はじめに
Azure OpenAI on your data のサービスが利用開始になり、Azure Cognitive Search のデータを参照してChatGPTがいい感じで返してくれるシステムを簡単に構築できるようになりました。
ただ、手元にある Oracle Database に格納されているデータを参照してChatGPTがいい感じの回答をしてくれたらいいのになぁ・・・と思い、それっぽいものをLINEのボットとして作ってみました。
実際に作ったLINEボットを使った時の画面はこちらです。
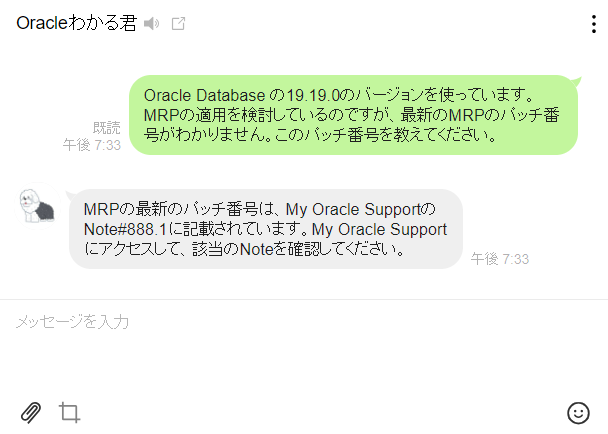
普通のChatGPTに聞いたときに回答してくれるような内容ではなく、ちゃんとナレッジ情報に存在する専門的な内容について回答してくれていますね!
この記事では細かいコードは記載しませんが、システムの構成や利用したアーキテクチャなどを紹介します。
動作環境について
本環境はOracle Cloud の Autonomous Database と Compute を活用しました。
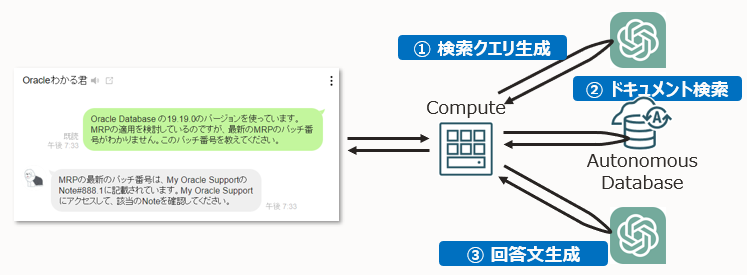
Compute の代わりに Oracle Functions を利用し、Autonomous DatabaseをAlways Freeで構築すれば、費用としては0円に近くなるかもしれません。
システム概要
事前にAlways Freeとして作成した Autonomous Database の中にOracle Databaseのナレッジ情報を登録しておき、
LINEで質問を入力すると Autonomous Database にあるナレッジを検索し、取得されたナレッジ情報をChatGPTに渡してそれっぽい回答をしてくれます。
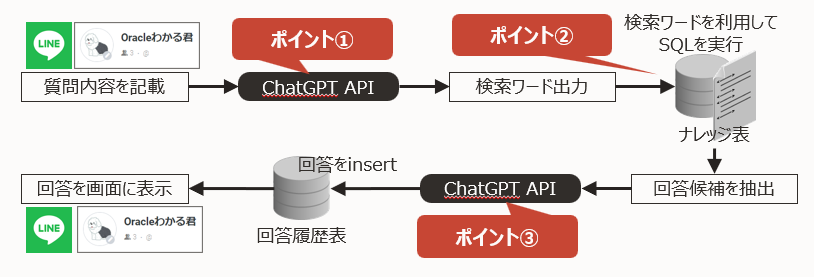
それぞれの「ポイント」の部分で何をやっているかを後述します。
利用したPythonのパッケージ
- Flask 2.3.3
- line-bot-sdk 3.3.0
- openai 0.27.9
- oracledb 1.4.0
- python-dotenv 1.0.0
※ cx_Oracle がいつのまにか python-oracledb に変わっていました。
ポイント① 検索ワードを抽出する
質問文の中からDBに格納されているナレッジ情報を検索するにあたって、いい感じの検索ワードを抽出する方法としてChatGPTを活用します。
プロンプトエンジニアリングを活用し、この次のステップでDB検索する際にSQLに埋め込めるような形式でデータを取得するのがポイントです。
例えば、LINEで「Oracle Database の19.19.0のバージョンを使っています。MRPの適用を検討しているのですが、最新のMRPのパッチ番号がわかりません。このパッチ番号を教えてください。」という質問文が line_message.text に入っている場合、以下のようにaskGPT1にChatGPTに投げる文字を作成してChatGPT APIで問い合わせを行っています。
askGPT1 = "1つの質問が提示されています。\n"\
"あなたのタスクは、提示された質問の内容を検索する際に使えそうなキーワードを3つ抽出することです。\n"\
"なお、AA,BB,CCというキーワードを抽出した場合は、以下のように回答してください\n"\
"‘AA or BB or CC’\n\n質問:" + line_message.text

回答方法をこんな形式にしている理由は、この方法で取得した「'Oracle Database or 19.19.0 or MRPの最新パッチ番号'」の文字列を次のステップでそのまま活用するためとなります。
では、次のステップでSQLの実行の部分ついて解説しましょう。
ポイント② キーワードを利用してナレッジを検索する
検索ワードを利用してナレッジから該当する情報を抽出する際に、単にキーワードを含むメッセージを抽出しても答えに近いかどうかはわかりません。
質問の内容に近い回答をDBから抽出してあげる必要があります。
ただ、それを実装するのは結構大変なので、ここではOracle Databaseに搭載されている機能である Oracle TEXT を活用します。
Oracle TEXTとは
Oracle Database に実装されているテキスト検索の機能です。
検索したレコードごとにOracle TEXTとして定められたscoreを算出し、スコア順に検索結果を出すことができます。
利用するうえでライセンスは不要であり、Oracle Databaseをインストールする時にOraccle TEXTのオプションを指定していれば利用することができます。
Oracle Cloud で Autonomous Database を利用している場合は最初からインストールされているため、Always Freeの環境でも利用が可能です。
Oracle TEXTには日本語に適したレクサーがすでに搭載されていますので、Oracle TEXTがインストールされていれば特に準備することなく、すぐに使うことができます。
なお、Oracle TEXTでテキスト索引を作るユーザーには ctxapp ロールが必要となりますので、事前に以下のようなコマンドで権限を付与しておいてください。
以下、サンプルで作成したknowledgeユーザーに対してctxapp ロールを付与するSQLです。
SQL> grant ctxapp to knowledge;
Oracle TEXTを利用したテキスト索引の作成方法と利用方法
例えば以下のようなテーブルを作成し、ナレッジを挿入しておきます。
テーブル名や列名などは私の思いつきなので、皆様好きなテーブルを作成いただけたらと思います。
SQL> create table knowledge_tab (
no number, --ナレッジ番号
create_date date, --ナレッジ登録日
title varchar2(2000), --ナレッジのタイトル
summary varchar2(2000), --ナレッジの質問文を記載した列
answer varchar2(2000), --ナレッジの回答文を記載した列
scol clob); --ナレッジ検索するための列(質問文+回答文)
ナレッジをinsert後、質問文と回答文が格納されている列に対してテキスト索引を作ります。
上記ならscol列に対してテキスト索引を作るイメージです。
scol列に対してテキスト索引を作成するサンプルのSQLは以下となります。
SQL> create index knowledge_txtidx on knowledge_tab(scol)
indextype is ctxsys.context parameters ('lexer JAPANESE_VGRAM_LEXER');
上記のコマンドでscol列にテキスト索引が作成されました。
このテキスト索引を利用してナレッジ検索ができるかselect文を実行して検証してみます。
試しに、「Oracle Database」「19.19.0」「最新のパッチ番号」のキーワードをscol列で検索し、抽出されたデータとそのスコア値の中で上位3レコードを抽出してみます。(同じスコアの場合は登録日付の新しい方が上になるようにする)
以下のSQLを実行することで、その結果を得ることができます。
SQL> select title, answer, score from
(select no,title, answer, score(1) as score
from knowledge_tab
where contains (scol, 'Oracle Database or 19.19.0 or MRP or 最新のパッチ番号',1) >=0
order by score desc, create_date desc)
where rownum <= 3;
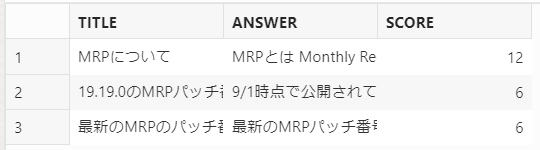
ステップ①で取得した「'Oracle Database or 19.19.0 or MRPの最新パッチ番号'」のキーワードを利用して、Oracle Databaseに格納されたナレッジの中から質問文のキーワードに適合値の近いナレッジ情報を抽出することができました。
ここで取得したナレッジ情報を活用して、次のステップでChatGPTにそれっぽい回答を生成してもらいます。
ポイント③ ナレッジを活用して自然な回答文を作る
取得したナレッジ情報を使ってChatGPTに質問を投げ、回答を取得します。
ここでもプロンプトエンジニアリングを活用して、それっぽい回答をしてくれる工夫をしています。
例えばLINEで質問した「Oracle Database の19.19.0のバージョンを使っています。MRPの適用を検討しているのですが、最新のMRPのパッチ番号がわかりません。このパッチ番号を教えてください。」という質問文が line_message.text に入っており、かつDBから取得した3つのナレッジ情報がresults.answerに格納されている場合は、以下のようにaskGPT2にChatGPTに投げる文字を生成してChatGPT APIで問い合わせを行っています。
askGPT2 = "三重引用符で区切られた3つの参考文書と一つの質問が提示されます。\n"/
"あなたのタスクは、提示された参考文書の内容を参考にして回答することです。\n"\
"もし参考文章に質問への回答に必要な情報が含まれていない場合は、回答冒頭に"\
"「DBのナレッジ情報には含まれていませんでした」と記述し、"\
"ナレッジ情報を参照せずに回答をしてください。\n\n"
for answer in results:
askGPT2 = askGPT2 + "'''" + answer + "'''\n\n"
askGPT2 = askGPT2 + "質問:" + text_message.text

ここで取得したデータを回答履歴表に質問とともにinsertし、回答をLINEで返答させています。
その他工夫している点や反省点など
回答の揺らぎをできるだけなくするため、ChatGPT APIを利用する際に、temperature=0にしています。
また、ポイント①の部分について想定外の回答が返ってくるケースがあってSQLの実行にたまに失敗するため、検索クエリ生成についてはChatGPTを活用せずに別の方法(Yakeなどのキーフレーズ抽出)の方が安定するかもしれないです。
Oracle TEXTを使う場合は索引のメンテナンスも考えないといけないのと、ナレッジとして同じ単語が多く入っている場合にスコアが高くなりやすいため、ナレッジ登録する人がいろいろ気を付けて登録してあげないと、想定した検索結果が返ってこないことがあるので注意が必要です。