このエントリは以下2つのエントリの続編です。
Datalabを中心とした分析環境についての検討
データ分析環境については、分析者の人数であったり企業の業態、規模感等において色々な考え方があり、話を聞くたびに悩ましいなぁというところです。Datalabについては未来を感じているのですが、結論としては、残念ながらまだDatalabだけでは機能的には足りなさそうです。が、ディープラーニングという新しい分析技術がある程度デファクトスタンダードになった今、改めて分析環境については整理する意義はあると思うのでつらつら書いてみます。
分析環境に投資する意義
Rettyさんの事例は大変話題になり、また私自身も参考になりました。昨今ではディープラーニングが流行っておりますので、実用的にはやはりこの方向性に落ち着くのでしょう。弊社も似たような方向性で分析環境は作られています。
また、一昔前のソーシャルゲーム業界などで見られた、データマイニングでゲームを改善して○億円儲かりました、ほどのインパクトはないですが、上述のRettyさんは投資した分以上の回収ができていそうですし、確実に分析環境に投資する意味は見いだせそうです。
想定する分析環境の要件
ここからの話としては、以下を想定しています。
- 分析者が複数人(それなりの数)いる
- 分析するテーマがある程度多岐に及んでいる
- GPUなどの少しコストが高めなリソースも必要となる(ディープラーニングなどで)
データ分析環境の構成
なんとなく分析環境がたどる変遷とともに書いていきます。
各人が手元で環境を構築
分析を始める当初はこんな感じとなるでしょう。

- 各人が必要に応じて分析環境を構築
- データのソースもバラバラで、各人が分析に必要なものを勝手に取ってくる感じ
- 使って良いデータ、使えるデータが明確ではないので全体的に探り探り進める
少人数かつ分析に対してコストを掛けられない状態では致し方ない状態かと思います。
データソースは揃えたい
次のステップとしては、データソースはある程度揃えたいよね、という話になってくると思います。
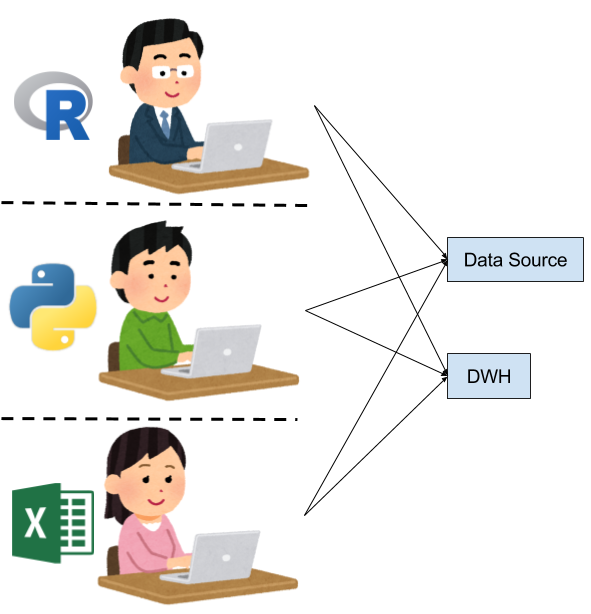
- 共用のストレージやクラウドストレージなどを用意して、そこでデータソースを集約する
- 商用のDWHやHadoopなどを導入し、データの加工や一次処理などは行う
- 加工結果を各人が手元の分析環境に持ち込んで分析を行う
相変わらず分析環境自体は各自がバラバラな感じでしょうが、データソースが一元化されることで改善された点も多いと思います。とはいえ、分析環境がそろっていないため、チームで分析を行うにはコストが高く、各人が独立して分析作業を行っているレベルに留まっています。
分析環境も揃えたい
さらに次のステップとして、分析作業を協働していく、という段階に進んできます。この段階では、分析環境が揃っていないと、分析作業の分担化や、OJTのようなこともやりにくいため、分析環境も揃えたいというニーズが生まれはじめます。
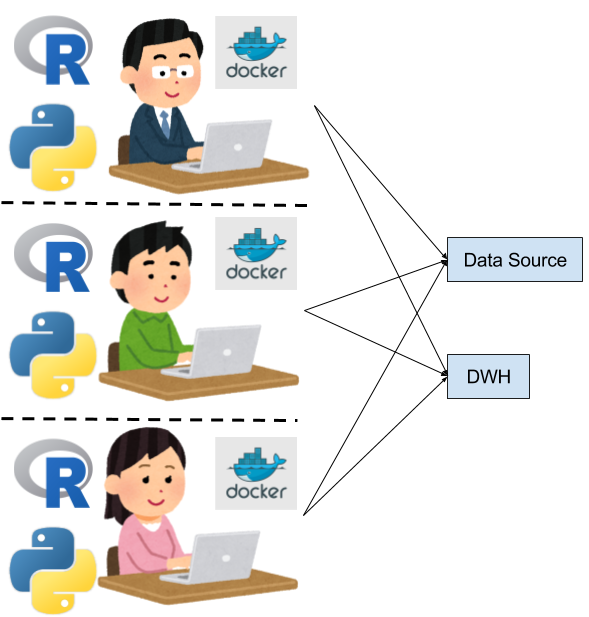
- 大抵は、インストール手順などをドキュメントに残して、新しく始める方には自前で分析環境を構築してもらうことになります
- Jupyterを使ってPythonのバージョンも揃えて、、、みたいな
- いい感じのところは、例えば、分析環境構築済みのVMを提供したり、docker imageレベルで実行環境を揃えて、notebook(ipynb)ファイルを共有する、みたいな感じになってたりします
徐々に分析環境をエンジニア目線で共通化、共用化していくことが重要になってくるフェーズとなります。ディープラーニングが登場するまでは、この段階である程度満足のいく分析環境が作れていたと言えるのではないでしょうか。
ここまでの問題点:クソクエリ問題
ここまでの構成で分析環境として運用していくには課題があります。
それは、データ加工の部分(DWHとかHadoop/Hive、Redshiftなど)が共用のため、他人に作業や管理者に迷惑をかけるクエリ(クソクエリ)が生み出されてしまうということです。DWH部分の管理者はクソクエリを見張ってkillするということが必要になります。
が、一方で分析者目線でいくと、明確にルールが無い場合、可能な限りクエリでデータ加工を進めようとする傾向があり、また、新しくjoinした人は悪気なくクソクエリを発行しガチになります。クソクエリ問題は一般的にはいたちごっこになり、根本的な解決策がないという認識です。
よりリッチな計算資源を確保して共有したい
続いて、最近のトレンドとして、ディープラーニングをまともに取り組むにあたり、GPUを導入したいという流れが出てきています。一般的に、GPUのマシンはCPUマシンよりも調達がややコストが高く、クラウドでもまだ安価で使いやすい状態でない。また、大量にGPUのリソースが欲しいのではなく、せいぜい分析のための高性能かつ数枚のGPUを試験的に導入していく傾向があり、数枚のGPUが使える環境自体をオンプレで作るケースがほとんどのようです。
その場合、GPUマシンは共用するケースが多く、その場合はDockerイメージを活用することが多いように思えます。Rettyさんの事例でもそうですね。深層学習にはデータも多く必要なため、当然、GPUマシンには大きめのディスクをつけて近くに配置することになります。
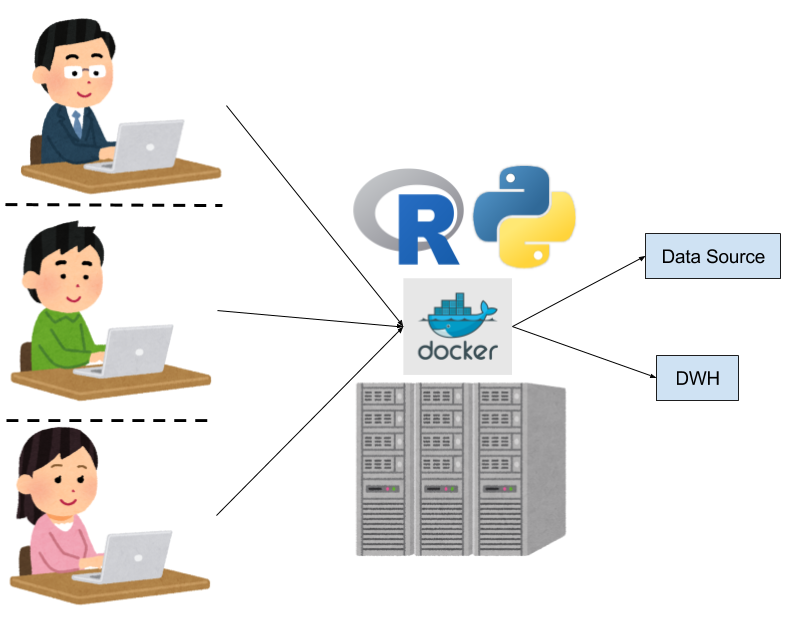
ここでの問題点:GPU借りまーす問題
当然GPUは共有ですので、チャットなどで、GPU借りまーす、お返ししまーす、というやり取りが発生しはじめます。さらにやっかいなことに、ディープラーニングは学習に時間がかかりますので、一度借りるとなかなか返せません。たまたまGPUを使いたい作業が重なると途端にリソースが枯渇しますし、逆に使われない時は全然使われない、ということがおきます。データもオンプレ運用のため、バックアップや容量の問題などが起こりえます。
そこでDatalabを中心としたワークフローを考えてみる
Datalabを中心としたワークフローはここにどうはまるのでしょうか?下記の用になると思います。
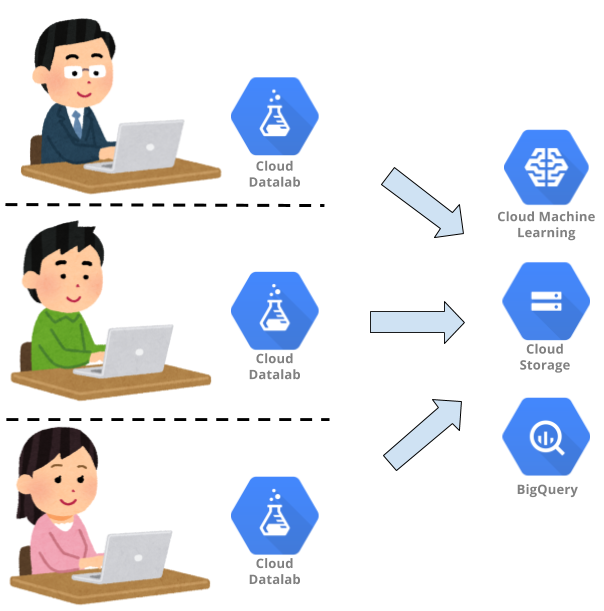
DWH側のアドミン問題(クソクエリ問題対策)
- BigQueryに任せて、クソクエリも力技で解決していく
計算リソースの分離(GPU借りまーす問題対策)
- GCEを使う人用にポコポコ立てることができる
- 他人と共有していないリソースがコマンド一発ですぐに準備できる!
- 必要に応じてインスタンスのスペックを上げたり下げたりも可能
データ容量有限問題(GPU借りまーす問題対策)
- DatalabからはGCSへアクセスできるので、容量問題は事実上解決されそうです
その他色々
- Googleアカウントと連携できる!
- IAMと連携して適当に制約を掛けられるので、割と柔軟に管理はしやすそう
Datalabは全部うまくいきそうです(と言いたかった)
で、Datalabサイコー、みんな使おう!って言いたいのですが、GPUインスタンが使えないので崩壊しました(笑)
惜しい、惜しいぞおおおお。あと、一部でご指摘いただきましたが、DatalabはPython2系問題もあります。
まだまだ課題は多いですが、Datalabを中心としたGCP上のデータ分析環境には個人的には注目していきたいと思っています。
って、話をまさかのCloud NEXT Extendedと被っている4/1に開催されるどアウェーな勉強会で話してきます。