本記事はJPOUG Advent Calendar 2024 と Oracle Cloud Infrastructure Advent Calendar 2024 シリーズ2 の、いずれも22日目の記事のクロスポストとなります。
JPOUG Advent Calender 21日目の記事は Hiroshi Sekiguchi さんの記事でした。
Oracle Cloud Infrastructure Advent Calendar 2024 シリーズ2 21日目の記事は m_uriu さんの記事でした。
概要
RAGというキーワードが使われ始め、ベクトルデータベースの機能を活用したセマンティック検索が注目されています。
Oracle Database も 23ai からベクトルデータベースの機能が搭載され、RAGとして利用するデータソースとして注目され始めています。
とはいえOracle Databaseには全文検索を提供するOracle TEXTの機能がかなり昔のバージョンから存在しています。
全文検索の特性を知ることで様々な活用方法があるなと思うので、改めて脚光を浴びてもらうために機能について紹介します。
Oracle TEXTの超概要
Oracle Databaseで利用可能な全文検索の機能です。
テキスト形式、PDF、Wordといった各種フォーマットデータに対して索引付けを行うことで、索引を利用した検索が可能となります。
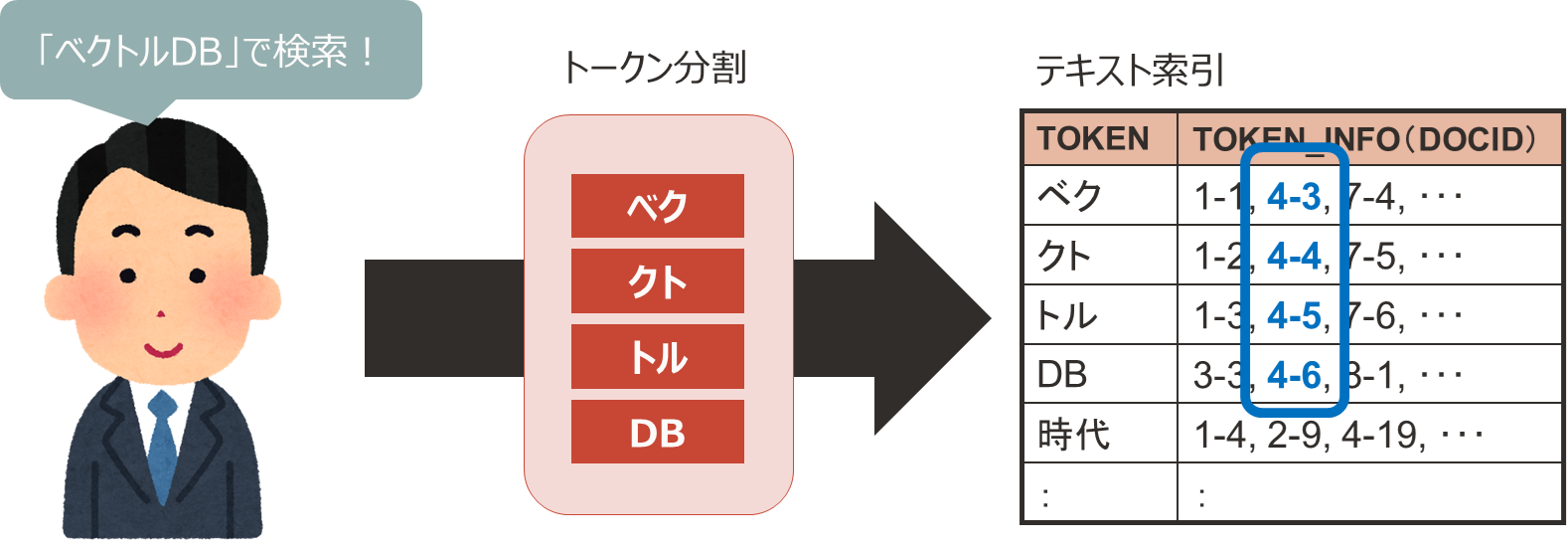
索引付けの機能はOracle Databaseのカーネルに組み込まれており、テキスト索引を作ると内部的に索引付けしたいデータを「トークン」というものに分割して所持します。
検索するときも検索ワードを同様にトークンに分割し、DB内で分割したトークンが連続して存在している場合に結果として返します。
セマンティック検索と全文検索の違い
簡単に言えば、意味として近いデータを検索するのがセマンティック検索で、検索ワードを含むデータを検索するのが全文検索です。
ベクトルデータベースはセマンティック検索に位置づけられると思います。

検索方法としても、セマンティック検索はChatGPTのように自然言語で質問をするのに対し、全文検索はGoogle検索のようにキーワードで質問をする感じです。
Oracle TEXTの「近さ」のアルゴリズム(TF-IDF)
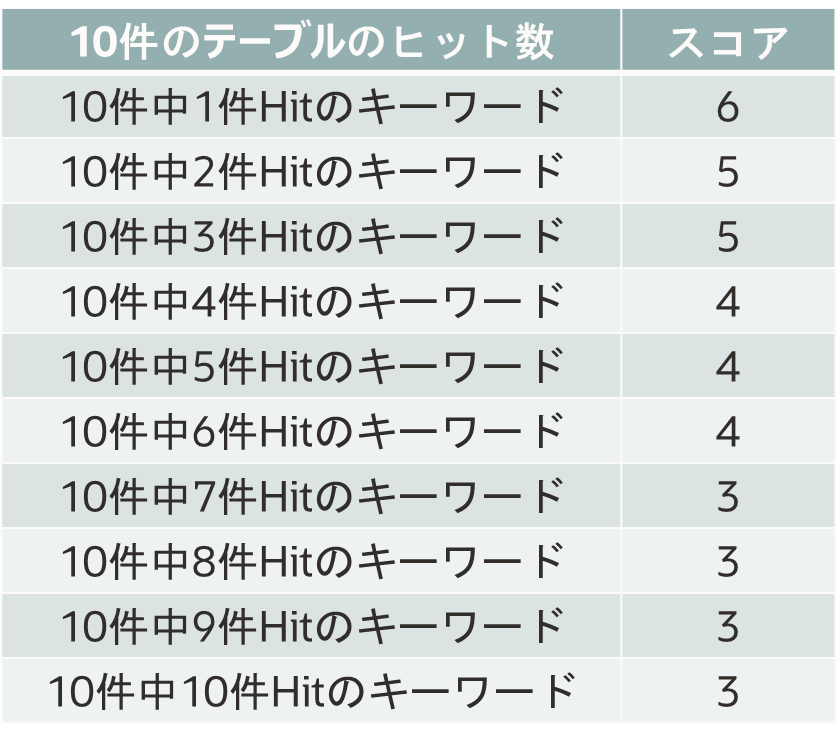
Oracle TEXTは、出現頻度の少ないキーワードで検索した場合にスコアが高くなるような検索スコアを算出し、結果を返す際に活用することができます。
この検索スコアのアルゴリズムとして、TF-IDFのアルゴリズムを採用しています。
例えば10レコードのナレッジテーブルのナレッジデータに対してOracle TEXTのテキスト索引を付与した場合、10レコードの中で1件だけヒットするような検索ワードの検索スコアは6となり、10件中10件ヒットする場合の検索ワードの検索スコアは3となります。
TF-IDFはその特性上、レコードの中に含まれる単語の数を考慮していません。
例えばテキスト索引付与列に同じ用語が何度も出現している場合、その用語で検索をした際にスコアが高くなりやすくなる特徴があります。
レコードの中に含まれる単語の数を考慮した Okapi BM25 などのアルゴリズムは、Oracle TEXTでは活用されません。
Oracle TEXT で提供される索引の種類
Oracle TEXTでは3種類の索引が利用できます。
-
CONTEXT索引(今回取り上げる索引)
- 全文検索を高速に実現するために利用する索引
- Oracle Database 19cから create search index構文でも作成できるようになった
- CTXCAT索引
- CONTEXT索引同様に全文検索が可能
- CTXRULE索引
- ドキュメントの分類を高速に実現する索引
以降は利用されることが多いCONTEXT索引にフォーカスを当てて紹介します。
また、CONTEXT索引のことを以後「テキスト索引」と記載します。
Oracle TEXTを使うまでのステップ
Oracle TEXTのテキスト索引を作成して検索できるようにするまでに、以下の8つのステップを踏む必要があります。Autonomous DatabaseをはじめとしたOracle CloudのPaaS製品を利用している場合は1のステップは不要です。
- オンプレの場合はDBCAでDBを作成する際、ORACLE TEXT オプションにチェックを入れてインストールする
- テスト用となら必要に応じてテキスト検索専用のユーザーを作る(作らなくてもできる)
- テキスト索引を作成するための権限をユーザーに付与する
- テキスト索引を付与するデータソースを用意する
- レクサーを決める
- テキスト索引への同期頻度を決める
- プリファレンスを作成する
- テキスト索引を作る
特に5番のレクサーと6番の同期頻度については注意が必要になり、この内容によっては意図した検索ができない可能性があります。
以後簡単に何を選択するべきかを記載します
テキスト索引を利用するための権限
TESTUSERというユーザーがテキスト索引を利用した検索を行いたい場合は、TESTUSERに以下の権限を付与します。
GRANT CTXAPP to TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_CLS TO TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_DDL TO TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_DOC TO TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_OUTPUT TO TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_QUERY TO TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_REPORT TO TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_THES TO TESTUSER;
GRANT EXECUTE ON CTXSYS.CTX_ULEXER TO TESTUSER;
詳細についてはOracle TEXTのアプリケーション開発者ガイドを参考にしてください。
テキスト索引を付与するデータソース
Oracle TEXTでは以下の3つのデータソースが選べます
- DBに格納されているデータ
- DBサーバ―のローカルディスクに格納されているファイル(ファイルデータストア)
- リモートのストレージに格納されているファイル(URLデータストア)
DBに格納されているデータ(テーブル)にテキスト索引を作成する場合は、テーブルのどの列に対してテキスト索引を付与するかを決めます。この際、単一の列だけか、複数列に対するテキスト索引にするかも検討します。
ローカルディスクに格納されているファイルにテキスト索引を作成する場合は、データソースを1つのフォルダにまとめ、そのフォルダをoracle databaseでディレクトリオブジェクトとしてパスを登録し、そのディレクトリオブジェクトに対する読み取り権限をテキスト索引を作るユーザーに付与します。その後、DB上にテーブルを作成し、ディレクトリに格納したファイル名をinsertし、その列に対してテキスト索引を作成するイメージです。
リモートのストレージに格納されているファイルにテキスト索引を作成する場合も同様にDBにテーブルを作成し、ファイルのURLをinsertし、その列に足してテキスト索引を作成するイメージです。
ローカルディスクに格納されているファイルや、リモートのストレージに格納されているファイルに対してテキスト索引を作成する場合はOracle TEXTのリファレンスマニュアルをご参照ください。
テキスト索引で活用するレクサー
Oracle Databaseでは様々な言語で利用できるように様々なレクサーがカーネルに組み込まれています。
日本語ドキュメントの場合は以下の3つから選択するのが良いと思います。
- JAPANESE_LEXER
- JAPANESE_VGRAM_LEXER (BIGRAM=FALSE)
- JAPANESE_VGRAM_LEXER (BIGRAM=TRUE)
それぞれのレクサーの特徴を、私の独断と偏見で表にまとめたのが以下です。
| レクサー | 検索漏れリスク | 索引の大きさ | 検索性能 |
|---|---|---|---|
| JAPANESE_LEXER | ×:ある | ◎:小さい | ◎:早い |
| JAPANESE_VGRAM_LEXER (BIGRAM=FALSE) | 〇:とても低い | △:やや大きい | △:やや遅い |
| JAPANESE_VGRAM_LEXER (BIGRAM=TRUE) | ◎:無い | ×:大きい | 〇:中 |
JAPANESE_LEXERを選択すると意図した使い方をしない人から「検索にヒットしない!」とクレームが入る可能性があるので、よくわからないならJAPANESE_VGRAM_LEXERを選択したほうが良さそうです。
容量的に問題が無いならJAPANESE_VGRAM_LEXER (BIGRAM=TRUE) が良いと思いますが、BIGRAM=FALSEでも問題になるケースはあまり聞いたことがないので、そこはディスク容量との相談になりそうです。
それぞれの特徴を言葉でも簡単に記載します。
JAPANESE_LEXER
JAPANESE_LEXERは索引のサイズが小さく性能も良いですが、意図したワードがヒットしない可能性がある索引です。
Oracle Databaseには、日本語レキシコンと呼ばれる辞書がDB内部に実装されているのですが、この辞書を活用して品詞などを考慮したうえで文章を細かいトークンに分けるしくみがJAPANESE_LEXERです。
例えば「テキスト索引」という単語にテキスト索引を付与した場合、内部的に「テキスト」「索引」というようにトークン分割して索引付けをします。「テキスト」を含む文字をテキスト索引を利用して検索するとヒットしますが、「キス」を含む文字をテキスト索引を利用して検索してもヒットしないことが期待されます。
キーワードとして検索する用途であればJAPANESE_LEXERのメリットが大きそうですが、単語の一部で検索されても思ったような検索結果にならないことが考えられます。
JAPANESE_VGRAM_LEXER (BIGRAM=FALSE)
JAPANESE_VGRAM_LEXER(BIGRAM=FALSE)は検索漏れのリスクを考慮し、辞書を活用しつつも2文字以上の単語については基本的に2文字のトークンに分割する特徴があります。
JAPANESE_VGRAM_LEXERを選択し、BIGRAMを指定しなかった場合は BIGRAM=FALSE になります。
例えば先ほどの「テキスト索引」なら、「テキ」「キス」「スト」「ト」「索引」「引」といったようにトークン分割するので、「キス」を含む文字をテキスト検索で検索してもヒットするようになります。
「キ」で検索しても、内部的に「キ%」に置き換えて検索するのでヒットしますが、1文字検索はヒット件数が多く性能が悪くなりやすい特性があります。そのため、品詞の区切りで1文字になりやすいJAPANESE_VGRAM_LEXER(BIGRAM=FALSE)は他のレクサーよりも検索性能が悪くなりやすいです。
なお、日本語として本来検索しないであろう文字ではトークン分割しない仕様なので、例えば「ぼったくり」の場合は「ぼった」「たく」「くり」「り」と分割され、「った」を含む文字をテキスト索引を利用して検索してもヒットさせることができないという特徴があります。
JAPANESE_VGRAM_LEXER (BIGRAM=TRUE)
BIGRAMの設定は品詞などを無視して強引に2文字で区切るというオプションです。
「テキスト索引」なら、「テキ」「キス」「スト」「ト索」「索引」「引」と言ったようにトークン分解します。「ぼったくり」なら、「ぼっ」「った」「たく」「くり」「り」となります。
品詞を無視して2文字にするので1文字の検索をする機会が減ることでBIGRAM=FALSEより性能劣化はしにくいですが、索引のサイズが大きくなる特徴があります。
ちなみに、索引のサイズを見積もるのはほぼ不可能です。
えいや!として見積もるなら、テキスト索引を付与するデータサイズの3倍ほどを見込んでおけば良いと思います。
テキスト索引の同期頻度
テキスト索引を作成すると、データソースの内容を検索可能にするテキスト索引が作成されます。
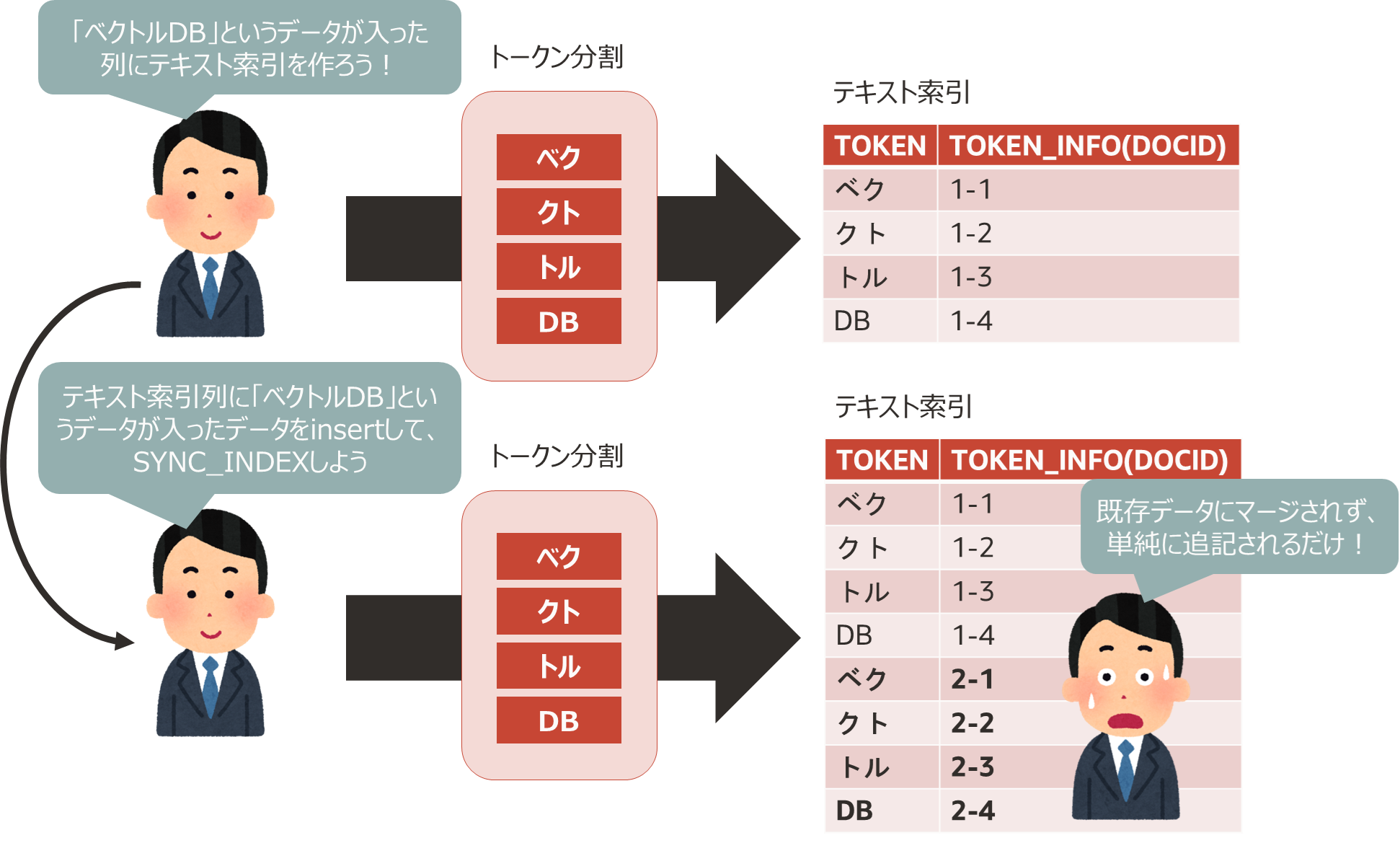
テキスト索引の作成後にデータソースに対して更新やinsertをした場合、そのデータも検索対象に含まれることが期待されると思いますが、デフォルトは索引への情報の反映タイミングが非同期であり、更新した情報を検索をしてもヒットしません。
これは、テキスト索引が普通のB*Tree索引とは全く異なる構造の索引だからです。
テキスト索引ではどのデータに対して、何番目の言葉として登録されているというデータをトークンごとに整理しています。
更新があるたびに更新データをトークン分割し、現存のテキスト索引と統合していたら更新の性能がかなり劣化してしまいますよね。
そのため、SYNCのタイミングでは基本的にテキスト索引に対して追記しかされません。
現存のテキスト索引と統合されないので、データ量がどんどん増えていきます。この状態を「テキスト索引の断片化」と呼ばれています。
このテキスト索引の同期頻度については3つから選択可能です
- MANUAL(デフォルト)
- ユーザーが CTX_DDL.SYNC_INDEXを実行したタイミングでデータソースに対するDMLが索引に反映される
- EVERY XXX
- 決まった時間に同期をする(毎日0時なら EVERY “FREQ=DAILY; BYHOUR=0” といった感じで指定する)
- ON COMMMIT
- COMMITを発行するタイミングで同期をする
検証目的であれば ON COMMIT を選択するべきですが、例えば大量更新を行う可能性のあるテーブルに対してテキスト索引を作るなら、MANUALにしてDML後にSYNC_INDEXを実行した方がテキスト索引の断片化を少しだけ抑えられます。断片化すると索引のサイズが必要以上に大きくなったり、検索性能も悪くなるため注意が必要です。
プリファレンスの作成
テキスト索引を作るには、データソースの場所やレクサーを指定します。
これを指定するにはプリファレンスというものを作成することが必要です。
例えばDBのKNOWLEDGEテーブルにあるQUESTION列とANSWER列に対して、JAPANESE_VGRAM_LEXER(BIGRAM=TRUE)のテキスト索引を作るケースの例を以下に記載します。
-- テーブルの作成
create table KNOWLEDGE(ID number, QUESTION varchar2(4000), ANSWER varchar2(4000));
insert into KNOWLEDGE values (1,'日本で一番人口の少ない都道府県は?','鳥取県です');
insert into KNOWLEDGE values (2,'日本で一番人口の多い都道府県は?','東京都です');
insert into KNOWLEDGE values (3,'日本で一番人口の少ない都道府県の人口は?','鳥取県は2023年7月1日時点で53.85万人です');
commit;
-- データソースとして、KNOWLEDGEテーブルのQUESTION列とANSWER列の複数列を定義したプリファレンス datasourcepref1 を作成する
begin
ctx_ddl.create_preference('datasourcepref1','MULTI_COLUMN_DATASTORE');
ctx_ddl.set_attribute('datasourcepref1','COLUMNS','QUESTION,ANSWER');
end;
/
-- レクサーに JAPANESE_VGRAM_LEXER(BIGRAM=TRUE) を定義したプリファレンス lexerpref1 を作成する
begin
ctx_ddl.create_preference('lexerpref1','JAPANESE_VGRAM_LEXER');
ctx_ddl.set_attribute('lexerpref1','BIGRAM','TRUE');
end;
/
この内容について良くわからない場合はOracle TEXTのアプリケーション開発者ガイドもご参照ください。
テキスト索引の作成
ここまで準備した後に、ようやくテキスト索引が作成できます。
前段で作成した2つのプリファレンス(datasourcepref1、lexerpref1)を指定して KNOWLEDGE_TXTIDX という名前でCONTEXT索引を作成するコマンド例を記載します。
同期モードは ON COMMIT として作成します。
なお、このテキスト索引はKNOWLEDGEテーブルのANSWER列を検索したときに利用される索引として作成します。
-- context索引の作成
-- KNOWLEDGEテーブルのANSWER列に対し、datasourcepref1とlexerpref1、ON COMMITの条件で作成
create search index KNOWLEDGE_TXTIDX on KNOWLEDGE(ANSWER) for text parameters('DATASTORE datasourcepref1 LEXER lexerpref1 SYNC (ON COMMIT)');
今回はKNOWLEDGEテーブルのQUESTION列とANSWER列に対するテキスト索引を作成していますが、KNOWLEDGE_TXTIDXはANSWER列に対して付与していますので、ANSWER列に対するSELECT文で利用されるようになります。
以上の作業を行うことで、テキスト索引を作成することができました。
テキスト索引の検索の検証
先ほど作成したテキスト索引を利用して「鳥取県の人口」を調べてみましょう。
KNOWLEDGEテーブルに「鳥取県の人口」という文字は含まれていないので、「鳥取県の人口」で検索をしてもヒットしないことが予想されます。
ただし、「鳥取県」「人口」であれば、ID=1とID=3のデータがヒットするハズです。
SQL> select ID, QUESTION, ANSWER, score(1) from KNOWLEDGE where contains (ANSWER, '鳥取県の人口',1) >0 order by score(1) desc;
★ヒットしない
SQL>select ID, QUESTION, ANSWER, score(1) from KNOWLEDGE where contains (ANSWER, '鳥取県 and 人口',1) >0 order by score(1) desc;
ID QUESTION ANSWER SCORE(1)
---------- ---------------------------------------- ---------------------------------------- ----------
3 日本で一番人口の少ない都道府県の人口は? 鳥取県は2023年7月1日時点で53.85万人です 4
1 日本で一番人口の少ない都道府県は? 鳥取県です 3
★ヒットした
SCORE(1)はOracle TEXTのスコア値となります。
ID=3は「人口」という文字が複数回出現しているため、ID=1よりもスコアが高くなっています。
なお、今回は「鳥取県」と「人口」のAND演算を行いましたが、同様に OR や NOT も利用可能です。
また、ワイルドカード演算子(%)は日本語の文字検索では利用できず、英語の文字検索では利用できます。
Oracle TEXT を利用した際に良くある問題
Oracle TEXTを利用していると、以下のような問題が起きるケースがあります。
- テキスト索引で検索しても、ヒットしてほしいデータがヒットしない問題
- テキスト検索が遅い問題
この時に疑うべき内容について記載します。
テキスト索引で検索しても、ヒットしてほしいデータがヒットしない時に確認すること
テキスト索引を作ったんだけど、ヒットしてほしいものがヒットしないケースが生じた場合、疑うべきは以下です。
- JAPANESE_LEXERを利用していないか
- 同期モードがMANUALになっていないか
JAPANESE_LEXERは辞書を利用してトークン分割するので、単語の一部だけを利用した検索はヒットすることができません。
また、同期モードをデフォルトのMANUALにしている場合は更新データが索引に反映されないため、挿入したデータが検索されないといったことが起こりえます。
作成したテキスト索引のレクサーや同期モード、データストアの情報はディクショナリ情報から確認することができます。
以下に、KNOWLEDGE_TXTIDXが利用しているレクサーの種類や同期モード、データストア情報を確認するSQLを記載します。
-- KNOWLEDGE_TXTIDXが利用しているレクサーを確認するSQL
SQL> select * from CTX_USER_INDEX_VALUES where IXV_INDEX_NAME = 'KNOWLEDGE_TXTIDX' and IXV_CLASS='LEXER';
IXV_INDEX_NAME IXV_CLASS IXV_OBJECT IXV_ATTRIB IXV_VALUE
-------------------- ---------- ---------------------- ---------- --------------------
KNOWLEDGE_TXTIDX LEXER JAPANESE_VGRAM_LEXER BIGRAM YES
★ JAPANESE_VGRAM_LEXERで、BIGRAM属性がTRUEであることが確認できます。
-- KNOWLEDGE_TXTIDXの同期モードを確認するSQL
SQL> select IDX_NAME, IDX_SYNC_TYPE, IDX_SYNC_INTERVAL from CTX_USER_INDEXES where IDX_NAME = 'KNOWLEDGE_TXTIDX';
IDX_NAME IDX_SYNC_TYPE IDX_SYNC_I
-------------------- -------------------- ----------
KNOWLEDGE_TXTIDX ON COMMIT
★ 同期モードがON COMMITであることが確認できます。
-- KNOWLEDGE_TXTIDXのデータソースを確認するSQL
SQL> select * from CTX_USER_INDEX_VALUES where IXV_INDEX_NAME = 'KNOWLEDGE_TXTIDX' and IXV_CLASS='DATASTORE';
IXV_INDEX_NAME IXV_CLASS IXV_OBJECT IXV_ATTRIB IXV_VALUE
-------------------- ---------- ---------------------- ---------- --------------------
KNOWLEDGE_TXTIDX DATASTORE MULTI_COLUMN_DATASTORE COLUMNS QUESTION,ANSWER
★ データソースがDBの複数列にまたがるMULTI_COLUMN_DATASTOREであり、
QUESTION列とANSWER列に対するテキスト索引であることが確認できます。
分割したトークン自体を以下のSQLで確認することもできますので、そのトークンの中に検索させたい文字が含まれているかどうかも確認するのも有効です。
このトークンは内部的に作成される DR$索引名$I テーブルのTOKEN_TEXT列から確認できます。
SQL> select token_text from DR$KNOWLEDGE_TXTIDX$I;
TOKEN_TEXT
----------
1
2023
53.85
7
ANSWER
QUESTION
い都
す
で
です
で一
ない
の人
の多
・・・(略)
JAPANESE_VGRAM_LEXERをデフォルト(BIGRAM=FALSE)で利用しているときに、想定しているキーワードでヒットしない場合は、BIGRAMをTRUEにすることで改善する可能性があります。
上記のトークンの中で検索したいワードがあるかどうかを確認し、BIGRAMでテキスト索引を作ることも検討いただくのが良さそうです。
テキスト検索が遅いときに確認すること
テキスト検索の性能が悪くなってきたケースでは、テキスト索引が断片化している可能性を疑います。
テキスト索引の断片化具合はCTX_REPORT.INDEX_SIZEを利用して具体的に確認することができますが、そもそも索引の最適化の頻度が少ない場合は断片化が原因である可能性が極めて高いと考えられます。
索引の最適化には様々なモードがありますが、主に以下の3つから選びます
- FAST : 高速モード
- 断片化した行が圧縮されるけど、削除済みデータはテキスト索引から削除されない
- 削除や更新が無いマスターテーブルに付与されたテキスト索引ならこのモードで十分
- FULL :完全モード
- 断片化した行が圧縮され、削除済みデータもテキスト索引から削除される
- 最適化中の処理は実施できるが、時間がかかるので、実行時間を指定することもできる(指定した時間だけ処理するイメージ)
- REBUILD :再構成モード
- 断片化した行が圧縮され、削除済みデータもテキスト索引から削除され、索引セグメントのHWMも下がる
- 最適化中はテキスト索引を使った処理が失敗する可能性がある
断片化具合にもよりますが、一般的には実行時間としては、高速モード > 再構成モード >> 完全モード というイメージです。(断片化具合がすごい場合、REBUILDが最短になると思います)
メンテナンス時間が十分に確保できる場合は定期的な再構成モードでの最適化が良いですが、メンテナンス時間が確保できない場合は高速モードや完全モードを検討します。
特に完全モードは例えば2時間だけ行うといったモードも指定できますので、メンテナンス時間が決まっている場合などにおいても活用することができます。
コマンドの詳細はCTX_DDL.OPTIMIZE_INDEXのリファレンスマニュアルをご参照ください。
これからのOracle TEXTの活用シーン
RAGを行うケースではベクトルデータベースを活用することが一般的ですが、例えば特定のキーワードを利用して検索させたいといったケースでは全文検索を活用し、抽出したデータをプロンプトとしてLLMに問い合わせを行うことで意図した回答をLLMから回答させることができると考えられます。
また、ベクトルデータベースでの検索結果と、全文検索での検索結果を抽出し、cohereで実現可能なrerankを実施して、より回答に近いものを選択させることもできます。
精度を向上させる1つの方法として全文検索をりようすることも考慮にいれて、RAGの精度向上を行っていただけたらと思います。
動画解説