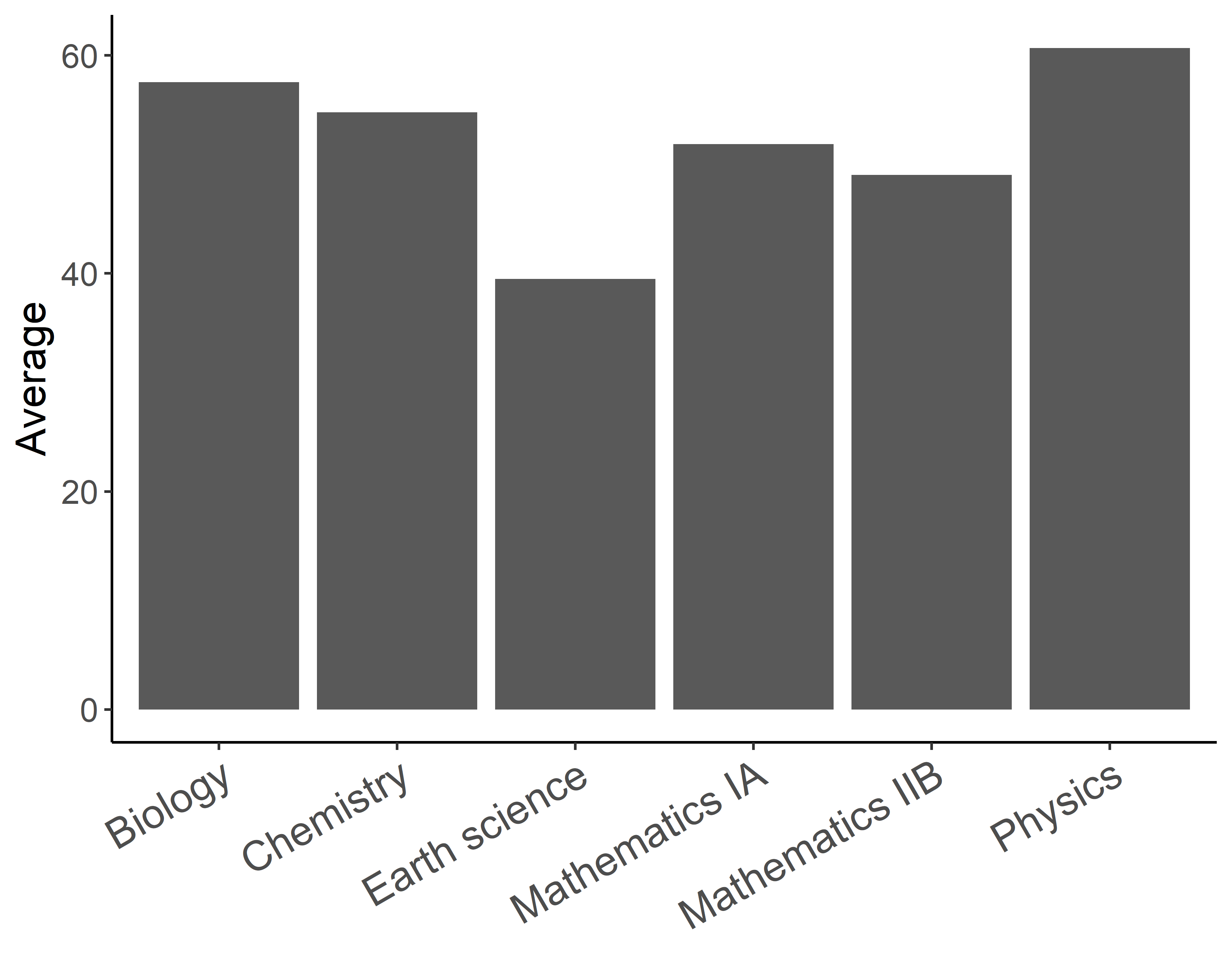
これで科目名が読めるようになりました.hjust引数やvjust引数でラベルの位置を上下左右に微調整できます.基本的にはhjust = 1としておけば間違いないでしょう.
標準偏差をエラーバーで表示する
実験結果を示すグラフを描く際はエラーバーを表示しなければならないでしょう.この棒グラフに各科目の標準偏差をエラーバーで表示してみましょう(テストの点数の標準偏差の可視化として適切ではありませんが......).エラーバーを表示する要素はgeom_errorbar()です.今回の場合以下のように書きます.
g <- ggplot(df, aes(x = Subject, y = Average)) +
geom_bar(stat = "identity") +
theme_classic() +
geom_errorbar(aes(ymin = Average - SD, ymax = Average + SD), width = 0.3) + #これ!!!!!!!!!!!!!!!!
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
theme(axis.title.x = element_blank()) +
theme(axis.text.x = element_text(angle = 30, hjust = 1, size = 15))
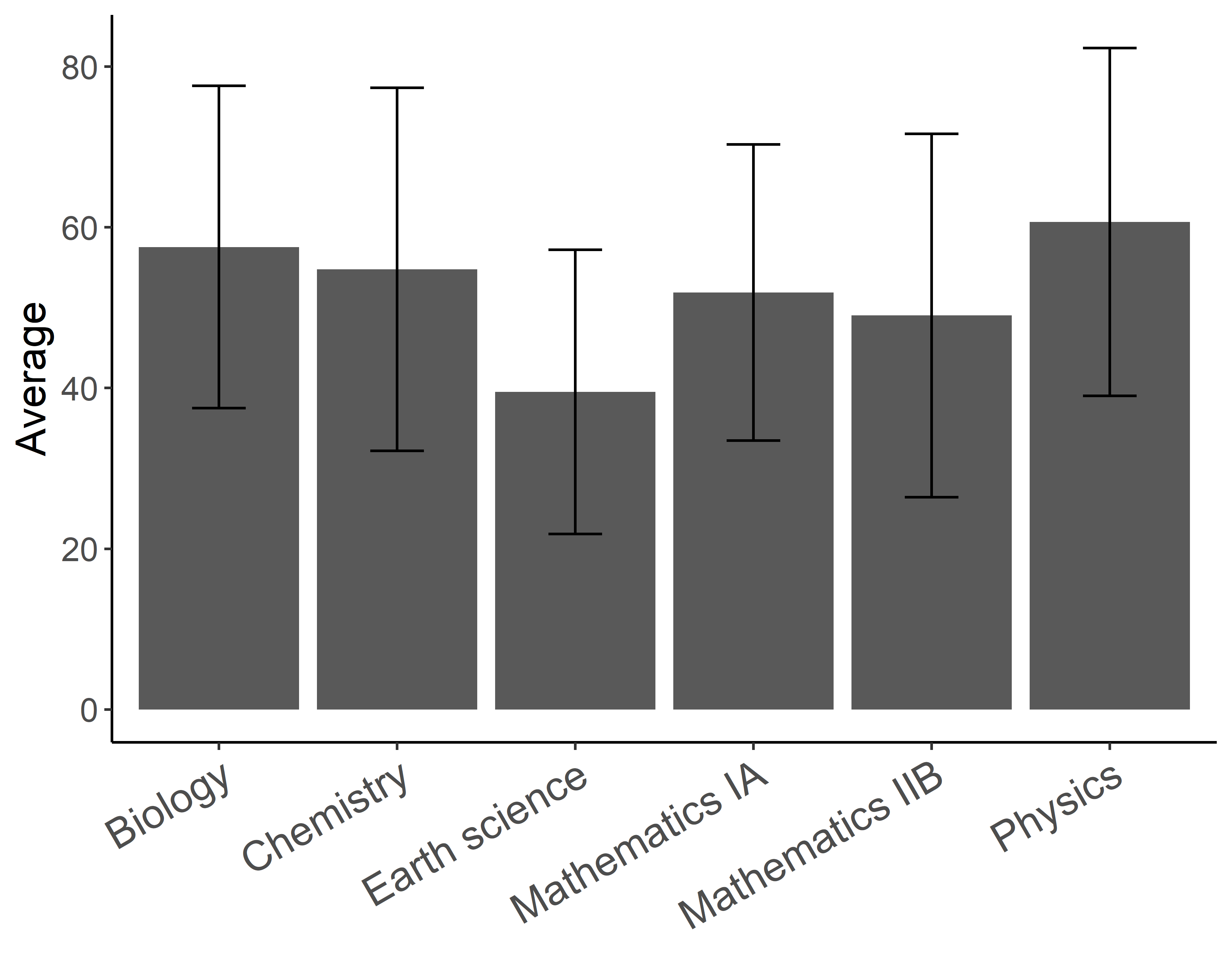
geom_errorbar()もaes()を指定します.縦軸のエラーバーを作成するのでエラーバーの下端yminをAverage - SD,上端ymaxをAverage + SDとします.widthはエラーバー自体の横幅です.指定しないとデフォルトの1が適用されて棒グラフ本体の横幅と同じ幅となりかなりダサいです.
各科目のエラーバー,標準偏差はほぼ同じであり,特定の科目のみが「差が付きやすい」試験だったということはなかったようです.受験生はこれらの教科からいくつか選択して受けるので科目ごとの標準偏差が大きく異なるようでは不公平になりますよね.地学を除けば平均点もほぼ横並び,センター試験,すごいです.
項目の表示順を変更する
あれ?そういえば科目の表示順が変わっていませんか?もう一度もとデータを見てみましょう.
| Subject | Average | SD |
|---|---|---|
| Mathematics IA | 51.88 | 18.43 |
| Mathematics IIB | 49.03 | 22.63 |
| Chemistry | 54.79 | 22.59 |
| Physics | 60.68 | 21.64 |
| Biology | 57.56 | 20.06 |
| Earth science | 39.51 | 17.69 |
次に今のグラフを見てみましょう.
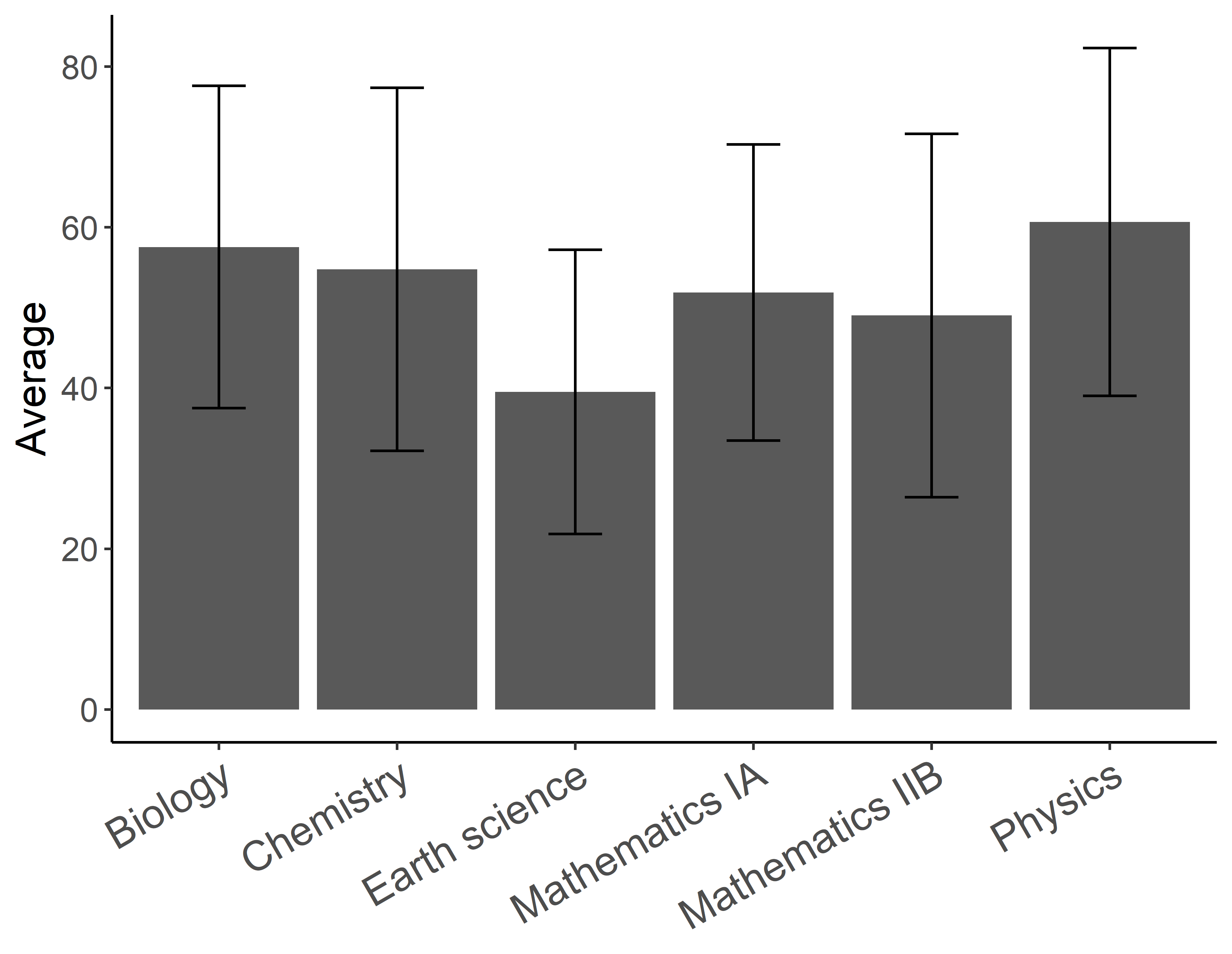
もしかして,横軸ラベルが,辞書順に,入れ替わってるぅ~~~~~~!!!???
なんたるありがた迷惑!実はggplotには指定をしない限りグラフの軸ラベルを辞書順に並び替えて表示してしまう悪い癖があるようです.これを防ぐためには予め順番を指定しておく必要があります.これには順番の情報を保持したデータ型であるfactor型を使用します.以下のように書きます.
df$Subject <- factor(df$Subject, levels = c("Mathematics IA", "Mathematics IIB",
"Chemistry", "Physics", "Biology", "Earth science")) #これ!!!!!!!!!!!!!!!!!!!
g <- ggplot(df, aes(x = Subject, y = Average)) +
geom_bar(stat = "identity") +
theme_classic() +
geom_errorbar(aes(ymin = Average - SD, ymax = Average + SD), width = 0.3)+
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
theme(axis.title.x = element_blank()) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 15)) #角度を45度に変更しました.
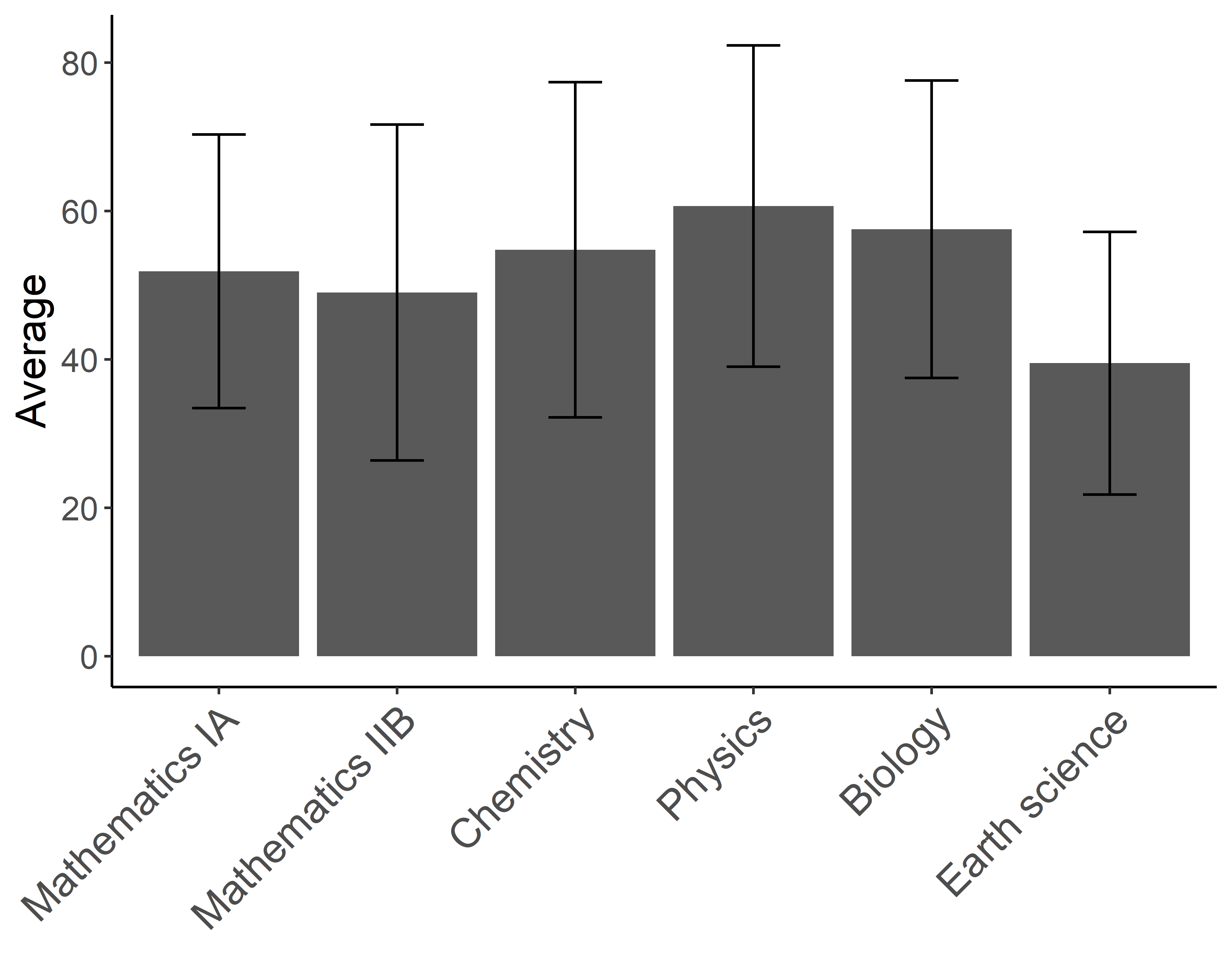
factor()関数の1つ目の引数に順番を指定したい文字列のベクトル(今回はdf$Subject)を指定します.そしてlevels引数に順番を直接ベクトルで入力することで指定します.ここに指定した順でグラフに表示されるようになります.(今回の場合はdf$Subject <- factor(df$Subject, levels = df$Subject)でもOKですね.)
棒グラフに色をつける
灰色のグラフは見苦しいですね.色をつけましょう.それぞれの科目っぽい色を指定してみましょう.
df$Subject <- factor(df$Subject, levels = c("Mathematics IA", "Mathematics IIB",
"Chemistry", "Physics", "Biology", "Earth science"))
g <- ggplot(df, aes(x = Subject, y = Average, color = Subject)) +
geom_bar(stat = "identity") +
theme_classic() +
geom_errorbar(aes(ymin = Average - SD, ymax = Average + SD), width = 0.3) +
scale_color_manual(values = c("deepskyblue1", "royalblue", "purple", "red",
"seagreen", "saddlebrown")) +
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
theme(axis.title.x = element_blank()) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 15))
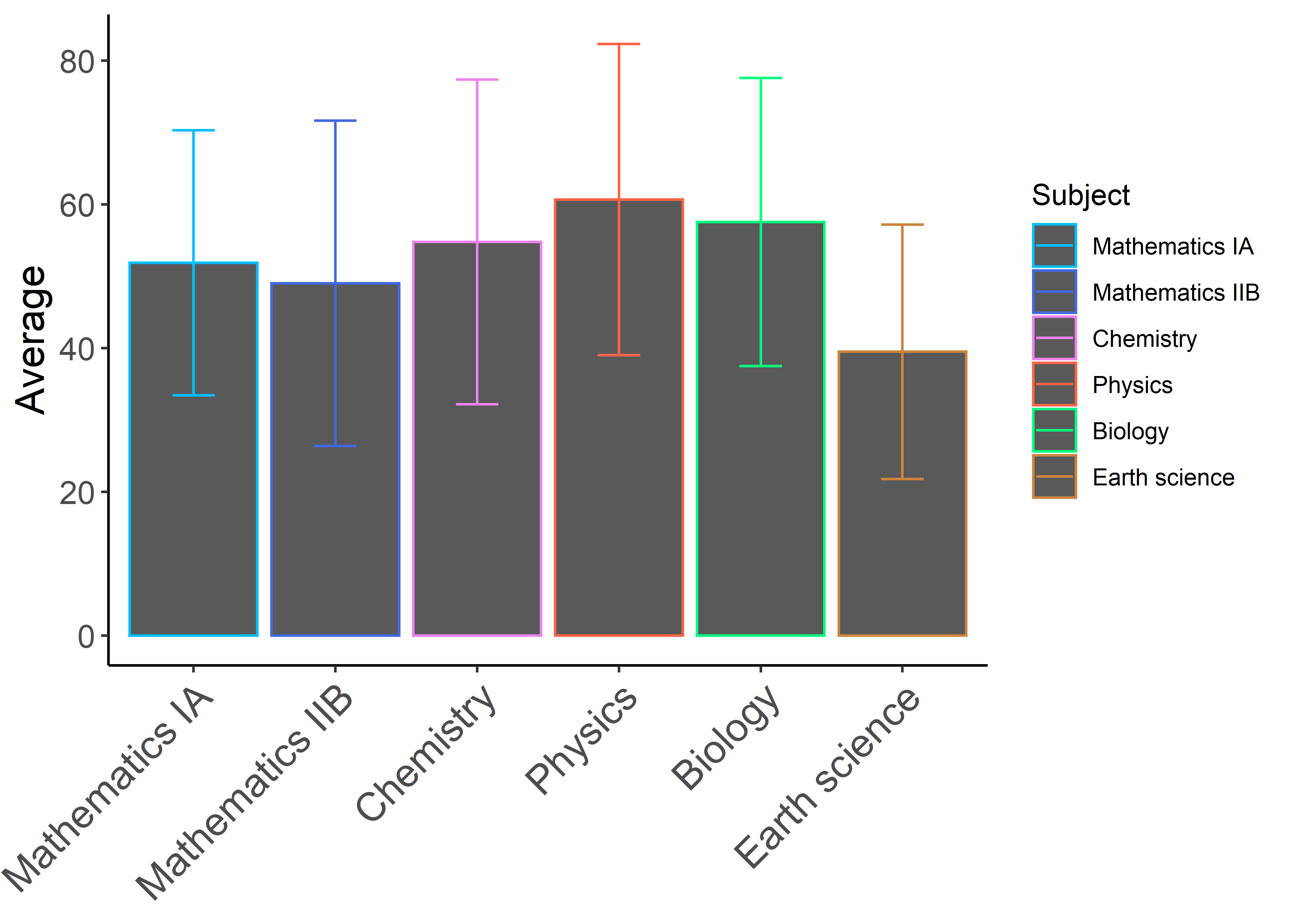
あれ??なんか思ってたのと違う......
実はggplotでは棒グラフの外枠線をcolorで,塗りつぶしの色をfillという別の引数で指定することになっています.また,余計な凡例も出ていたりするのでそこのところを以下のように調整します.
df$Subject <- factor(df$Subject, levels = c("Mathematics IA", "Mathematics IIB",
"Chemistry", "Physics", "Biology", "Earth science"))
g <- ggplot(df, aes(x = Subject, y = Average, fill = Subject)) + #color = Subject -> fill = Subject
geom_bar(stat = "identity") +
theme_classic() +
geom_errorbar(aes(ymin = Average - SD, ymax = Average + SD), width = 0.3) +
scale_fill_manual(values = c("deepskyblue1", "royalblue", "violet", "tomato1", #scale_color_manual() -> scale_fill_manual()
"springgreen1", "tan3")) +
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
theme(axis.title.x = element_blank()) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 15)) +
guides(fill = F) #これを書かないと各fillの色がどの科目かを示す凡例が出てしまう.
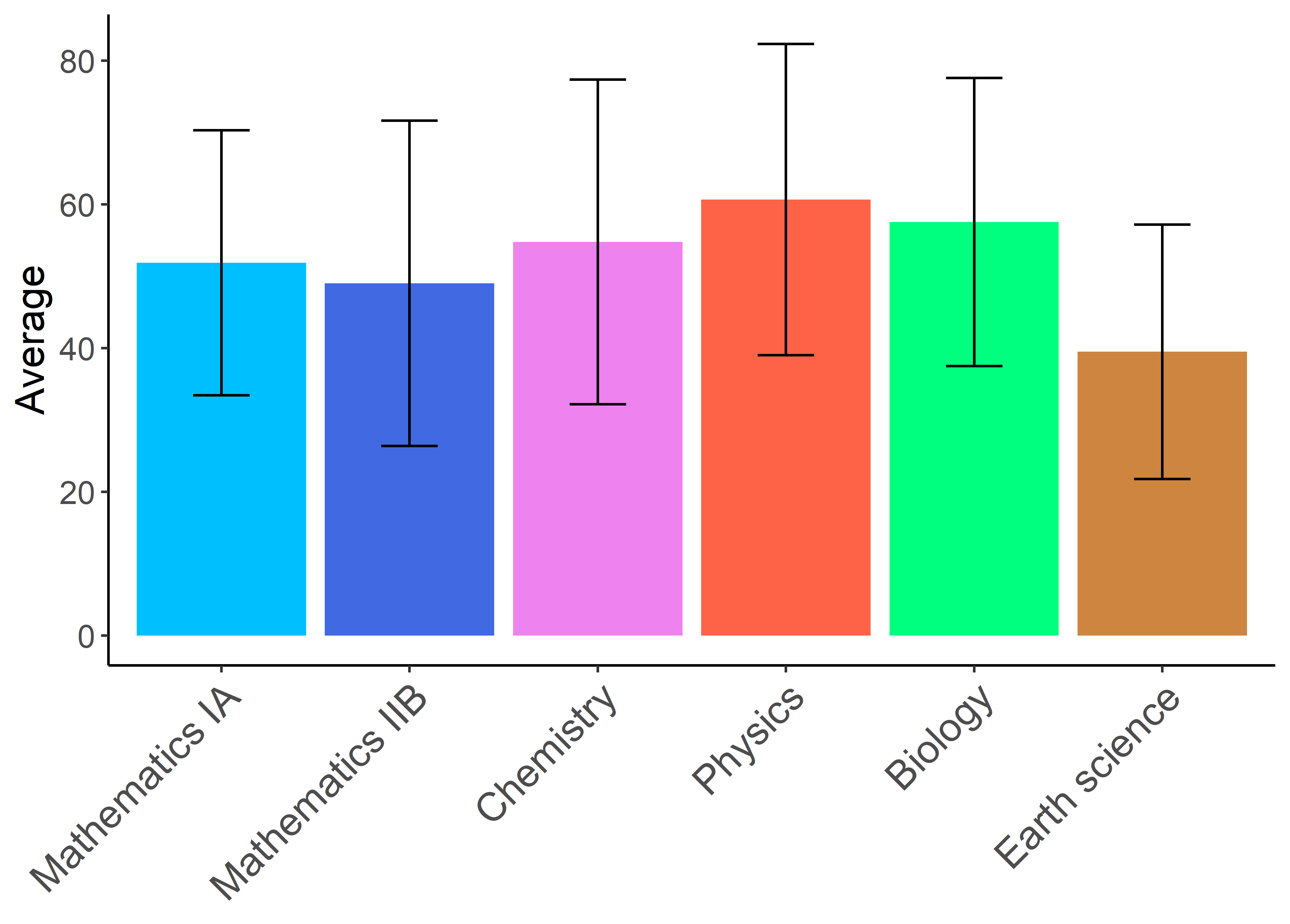
いい感じになりましたね.
軸の範囲や目盛り間隔を変更する
テストは100点満点なので縦軸の範囲を0~100点にしてみましょう.横軸の範囲設定はxlim(),縦軸はylim()で行います.
g <- ggplot(df, aes(x = Subject, y = Average, fill = Subject)) +
geom_bar(stat = "identity") +
theme_classic() +
geom_errorbar(aes(ymin = Average - SD, ymax = Average + SD), width = 0.3) +
scale_fill_manual(values = c("deepskyblue1", "royalblue", "violet", "tomato1",
"springgreen1", "tan3")) +
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
theme(axis.title.x = element_blank()) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 15)) +
guides(fill = F) +
ylim(c(0,100)) #これ!!!!!!!!!!!!!!!!!!!!
plot(g)
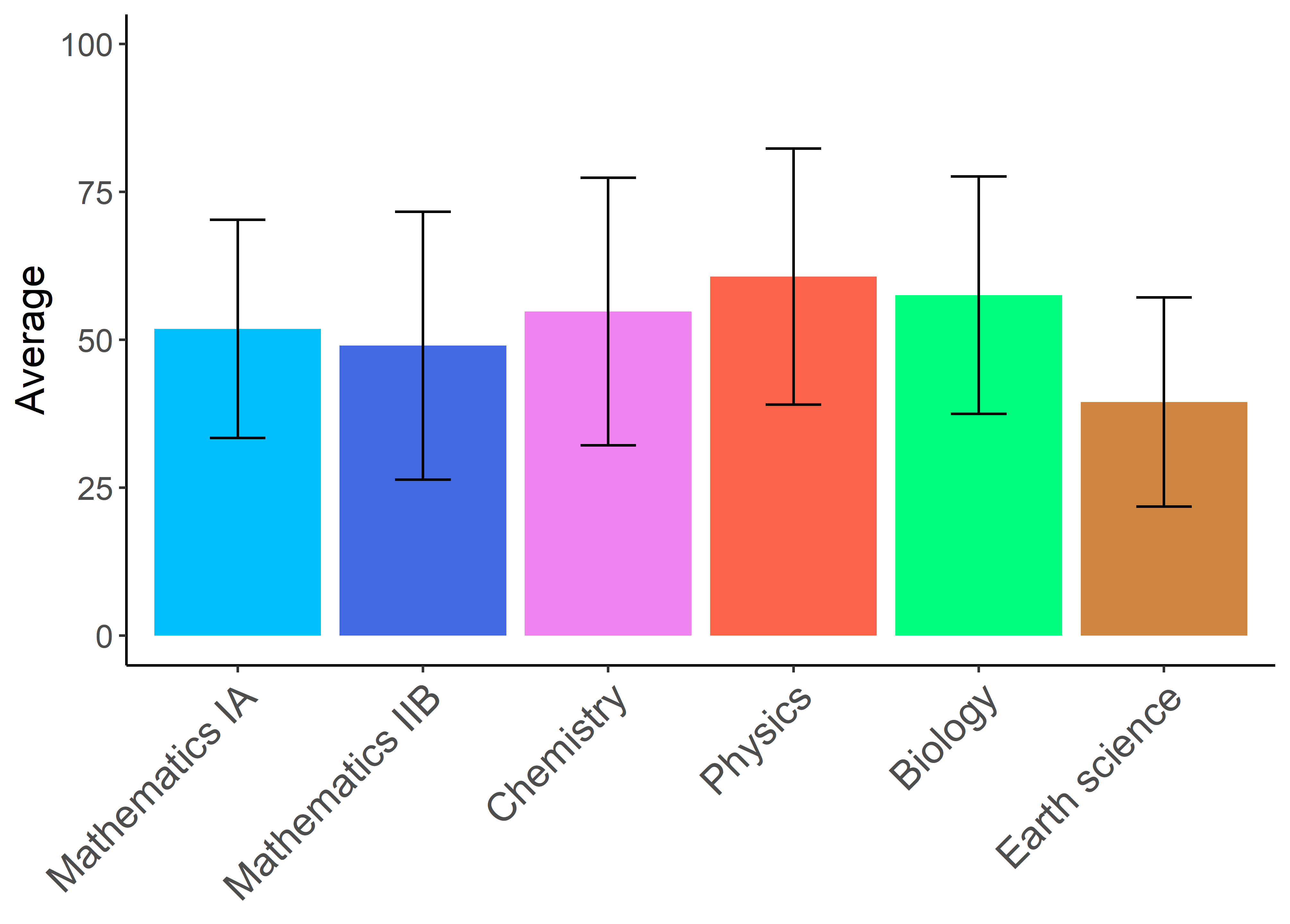
縦軸の間隔を20点ずつに変更してみましょう.先程も登場しましたがscale_x_continuousやscale_y_continuousで設定します.
g <- ggplot(df, aes(x = Subject, y = Average, fill = Subject)) +
geom_bar(stat = "identity") +
theme_classic() +
geom_errorbar(aes(ymin = Average - SD, ymax = Average + SD), width = 0.3) +
scale_fill_manual(values = c("deepskyblue1", "royalblue", "violet", "tomato1",
"springgreen1", "tan3")) +
theme(panel.grid = element_blank()) +
theme(axis.text = element_text(size = 12), axis.title = element_text(size = 15)) +
theme(axis.title.x = element_blank()) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 15)) +
guides(fill = F) +
scale_y_continuous(breaks = seq(0,100,20), limits = c(0,100)) #これ!!!!!!!!!!!!
plot(g)
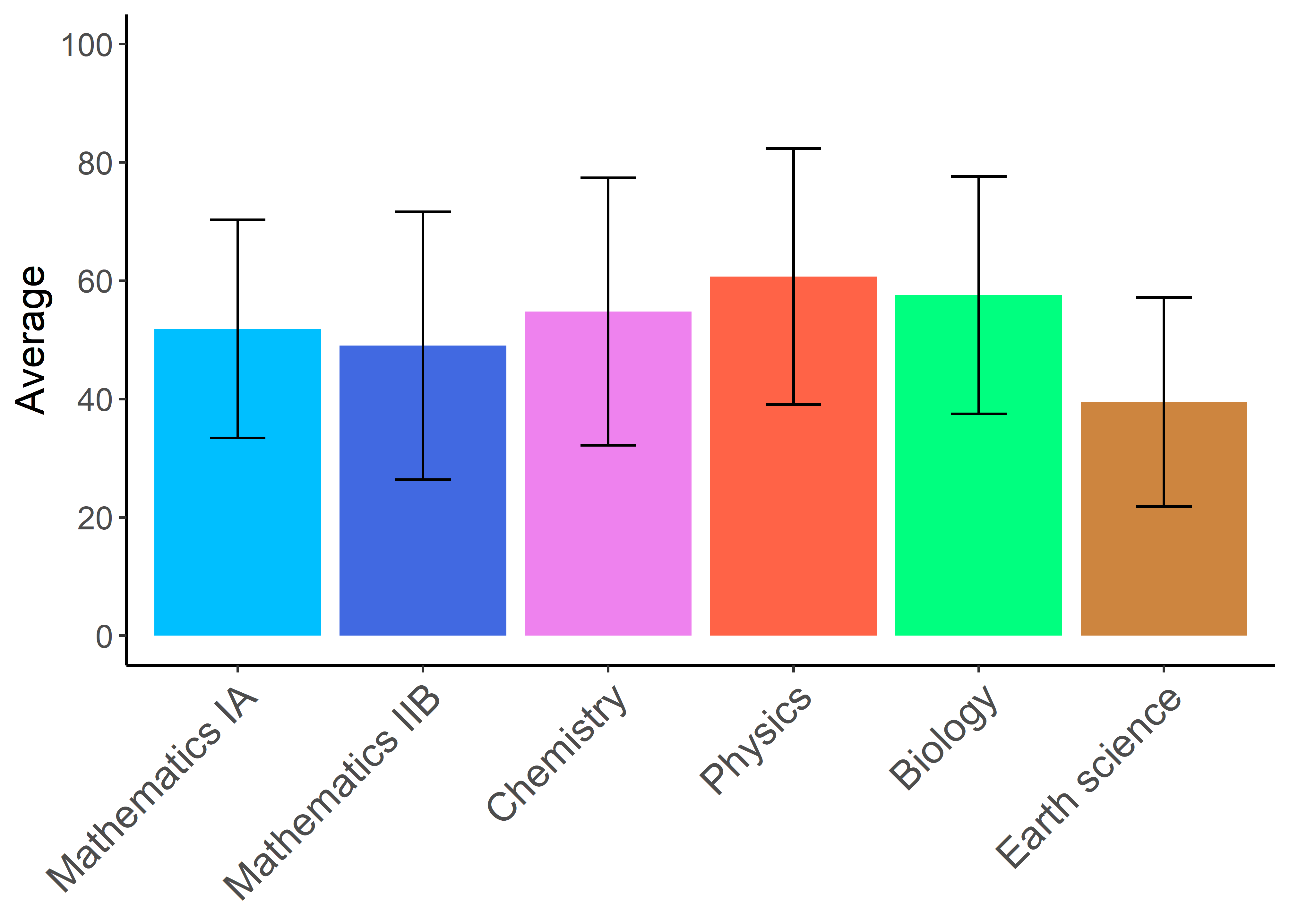
scale_y_continuousのbreaks引数に間隔としたいベクトルを指定します.そしてlimitsに軸の範囲を設定します.このとき先程のylim()を残しているとエラーを吐かれてしまいます.また,limitsを指定しないと軸の範囲が勝手に調整されてしまいますので注意です.
その他のグラフ
ここまでで概ねggplotの設定の仕方について説明しました.ここではその他のよくプロットするグラフを描くためのサンプルプログラムをおいておきます.データはデータサイエンス界隈ではおなじみのirisというRにすでに入っているものを使いましょう.3種類のアヤメの花の花びらとがくの長さと幅のデータです.各種類50個ずつの花のデータが収録されています.Rではirisという変数にすでに格納されているのでいきなり呼び出すことができます.以下にirisの頭だけ表示します.
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | setosa |
箱ひげ図
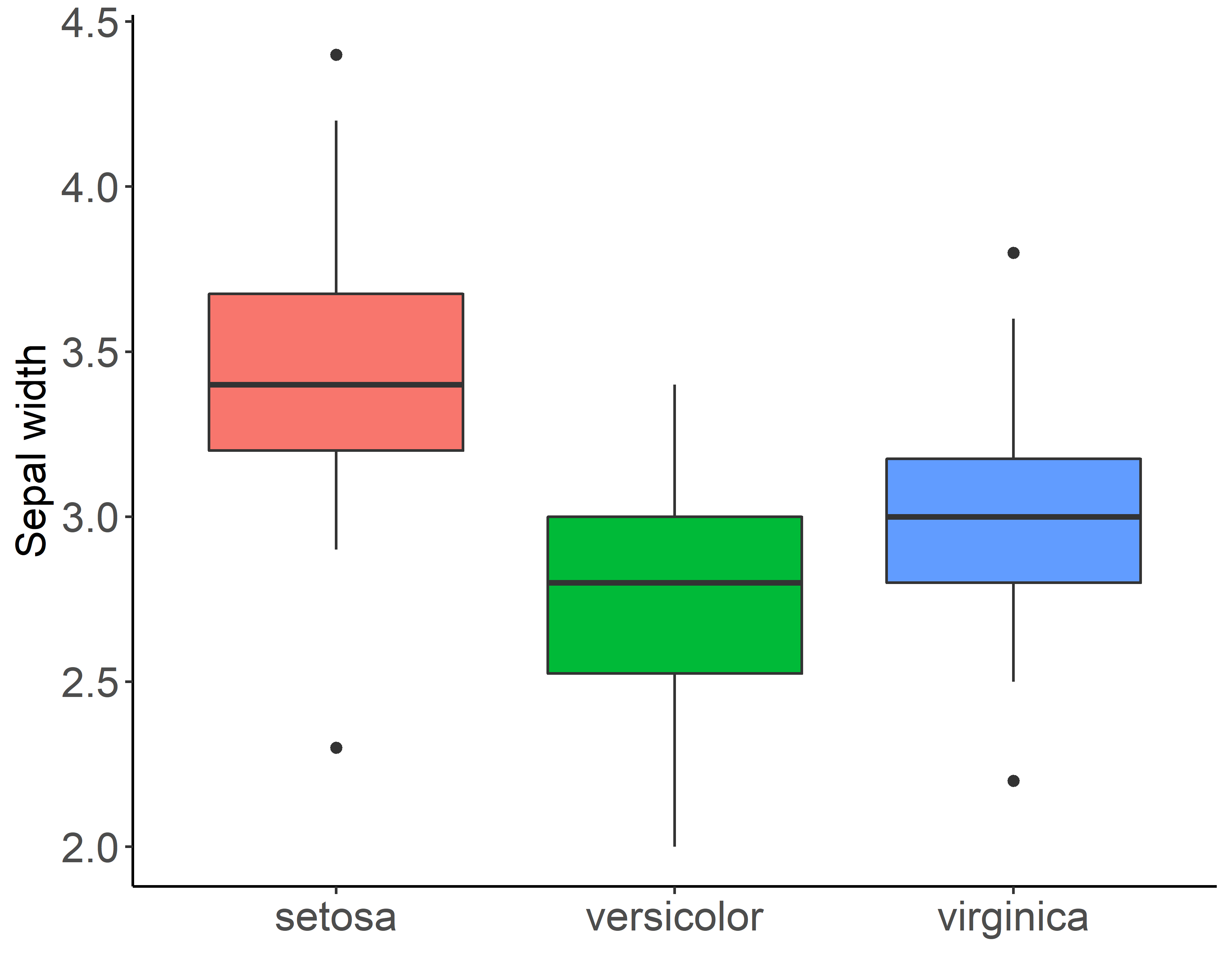
geom_boxplot()を使用します.
g <- ggplot(iris, aes(x = Species, y = Sepal.Width, fill = Species)) +
geom_boxplot() +
theme_classic() +
theme(axis.title.x = element_blank(), axis.title.y = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
guides(fill = F) +
ylab("Sepal width")
plot(g)
ヒストグラム
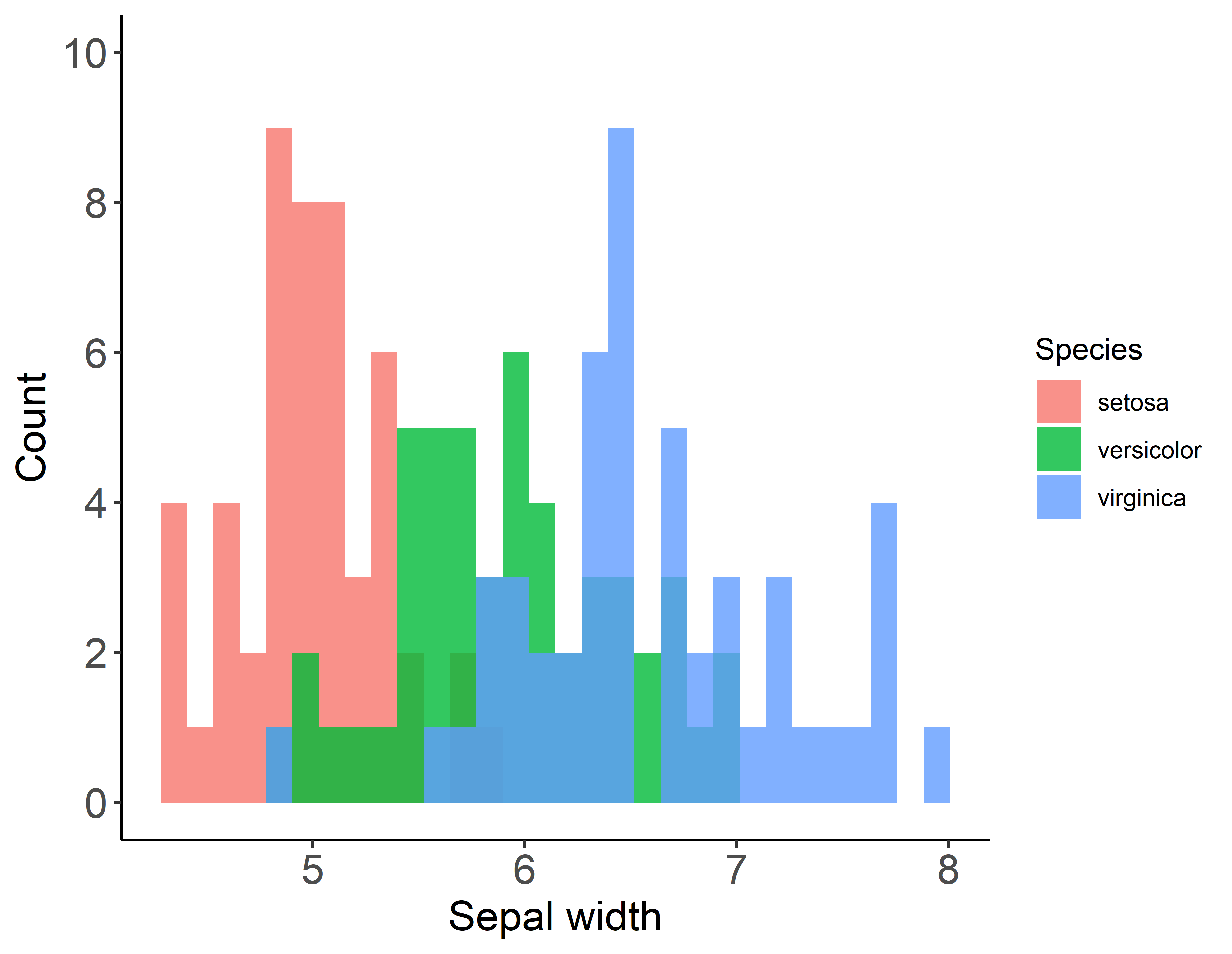
geom_histogram()を使用します.
g <- ggplot(iris, aes(x = Sepal.Length, fill = Species)) +
geom_histogram(position = "identity", alpha = 0.8) + #alphaは色の透過度.0~1で設定.
theme_classic() +
theme(axis.title.y = element_text(size = 15), axis.title.x = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
xlab("Sepal width") +
ylab("Count") +
scale_y_continuous(breaks = seq(0,10,2), limits = c(0,10))
plot(g)
binの数はgeom_histogram()のbinsで変えられます.デフォルトは30です.
g <- ggplot(iris, aes(x = Sepal.Length, fill = Species)) +
geom_histogram(position = "identity", alpha = 0.8, bins = 10) + #bins = 10
theme_classic() +
theme(axis.title.y = element_text(size = 15), axis.title.x = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
xlab("Sepal width") +
ylab("Count")
plot(g)
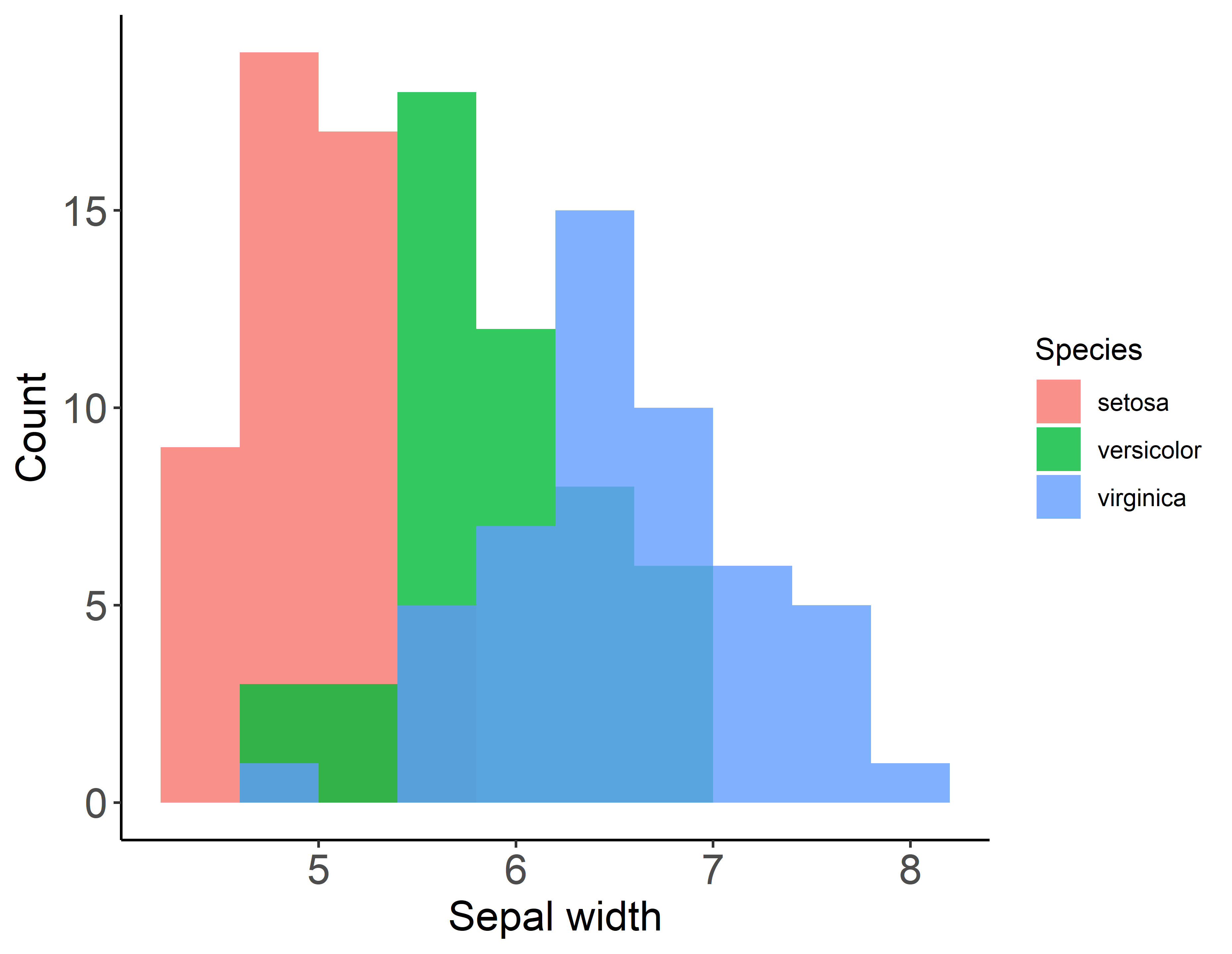
注意!! geom_histogram()にposition = "identity"をしてしないと以下のような積み上げ式グラフになってしまいます.
g <- ggplot(iris, aes(x = Sepal.Length, fill = Species)) +
geom_histogram(alpha = 0.8, color = "black") +
theme_classic() +
theme(axis.title.y = element_text(size = 15), axis.title.x = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
xlab("Sepal width") +
ylab("Count")
plot(g)
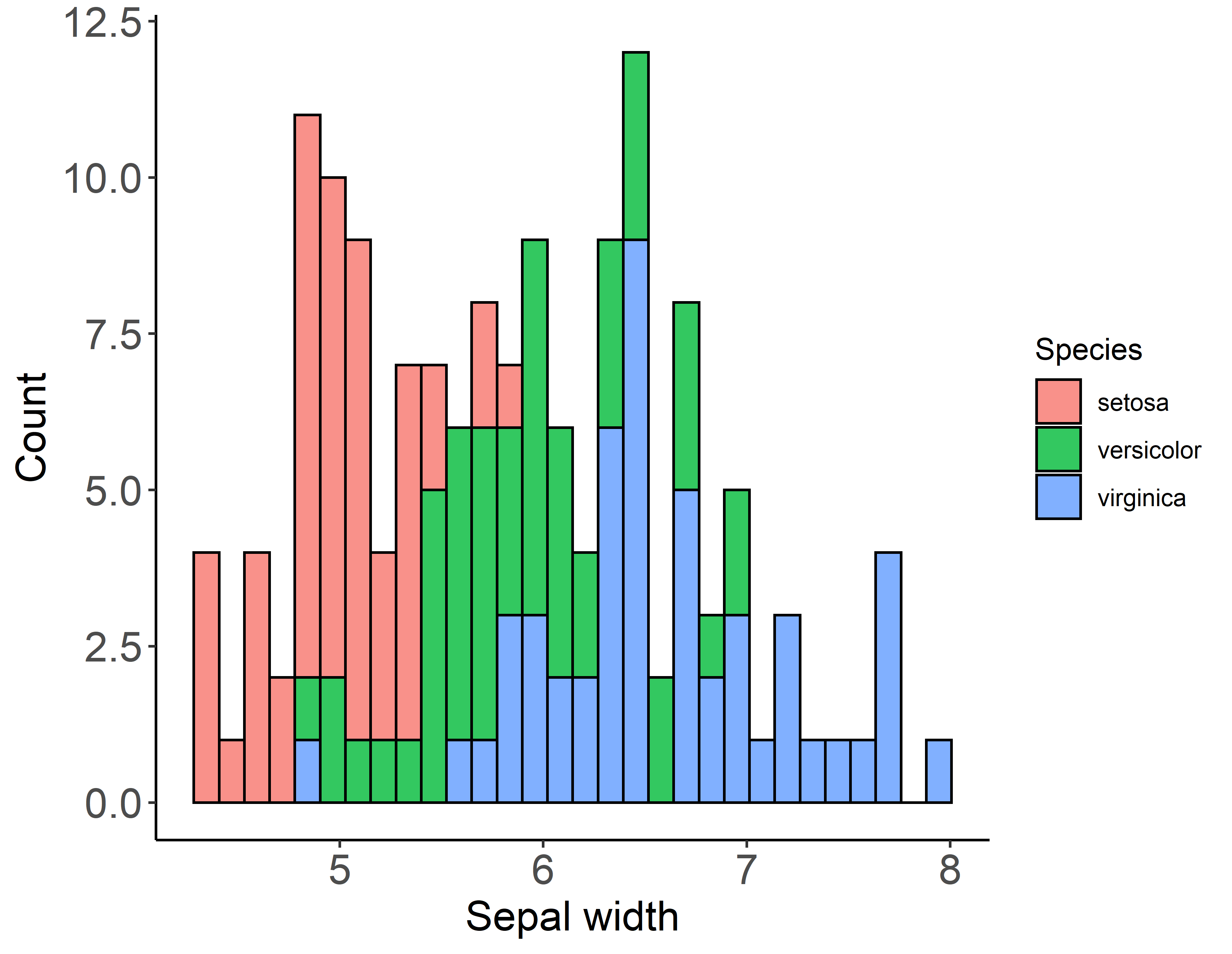
気づきにくいミスなので本当に注意してください.
確率密度曲線
geom_density()を使用します.
g <- ggplot(iris, aes(x = Sepal.Length, fill = Species)) +
geom_density() +
facet_wrap(~Species, ncol = 1) +
theme_classic() +
theme(axis.title.y = element_text(size = 15), axis.title.x = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
xlab("Sepal width") +
ylab("Density") +
guides(fill = F) +
theme(strip.background = element_blank(), strip.text = element_text(size = 15))
plot(g)
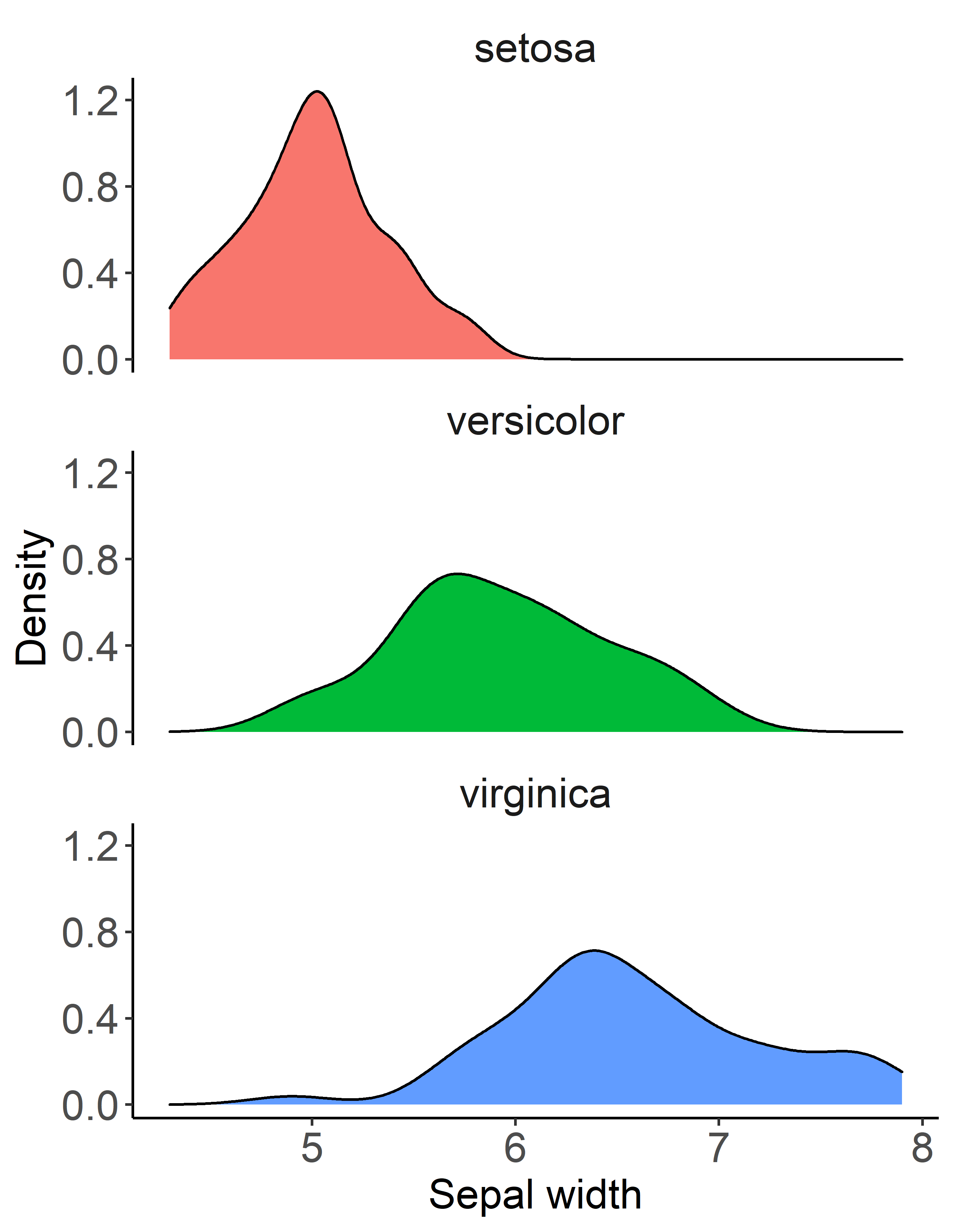
facet_wrap()を使って種ごとに分けてプロットしてみました.
実務的なサンプルプログラム
最後にggplotを使用して大量のデータの可視化を自動化するなど実務的なサンプルプログラムを書いてみます.ぜひ参考にしてみてくださいね.また,実際に動かすとプログラミングで業務の自動化をすることの感動を体験できると思います.
表データの項目別可視化
Breast Cancer Wisconsin (Diagnostic) Data Setをお借りします.このデータは良性腫瘍と悪性腫瘍のがん細胞の核の形の特徴量のデータです.1列目に検体のID,2列目に良性腫瘍か悪性腫瘍かのラベル("B" = 良性腫瘍,"M" = 悪性腫瘍),3列目以降に特徴量が格納されています.10種類の特徴量について平均値,標準誤差,最大値が順番に格納されていて計30列の項目があります.
以下のサンプルプログラムではこのデータから10種類の特徴量の平均値のみを取り出し,良性腫瘍群と悪性腫瘍群の分布をバイオリンプロットで可視化します.さらに各群での平均値をひし形の点で表示します.forループを使って10個のグラフを一気に出力します.
library(ggplot2)
data <- read.csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",
header = F)
attri <- c("ID", "Diagnosis", "Radius", "Texture", "Perimeter", "Area", "Smoothness",
"Compactness", "Concavity", "Concave_points", "Symmetry", "Fractal_dimension")
ext_data <- data[,c(1, 2, seq(3, 30, 3))]
colnames(ext_data) <- attri
ext_data_mean <- data.frame(Diagnosis = c("B", "M"))
B <- which(ext_data$Diagnosis == "B")
M <- which(ext_data$Diagnosis == "M")
for(i in 3:12) ext_data_mean <- cbind(ext_data_mean, c(mean(ext_data[B,i]), mean(ext_data[M,i])))
colnames(ext_data_mean)[2:11] <- colnames(ext_data)[3:12]
for(i in 3:12){
g <- ggplot(ext_data, aes(x = Diagnosis, y = ext_data[,i], fill = Diagnosis)) +
geom_violin() +
theme_classic() +
theme(axis.title.x = element_blank(), axis.title.y = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
guides(fill = F) +
scale_fill_manual(values = c("royalblue", "firebrick3")) +
ylab(gsub(x = colnames(ext_data)[i], pattern = "_", replacement = " "))
g <- g +
geom_point(data = ext_data_mean, aes(x = Diagnosis, y = ext_data_mean[,i-1]),
fill = "white", size = 3, shape = 23)
ggsave(plot = g, file = paste0("wdbc_plots/", colnames(ext_data)[i], ".png"), w = 6.2, h = 4.8, dpi = 600)
}
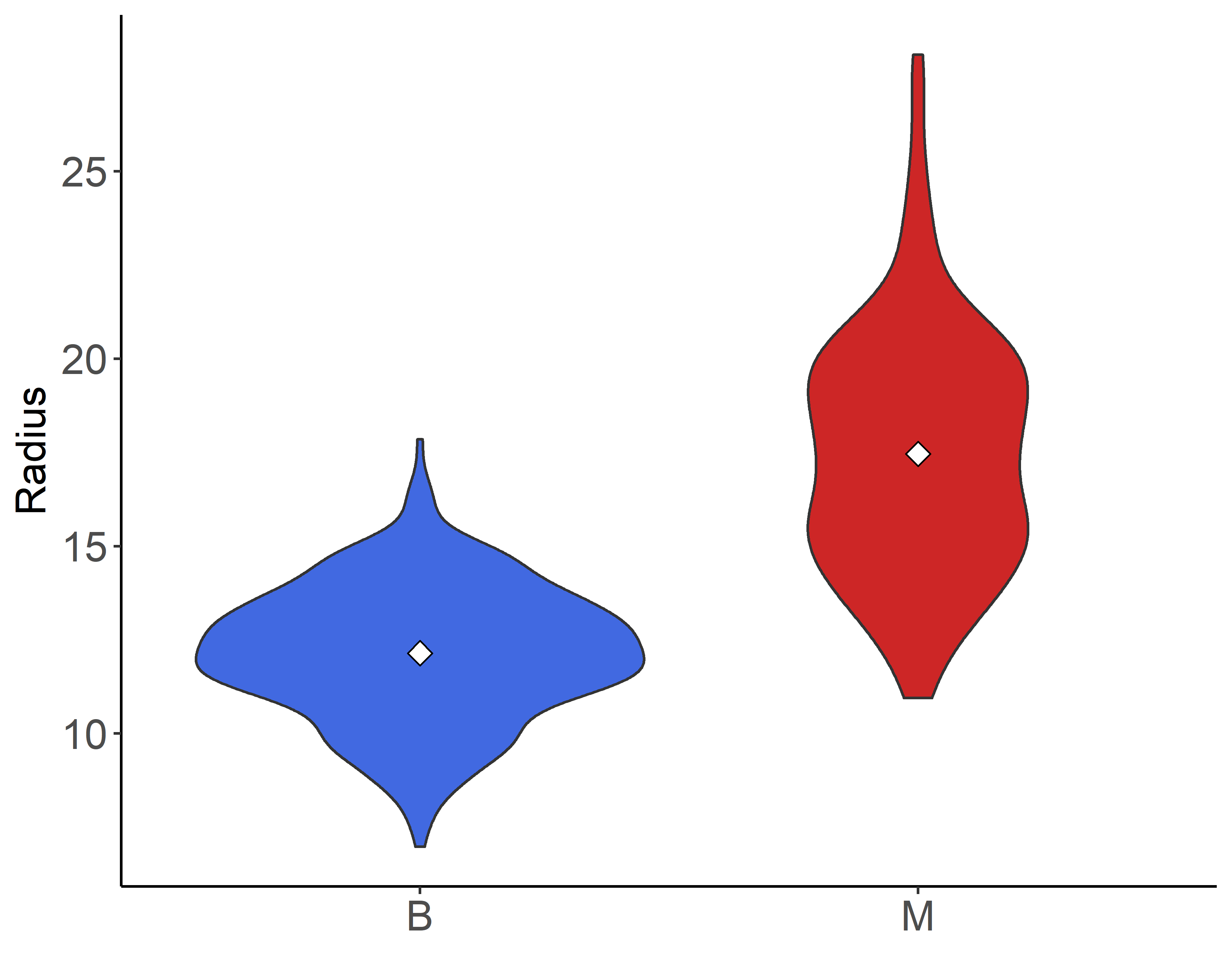
このプログラムを実行すると以下のようなバイオリンプロットが10種類の特徴量に対して一瞬で作成されます(実行するディレクトリの直下にwdbc_plotsという名前の空ディレクトリを作成しておいてください).
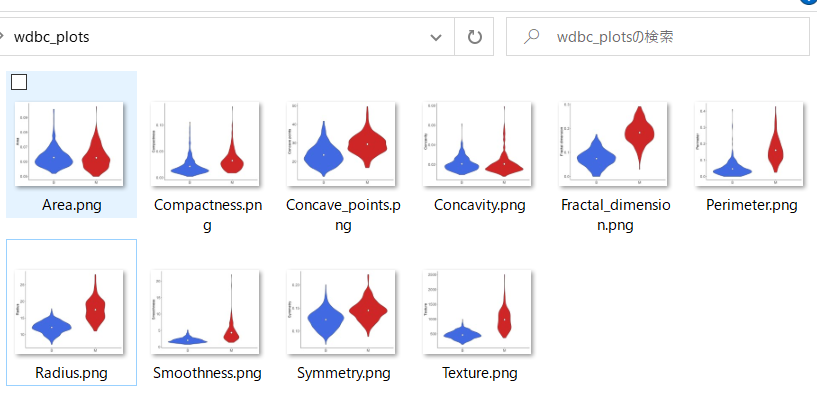
このように様々な項目について同じグラフをたくさんつくりたいときはforループを使うのが便利です.
ちなみに一つのPDFファイルにまとめたいときは
pdf("wdbc_plots.pdf", w = 6.2, h = 4.8) #PDFファイルを開く.
for(i in 3:12){
g <- ggplot(ext_data, aes(x = Diagnosis, y = ext_data[,i], fill = Diagnosis)) +
geom_violin() +
theme_classic() +
theme(axis.title.x = element_blank(), axis.title.y = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
guides(fill = F) +
scale_fill_manual(values = c("royalblue", "firebrick3")) +
ylab(gsub(x = colnames(ext_data)[i], pattern = "_", replacement = " "))
g <- g +
geom_point(data = ext_data_mean, aes(x = Diagnosis, y = ext_data_mean[,i-1]),
fill = "white", size = 3, shape = 23)
plot(g) #開いたPDFファイル内にプロットしていく.
}
dev.off() #PDFファイルを閉じる.
とすると作成できます.
さらに上級テクですがapply()などを使ってもっとスタイリッシュに書くこともできます!!
library(tidyverse)
data <- read.csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",
header = F)
attri <- c("ID", "Diagnosis", "Radius", "Texture", "Perimeter", "Area", "Smoothness",
"Compactness", "Concavity", "Concave_points", "Symmetry", "Fractal_dimension")
ext_data <- data[,c(1, 2, seq(3, 30, 3))]
colnames(ext_data) <- attri
ext_data_mean <- apply(ext_data[, 3:12], 2, function(x) tapply(x ,ext_data$Diagnosis, mean)) %>% as.data.frame()
ext_data_mean$Diagnosis <- rownames(ext_data_mean)
plot_violin <- function(obs){
g <- ggplot(ext_data, aes(x = Diagnosis, y = .data[[obs]], fill = Diagnosis)) +
geom_violin() +
theme_classic() +
theme(axis.title.x = element_blank(), axis.title.y = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
guides(fill = F) +
scale_fill_manual(values = c("royalblue", "firebrick3")) +
ylab(gsub(x = obs, pattern = "_", replacement = " "))
g <- g +
geom_point(data = ext_data_mean, aes(x = Diagnosis, y =.data[[obs]]),
fill = "white", size = 3, shape = 23)
ggsave(plot = g, file = paste0("wdbc_plots/", obs, ".png"), w = 6.2, h = 4.8, dpi = 600)
}
sapply(attri[3:12], plot_violin)
apply()の使い方はこちらの解説がわかりやすかったです.
2つの特徴量組の散布図を相関係数と一緒に出力する.
引き続きBreast Cancer Wisconsin (Diagnostic) Data Setを使います.
library(ggplot2)
data <- read.csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",
header = F)
attri <- c("ID", "Diagnosis", "Radius", "Texture", "Perimeter", "Area", "Smoothness",
"Compactness", "Concavity", "Concave_points", "Symmetry", "Fractal_dimension")
ext_data <- data[,c(1, 2, seq(3, 30, 3))]
colnames(ext_data) <- attri
for(i in 3:11){
for(j in (i+1):12){
r <- round(cor(ext_data[,i], ext_data[,j]), 2) #相関係数の計算
g <- ggplot(ext_data, aes(x = .data[[attri[i]]], y = .data[[attri[j]]], color = Diagnosis)) +
geom_point(alpha = 0.5) +
theme_classic() +
theme(axis.title.x = element_text(size = 15), axis.title.y = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
scale_color_manual(values = c("royalblue", "firebrick3")) +
xlab(gsub(x = attri[i], pattern = "_", replacement = " ")) +
ylab(gsub(x = attri[j], pattern = "_", replacement = " ")) +
ggtitle(paste0("r = ", r)) + #相関係数を表示
theme(plot.title = element_text(size = 15)) +
guides(alpha = F)
ggsave(plot = g, file = paste0("wdbc_plots_cor/", attri[i], "_vs_", attri[j], ".png"),
w = 6.2, h = 4.8, dpi = 600)
}
}
このプログラムを実行すると計45個の以下のような散布図が作成されます(実行するディレクトリの直下にwdbc_plots_corという名前の空ディレクトリを作成しておいてください).
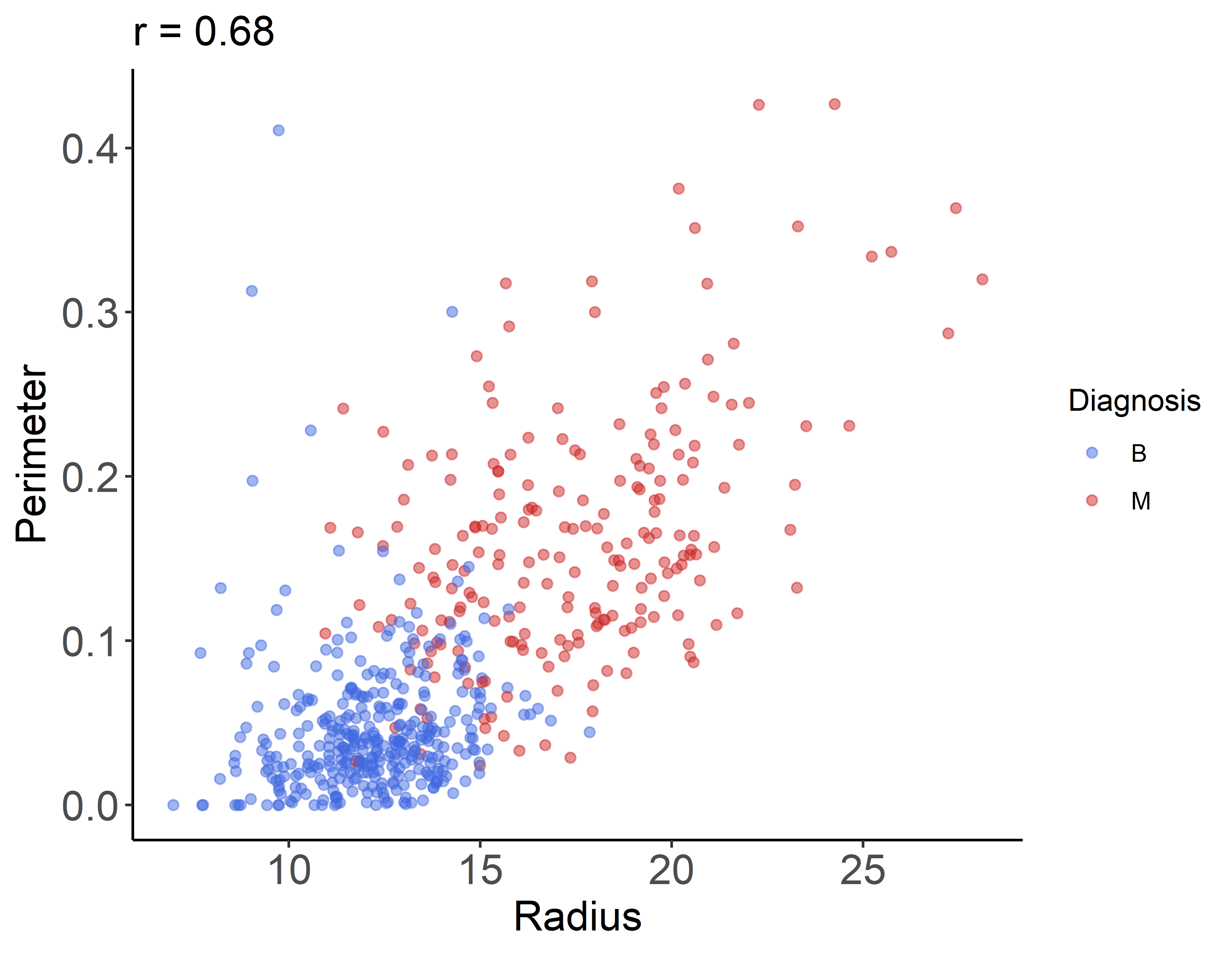
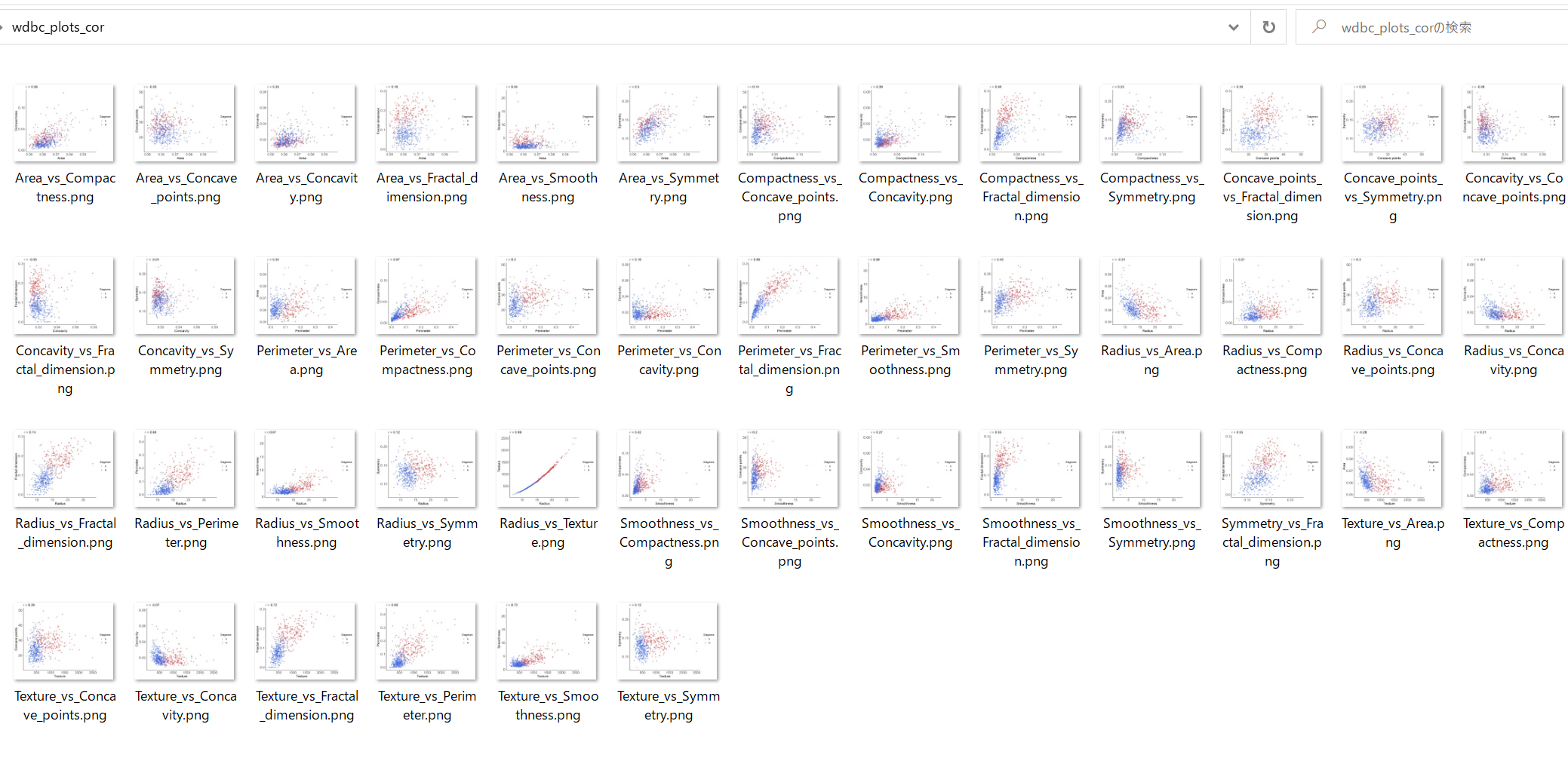
このスクリプトもapply()を使うと少しだけスタイリッシュになります.
library(tidyverse)
data <- read.csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data",
header = F)
attri <- c("ID", "Diagnosis", "Radius", "Texture", "Perimeter", "Area", "Smoothness",
"Compactness", "Concavity", "Concave_points", "Symmetry", "Fractal_dimension")
ext_data <- data[,c(1, 2, seq(3, 30, 3))]
colnames(ext_data) <- attri
attri_comb <- combn(attri[3:12], m = 2)
plot_cor <- function(obs){
r <- round(cor(ext_data[,obs[1]], ext_data[,obs[2]]), 2) #相関係数の計算
g <- ggplot(ext_data, aes(x = .data[[obs[1]]], y = .data[[obs[2]]], color = Diagnosis)) +
geom_point(alpha = 0.5) +
theme_classic() +
theme(axis.title.x = element_text(size = 15), axis.title.y = element_text(size = 15)) +
theme(axis.text = element_text(size = 15)) +
scale_color_manual(values = c("royalblue", "firebrick3")) +
xlab(gsub(x = obs[1], pattern = "_", replacement = " ")) +
ylab(gsub(x = obs[2], pattern = "_", replacement = " ")) +
ggtitle(paste0("r = ", r)) + #相関係数を表示
theme(plot.title = element_text(size = 15)) +
guides(alpha = F)
ggsave(plot = g, file = paste0("wdbc_plots_cor/", obs[1], "_vs_", obs[2], ".png"),
w = 6.2, h = 4.8, dpi = 600)
}
apply(attri_comb, 2, plot_cor)
さいごに
この記事ではggplot2の使い方をハマりどころを含め一通り説明いたしました.少しでもみなさんの研究やお仕事に役立つと嬉しいです.追加説明などご希望ございましたらコメントまでぜひお願いいたします!!!