何ページにもわたるテーブルデータ(pdf形式)をpythonとかでいじりたい時に!
私が持っていたpdfデータはページごとに注釈がついていたりして、どのpdf/csvの変換サイトでもうまくできませんでした。
sample1.py
# pdfからcsvに変換するのに使う。ページ指定で1枚ずつしか一気に使えないです。
from tabula import wrapper
# pdfのページ数を数えるのに使う
import PyPDF2
# 任意のファイルパスをここに記載
FILE_PATH = "***"
# ページ数を取得
with open(FILE_PATH, mode='rb') as f:
pages = PyPDF2.PdfFileReader(f).getNumPages()
# このデータフレームに全ページのデータを入れます
df = pd.DataFrame(columns = "欲しいカラム名")
# 全ページのテーブルデータを一つのデータフレームに
for i in range(pages+1):
tmp = wrapper.read_pdf(FILE_PATH, pages = i, encoding = "utf-8_sig", spreadsheet=True)
df = pd.concat([df, tmp], ignore_index=True)
これでデータフレームはこんな感じに。pdf43枚くらいのテーブルデータが2分くらいで一つのデータフレームにできました。
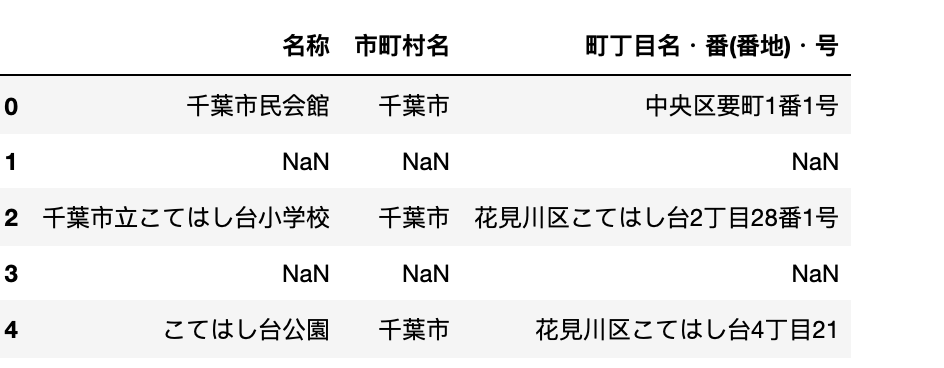
毎行にNaNが入ってしまっているので、
sample2.py
import pandas as pd
df = df.dropna()
をすれば、

こんな感じでとても綺麗なテーブルデータができます。
今回は1つのpdfの変換でしたが、複数のpdfのテーブルデータを一つのデータフレームにしたい時は(例えば国毎年発表している医者の数とかそういうデータ)
sample3.py
import glob
for i in glob.glob("任意のフォルダ"):
#sample1.pyの操作
なんてすれば一気に作業できちゃいます
あとはこの一行
sample4.py
df.to_csv("任意のcsvのパス")
でcsvに変換できます。データフレームで機械学習かけようが、csvでエクセルに通して統計資料まとめたり、いろいろできます!