はじめに
この記事はwacul アドベントカレンダーの6日目です。
「歌詞で使われる言葉の流行り廃りを可視化してみたら、思いがけない気づきなどありそうで面白いのでは?」 との思いつきのもと、データを入手して1いくつかの観点で分析するということをやりました。
ある言葉が何をもって流行ってるor廃ってるとするかは色々な見方があると思いますが、ここではシンプルに、「ある言葉が、以前と比べてより多くの曲で使われるようになったら流行ってる。少なかったら廃ってる」とします2。ある言葉(単語)が1つの曲で複数回登場する場合がありますが、1回使われたとカウントします。(フレーズの繰り返しで出現頻度が水増しされてしまうのを防ぐため)
また、分析対象期間は入手できたデータ量のバランス等考えて1991年〜2017年としました。
データのサマリは以下の通りです。3
<全期間合計>
| ボキャブラリー数 | 曲数 | アーティスト数 |
|---|---|---|
| 2289 | 189964 | 4748 |
年代別、出現頻度の高い言葉ランキング
まず、3年スパンでの出現頻度は以下のようになりました。
| 1991.0 - 1993.0 | 1994.0 - 1996.0 | 1997.0 - 1999.0 | 2000.0 - 2002.0 | 2003.0 - 2005.0 | 2006.0 - 2008.0 | 2009.0 - 2011.0 | 2012.0 - 2014.0 | 2015.0 - 2017.0 | |
|---|---|---|---|---|---|---|---|---|---|
| 1位 | 心 | 心 | 心 | 心 | 心 | 君 | 君 | 君 | こと |
| 2位 | 夢 | 夢 | 夢 | 君 | 君 | 心 | 心 | こと | 君 |
| 3位 | あなた | あなた | あなた | 夢 | 夢 | 夢 | こと | 心 | 心 |
| 4位 | こと | こと | こと | こと | こと | こと | 夢 | 夢 | 夢 |
| 5位 | 君 | 愛 | 君 | あなた | 何 | 何 | 何 | 何 | 何 |
| 6位 | 愛 | 君 | 何 | 何 | あなた | あなた | 手 | 手 | 手 |
| 7位 | 胸 | 胸 | 愛 | 愛 | 胸 | 手 | 僕 | 僕 | 僕 |
| 8位 | 私 | 涙 | 胸 | 胸 | 涙 | 涙 | 涙 | 誰 | 誰 |
| 9位 | 恋 | 私 | 涙 | 僕 | 僕 | 僕 | あなた | 涙 | それ |
| 10位 | 涙 | 恋 | 私 | 風 | 空 | 胸 | 胸 | それ | 世界 |
それぞれの単語について、それぞれの年代においてどの程度の割合出現するのかを調べると以下のようになりました。割合は、 (その単語の出現頻度)/(全ての曲数)*100 で計算しました。
| 1991.0 - 1993.0 | 1994.0 - 1996.0 | 1997.0 - 1999.0 | 2000.0 - 2002.0 | 2003.0 - 2005.0 | 2006.0 - 2008.0 | 2009.0 - 2011.0 | 2012.0 - 2014.0 | 2015.0 - 2017.0 | |
|---|---|---|---|---|---|---|---|---|---|
| 1位 | 31.6 | 32.0 | 30.7 | 28.8 | 29.7 | 30.4 | 31.2 | 32.3 | 32.6 |
| 2位 | 30.0 | 30.3 | 29.2 | 27.9 | 29.0 | 29.8 | 30.4 | 29.6 | 32.2 |
| 3位 | 28.7 | 29.0 | 28.4 | 27.8 | 28.0 | 26.8 | 28.3 | 28.6 | 27.3 |
| 4位 | 26.4 | 27.1 | 27.9 | 27.6 | 24.3 | 26.8 | 26.6 | 27.0 | 26.1 |
| 5位 | 25.2 | 23.5 | 23.8 | 24.0 | 23.2 | 23.9 | 25.1 | 25.3 | 24.9 |
| 6位 | 24.9 | 22.5 | 22.6 | 23.3 | 22.1 | 21.6 | 22.8 | 23.2 | 22.9 |
| 7位 | 23.2 | 22.5 | 22.6 | 21.3 | 21.8 | 21.4 | 21.6 | 23.0 | 22.9 |
| 8位 | 21.6 | 22.5 | 22.0 | 20.6 | 21.0 | 21.3 | 21.2 | 20.8 | 20.3 |
| 9位 | 20.8 | 22.3 | 21.3 | 20.3 | 20.7 | 21.0 | 20.5 | 20.2 | 19.8 |
| 10位 | 20.6 | 22.0 | 20.5 | 19.4 | 19.8 | 20.7 | 20.2 | 19.2 | 18.5 |
上位10位まではほぼ20%、つまり5曲に1曲は該当の言葉が使われていることがわかりました。1位になると概ね30%の割合で使われています。
時間が経つごとに流行っていった言葉
次は、時間軸上に沿った「出現頻度の変化」、つまり「流行り」に着目します。具体的には、2017年に50位以内に入ったそれぞれの言葉に対して回帰係数を計算して、大きい順に5つ、1991-2017年の変化を可視化してみます。
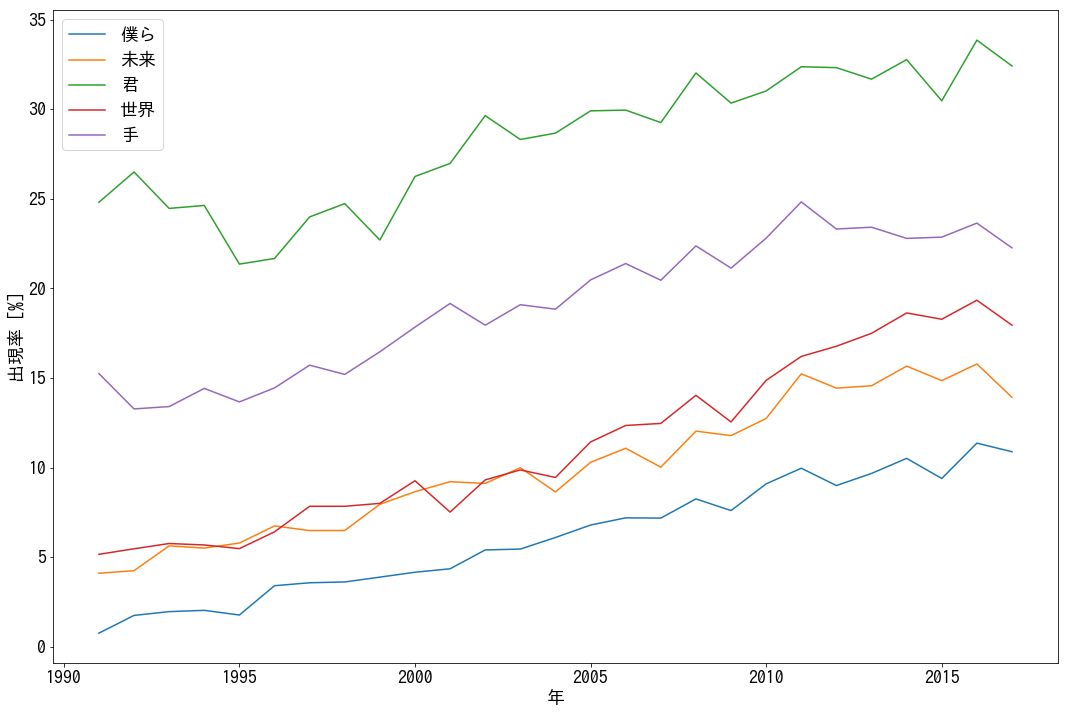
回帰係数は、大きい順に「世界」「未来」「手」「君」「僕ら」となりました。「世界」については1991年に5%程度だったものが2017年には20%近く使われるようになっており、4倍近くまで伸びていることがわかりました。
流行りの言葉をよく使うアーティストを探す
次は、流行りの言葉、ここでは「世界」または「未来」を多用したアーティストをリストアップします。ただし、ある程度のサンプル数を確保したいため全曲数が10以上のアーティストに限定しました。
世界
| アーティスト名 | 全曲数 | 該当曲数 | 出現率[%] |
|---|---|---|---|
| 上北健 | 12 | 10 | 83.3 |
| 北川理恵 | 10 | 8 | 80.0 |
| TRUE | 38 | 30 | 78.9 |
| 赤髪 | 14 | 11 | 78.6 |
| ササキオサム | 12 | 9 | 75.0 |
| miCKun | 10 | 7 | 70.0 |
| Crack6 | 10 | 7 | 70.0 |
| ぼくのりりっくのぼうよみ | 29 | 20 | 69.0 |
| sasakure.UK | 18 | 12 | 66.7 |
| GENERAL HEAD MOUNTAIN | 21 | 14 | 66.7 |
未来
| アーティスト名 | 全曲数 | 該当曲数 | 出現率[%] |
|---|---|---|---|
| リトルブルーボックス | 17 | 13 | 76.5 |
| MAG!C☆PRINCE | 10 | 7 | 70.0 |
| G.Addict | 10 | 7 | 70.0 |
| faith | 33 | 23 | 69.7 |
| トーマ | 13 | 9 | 69.2 |
| 谷本貴義 | 16 | 11 | 68.8 |
| 工藤真由 | 19 | 13 | 68.4 |
| KEN-U | 14 | 9 | 64.3 |
| yozurino* | 11 | 7 | 63.6 |
| 夏代孝明 | 10 | 6 | 60.0 |
時間が経つごとに廃れていった言葉
次は、逆に廃れていった言葉を見ていきます。具体的には、1991年に50位以内に入ったそれぞれの言葉に対して回帰係数を計算して、小さい順に5つ、1991-2017年の変化を可視化してみます。
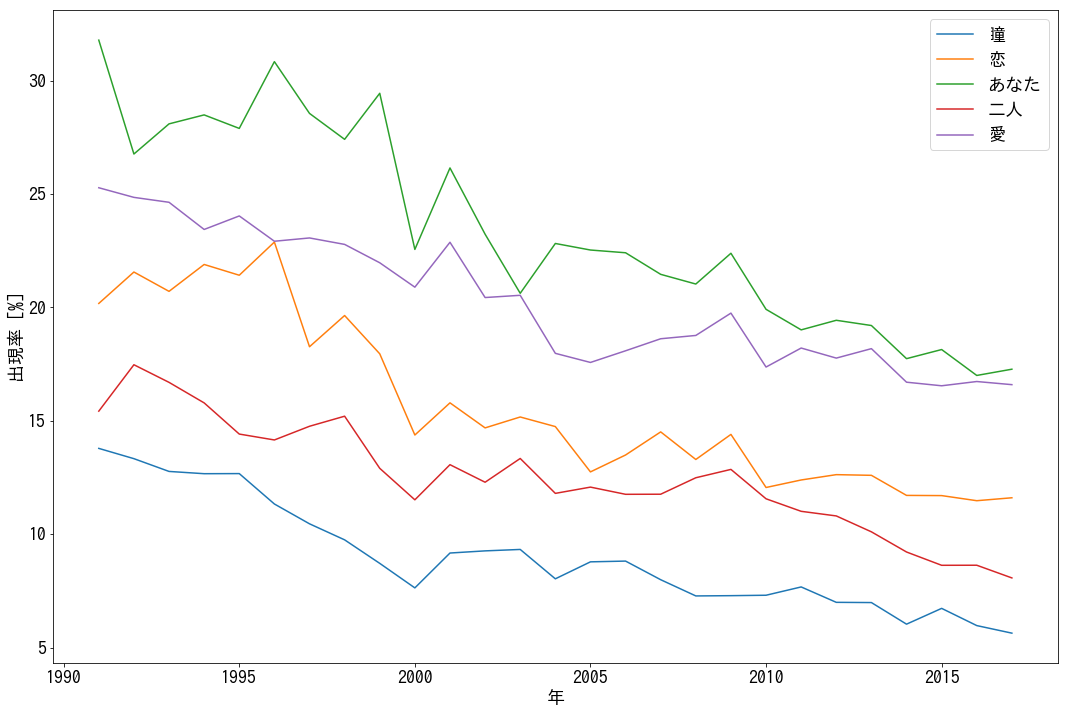
回帰係数は、小さい順に「あなた」「恋」「愛」「二人」「瞳」でした。
おわりに
歌詞データの分析内容を紹介しました。個人的に、今は昔に比べて語感の軽い言葉が選ばれる傾向にあると感じました。二人称として、「あなた」が廃れて「君」が流行ったことなどわかりやすいです。また、最近は「愛」や「恋」といったストレートに内容をイメージできる言葉が避けられ、代わりに「世界」や「未来」といった受け手に想像の自由を多く与えるタイプの曖昧な言葉が選ばれているのがいかにも現代という感じで面白いと思いました。アニソンの影響があるかもしれません。
おまけ
最後に、一応技術っぽい話を書いておきます。
重い処理の結果得られるデータをキャッシュしておき、キャッシュが存在する場合は次回からはこちらから読み込む
みたいな処理、データ解析タスクをやってると稀によくあると思うのですが、どうやるのがベストでしょうか?使いやすいライブラリがあればそれを使いたいのですが(いかにもありそう)、寡聞にして知らないため以下のようなラッパー関数を定義して使ってます。
def cache_located_at(name):
"""
STORAGE_DIRをルートディレクトリするpickle置き場で読み書きするのをサポートする関数
"""
def _func(f):
def __func(*args, **kwargs):
filepath = os.path.join(STORAGE_DIR, name)
if os.path.isfile(filepath):
with open(filepath, 'rb') as fp:
obj = pickle.load(fp)
return obj
result = f(*args, **kwargs)
with open(filepath, 'wb') as fp:
pickle.dump(result, fp)
return result
return __func
return _func
呼び出し側はこういう感じ。resultが自動でpickle化されて os.path.join(STORAGE_DIR, analysis, hogehoge.pickle) に保存され、このファイルが存在する限りこちらから読むようになります。
@cache_located_at('analysis/hogehoge.pickle')
def very_heavy_process():
# 様々な処理
return result
pandasのrank関数
は、とても便利なので使うべきだと思います。何かをソートする時にsort_valuesを良く使っていたのですが、今回のようなランキングを出すタイプのタスクではsort_valuesしてたところをrankに変えると非常に見通しが良くなったりしました。
-
歌詞データはUta-Net (https://www.uta-net.com/) をクロールして入手しました。 ↩
-
単語抽出のための形態素解析にはmecab, 辞書は2017/12/2時点のipadic-neologdを使いました。また、形態素解析結果の属性が(名詞・一般)以外の単語、日本語以外の文字を含む単語、ひらがなorカタカナ1文字の単語は除外するなどのフィルタをかけています。 ↩
-
1991-2017年の全ての年代で少なくとも1回登場した単語を分析対象としました。また、全ての年代合わせて10曲以上入手できたアーティストを分析対象としました。また、曲のリリース日(正確に言うと、多くのケースでその曲が含まれるアルバムのリリース日だと思います)をutanetから取得できる曲を分析対象としました。 ↩