はじめに
最近「Rによる統計的学習入門」を読み始めました。各章の最後に演習問題が用意されているので、自身の解答の備忘もかねて、記事として残しておきます。
ご参考になれば幸いです。
また、間違い等ありましたらコメントいただけるとありがたいです。
2章演習問題(理論編)
※問題文は載せておりません
(1)
a)
柔軟な統計的学習法
十分なデータがある場合は、柔軟でない方法より柔軟な方法の方が優れたfitとなる
b)
柔軟でない統計的学習法
小さなデータセットの場合、柔軟なモデルover fitを起こして、汎化性能が下がる可能性が高い
c)
柔軟な統計的学習法
線形回帰のような柔軟でないモデルでは非線形を表現することは難しいため、非線形の関係に対しては、柔軟な手法が適している
d)
柔軟でない統計的学習法
柔軟なモデルでは、誤差項に含まれているノイズに対して過剰にfitしてしまい、分散が大きくなる
(2)
a)
回帰問題 n:500社分のデータ p:利益、従業員数、業界の3つの変数
b)
分類問題 n:20この過去事例データ p:製品の価格、マーケティング費用、競合製品の価格を含む13個の変数
c)
回帰問題 n:2012年の52週分のデータ p:アメリカ、イギリス、ドイツの3つの株式市場の上下割合
(3)
a)
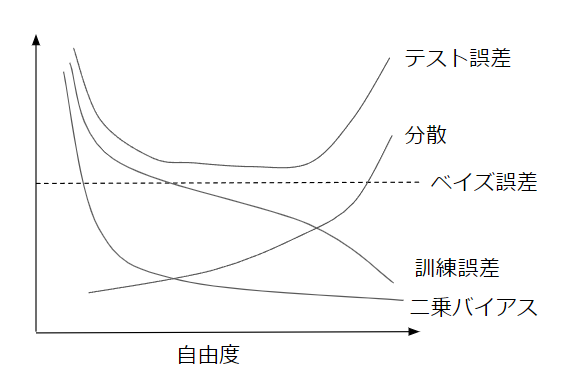
b)
訓練誤差:自由度が増すに連れて、データに対する適応具合も向上するため、訓練誤差は自由度に伴って減少する
二乗バイアス:バイアスは学習において前提とした仮定に対する誤差となるため、自由度が増すに連れて減少する
分散:分散は異なる訓練データにより、学習モデルがどの程度変化するかを示している。自由度が大きくなるほど、データに対して良く適合することを考えると、自由度の増加に伴って分散は大きくなる。
ベイズ誤差:データ自体が内包する誤差のため、自由度によらず一定の値を取る
テスト誤差:テスト誤差は二乗バイアスと分散、ベイズ誤差の和となり、どれだけ誤差を最小化してもベイズ誤差を下回ることはなく、U字の形をしている。
(4)
a)
デフォルト予測 過去の入出金データをもとにデフォルトするかどうかを予測する
異常検知 製品の画像をもとに異常があるかどうか判定を行う
大学への入学推定 現在の学力データをもとに大学への入学可否を推定する。推定によって、各学力データの効果量を測り、改善可能性を探る。
b)
農作物の収穫量予測 生育データやハウス内の環境データ、気象データなどを説明変数として収穫量を予測する
需要予測 流通データなどからトレンドを予測する
賃貸価格の予測 間取り等の賃貸情報から適正価格を推定する
c)
顧客データのクラスタリング 顧客の購買データをクラスタリングにより分割し、戦略立案に活用する
患者データのクラスタリング 患者データをクラスタリングにより分割し、病気と患者情報との関連性を探る
製品データのクラスタリング 不良製品を含んだデータをクラスタリングにより分割し、不良の原因を探る
(5)
柔軟な手法は、複雑な関数を近似できるが、一方で少数データやノイズの大きなデータに対してはover fitしてしまう問題がある。データが豊富にあり、予測精度が求められる場合においては柔軟なアプローチが優れている。一方で説明性を求められる場合や、データのノイズが大きい場合、データが少ない場合には柔軟でないアプローチが優れている。
(6)
パラメトリック法はfを推定するために、"線形"のように仮定を置く。その仮定のもとでデータからfを推定する方法となる。一方でノンパラメトリック法は特にfについて仮定を置かず、なめらかにデータに適合するfを推定する。
パラメトリック法の場合、解釈性が高いという利点があるため、推論が目的である場合、優れた方法となる可能性がある。一方で、パラメトリック法はfを推定する過程で、制約を持たせているため、その制約の外に関しては上手くfで表現することはできない。
(7)
a)
1:3
2:2
3:√10
4:√5
5:√2
6:√5
b)
5のgreen
c)
最も近い点を3つ取得すると、5のgreen,2のred,4のgreen,6のred(4,6は同じ距離)となり、greenとredの確率が同じとなる。そのため、最も近い点で判断すると、5のgreenとなる。
d)
Kが大きくなるにしたがって、決定境界の柔軟性は下がる。そのため、決定境界が非線形である場合はKは小さい方が適している。
2章演習問題(応用編)
RではなくPythonで解答を作ってみています。
参考文献
最後に
最後まで読んでいただきありがとうございます。
今回は2章の解答でした。
次回は3章の解答を作成しようと思います。