AWS OpenSearch Serverless が、先月 Preview 版として利用可能になったので試してみた記事です。
アナウンス:
対象とする読者(と僕)は、文書検索とかなんもしらん程度のRailsエンジニアです。
OpenSearch とは
Elastic 社が、フリーライダーP(I)aaSにキレてライセンスを変更したため、
Elastic製品(の新しいバージョン)をサードパーティが製品そのものをサービスとして提供できなくなりました。
このライセンス変更に反対した開発者を中心に、Elasticsearch と Kibana をフォークして、より自由に利用できるようにしたソフトウェア群が OpenSearch です。
Amazon OpenSearch Service は、その OpenSearch をマネージドサービスとしてAWSが提供しているものです。
Amazon OpenSearch Service Serverless とは
マネージドサービスで提供されていた AOS をサーバーレスにしたものです。
( マネージドとサーバーレスの概念的な違いについては、 GCPのこちらのポスト がわかりやすい )
AOSについていえば、
マネージドサービスでは:
- インスタンスのスペックや種類を指定する必要がある
- クラスター構成を指定する必要がある
- インスタンスの稼働時間毎の課金
サーバーレスでは:
- インスタンスやクラスター構成について考える必要がない
- 使用したリソース(OCU)毎の課金
という違いがあります。
個人的な感覚として、これらの違いについてざっくり解釈すると
使用したリソース(OCU) というのがわかりづらく、最終的な課金額が予想しづらい(ただし最大額は指定できる)というデメリットさえのめれば、サーバーについて考える必要がないServerlessは相当に便利だと考えています。
ハンズオン
さて、座学はこのぐらいにして、ハンズオンタイムです。
セットアップ
Create Collection で適当なCollectionを作ります。
Collectionとは、RDBでいうところのデータベースに当たるものと解釈すると(詳しい人からは叩かれるかもしれませんがアナロジーとしては機能するとおもうので!)よいとおもいます。
RDBのデータベースとCollectionの何が共通しているかというと、どちらも文書群の群であるという点です。
後に登場しますが、この"文書群"の名前は、OpenSeachでは index といいます。(RDBでいうところの"テーブル"にあたります; 詳しい人からは叩かれるかもしれませんが)
概念対応表
| RDB | AOSS |
|---|---|
| データベース | Collection |
| テーブル | index |
| レコード | Document |
さて、今回は Collection Type はSearch にしました。
Collection の作成には数分かかります。
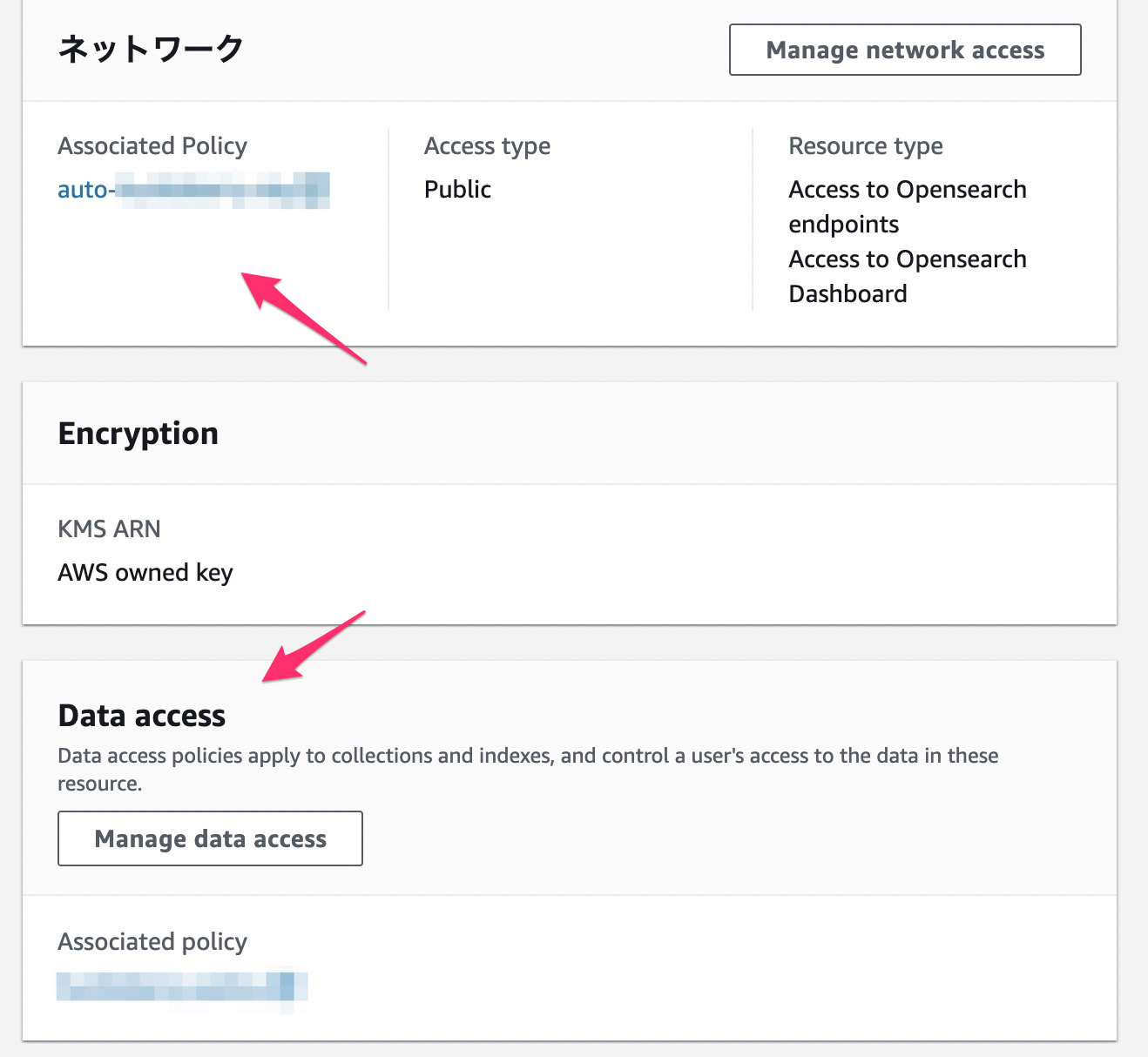
Collection が作られたら、いい感じのネットワークの設定と、いい感じのDataアクセスの設定をして、とにかく自分のIAMで全ての権限を持つように設定します。
ダッシュボードでのデモ
AOSSにはダッシュボードが標準搭載されています。(KibanaのOpensearch版です。)
ダッシュボードでは、データを可視化したり、APIリクエストのテストをすることができます。
コレクションを作成するごとに、ダッシュボードURLが自動で発行されるので、利用するのに特別な追加的な手順は必要ありません。
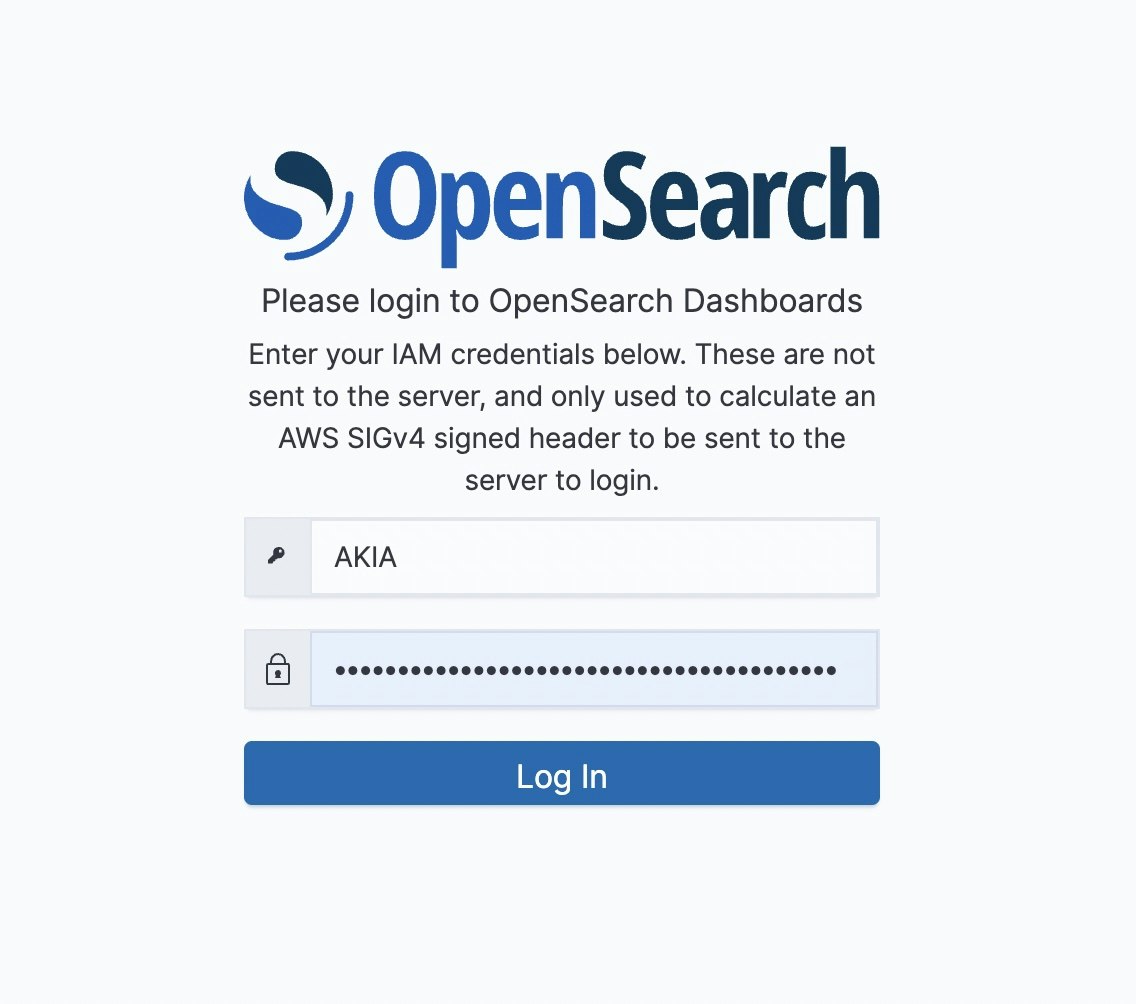
発行されたダッシュボードのURLにアクセスすると、ログイン画面が表示されます。適切なIAMのアクセスキーとシークレットキーを渡すと入れます。
初回ログインすると、AWSの用意したダミーデータを作成してダッシュボードを試すか? などの事細かなチュートリアルが提示されます。(が、説明書を読まないタイプなのでスキップしてしまったし、詳細は知りません)
Dev Tools に遷移すると、 Web UI 上でクエリを試すことができます。非常に便利です。
できること(API)の一覧はここに記載があります。
https://opensearch.org/docs/1.0/opensearch/rest-api/index/
ただし、サーバーレスの特性上一部のAPIは利用できません。例えば、クラスターに関するものとか。
上記に例示したように、この Web コンソール上では、
<HTTP Method> <Path>
<Parameters>
の形で記述します。
たとえば、
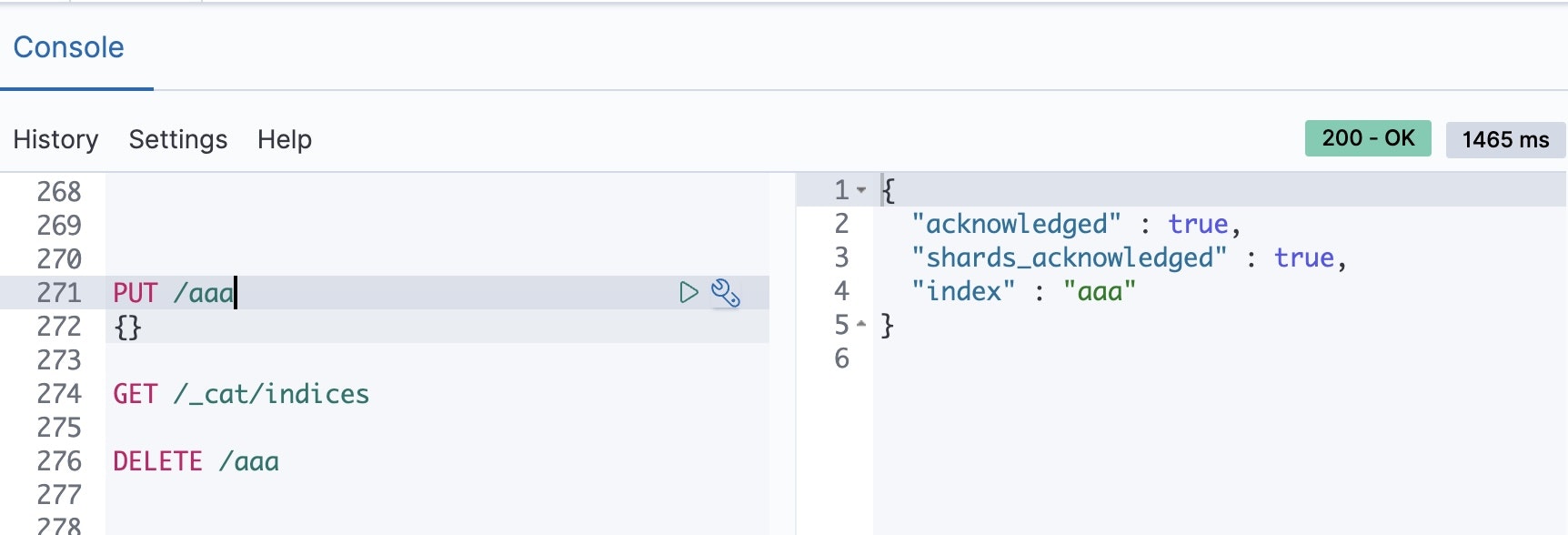
indexを作る
ここでは aaa という名前の index を新たに作っています。 (復習: index とは、 RDB でいうところのテーブルです。データベース = Collection の下位の概念であり、 レコード = Document を複数保持する塊であるという観点で。)
parameterは空です。(本当は、analyzerやmapping等設定項目が膨大に存在しますが、無視してとりあえず進めます。)
https://opensearch.org/docs/1.0/opensearch/rest-api/create-index/
PUT /aaa
{}
すでに作った index の一覧は、
GET /_cat/indices
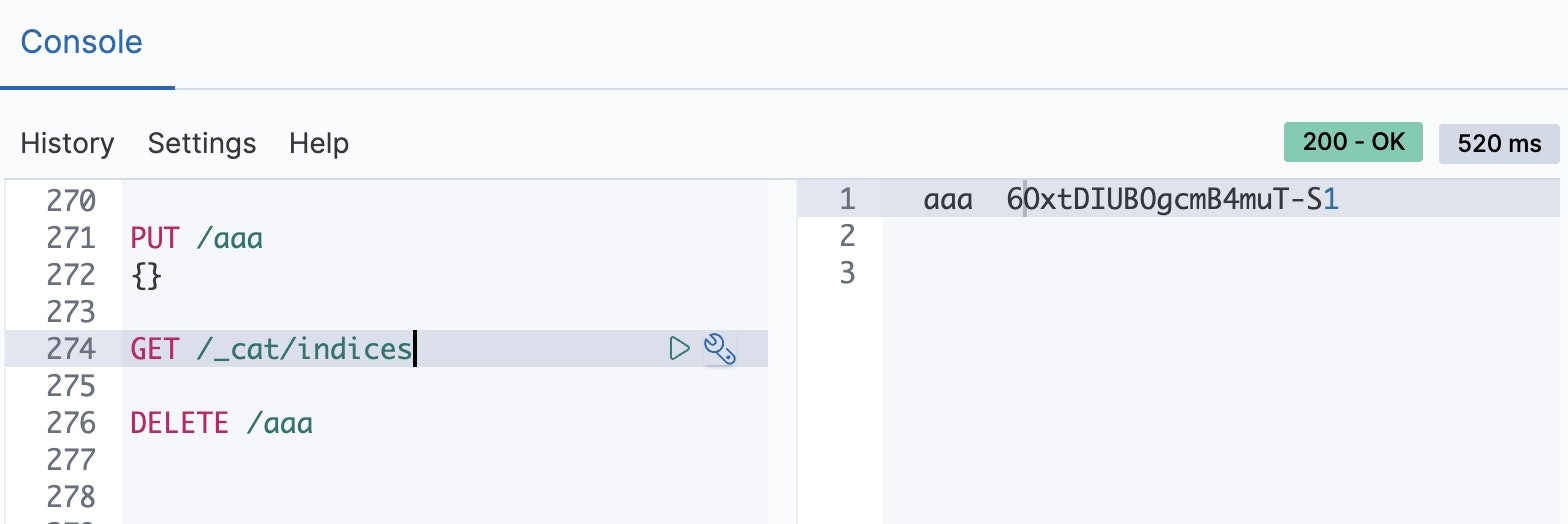
で確認できます。
https://opensearch.org/docs/1.0/opensearch/rest-api/cat/cat-indices/
(index の複数形がindeces なの、マジ!?って感じがしますよね。)
インデックスの用意ができたら、実際に適当なデータをインデックスに取り込んでみます。
データを1件ずついれるには、 PUT /<index>/<id> でできます。 更新も同じAPIです。
https://opensearch.org/docs/1.0/opensearch/rest-api/document-apis/index-document/

まとめでデータを投げたい場合は、 POST _bulk で可能です。
https://opensearch.org/docs/1.0/opensearch/rest-api/document-apis/bulk/

データのインポートが本当にできているか確認するために、何も絞らず全件返す検索をしてみます。
GET /aaa/_search
{
"query": {
"match_all": {}
}
}
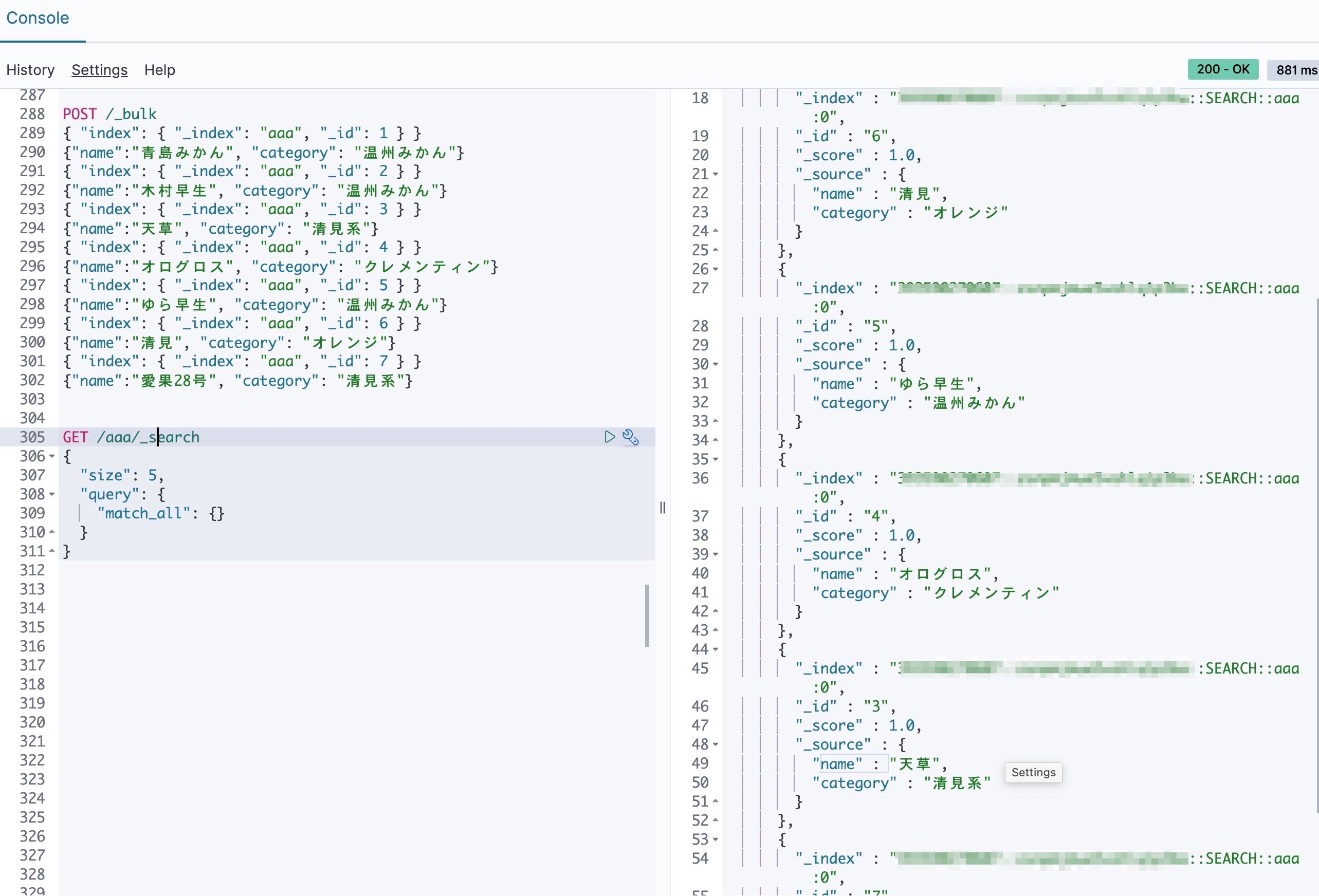
なんだかちゃんとデータが返ってきていそうです。
では、このデータセットのうち、 清見 という文字列を含むものを検索してみます。
GET /aaa/_search
{
"size": 5,
"query": {
"multi_match": {
"query": "清見",
"fields": ["*"],
"type": "most_fields"
}
}
}
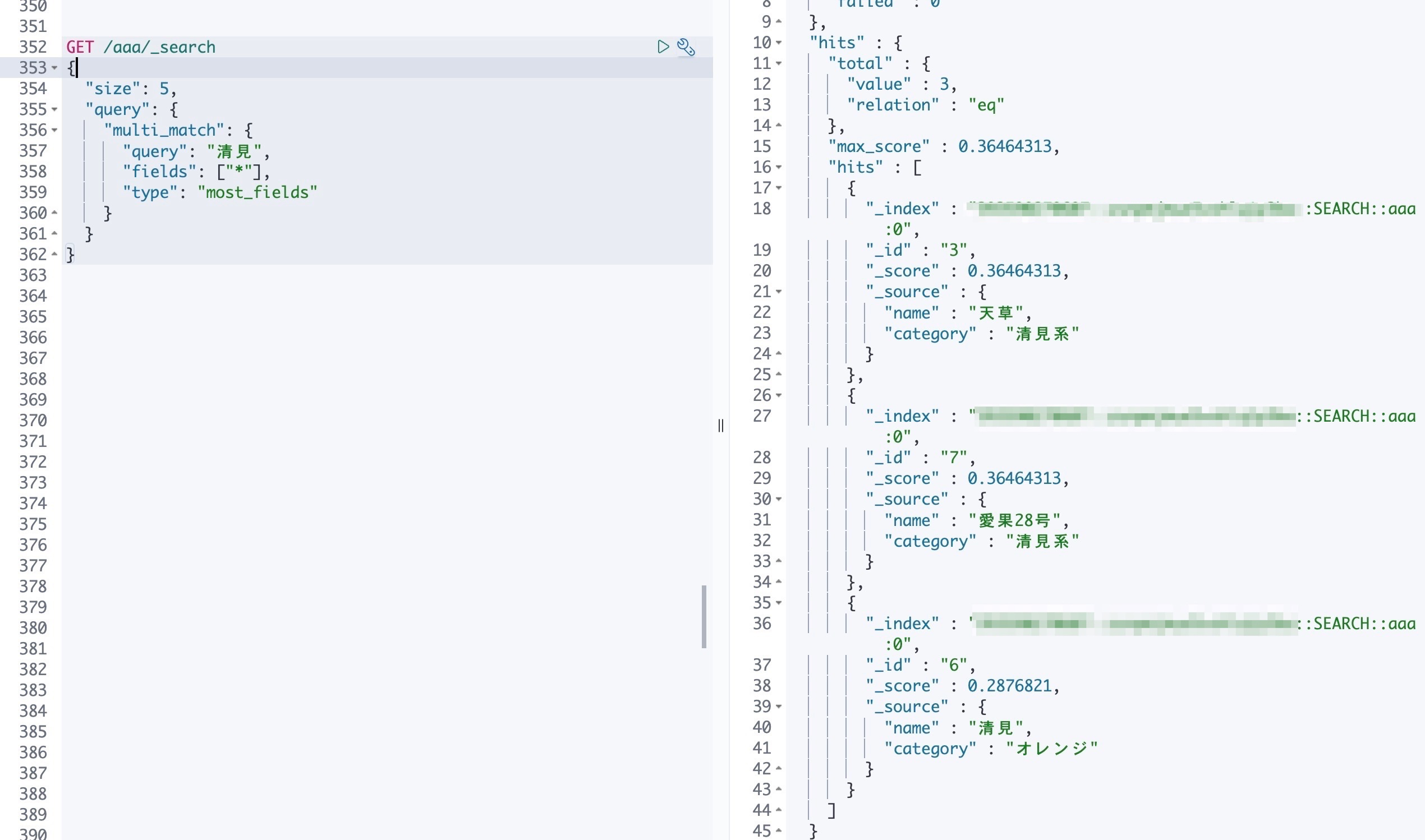
ちゃんと name と category に 清見 を含む、 天草と愛果28号と清見 が返ってきて偉いです。
ただ、名前が一致しているレコードを1番目に返したいと思ったらブーストフィールドというのをつかって、
GET /aaa/_search
{
"size": 5,
"query": {
"multi_match": {
"query": "清見",
"fields": ["name^200", "category"],
"type": "most_fields"
}
}
}
としてみたり、
よみがな検索できたり
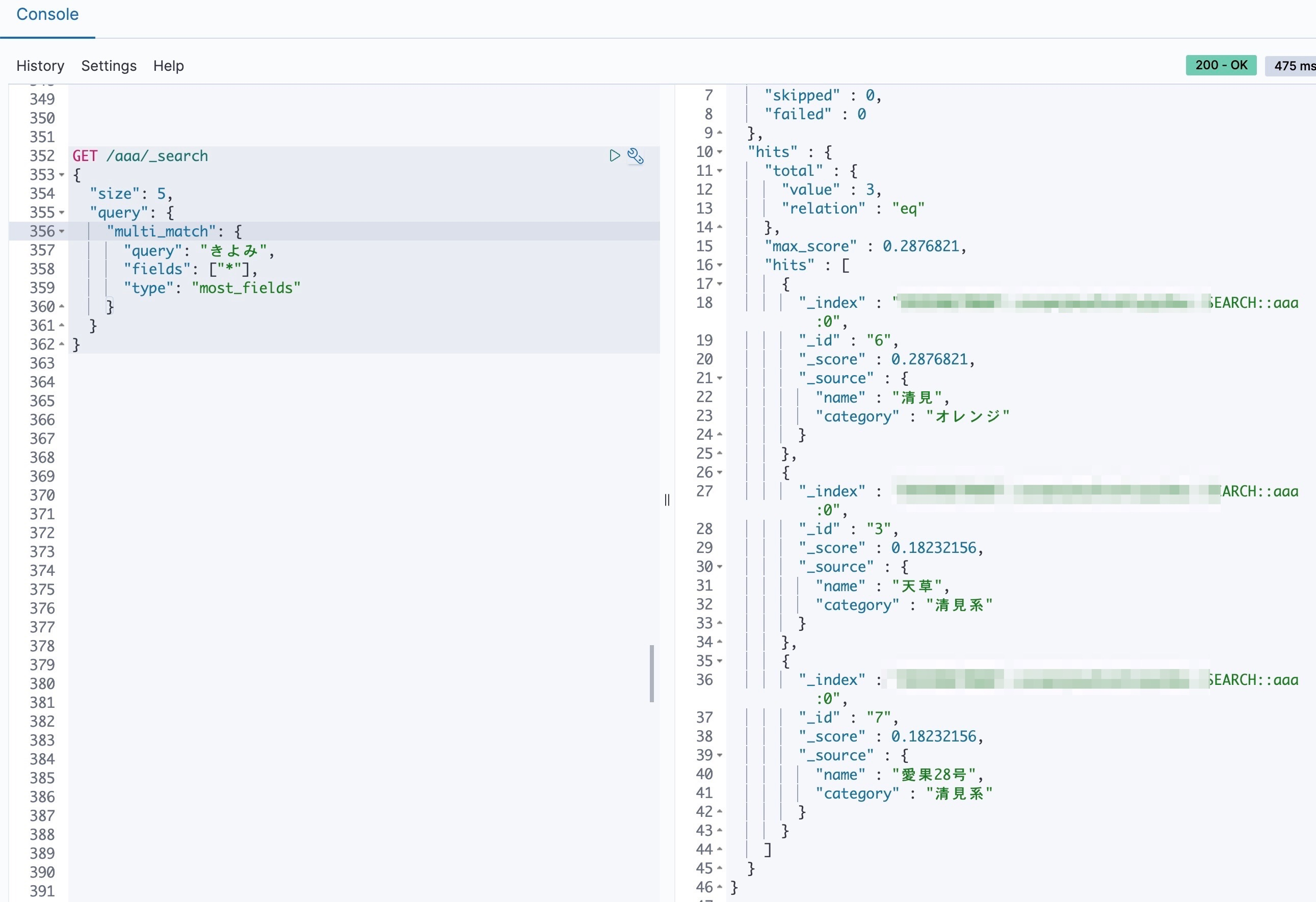
あいまい検索ができたり、ハイライトすべき箇所をピックアップしてくれたり
なんだか柔軟な検索ができて、べんりそ〜というのがわかりました。
今回、
- AOSS, サーバーのことを考えなくて良くて便利
- WebUI で手軽にデータ操作を試せる
- 検索、なんだか色々できそう
ということがわかりました。
プロダクションで採用するには更に調査を進める必要がありますが、あとはプログラムからどうこのサービスを利用できるかを検証しておけば、単なる好奇心による技術調査としては十分そうです。
Ruby でのデモ
comming soon...
12月中に別記事として書きます。
まとめ
この記事とかけまして、忙しい冬の軽食ととく
そのこころはどちらも、「みかんですまそ(未完でスマソ、みかんで済まそ)」
ご自愛ください。