はじめに
すっかり秋めいてきましたね。田舎暮らしをはじめてもう2年ですが、この時期は朝日や夕日がいつもに増してきれいで、自然のそばに住まわせていただく嬉しさをかみしめている毎日です。
さて今回は、Kubernetesのキャパシティ管理に取り組むべく、Requests・LimitsによるPodスケジューリングをはじめ、KubernetesのPodリソース管理について、しっかり理解していこうと思います。
Requests・Limitsを設定する目的
新規Podを起動すると、Kubernetesは自動的にPodをNodeに割り当てる。(これをスケジューリングという)
スケジューリング後、Podはその負荷に応じて、Nodeのリソースを使えるだけ使おうとし、Pod達によるリソースの奪い合いが起きてしまう。
そのため、各Podが利用できるリソース量を指定し、Nodeに負荷をかけすぎないようにする仕組みがあり、それがRequestsとLimitsである
Requestsとは
Podが最低限必要とするCPU/メモリの最少容量
Limitsとは
Podの負荷が高まった際に使用可能なCPU/メモリの最大容量
Kubernetesの各種コンポーネントによるリソース管理
では、実際にRequests・Limitsにより、Podがどのようにスケジューリングされ、起動後どのようにリソース管理されていくか、順を追って確認していく。
Kubernetesの様々なコンポーネントにより、リソース管理が行われる。下記がそのコンポーネントである
| 名前 | コンポーネント種別 | 説明 |
|---|---|---|
| kube-scheduler | コントロールプレーンコンポーネント | スケジューリングの監視&Node未割り当てのPodに対し、リソース設定等を考慮して最適な割り当てNodeを決定する |
| kubelet | ノードコンポーネント | KubernetesのNodeエージェントで、Podのスケジューリング、起動、管理を担う |
| コンテナランタイム | ノードコンポーネント | Pod上のコンテナの実行を担う |
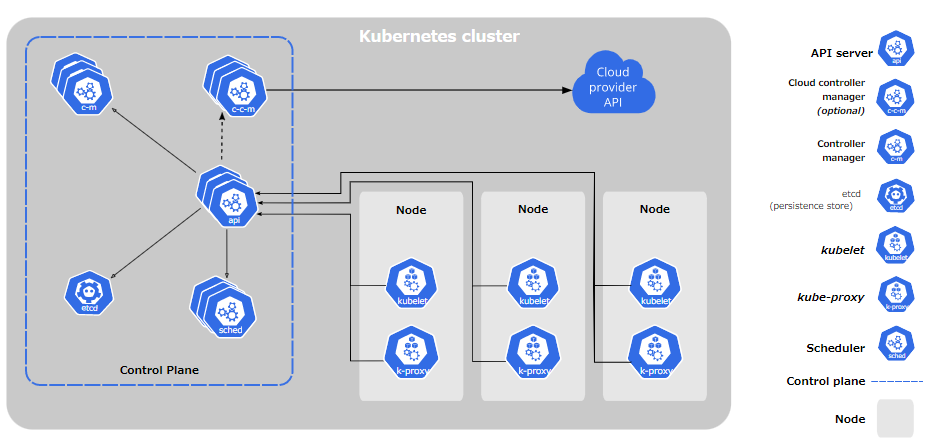
(詳細は下記へ)
1. Pod スケジューリング
Podデプロイ後、kube-scheduler によりスケジューリングが行われ、PodがNodeに割り当てられる。その、下記2点をチェックする。
(1) 対象Podを含めた、Node上で動く全PodのRequests(最小容量)の容量合計が、Nodeの容量よりも少ないこと
(2) Nodeに、対象PodのLimits(最大容量)が確保できること
kube-schedulerによるチェックが失敗するとスケジューリングが失敗する
例
図のようにメモリの容量が100GiBのNode_A、Node_Bがあるクラスタ上で、Pod_4を起動する場合、kube-schedulerは下記の通りにスケジューリングを行う。
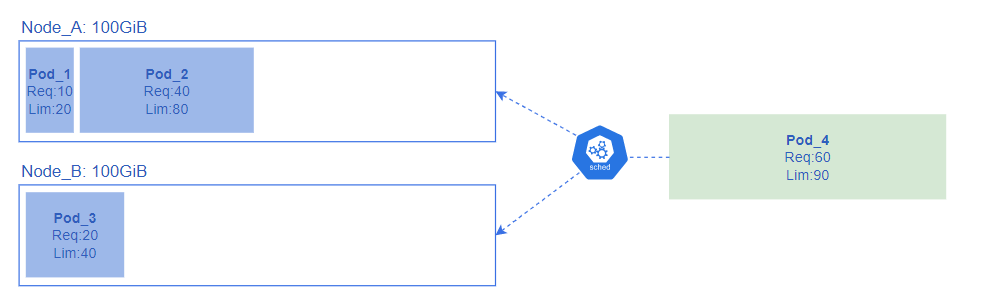
(1) 対象Podを含めた、Node上で動く全PodのRequests(最小容量)の容量合計が、Nodeの容量よりも少ないこと
-
Node_A: 下記により、割り当て不可と判断
全PodのRequestsの合計: 10GiB(Pod_1) + 40GiB(Pod_2) + 60GiB(Pod_4) = 110GiB
Nodeの容量 100GiB < 全PodのRequestsの合計 100GiB -
Node_B: 下記により、割り当て可と判断
全PodのRequestsの合計: 20GiB(Pod_3) + 60GiB(Pod_4) = 80GiB
Nodeの容量 100GiB > 全PodのRequestsの合計 80GiB
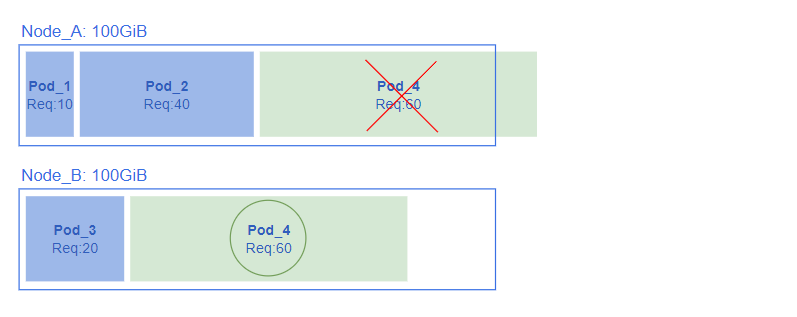
(2) Nodeに、対象PodのLimits(最大容量)が確保できること
-
Node_A, Node_B: 下記により、割り当て可と判断
Nodeの容量 100GiB < 対象PodのLimits 90GiB

上記により、Node_Aは割り当て不可、Node_Bには割り当て可と判断し、kube-schedulerはNode_Bに対し割り当てを行う
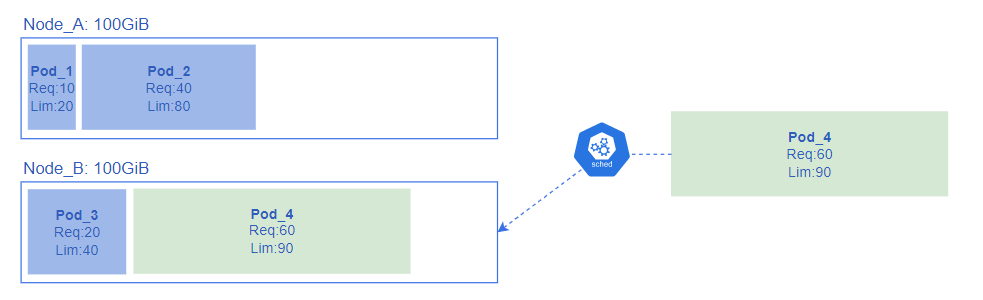
2. Pod リソース確保
Podスケジューリングが成功すると、kubeletはPodに対して、少なくともRequests(最小容量)以上のリソースを確保する。
この時、Nodeにリソースがあまっている場合、下記のようにRequests(最小容量)よりも多くリソースを確保する
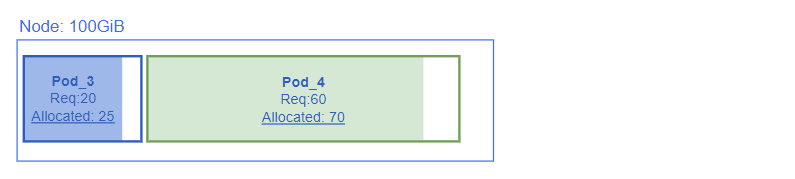
3. Pod 運用
kubeletがPodを起動すると、Limits(最大容量)設定がコンテナランタイムに渡される。
それ以降はkubeletがLimits(最大容量)を超えてリソースを使用することのないよう、管理をする。
Limitsを超えるとkubeletが検知し、下記のしかるべき対応を行う。
メモリがLimitsを超えた場合
プロセスがカーネルにより適当にkillされ、コンテナが(可能であれば)再起動する。
再起動ができない場合、クラッシュし終了する
CPUがLimitsを超えた場合
メモリのようにコンテナが再起動または終了するということはないが、Podの動作が保証されない状態になる
PodのRequests・Limitsの設定箇所
Podの各コンテナは、次の1つ以上を指定することができる
Pod内の全コンテナのRequests・Limits容量の合計値が、PodのRequests・Limits容量となる
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
spec.containers[].resources.requests.hugepages-<size>
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.limits.hugepages-<size>
Requests・Limitsの最適な設定値とは
Requests・Limits間の差が大きい場合
Podのスケジューリングは主にRequestsに基づき決定される。
Requestsの設定値を少なく見積もり、Limitsとの差が大きくなる場合、負荷が高いNodeに対してもPodの割り当てをされてしまい、下記のようなovercommittedの状態になることがある。(Requestsの合計値として空きがあると判断されるため)
よく言えば適切にNodeのリソースを使いあう状態になるのでコスト効率はよいが、Nodeのリソースを使い果たす一歩手前の状態ともいえるため、リスクがある
overcommitted状態とは
下記のように、[ $ kubectl describe node ] コマンドで確認可能。
Requests・Limitsの右に記載されているパーセンテージは、Node上で起動している全PodのLimitsの合計の割合を表している。
下記のように100%を超える状態 = overcommittedしている状態。
全てのPodが付加が高い状態が続くわけではないため、Podがクラッシュすることのない状態になる。
$ kubectl describe node ip-XX-XX-XX-XX.ec2.internal
・・・(省略)・・・
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.) # ★
Resource Requests Limits
-------- -------- ------
cpu XXXX m (XX%) XXXX m (XX%)
memory XXXX Mi (89%) XXXX Mi (210%) # ★
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
attachable-volumes-aws-ebs 0 0
Events: <none>
Requests・Limits間の差が小さい(同じ)場合
RequestsとLimitsの差を小さくする、もしくは同じ値にすると、overcommittedになること、またNodeのリソースを使い果たすリスクを回避できる。しかし、それに引き換えリソースの集約率は低下する。
(※ 因みに、Requests または Limits どちらかのみ指定すると、同じ設定値を指定していない方に自動的に割り当てされてしまうため、要注意)
結論
- Podの安定稼働とリソース集約率はトレードオフ
- おおよそRequestsの1.5~2倍の容量をLimitsに設定し、ユースケースに見合ったチューニングをする
- Podがクラッシュしたり、再起動が走った際は、まずはメモリのスパイクを疑う
おわりに
適切にRequests・Limitsを指定することで、確実なキャパシティ管理が可能になります。
Podを安定稼働させるために、必ず設定するようにしていきましょう