2022 年もあと残りわずか。2022年は Glue のインタフェースの刷新があり、Glue Job の作成が Glue Studio と統合されて使いやすくなる部分があった反面、利用の仕方がよくわからなくなってしまった方も多いはず。また、AWS re:Invent も終わり Analytics 領域は大きな発表がたくさんあり、AWS が現在いかに力を入れている領域か認識しました。Glue は Apache Spark、Python Shell script に加えて、直近 Ray をエンジンとして利用することができるようになりました。
と前置きしつつ、本稿では表題にある通り、AWS Glue で Java Archive (JAR) を扱う方法をまとめていきたいと思います。
はじめに
今回フォーカスするのは Glue for Apache Spark で、Java や Scala で開発された Spark アプリケーション (JAR) の実行方法についてです。Glue では追加の JAR ファイルを依存関係として設定することができます。これは以下のような場面で主に利用されます。
- Glue ジョブ内で追加のライブラリを利用したい
- Java や Scala で開発された Spark アプリケーションを Glue ジョブとして実行したい
この記事は後者をターゲットにします。たとえば、Amazon EMR などの Spark クラスタでは spark-submit コマンドで Spark アプリケーション (JAR) を実行できます。このような環境からアプリケーションを Glue ジョブに移行したい場合も多いかと思います。 Glue 外部の JAR に含まれたクラスを実行する方法は2種類あります。
事前準備
方法を紹介する前に、実行したい Spark アプリケーションが Glue Job 環境と互換性があるか確認しましょう。たとえば Glue 3、4 の場合は以下の通りです。
- Glue 3: Spark 3.1.1, Java 8, Scala 2.12
- Glue 4: Spark 3.3.0, Java 8, Scala 2.12
Glue のスクリプトを利用せず、直接 JAR からクラスを呼び出す
単純移行する場合、固められた JAR ファイルをそのまま動かしたい要件もあるかと思います。その場合はこちらの方法が利用できます。この方法が利用できるのは以下のケースです。
- 引数がないケース
- 引数が Key-Value 形式で渡されるケース
手順は以下の通りです。
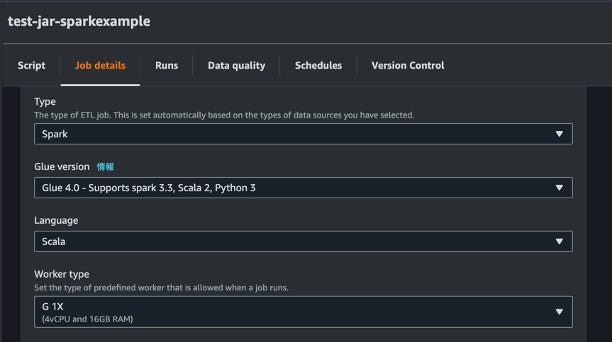
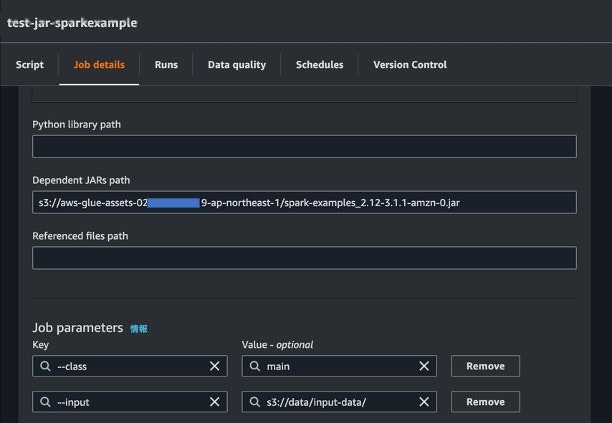
- Glue Job の Job details の Language を Scala と選択する
- 利用したい JAR を S3 にアップロードし、その S3 URI を Job details の Dependent JARs path に記載
- エントリとなるクラスを Job parameters の Key に
--class、Value にクラス名として記載 - (オプション)環境変数を Key-Value 形式で与える場合は、Key に
--変数名、Value に値として記載 - Script の中身を全消去する
この方法で Glue Job を実行すると、 --class に指定したクラスがエントリとして読み込まれ、Spark アプリケーションが実行されます。
Glue のスクリプトから JAR 内のクラスをインポートして利用
変数を直接入力したい場合には、Glue のスクリプトから JAR のクラスを呼び出す方法を利用します。一般的に、JAR 内のコンポーネントを利用する際も同様の方法で利用することができます。手順は以下の通りです。手順 1 と 2 は先ほどと同様です。3 はエントリポイントとなるスクリプトのクラス名を指定する必要があります。
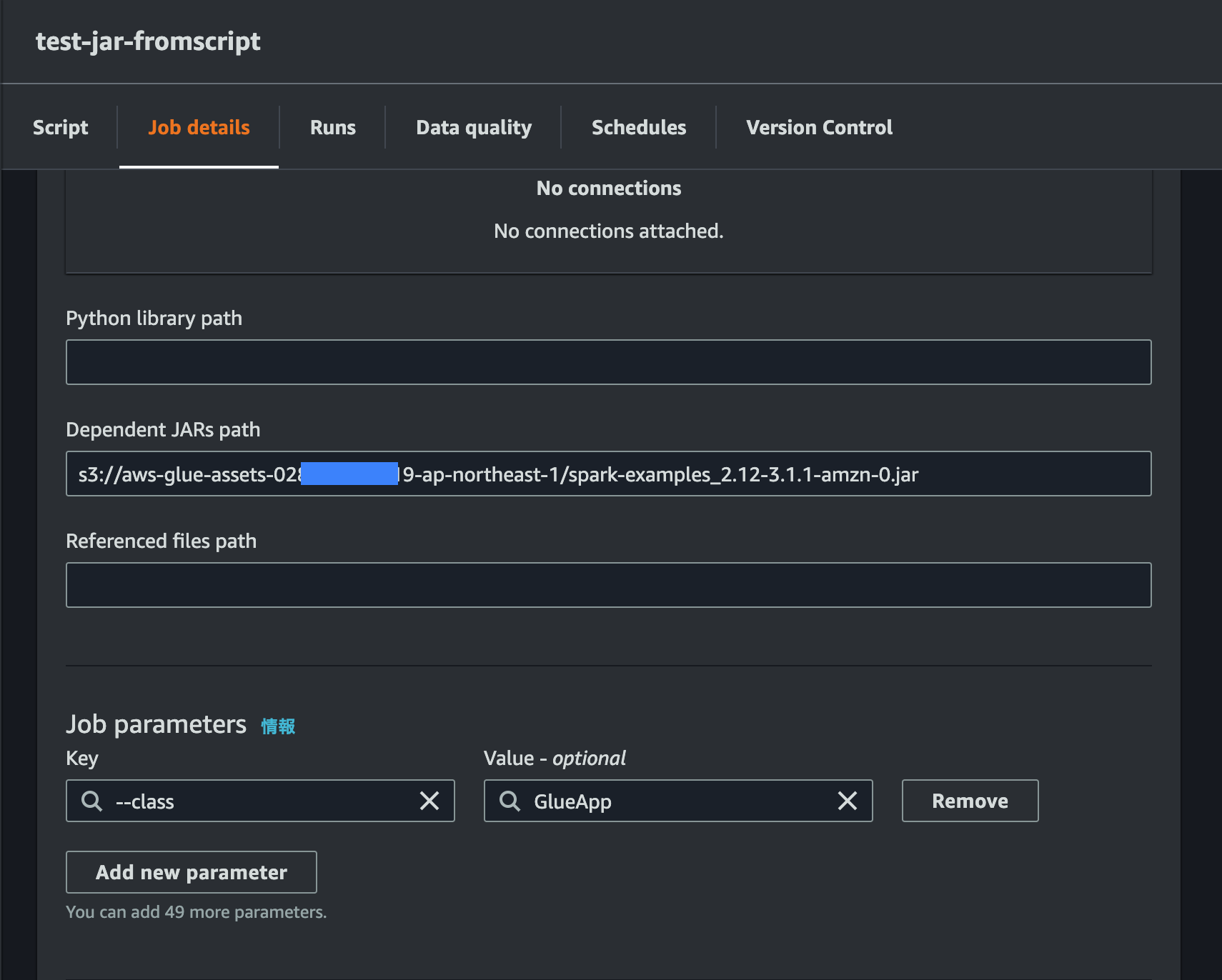
- Glue Job の Job details の Language を Scala と選択する
- 利用したい JAR を S3 にアップロードし、その S3 URI を Job details の Dependent JARs path に記載
- エントリポイントとなるスクリプト上のクラスを Job parameters の Key に
--class、Value にクラス名として記載 - Script の中身を以下のように変更
Glue Script (pySpark)
import com.amazonaws.services.glue.util.JsonOptions
import com.amazonaws.services.glue.{DynamicFrame, GlueContext}
import org.apache.spark.SparkContext
import org.apache.spark.examples.SparkPi
object GlueApp {
def main(sysArgs: Array[String]): Unit = {
SparkPi.main(Array("1000"))
}
}
今回は spark の examples から SparkPi.scala を呼び出しています。main 関数の引数として args: Array[String] が必要なため、今回は Array(“1000”) としています。
上記コードで自由に引数を利用することができましたが、引数をコードにベタ書きする必要があるため、用途が限られてしまいます。この場合、getResolvedOptions を利用することで、ジョブの実行時にスクリプトに引数を渡して利用できるようになります。下記のコードでは resource_name、strnum、start_minute が引数になります。
Glue Script (pySpark)
import com.amazonaws.services.glue.util.{JsonOptions, GlueArgParser, Job}
import com.amazonaws.services.glue.{DynamicFrame, GlueContext}
import org.apache.spark.SparkContext
import org.apache.spark.examples.SparkPi
object GlueApp {
def main(sysArgs: Array[String]): Unit = {
val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("strnum","resouce_name","start_minute").toArray)
SparkPi.main(Array(args("strnum")))
print(args("resouce_name"),args("start_minute"),args("strnum"))
}
}
(オプション)環境変数を注入して Glue Job をキック
2 番目の方法で自由に変数を利用することができるようになりました。最後に --arguments オプションを利用して Glue Job を開始する際に引数を注入する方法を見ていきましょう。CLI を利用する方法はドキュメントにも記載されているため、そちらをご確認ください。今回は AWS Lambda から Glue job をキックする方法を試してみたいと思います。
Lambda (Python 3.9)
import boto3
import time
glue_job_name = 'test-jar-fromscript'
glue_job_arguments = {
'--resouce_name': 'hogehoge',
'--strnum': '1000',
'--start_minute': str(time.time),
}
def lambda_handler(event, context):
glue = boto3.client('glue')
glue.start_job_run(JobName=glue_job_name,Arguments=glue_job_arguments)
print('launched glue job: ' + glue_job_name)
return
実行すると Glue の Run から Output Log で以下のように確認できます。
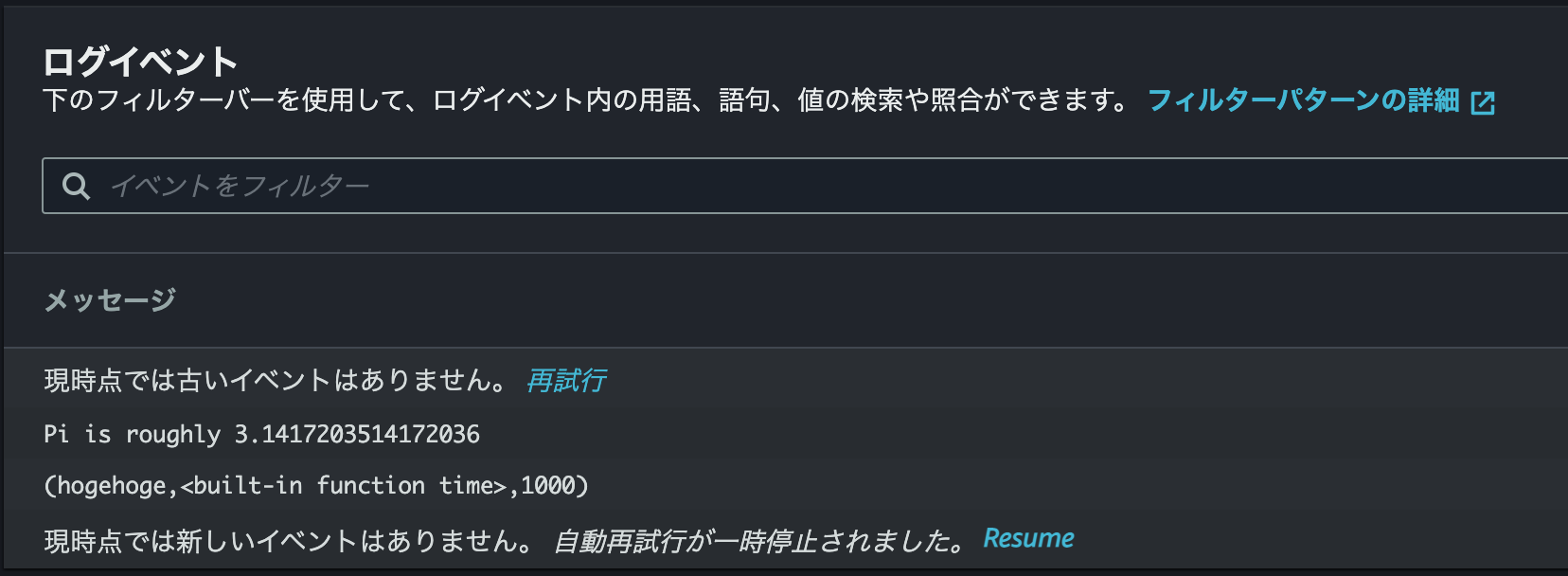
上記のような形で Lambda 関数から変数を渡して Glue job をキックすることができます。Lambda 上では環境変数を利用することもできますし、外部のパラメータストアやデータベースから変数を取ってくる構成も考えられます。ETL と変数を収集する部分のロジックを分離できるのでこの方法がいいかなと個人的には思います。
まとめ
できることが増えて複雑性も増した Glue で JAR を扱う方法をについてまとめました。今回は既存資産を活用しようという前提でしたが、これから新規に構築される場合は Git などとも連携が増えているので、Glue スクリプト上でアプリケーションを実行する方がわかりやすくてそちらもおすすめです。これからも良き Glue ライフを!