はじめに
「WACUL Advent Calendar 2016」、11日目の記事です。
今回は、airbnb製の可視化ツール、supersetを一通り触ってみた感想と紹介を書いてみます。
supersetとは
公式には http://airbnb.io/superset/index.html に書いてあります。個人的には以下のようなツールだと認識しています。
- 柔軟なデータ入出力機構
- Flaskベースのwebアプリケーション
- 豊富な組み込みの管理機能
また、ubuntu16.04で試したところ導入は楽でした(公式サイトに乗ってるとおりの手順であっさり)
柔軟なデータ入出力機構
supersetは、蓄積されたデータを出力するのに、グラフとして出力したりjsonだったりcsvだったりと様々な出力フォーマットに対応しています。また、入力元もMySQLやPostgresSQLなど色々と対応しています。
Dashboard, Slice
supersetには、"Dashboard"と"Slice"というコンポーネントがあります。DashboardがSliceの集まりであるようなイメージです。Sliceというのは、簡単に言うとDashboardの中で意味のある表示単位だと理解しました。
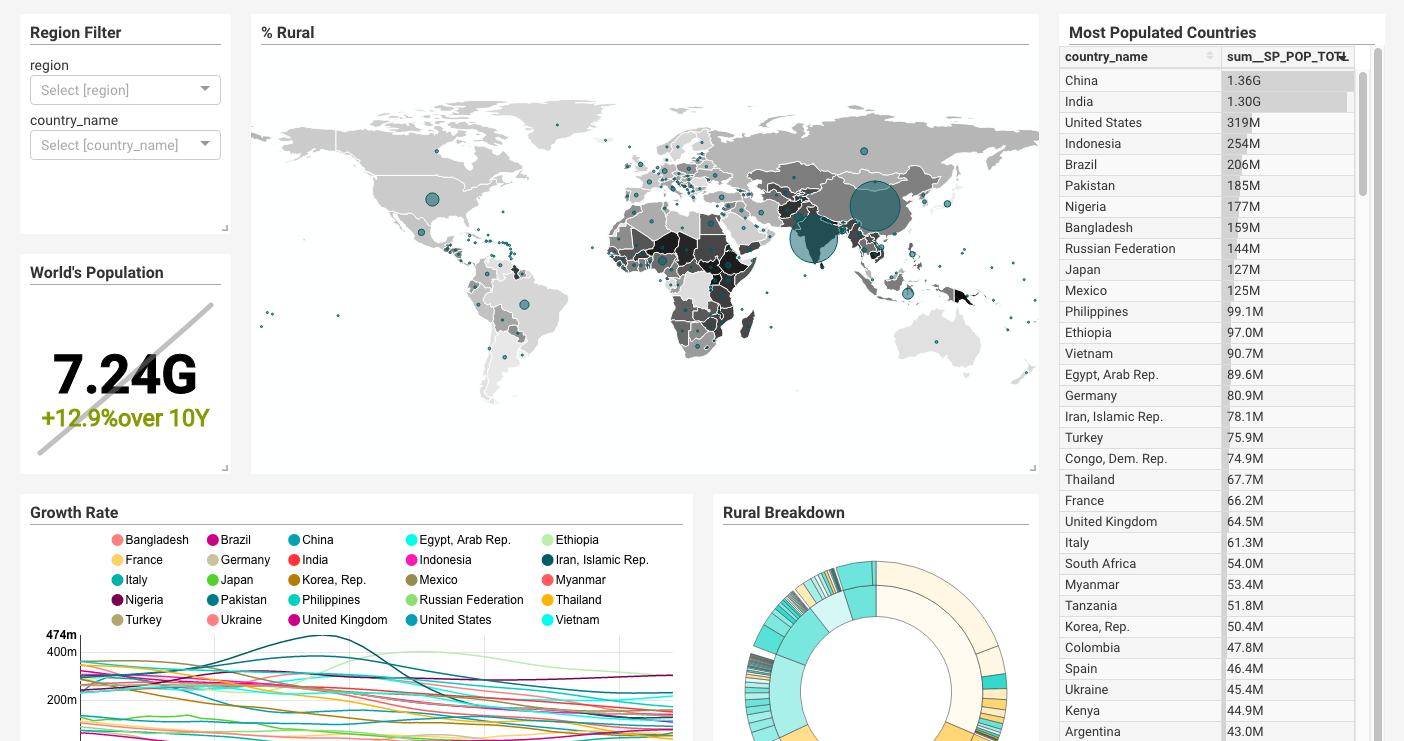
この画像でいうと、画面全体がDashboard、"Region Filter" "%Rural" "Growth Rate" などがSliceになります。
Dashboardの画面のどこにどのSliceを置くか、といった設定は管理画面からできるようになっています。
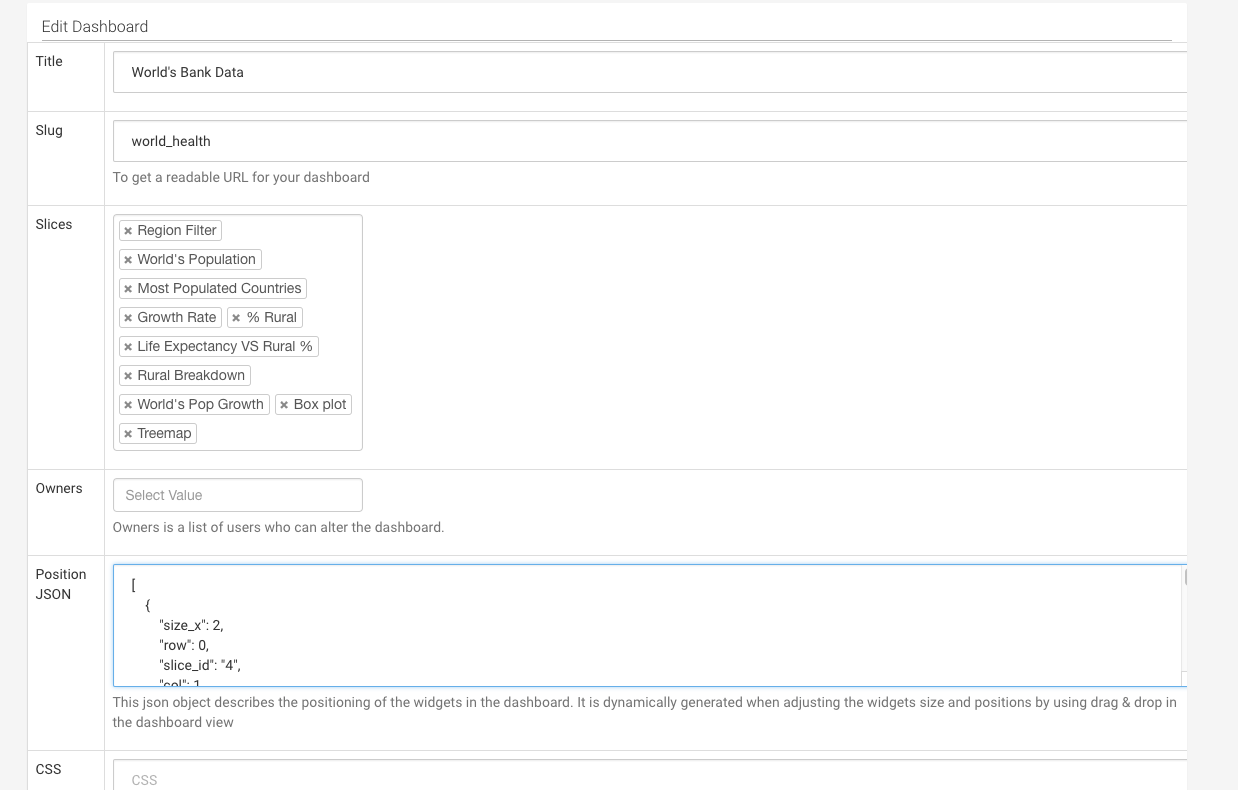
ちょっと見づらいですが、"Slices"のフォームにどのSliceをDashboardに載せるか、"PositionJSON"のフォームにどの位置に配置するのかを書きます。
Slice, Visualization Type, Datasource
Sliceを構成するのは、「データ自体」と「表示の方法」の2つです。それぞれの役目を担うコンポーネントを、supersetでは"Datasource", "Visualization Type"と呼んでいます。supersetには多くのVisualization Typeが用意されています。

(↑は一部です)
Flaskベースのwebアプリケーション
supersetは、Flaskをベースに構築されたwebアプリケーションです。Flaskの開発に慣れている人であれば簡単にカスタマイズできると思います。
豊富な組み込みの管理機能
認証やアクセス制御の方法が豊富です。
ユーザの属性としてRoleを設定できて、さらに各Roleごと許可されるアクションを設定できます。また、更新系のアクションであればログが残ります。
自作しようとすると一手間かかると思いますが、supersetなら一行もコードを書かずに実現できるのが嬉しいところです。
ちなみに、デフォルトだと自前管理のDBに書き込むタイプのパスワード認証ですが、先に紹介した通りFlaskベースのアプリケーションですので、OAuthなど認証タイプを変更することも可能です。(OAuthするならviewまわりの開発が必要だと思います)
自前のデータでsupersetを使ってみる
せっかくなので、自前のデータでsupersetを使ってみます。今回は以下のことをやりました。
- データ元をMySQLに切り替える
- いくつかのVisualizationTypeでデータを可視化する
データ元をMySQLに切り替える
まず、superset_config.py に以下のように書きます。
SQLALCHEMY_DATABASE_URI = 'mysql://root:testtest@localhost/tdb1'
これで、rootユーザ、パスワードtesttest、tdb1という名前のデータベースに接続できるようになります。
次に、ユーザ作成を含めたsupersetの初期化を以下のとおり実行します。
fabmanager create-admin --app superset
superset db upgrade
superset init
これで完了です。以下のようなテーブルが作成されたことを確認します。
mysql> show tables;
+-------------------------+
| Tables_in_tdb1 |
+-------------------------+
| ab_permission |
| ab_permission_view |
| ab_permission_view_role |
| ab_register_user |
| ab_role |
| ab_user |
| ab_user_role |
| ab_view_menu |
| access_request |
| alembic_version |
| clusters |
| columns |
| css_templates |
| dashboard_slices |
| dashboard_user |
| dashboards |
| datasources |
| dbs |
| favstar |
| logs |
| metrics |
| query |
| slice_user |
| slices |
| sql_metrics |
| table_columns |
| tables |
| url |
+-------------------------+
28 rows in set (0.00 sec)
いくつかのVisualizationTypeでデータを可視化する
まず、データを準備します。今回は、Googleトレンドのデータを使いました。2015/12/01-2015/12/31で「恋人」「リア充」のキーワードで日次のスコアを取得して可視化します。
まず、このようなテーブルを準備します
mysql> desc trend201512;
+---------------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| date | date | NO | | NULL | |
| score_koibito | int(11) | NO | | NULL | |
| score_riajuu | int(11) | NO | | NULL | |
+---------------+---------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
その後、データをimportしてsuperset側のdatasourceとして登録します。
色々な設定をした後、VisualizationTypeをtable viewとline chartに設定したsliceを作成すると、以下のようなダッシュボードができます。
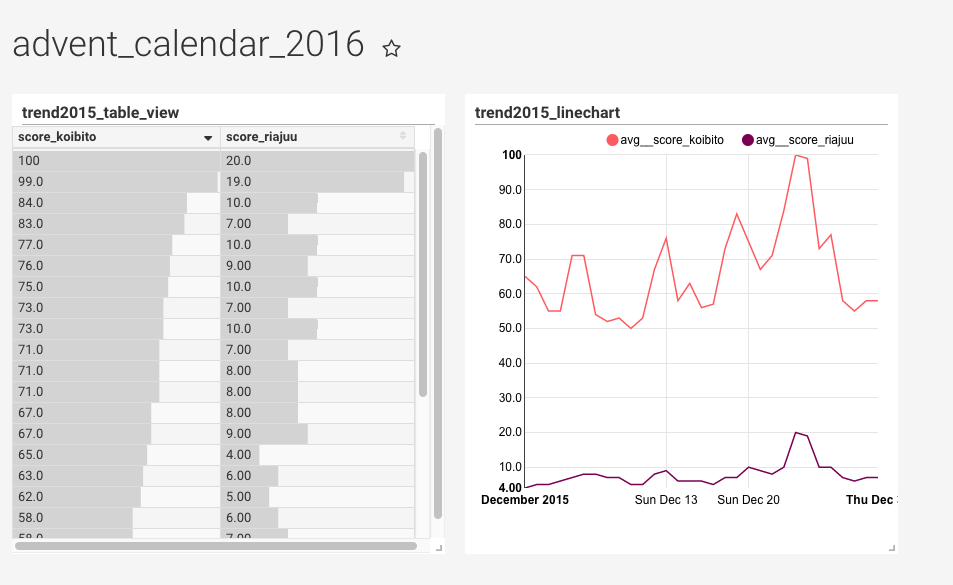
何らかの理由により、平日にもかかわらず24日と25日のスコアが高いことが読み取れました。
ちなみに、このグラフを作る過程でsupersetの(個人的に)辛い点も見えてきました。
まず、その前に、supersetの売りは何かというと、「SQLを書かずにデータの抽出(グラフとして表示したりエクスポートしたり)ができる」ことです。
しかしながら、このことが辛いと感じる原因でもありました。
今回のグラフを取得するシステムを自作しようとすると、例えば、まあサーバ側で雑に select date,score_koibito,score_riajuu from trend201512; 的なクエリを発行しつつ返ってきたデータをhighchartsあたりでさくっと描画すれば済みます。何も難しいことはありあません。
一方で、supersetではSQLでやればフィールドを指定するだけの部分で、「metrics定義」という作業が別途必要になります。これは何かというと、各テーブルごとのフィールドに集約関数をかませてエイリアスをつけて使いまわせるようにするための機構で、デフォルトだとcount,avg,sumなどが用意されます。VisualizationTypeに合わせてmetricsも設定します。
今回の例だと、table viewの場合はそもそも集約関数がいらないので、"identity(恒等写像)"というmetrics typeをわざわざ定義するということをやりました。その結果、table viewを作るためにsupersetで発行されるSQLは次のようになります。
SELECT score_koibito AS score_koibito,
score_riajuu AS score_riajuu
FROM trend201512
WHERE date >= STR_TO_DATE('1916-12-11 08:52:13', '%%Y-%%m-%%d %%H:%%i:%%s')
AND date <= STR_TO_DATE('2016-12-11 08:52:13', '%%Y-%%m-%%d %%H:%%i:%%s') LIMIT 50
このSQLはUIを操作することにより自動生成されるもので、手動でSQLを書いて実行することはできないようになっています。また、dateは指定が必須になっていて、dateの指定方法もsuperset独自のDSL的な記法が使われており書きにくいです。
... つらつら書いてみましたが、要するにSQLによるデータ抽出の操作もサポートしてほしいと思いました(UIによる操作で定型作業が効率化されるメリットはわかるのですが)。また、VisualizationTypeによってUIで指定できる項目が違ったりするので(これは、データ構造上当然)見た目ほど学習コストは安くないと感じています。
やろうとしてたけどやれなかったこと
supersetは、重いクエリを投げた時、celeryと連携して非同期実行的なことができるようです。このページに手がかりらしいことが書かれています
http://airbnb.io/superset/sqllab.html
Support for long-running queries - uses the Celery distributed queue
to dispatch query handling to workers
supports defining a “results backend” to persist query results
さいごに
airbnb製の可視化ツールであるsupersetについて書きました。不満も書きましたが、豊富な機能がぎっしり詰まっており素晴らしいツールだと思います。特に、データ解析がメインで可視化には時間をかけられない人にオススメです。また、うまくやればモニタリングにも使えると思いました。
※ ちなみに、SQL書きたいマンはre:dashを使えば良いのかもしれません https://redash.io/
※ SQLlabを使うと直接SQLが書けるように見えますがUIによる運用とどう共存するかのイメージがつかめませんでした。SQLlabはSliceの設定ページとは別に存在しています