gpt-3.5-turbo に fine-tuning ができるようになりました。
node.jsを使って触った際に、公式のAPI Reference だけだと少し分かりづらかったので、備忘メモ。
準備
- 適当な
node.js環境を用意。 -
npm i dotenv openaiしておく。 (※ 最新バージョンのopenaiへ) -
.envにOPENAI_API_KEYとして トークンを設置しておく。
学習データの用意
jsonオブジェクトを1行ごとに区切った jsonl 形式で用意。以下イメージ。
{"messages": [{"role": "user", "content": "AAAAAAと何ですか?"}, {"role": "assistant", "content": "AAAAAAとは〇〇〇〇〇〇〇〇〇〇のようなものです。"}]}
{"messages": [{"role": "user", "content": "BBBBBBと何ですか?"}, {"role": "assistant", "content": "BBBBBBとは〇〇〇〇〇〇〇〇〇〇のようなものです。"}]}
{"messages": [{"role": "user", "content": "CCCCCCと何ですか?"}, {"role": "assistant", "content": "CCCCCCとは〇〇〇〇〇〇〇〇〇〇のようなものです。"}]}
{"messages": [{"role": "user", "content": "DDDDDDと何ですか?"}, {"role": "assistant", "content": "DDDDDDとは〇〇〇〇〇〇〇〇〇〇のようなものです。"}]}
{"messages": [{"role": "user", "content": "EEEEEEと何ですか?"}, {"role": "assistant", "content": "EEEEEEとは〇〇〇〇〇〇〇〇〇〇のようなものです。"}]}
.
.
.
- 学習するサンプルは
最小10個必要。50~100個で明確な改善が見られるらしい。 - サンプルは
それぞれ4096トークン内に収まっている必要あり(越えた場合切り捨て) - ファイルは
50MB以下である必要がある - 学習データはユーザ以外の学習には使用されない。
OpenAI側で安全性のチェックは行われる。
学習データの登録
まず、API Referenceの以下のように書かれている部分の "file-abc123" に該当するIDを入手する。
const fineTune = await openai.fineTuning.jobs.create({
training_file: "file-abc123"
});
以下を実行し、実行結果のログからIDを入手。
require('dotenv').config()
const fs = require('fs')
const dataPath = './path/to/data.jsonl'
const OpenAI = require('openai')
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
async function uploadFile() {
try {
const f = await openai.files.create({
file: fs.createReadStream(dataPath),
purpose: 'fine-tune',
})
console.log(`File ID: ${f.id}`) // このIDを使う
return f.id
} catch (err) {
console.log('err uploadfile: ', err)
}
}
uploadFile()
ファインチューニングする
先程入手したIDを TRAINING_FILE_ID として.env に追記し、以下のコードを実行する。
require('dotenv').config()
const OpenAI = require('openai')
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
})
async function main() {
const fineTune = await openai.fineTuning.jobs.create({
training_file: process.env.TRAINING_FILE_ID,
model: 'gpt-3.5-turbo-0613',
})
console.log(fineTune)
}
main()
⚠️注意点
上記のサンプルコードの uploadFile() と main() を直列で、すぐに実行してしまうと、BadRequestError: File file-....... is not ready のようなエラーが帰ってくる。
処理にタイムラグがあり、少し待たなければならない。
ファインチューニングされたモデルを使用する
成功すると、少し時間を置いてsuccessfully completedと書かれたメールが届く。
これでファインチューニングしたモデルが使用可能になる。
OpenAI Playgroundを使うとすぐに動作確認できて便利。
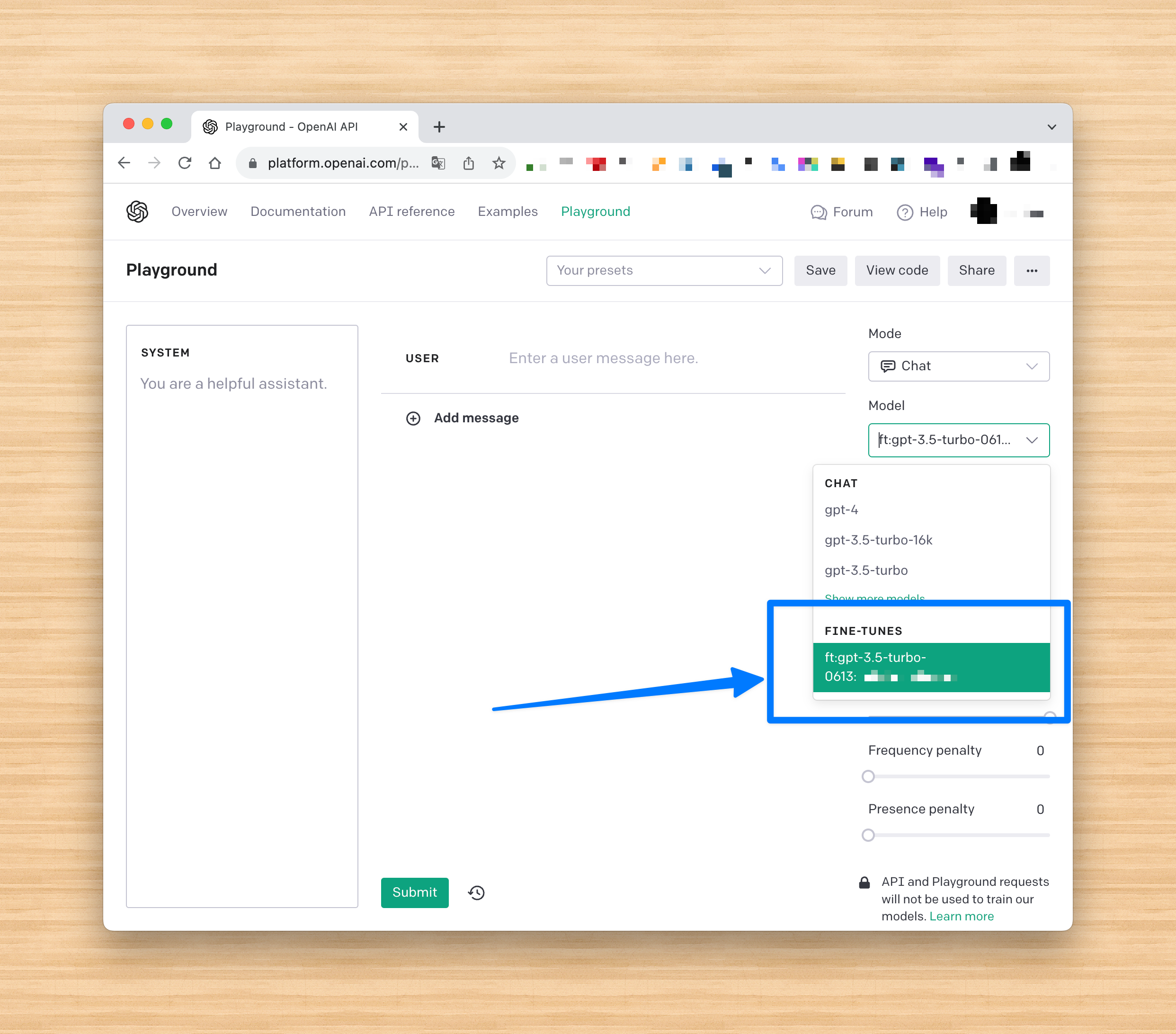
おまけ
サンプルのjsonlを見る限り、これまで embedding を駆使して in-context learning していた内容を予めモデルに焼き付けておけるようなものに感じました。
普遍性の高いデータは予めfine-tuningしておきトークンを削減させ、更新されうるデータは embeddingで都度プロンプトに含めていくようなデザインパターンが良さそうに思えますが、このあたりは少し実験していきながら掴んでいきたいです。
参考
参考にさせていただきました。ありがとうございます。
- https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates
- https://platform.openai.com/docs/api-reference/fine-tuning/create
- https://zenn.dev/nano_sudo/articles/eaf0d77646d7b8
- https://dev.classmethod.jp/articles/openai-gpt35turbo-fine-tuning/
- https://dev.classmethod.jp/articles/gpt35-finetuning-tips-qna/