(*この記事はバスケのデータでベイズ統計モデリングを改稿したものです)
はじめに
はじめまして、らんそうるいと申します。私はバスケットボールのデータを使って統計学の勉強をしています。この記事では、バスケのデータに対して、一般化線形混合モデル(GLMM)を立てたいと思います。テーマは、バスケ選手のポジションとオフェンスリバウンド獲得数の関連を調べることです。
ポジションとオフェンスリバウンド
バスケットボールに詳しくない方もおられるので、簡単にポジションとオフェンスリバウンドについて説明します。
バスケは身長によってプレイするエリアがだいたい決まる競技特性があります。日本のプロバスケットボールリーグ(Bリーグ)では、180cm程度の選手はガード(G)を務めており、ゴールから離れた場所でプレイします。200cm程度の選手はビッグマン(B)と呼ばれ、ゴールの近くでプレイします。その中間、190cm程度の選手はウイング(W)で、ゴールの近くでも離れた場所でもプレイします。以上が簡単なポジションに関する説明です。
次にオフェンスリバウンドについて説明します。バスケではシュートを失敗した後にボールを回収するプレイのことをリバウンドと呼びます。リバウンドの中でも、攻撃側の選手が再びボールを回収するプレイがオフェンスリバウンドです。オフェンスリバウンドはゴールの近くでプレイする選手ほど獲得しやすい傾向があります。
以上のことをまとめると、ポジションによってオフェンスリバウンドの獲得数は変化し、その獲得数はB>W>Gの順番になることが多いです。
この傾向はバスケットボールを知っている方なら予想がつくことで、わざわざGLMMを立てて検証するまでもないテーマです。しかし、今回は統計モデリングの練習ということで、あえて結果が分かりやすいテーマを選択しました。
データの概要
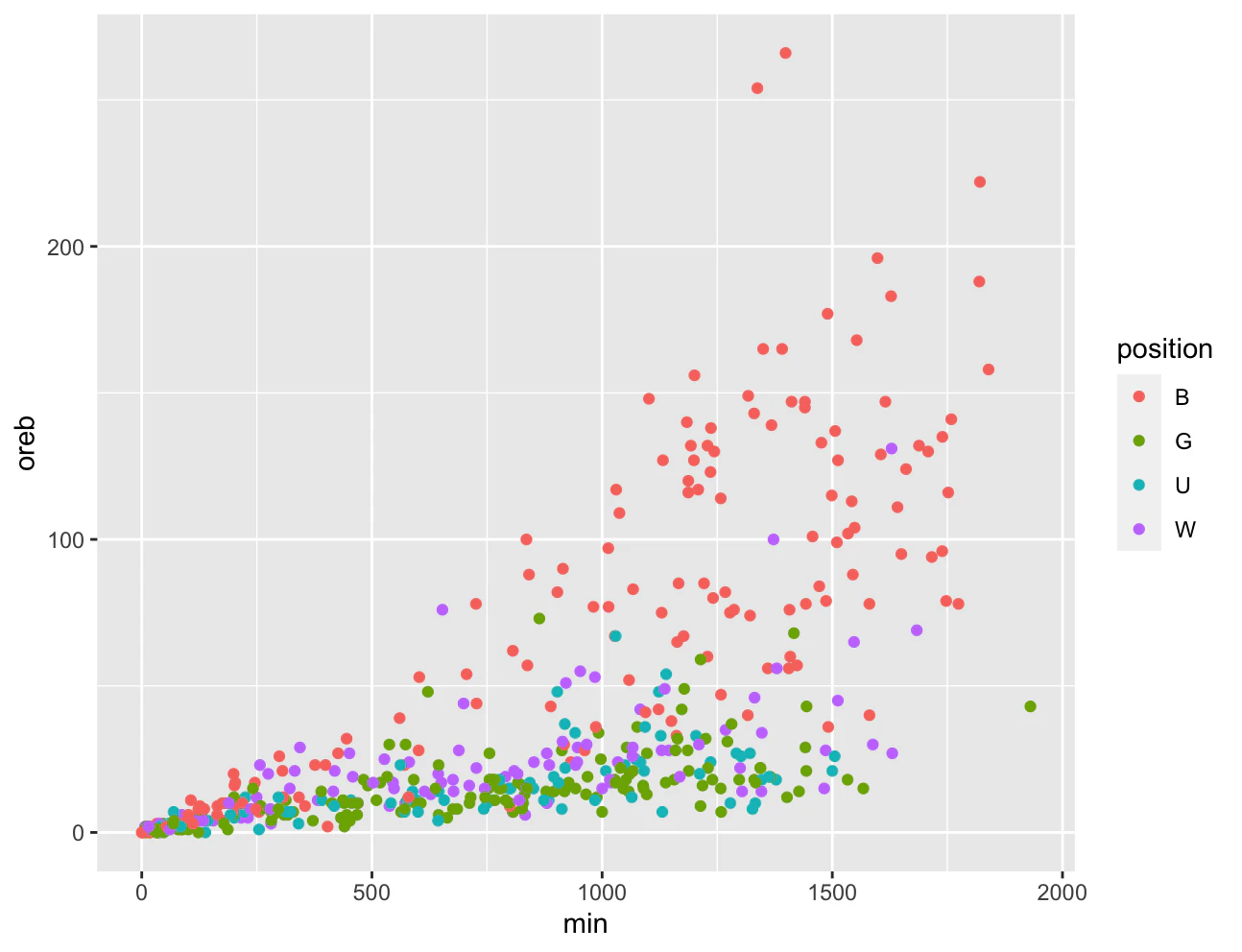
オフェンスリバウンドは出場時間が長いほど記録しやすいプレイです。縦軸にオフェンスリバウンド獲得数・横軸に出場時間をとり、散布図を描いた図は以下のようになります。点の色はポジションを表しています。ポジションUはポジションが不明な選手たちです。データはBリーグの1部リーグ(B1)と2部リーグ(B2)の2021-22シーズンです。
散布図を確認すると、Bは上側に位置する選手が多いことや、出場時間が長いほどオフェンスリバウンド獲得数が多くなることが分かります。
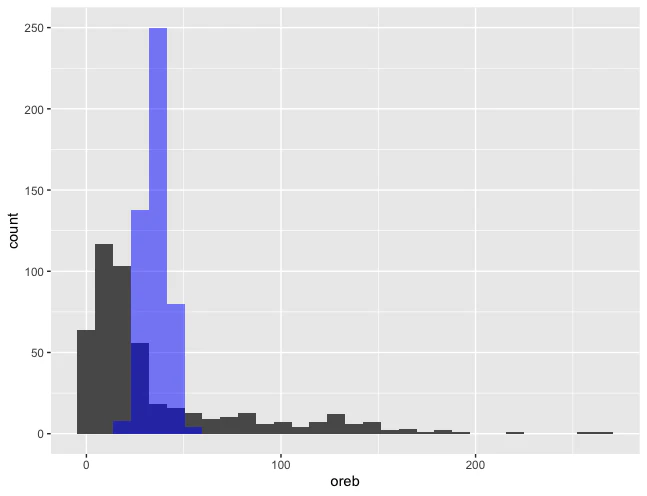
オフェンスリバウンド獲得数のヒストグラム(灰色)は以下のようになります。ヒストグラムを描写することで被説明変数の分布を確認することは、GLMMに使用する確率分布を選択するために有用です。灰色のヒストグラムを確認するとオフェンスリバウンド獲得数は0以上の値をとり、右に裾が長い分布をしていることが分かります。つまり、頻繁に使用される正規分布は当てはまりが悪いです。
非負で右に裾が長い確率分布にはいくつか選択肢があります。この記事では、ポアソン分布を使いたいと思います。ポアソン分布のパラメタを適切に設定した上で、選手数と同じ数だけ乱数を発生させ、ヒストグラム(青色)を重ねてみました。
青色のヒストグラム(ポアソン分布)に比べて、灰色のヒストグラムの方が、データのばらつきが大きいことが分かります。これは過分散と呼ばれています。過分散が生じる原因の一つは、考慮していないデータによる個人差があるためです。そこで、選手の個人差を考慮するために、ランダム切片をモデルに投入することにしました。
モデリング
方針
GLMMは確率分布、リンク関数、線形予測子から構成されます。
確率分布としてポアソン分布、リンク関数として対数リンク関数、線形予測子として選手のポジション(G、W、B、U)を表すダミー変数を3つ、出場時間のlogをオフセット項、ランダム切片を設定しました。ランダム切片は平均0・分散sigma_rに従うと仮定し、sigma_rの超事前分布としてstanのデフォルトである一様分布を使用しました。
stanによる実装
data{
int N;
int X_B[N];
int X_W[N];
int X_U[N];
int Y[N];
real MIN[N];
}
parameters{
real a;
real b_b;
real b_w;
real b_u;
real r[N];
real sigma_r;
}
transformed parameters{
real lambda[N];
for(n in 1:N){
lambda[n]=a+b_b*X_B[n]+b_w*X_W[n]+b_u*X_U[n]+log(MIN[n]+0.01)+r[n];
}
}
model{
r~normal(0,sigma_r);
Y~poisson_log(lambda);
}
generated quantities{
real Y_pred[N];
Y_pred=poisson_log_rng(lambda);
}
MCMCの設定と収束診断
MCMCの設定は次の通りです。
- chain数=4
- iteration数=4000
- burn-in=2000
全てのパラメタのR hatが1.1未満であったため、収束していると判断しました。
図によるモデルのチェック
GLMMの当てはまりを確認するために、2つの図を描写しました。いずれの図からもGLMMの当てはまりは良好であると判断しました。
まず、予測値(pred)と観測値(observed)の散布図を紹介します。予測値と観測値は一直線上に並んでおり、モデルの当てはまりが良いことが分かります。

次に、予測値(pred_median)の対数と残差(residual:観測値から予測値を引いた値)をプロットしたのが下の図です。このプロットは予測値vs.残差プロットと呼ばれており、残差=0を中心に上下左右均等にデータが散らばっている図の時に当てはまりがよいと解釈します。実際、今回のプロットはそのようになっており、モデルの当てはまりは良いと判断しました。
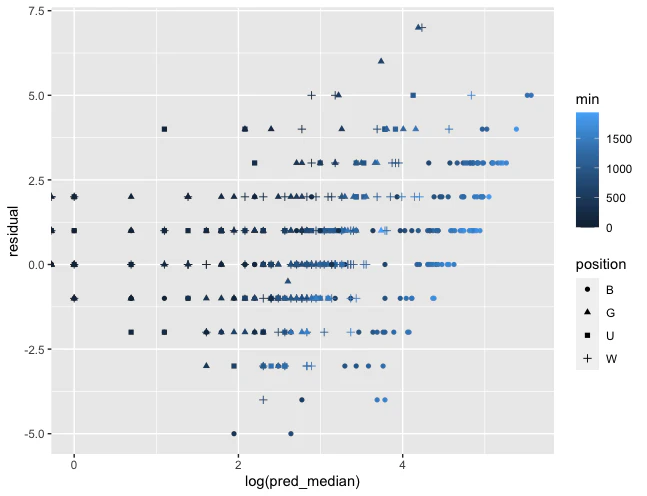
モデルの当てはまりに問題がないことが確認できたので、モデルの考察に進みたいと思います。
モデルの考察(ポジションとオフェンスリバウンドの関連)
モデルのダミー変数の回帰係数の確率密度を示したのが下のヴァイオリンプロットです。ヴァイオリンプロットは膨らんでいる部分の値が発生しやすいことを意味しています。
下のヴァイオリンプロットでは、Gが基準であり、0の影響を持っていると解釈します。Gに比べて、Wはexp(0.39)=1.47倍のオフェンスリバウンドを獲得していることが分かります。また、Bはexp(1.21)=3.35倍のオフェンスリバウンドを獲得していることが分かりました。
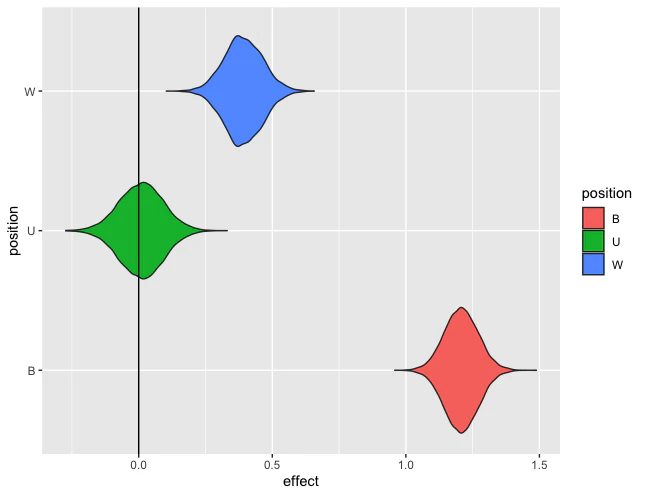
以上の結果は、バスケットボールの常識に沿ったものであると言えます。
まとめ
この記事では、バスケのデータに対してGLMMを立て、ポジションとオフェンスリバウンド獲得数の関係を調べました。その結果、ゴールの近くでプレイしているポジションほどオフェンスリバウンド獲得数が多くなるという、バスケの常識に沿った結果が得られました。
参考文献
久保拓弥, 2012. データ解析のための統計モデリング入門.
馬場真哉, 2019. RとStanではじめる ベイズ統計モデリングによるデータ分析入門.
松浦健太郎, 2016. StanとRでベイズ統計モデリング.