こんにちは!データサイエンス系オタク会社員のroadricefieldです!本記事は私が社内有志で行っているRの勉強会の課題を第五回のものだけ公開したものです!
はじめに
第五回のテーマは自作関数でした.今回の課題は色々な処理をする関数をご自身で作っていただくものにしました.6問ありますが難易度は以下のようなイメージとなっています.
| 問題 | 難易度 | コメント |
|---|---|---|
| 第1問 | 8級 | 第五回の資料をご覧いただければできると思います. |
| 第2問 | 6級 | 少しややこしいですが落ち着いてテストをしながらやってみてください. |
| 第3問 | 5級 | 少しだけプログラミング的な発想が必要となります.実務ではまずはこれぐらいの処理が実装できるとかなり業務効率化につながると思います. |
| 第4問 | 3級 | 統計学への慣れも必要となります.数式の書き下しミスに気をつけてください. |
| 第5問 | 1級 | めちゃくちゃややこしいです.作問した私も数え間違いや勘違いで40分以上かかってしまいました...... |
| 第6問 | 2段 | これができた方がもしいらっしゃれば素晴らしいプログラミングスキルをお持ちかと思います!! |
第1~2問はすんなり取り組んでいただけるかと思います.第3問と第4問は少しプログラミングとしての工夫が必要になります.第5問と第6問は鬼です.正直実装できなくて実務上でお困りになることはこの会社ではほぼないかと思われます.
第1問
データの変動係数(標準偏差を平均で割ったもの)を求める関数CV()を作成してください.
例:
data <- c(15.464140, 15.906783, 13.549226, 5.936364, 17.483476, 14.304794, 5.702369, 1.217696, 12.138178, 15.374934)
> CV(data)
[1] 0.4663393
第2問
データを最小値0, 最大値1の範囲に正規化する関数zero_one_scale()を作成してください.
例:
data <- c(1, 3, 5, 8, 11)
> zero_one_scale(data)
[1] 0.0 0.2 0.4 0.7 1.0
最小値0, 最大値1の範囲に正規化の仕方に自信がない方は第一回課題の課題1のヒント2をご覧ください.
第3問
データの累積和を求める関数my_cumsum()を作成してください.配列 $a$ に対する $i$ 番目の累積和 $b_i$ は以下で定義されます.
b_i = \sum_{k=1}^{i} a_k
例えばa = c(1, 1, 1, 2)ならその累積和はb = c(1, 2, 3, 5)です.a = c(1, -1, 2, -2, 4, 3)ならその累積和はb = c(1, 0, 2, 0, 4, 7)です.
なお,Rにはすでに同じことを行うcumsum()という関数が用意されているので実際はこれを自作する必要はありません.
例:
a <- c(1, -1, 2, -2, 4, 3)
> my_cumsum(a)
[1] 1 0 2 0 4 7
上記の例でcumsum(a)も同じ結果になります.
第4問
標本の数と相関関係を引数に取って無相関の検定のp値を返す関数test_of_no_correlation()を作成してください.無相関の検定についてはこちらを参考にしてください.
もし母相関が0であった場合参考ページの統計量 $t$ は自由度 $n-2$ のt分布に従いますから,検定は計算された $t$ に対する自由度 $n-2$ のt分布の上側確率の2倍(両側検定)をp値とします.
Rではpt()という関数を用いてt分布の上側確率を求めることができます. 例えば自由度10のt分布の$t = 2.228$における上側確率は以下の様に得られます.
> pt(2.228, 10, lower = F)
[1] 0.02500589
この課題ではこれを使ってください.
例:
> test_of_no_correlation(N = 20, r = 0.246)
[1] 0.2957996
> test_of_no_correlation(N = 20, r = 0.446)
[1] 0.04872096
上記で出力されているのが検定のp値です.
第5問
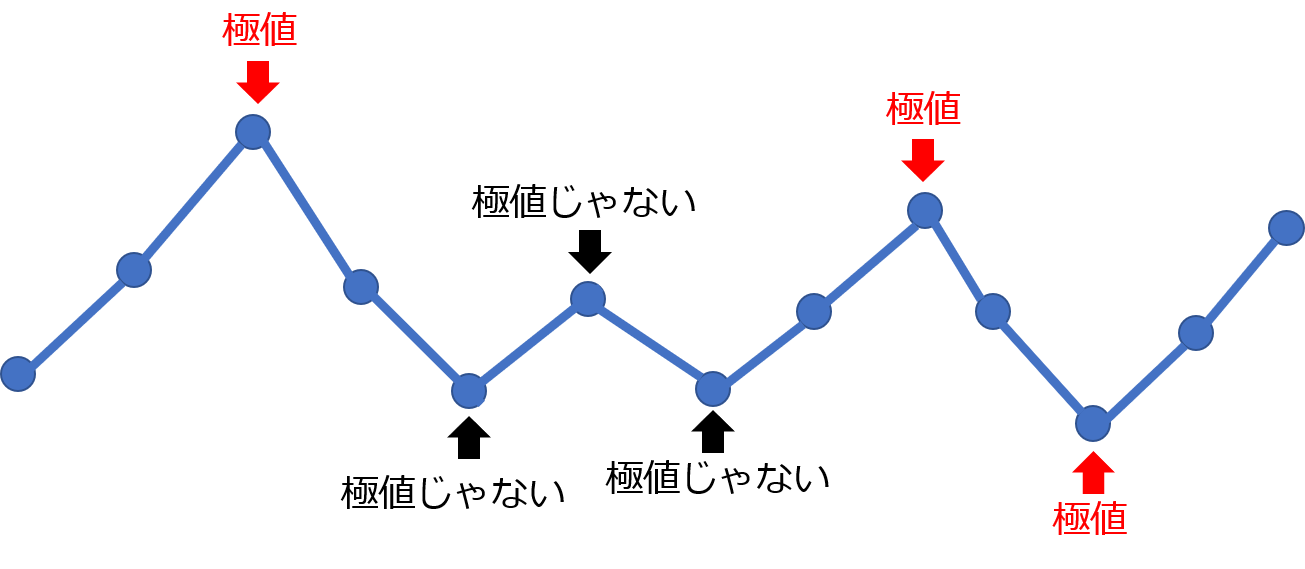
時系列データ $a$ が配列で与えられます.「極値」を以下の様に定義します.極値となるデータのインデックス(時刻)をすべて返す関数extremum_detector()を作成してください.
【極値の定義】
$a$ の連続する5つのデータ点,$a_t$, $a_{t+1}$, $a_{t+2}$, $a_{t+3}$, $a_{t+4}$について,
$a_{t+1} - a_t \geqq 0$ かつ $a_{t+2} - a_{t+1} \geqq 0$ かつ $a_{t+3} - a_{t+2} < 0$ かつ $a_{t+4} - a_{t+3} < 0$
または
$a_{t+1} - a_t < 0$ かつ $a_{t+2} - a_{t+1} < 0$ かつ $a_{t+3} - a_{t+2} \geqq 0$ かつ $a_{t+4} - a_{t+3} \geqq 0$
を満たすとき,$a_{t+2}$ を極値とし,$t+2$ を極値となるデータのインデックス(時刻)とする.
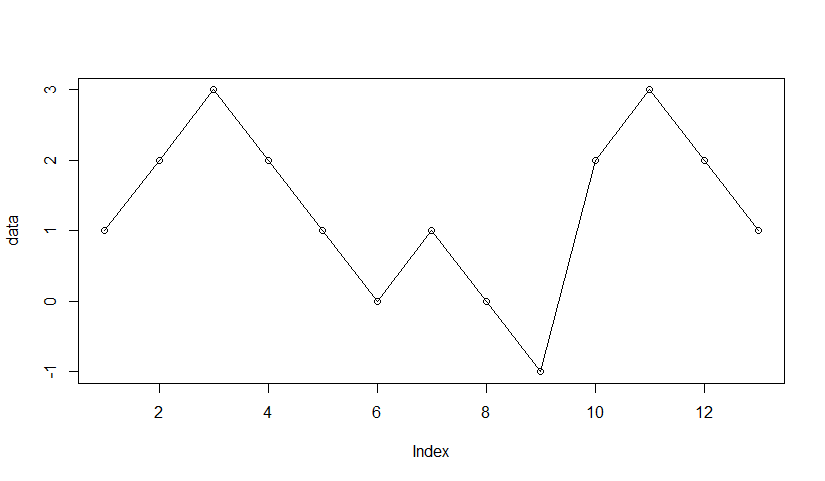
data <- c(1, 2, 3, 2, 1, 0, 1, 0, -1, 2, 3, 2, 1)
plot(data)
> extremum_detector(data)
[1] 3 9 11
第6問
k-meansクラスタリング法に基づくデータのクラス分けラベルを返す関数my_kmeans()を作成してください.
k-meansクラスタリング法自体は以下のよびノリたくみさんの動画にて確認してください.
今回は実装を簡単にするために以下の制約を設けます.
【制約】
与えられるデータは二次元(x, y)でx, yどちらも最小値1,最大値100の整数値である.また,長さは必ず50である.具体的には以下のスクリプトで与えられるx_sampleとy_sampleとする.
x_sample <- sample(1:100, 50, replace = FALSE)
y_sample <- sample(1:100, 50, replace = FALSE)
sample()は1つ目の引数に与えた配列から2つ目の引数に与えた数だけ復元抽出する関数です.オプションで非復元抽出にもできます.
(2022/7/25修正)すみません,デフォルトは非復元抽出でした.ちゃんと分かるようにオプションを明示しました.ほんとは復元抽出にしたかった.......
データ間の距離はユークリッド距離 $d = \sqrt{x^2+y^2} $ とします.作成するmy_kmeans()は引数にx, y, kを取り,kがクラスターの数とします.つまり分類するクラスター数を都度変えることが可能な関数を作成してください.
例:
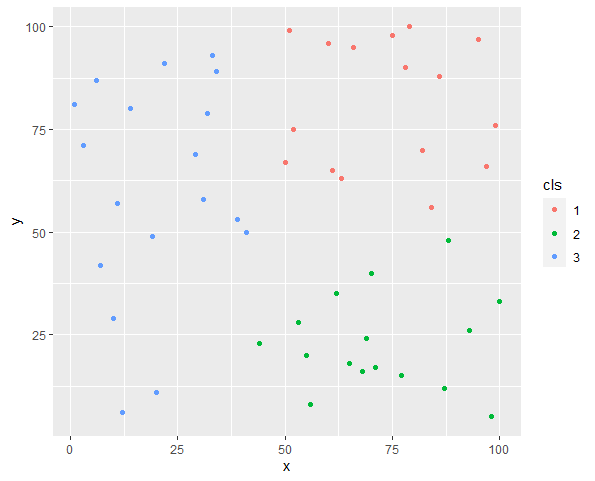
set.seed(2022)
x_sample <- sample(1:100, 50)
y_sample <- sample(1:100, 50)
cls <- my_kmeans(x = x_sample, y = y_sample, k = 3)
> print(cls)
[1] "2" "1" "1" "2" "1" "2" "3" "1" "2" "3" "3" "1" "1" "2" "3" "1" "3" "2" "3" "3" "1" "1" "2" "2" "2" "3" "2" "3" "3" "2" "3" "1"
[33] "1" "1" "3" "3" "3" "3" "3" "2" "2" "2" "2" "1" "3" "1" "2" "1" "1" "3"
df <- data.frame(x = x_sample, y = y_sample, cls = cls)
g <- ggplot(df, aes(x = x, y = y, color = cls)) +
geom_point()
plot(g)
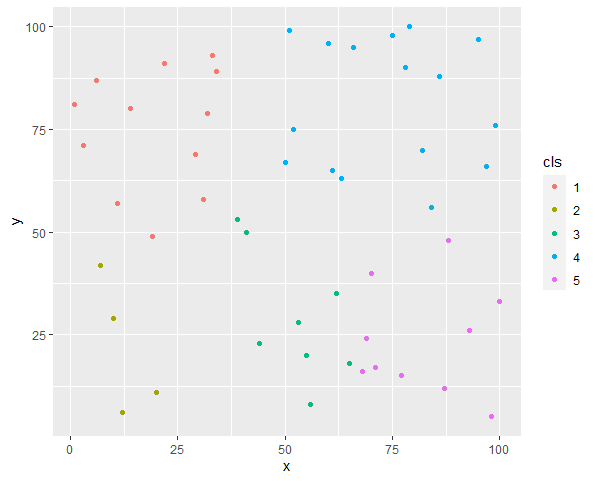
set.seed(2022)
x_sample <- sample(1:100, 50)
y_sample <- sample(1:100, 50)
cls <- my_kmeans(x = x_sample, y = y_sample, k = 5)
df <- data.frame(x = x_sample, y = y_sample, cls = cls)
g <- ggplot(df, aes(x = x, y = y, color = cls)) +
geom_point()
plot(g)
set.seed()は乱数シードを固定する関数で乱数がからむ処理の前にこれを同じ引数で実行すれば毎回同じ乱数が得られます.みなさんの手元でも私と同じ乱数が得られます.
なお,Rにはもとからkmeans()という関数が用意されているのでこれをわざわざ一生懸命実装する必要はありません.しかしとても練習になると思います.
解答例&解説(作成中)
こちらに解答例と解説を掲載する予定です.ひとまず私が作成した解答例スクリプトのみ取り急ぎ貼っておきます.