Fluid Annotation: An Exploratory Machine Learning–Powered Interface for Faster Image Annotation
Monday, October 22, 2018
Posted by Jasper Uijlings and Vittorio Ferrari, Research Scientists, Machine Perception
TensorFlow Object Detection APIで実装されているような現代の深層学習に基づいたコンピュータビジョンモデルのパフォーマンスは、Open Imageのようなますます大きくなるラベル付きのトレーニングデータ・セットの可用性に依存します。尚、高品質トレーニングデータの入手は、コンピュータビジョンにおいて主要なボトルネックとなっています。これは、特に自動運転、ロボット技術、および画像検索などのアプリで使用されるセマンティックセグメンテーションなどのピクセル単位の予測タスクの場合に特に当てはまります。実際、従来の手動ラベリングツールでは、境界線を慎重にクリックして、画像内の各オブジェクトの輪郭を描いて注釈を付ける必要があります。これは退屈です。COCO+Stuffデータセットの1つの画像にラベルを付けるには19分かかりますが、データセット全体の画像にラベルを付けるのに、53K時間を要します。
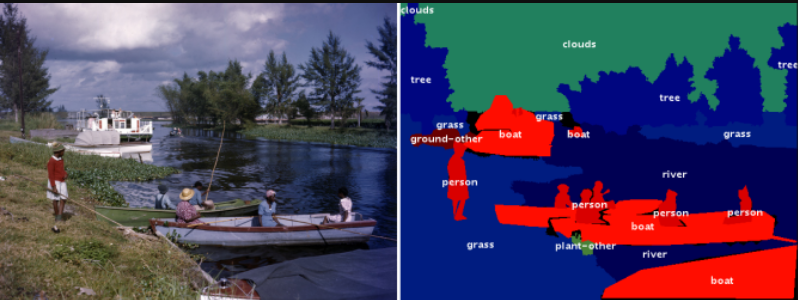
COCOデータセットの画像の例(左)、とそのピクセル単位の意味ラベル(右)。
Image credit: Florida Memory, original image.
2018 ACM Multimedia ConferenceのBrave New Ideas セッションで発表する予定の「Fluid Annotation: A Human-Machine Collaboration Interface for Full Image Annotation」研究では、画像内の全てのオブジェクト及び背景領域のクラスラベルを注釈する、輪郭を描くような機械学習のインタフェースを探索します。ラベル付きデータセットの作成スピードは従来の3倍に加速します。
Fluid Annotationは、人間の注釈者が自然なユーザーインタフェースを使用して、機械支援の編集操作を通して修正することができる強力なセマンティックセグメンテーションモデルの出力から始まります。このインタフェースでは、注釈者が何を修正するか、どの順番で行うかを選択できるようにし、機械がまだ分っていないものに効果的に取り込むことを可能にしています。
COCOデータセットの画像に対するFluid Annotationのインタフェースの可視化
Image credit: gamene, original image.
もっと正確に言えば、画像に注釈を付けるために、事前に訓練されたセマンティックセグメンテーションモデル (Mask-RCNN) を通して最初に実行します。これにより、約1000のクラスラベルと信頼スコア付けの画像セグメントが生成されます。最も信頼度の高いセグメントは、注釈者に提示されるラベリングの初期化に使用されます。その後、注釈者は次のことができます:
(1) 機械によって生成されたショートリストの選択から、既存のセグメントのラベルを変更することができます
(2) 足りないオブジェクトをカバーするためには、セグメントを追加できます。機械は、最も有望な事前生成されたセグメントを識別し、それを介して注釈者がスクロールして最良のものを選択できます
(3) 既存のセグメントを削除できます
(4) 重複するセグメントの深さレベルを変更できます
このインターフェースのより良い使い心地を得るには、デモ版を試してみてください(デスクトップ版のみ)。

3つのCOCO画像に対して、従来の手動ラベリングツール(中)とFluid Annotation(右)を使用した注釈の比較
手動ラベリングツールを使用する場合、オブジェクトの境界はしばしばより正確ですが、注釈相違の最大の原因は、人間の注釈者がしばしば正確なオブジェクトクラスに同意しないためです。
Image Credits: sneaka, original image (top), Dan Hurt, original image (middle), Melodie Mesiano, original image (bottom).
Fluid Annotationは、画像注釈をより迅速かつ容易にするための最初の探索ステップです。今後の作業としては、オブジェクト境界の注釈を改善し、より多くの機械知能を含めることでインターフェイスを高速化し、最終的に効率的なデータ収集が最も必要とされる過去の目に見えないクラスを処理するためのインターフェースを拡張することを目指しています。
お礼
This work was done in collaboration with Misha Andriluka. Special thanks to Christine Sugrue for creating the fluid annotation demo. We also thank Anna Ukhanova and Damien Henry for their valuable input.