CGM系のサービスで必要そうな「最近よくいいねされてる順」でリアルタイムに検索結果を出力する方法です。
単純ないいね数順ソートの問題
- いいねの累計数が多いコンテンツに検索結果の上位がいつまでも固定されてしまう。
- 直近30日以内のいいね数順のように期間を絞る方法にしても、その期間内のいいねが少なかったり、全く無かったりする検索ワードの場合、上手くいかない。
いいねトレンドスコアを計算する

コンテンツの直近N件のいいねについて、いいね時刻が現在時刻から過去に行くほど値が0に漸近する減衰関数に応じた値を各いいねのスコアとし、それらを全て足し算すると、そのときの「いいねトレンドスコア」が計算できます。最近のいいねほど価値が高く、昔のいいねほど価値が低い重みとなるスコアです。
スコアを計算するコード (Python)
def trend_score(item):
# 直近のいいねN件取得
likes = item.likes[:N]
# いいねトレンドスコアの計算
score = 0
for like in likes:
score += decay(datetime.now(), like.created_at)
return score
# 減衰関数
def decay(t1, t2):
diff = (t1 - t2).total_seconds()
return math.exp(-diff / 3600 / 24 / 40)
このスコアをいいねがある度に計算し、Elasticsearchに保存しておけば、検索時にスコア順にソートすると「いいねトレンド順」で検索結果を出力できます。
しかしこれだけだと問題があり、いいねが途絶えたコンテンツのスコアが更新されず、ずっと高いままになってしまいます。本来ならいいねが途絶えているのでスコアは下がっていくのが正しいはずです。
このスコアは検索対象の全コンテンツで更新する必要があるため、コンテンツ数が少ない場合は全コンテンツのスコアを定期バッチで計算し直すこともできますが、コンテンツ数が多いと現実的でないことがあります。
検索時に最終いいね時刻の減衰関数をスコアに掛け算して近似する
Elasticsearchでは減衰関数をスコア計算に利用することができるため、この問題の解決に使います。いいね時に「最終いいね時刻」もElasticsearchに保存しておき、検索時に下記スコア順でコンテンツを取り出します。
先程定義したいいねトレンドスコア × 最終いいね時刻を入力とした減衰関数のスコア
「最終いいね時刻を入力とした減衰関数のスコア」で利用する減衰関数は「いいねトレンドスコア」で利用した減衰関数と似たものを使います。
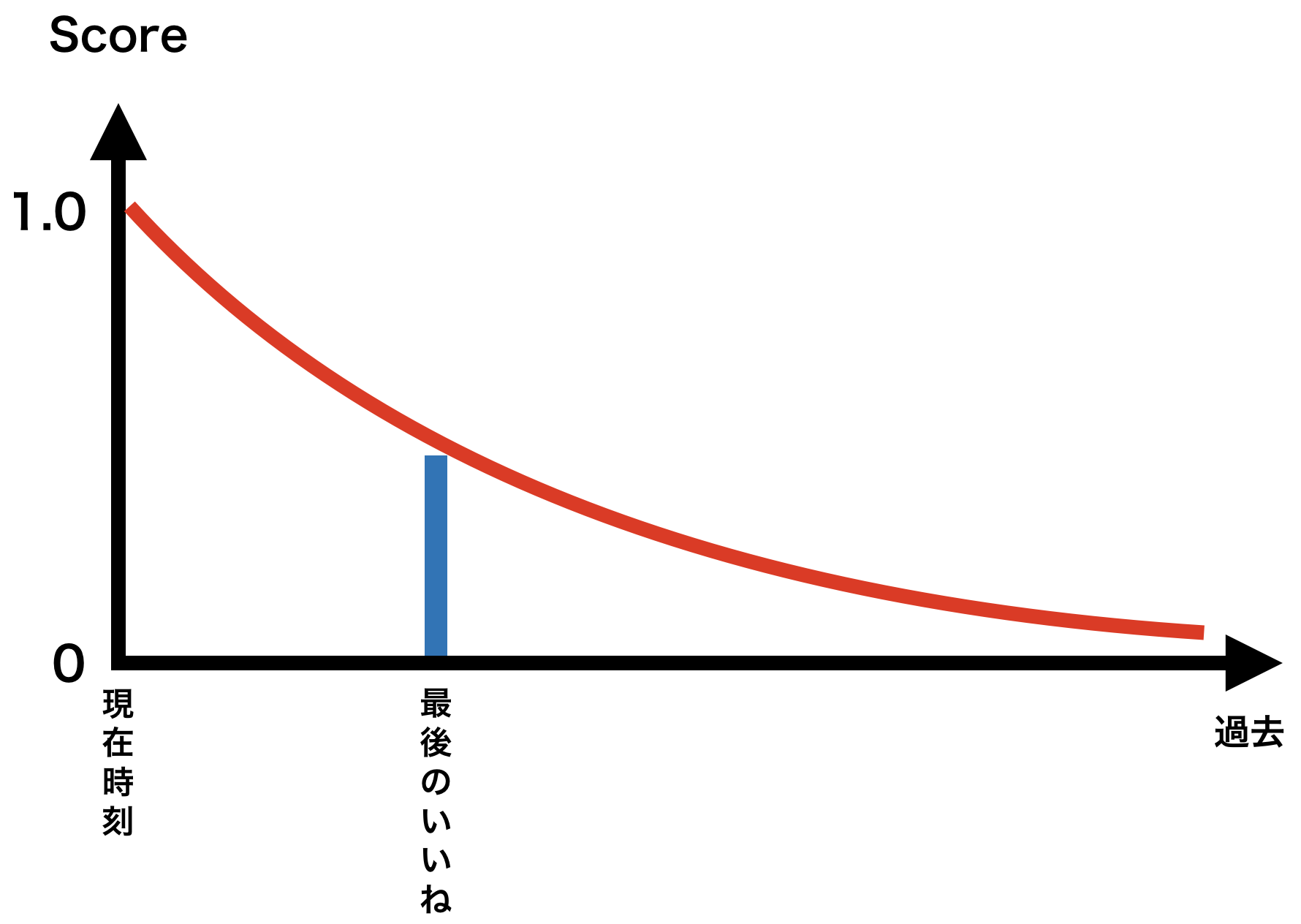
最終いいね時刻が検索時の時刻から離れているほど、検索時の「本当のいいねトレンドスコア」は小さくなるはずです。そのため上のような「最終いいね時刻を入力とした減衰関数のスコア」を検索時に掛け算することで、「本当のいいねトレンドスコア」を近似します。近似の程度は結構雑ですが、実用上問題なければ良いかなと思います。
Elasticsearchのスコア計算部分のクエリは下記のようになります。
"query": {
"function_score": {
"functions": [
{
# いいねトレンドスコア
"field_value_factor": {
"field": "trend_score",
"missing": 0
}
},
{
# 最終いいね時刻の減衰関数
"exp": {
"last_liked_at": {
"scale": "30d",
"decay": 0.5
}
}
}
],
# 掛け算する
"score_mode": "multiply"
}
}
まとめ
Elasticsearchの減衰関数を利用して「最近よくいいねされてる」順で検索結果を出す方法を説明しました。他にももっと良い案がある可能性はあります。いいねデータ自体をElasticsearchに全部保存し、いいねトレンドスコアごと検索時に全部ゴリ押しで計算する方法もできるかもしれません。でもかなりCPU使いそうです。コンテンツ数が少ない場合はバッチでスコア更新したほうが楽かもしれません。サービスのコンテンツ量や性質に応じて設計を考えると良いと思います。