はじめに
こんにちは。検索が好きなrilmayerです。
この記事は情報検索・検索エンジン Advent Calendar 2019の20日目の記事です。
最近2つの検索サービス立ち上げに関わっておりましたので、そこでの経験などを少し抽象化して検索サービス立ち上げ時に考慮すると良いことなどを共有したいと思います。
この記事の流れは以下のような感じになります。
- 検索サービス立ち上げ時に自分がよく気をつけていること
- が立ち上げに関わった実際の検索サービスでのシステム構築の流れ
- 検索サービス立ち上げ時に共通して考慮すべきだったかもしれないこと
バックエンドとしての検索エンジン
検索サービスを立ち上げる際には色々と考えることがありますが、今回はバックエンドシステムとしての検索エンジンを考えます。
つまりフロントエンドで何かしらのサービスを提供する中で、REST APIなどでリクエストとしてクエリを受け取り、レスポンスとしてアイテムのリストなどを返すサービスです。
立ち上げ時に考慮すること
現在、自分が検索サービスを構築する際には、いくつかの点を考慮してまいます。
全然MECEじゃないですが、以下に自分が気にするポイントを紹介していきます。
そもそも全文検索エンジンが必要か?
全文検索エンジンはSolrやElasticsearchなどに代表されるテキスト検索機能を提供するアプリケーションのことです。
これらのツールは大変便利ですが、不必要ならば管理コストが増えるため使う必要はありません。
例えば、MySQLでもキーワード検索はできますし、Railsなどのフレームワークでも(バックエンドをRDSとして)検索を実現するライブラリが存在します。
以下のような基準と照らし合わせて、基準に満たない場合は経験上RDBをそのまま利用しても問題ない場合が多いです。(とはいえ、色々検証してみることをお勧めします!)
| 検索エンジン必要・不必要の判断項目 | 全文検索が必要そうな基準 |
|---|---|
| 検索対象アイテムの特性(表現) | 主にテキストで表現されている |
| 検索対象アイテムの個数 | 数千〜数十万以上 |
| キーワード検索によるレスポンスタイム | 100〜500ms以下 |
ということで、以下は全文検索エンジンが必要な場合を想定します。
また、自分の場合は「システム的な側面」と「ビジネス的な側面」で考えることが多いので、以下はそのようなふわっとしたカテゴリ別に紹介します。
とはいえ、この両者は切っても切れないことが多いので注意が必要です。
システム的側面
サーバー運用コスト/予想トラフィック・サービスのSLOなど
システムの運用コストをどのくらい使えるかで選択肢がだいぶ変わってきます。コストはお金であったり、人員であったりします。
例えば、大量のトラフィックをさばくためには最低限のマシンリソースを大きくする必要があります。これは必然的に運用コストの増加を意味します。
また、ダウンタイムができるだけ少ない堅牢な構成にしたい場合、冗長構成にしたりバックアップなどを考慮する必要があります。これもまたコストの増大を意味します。
このように、どの程度コストを使えるかということとと、対応できるサービスの幅などはトレードオフな場合が多いのではじめに明らかにしておくのが良いです。
バッチ更新かリアルタイム更新か
検索対象のアイテムはその更新頻度やタイミングによって、システム構成やインデクシング方法(検索エンジンへのデータ投入方法)などが変わってきます。
インデクシングには基本的には以下の3つの方法があると思うので、それぞれの特性などと照らし合わせて方法を考えます。
| インデクシング方法 | 実装コスト(比較した際) | アイテム更新から検索結果表示までの遅延(アイテム更新頻度) | どのようなサービスか | サービス例 |
|---|---|---|---|---|
| 手動更新 | Low | 最大で数日に1回〜1時間に1回 | 定期刊行物や更新月の決まっているメディアなど | 図書館検索、趣味の検索サービスなど |
| バッチ更新 | Middle | 最大で1時間に1回〜数分に1回 | 検索結果への即時反映をうたっていないサービス | 求人検索、Eコマースなど |
| リアルタイム更新 | High | 即時(最大で数秒に1回〜1分に1回) | ユーザーがアイテムを追加するようなサービス | SNS、フリーマーケットアプリなど |
例外はたくさんあるのでこちらの表はあくまでも参考です。
バッチ更新の場合はcrontabやAirflow、Rundeckなどのワークフローエンジンが使えます。
一方、リアルタイム更新ではAWS KinesisやGCP pub/sub等を活用したり、Apache Beamなどを用いたりしてデータパイプラインを構築することがあります。
アイテムの特性と検索時のクエリ
検索対象となるアイテムの特性と検索する際にどのようなクエリが想定されるかを考えます。
全文検索エンジンを使っているので、基本的にはテキストにより表現されているとは思いますが、どのようなフィールドが存在するか、テキスト以外の検索項目などを洗い出します。
クエリに関しても基本は「キーワード」ですが、整理したアイテム情報に対してどのようなクエリで問い合わせが可能かを考えます。
システムとして「誰」が検索結果を取得するか、検索結果をどの程度カスタマイズしたいか
検索エンジニアの方だと、検索システムを作りながら「Precision/Recall」のバランスをどのようにとるかや、ランキングにどのような特徴量を使ってどのような基準で並び替えるかというのを念頭におきながらシステムを作っていくのは一般的かと思います。
実際にシステムを運用していく中で、「誰が」そうしたチューニングを行うのかを考える必要があります。
例えば、検索エンジンの設計者と運用者が同じ場合は本人が直接システムを書き換えれば良いわけですが、設計者と利用者(検索結果をチューニングしたい人)が異なる場合はそれらを簡単かつ安全に行えるようなインターフェースが必要となります。
具体的にElasticsearchのような検索エンジンの例で考えると、あまり検索に馴染みのないフロントエンドエンジニアがアイテムをインデックスする際のトークナイザー・アナライザーやシャード数等々をいじるのはなかなか難しいです。
しかし、簡単なAPIを噛ませて、ヒットさせるフィールドや並び順等を指定できるようにして、さらにおかしなクエリを受け付けないようにしておけば安全かつ簡単に運用することができます。
また、完全に非エンジニアが検索結果をチューニングできるようにするといったことも場合によっては考える必要があります。
このような要求は設定ファイルをいじれるようにすることや、GUIによるインターフェースを提供するなどで実現されることがあります。
ビジネス的側面
改善サイクルの回し方
基本的にどのようなシステムもリリース後に必ず改善を行う必要があります。(システム納品のタイミングで必ず終わる場合や、作ることそのものが目的の場合を除きます。)
改善の流れとしては、以下のようなものが一般的かと思います。
- 現状把握
- 課題の特定
- 仮説立て
- 施策立案
- 実施
そして、この「改善ループをどのくらいの速度で回すか」と「どこまで検索システムとして実現するか」については事前に考えておく必要があります。
改善ループのスパンはシステムでどの程度高頻度にデプロイが行われるかということに直結します。
高頻度なデプロイが行われる場合は当然CI/CD基盤が役にたちますし、システムも変更をくわえやすい形で作っていく必要があります。
どこまで検索システムとして実現するかというのは例えば、検索に関する現状把握を行動ログから行いたい場合にロギングのシステムが必要となることがあったり、施策の実施に関してA/Bテストを行いたい場合はそうしたシステムが必要になったりすることがあるということさします。
初期の要件として「このあたりの改善サイクルで検索システムがかなり関わるぞ」といったことは慎重に洗い出しておくと後々楽です。
何をとって何を取らないか
初期のゴールとノンゴールを決めることです。
検索エンジンのシステム作成者とサービスの企画立案実行者が同じ場合は考慮しなくても大丈夫ですが、複数人のチームで進める際はまず始めに何をとって何を取らないかというのを明らかにしておきます。
例えば、システムの品質についてwikipediaのISO/IEC 9126のページに色々な観点がありますが、こちらを参考にすることもあります。
例えば、変更しやすさは(保守性・移植性)は初期の技術選定やその後のシステム改善の速度などに影響しますので、「今回はとにかくスピーディーにリリースすることを重視したので、今後の改善はシステム変更はちょっと時間かかる」などです。
ユーザーの用途やニーズ
どのようなアイテムをヒットさせて、どのようなランキングにするかを考えるにあたってユーザーのニーズを想定することは非常に有意義です。
例えば、大量のアイテムを眺めたいのか、ピタッとしたアイテムを少量だけ見たいのか、デフォルトでは安い順が良いのか、キーワードのマッチ度合いが高い方が良いのかなど考えることはたくさんあります。
例えば、書籍を検索するようなサービスの場合、「ユーザーは特定の本を思い浮かべて、その断片としてのキーワードをシステムに入力している。欲しい本はできるだけ早く見つけられると嬉しい。」といった具合です。
このように何らかの仮説を持っておくと開発の時の助けになります。
2つのケースからみる検索エンジン立ち上げの過程
さて、ここからは実際に立ち上げに関わった2つのサービスについて、当初の課題やどのような思考を経て検索システムを構築していったかについて振り返ってみることにします。
今回例にあげるサービスは(今のところ)小規模トラフィックかつサービスレベルもそこまで高くない検索サービスなので、秒間リクエストが数百超えるよ、数分ダウンするとお金めっちゃ飛ぶよ的なサービスではないことにご注意ください。
ケース1: 雑誌検索サービス ink
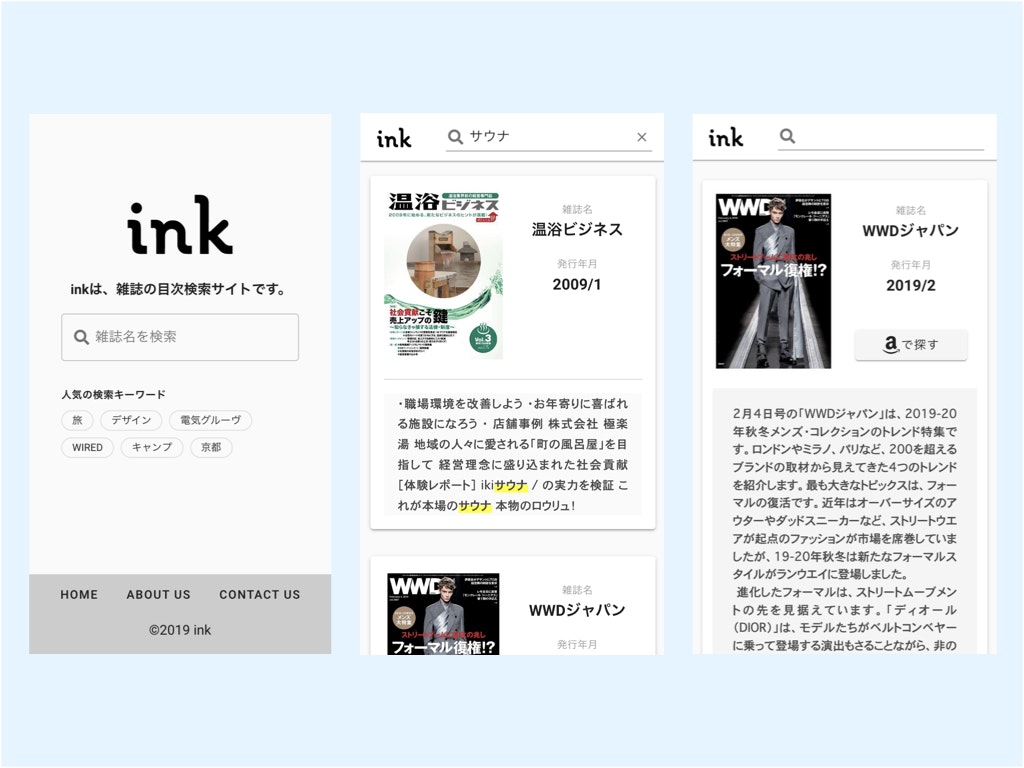
前職の同期に誘われて関わっている、様々な会社の有志が集まって作っている検索サービスです。
雑誌に興味のあるユーザーが雑誌の目次検索を通して、まだ見ぬ新しい雑誌と出会うことを目的とするサービスです。
検索サービス立ち上げ当初の課題(検索観点)
非常によくある課題だと思いますが、当時以下のような課題がありました。
- 数十万の雑誌データが集まったもののRDBのみで検索を行っていたため、結果取得に時間がかかる(数秒)
- タイトルや目次に対する柔軟な検索結果の調整が行えない、システムを変更しても意図したとおりの検索結果にならない
どのように解決に取り組んだか
経験上、これらの課題は検索エンジンを入れることで比較的簡単に解決することが分かっていたので、Elasticsearchを導入して検索機能を別のAPIとして切り出すことにしました。
先ほど紹介した観点について以下のようにまとめました。
- 更新頻度は1月に1度くらい(管理者によってアイテムの拡充が行われたタイミング)
- 検索結果の改善はプロダクトオーナーを中心として他のメンバーの意見を聴きながら開発者(自分)が行う
- アイテムは雑誌のタイトルと目次、発行年月日など、基本的にキーワードにより検索
- ユーザーは何らかの主題についてそれに関連する雑誌をできるだけたくさん見たい
- 改善サイクルは1ヶ月くらい(inkチームの振り返りと施策実施がだいたい一ヶ月周期)
- クイックに検証できることは重視するがスケール性は犠牲にする(週末開発なのでサクサク試したいが、トラフィックはそこまで急に増えない)
- 運用資金は潤沢ではない(メンバーの持ち寄り)
これらの点に注意して以下のような要件でシステムを作成してみました。
- シングルノード全部載せ
- Elasticsearchを利用(開発者の趣味)
- 薄いラッパーとしてのAPIをElasticsearchのフロントに配置
- 基本的にはこちらで検索式(ヒットとランキング)を管理
- インデックス用のプログラムはローカルかサーバーで実行
- RDBからアイテムを取得して、Elasticsearchにインデクシング
- 最低限の認証とルーティングでNginx
- キーワード検索によりできるだけRecallの高いヒットで、キーワードとの関連度順に並べる
成果:よくなったこと
-
検索速度アップ:数秒→数100msec
- 体感だと「うーん」という待ち時間が「一瞬」になった
-
ランキングの感覚がよくなる
- 定量的ではないけれど、目次とタイトルのバランスや上位に来る雑誌の内容に納得感が増した
-
カスタマイズ性アップ
- プロダクトマネージャーの「検索結果をこうしたい」をすぐに反映できるようになった
- 簡単な施策なら、以下のステップで終了
- 意見聞いて要件まとめる(数分〜1時間)
- ちゃっと実装(数分)
- ちゃっとテスト(数分)
- ちゃっとデプロイ(数分)
副作用(良いも悪いも)
- システムの管理コストが増えた
- お金:+月1000円くらい
- 障害時の対応:とはいえ、半年近く運用していてダウンしたのは1度だけ(トラフィック少ないのもある)
- 検索周りの改善がシングルポイントになった
- 基本自分しかいじれない(趣味の開発だし、まあそれはしょうがないかな)
- Elasticsearchを使っていたため、more_like_thisなどを使うことによって雑誌のレコメンド機能が比較的簡単に実装できた
反省点
- 雑にシステムを作りすぎたためスケール性がまったくない
- SaaS(たとえばAlgoliaやAzure Cognitive Search)をきちんと選択肢に入れていなかったため、自身でインフラ管理などすることになり管理コストが上がってしまった
とはいえ、全体的にはなかなか改善したのかなと思います。
雑誌ドメイン固有の課題
ここでは、雑誌検索にまつわる固有な課題について紹介しようと思います。
inkとして検索周りで課題として上がっていたのは以下のような内容でした。
目次の構造化ができない
雑誌の目次は非常にデザイン性の高いものが多く、単純にテキスト化しただけではかなりの情報量が落ちてしまいます。
例えば、以下のような雑誌の目次をテキスト化するとこんな感じになります。
(マガジンハウス Popeye No. 844より)

特集 なんでこんなにカレーが好きなんだろう。
世界のカレーをおさらい。
カレーニューウェ~ブ。
名店、ここはうまい。
今昔、”好きなカレー”物語。
ダルバートを求めて、カトマンズへ。
カレーはミステリー。
麺探偵がゆく。カレーはライスだけじゃない!
カレートリップ。あ~、安曇野のスープカレーを。/博多、2つのオマージュカレー。
なぜかうまい、そして落ち着く。孤独のカレー。
レトルトカレーを巡る冒険。
神田・神保町 カレーカード大全!
第2特集 夏の夜のハードボイルド。
Chapter 1 矢作さん、ハードボイルドって何ですか?
Chapter 2 固茹で・調査報告。
Chapter 3 俺の好きなハードボイルド。
chapter 4 ハードボイルドならこうするネ!
Chapter 5 お別れの前に一杯のギムレットを。
・・・
めちゃくちゃ情報落ちてますよね。
このあたりの情報(例えば「特集」など)を汎用的な形でデータとして保持するのがなかなか難しいです。
ちょっと古いですが、こちらの研究で雑誌の目次構造を検索に取り入れているような例があるので、参考にしつつ進めています。
また、現状は未着手ですが、構造を取り出してElasticsearchのNested Objectを用いると構造化されたドキュメントのデータを用いることができるので、それを使って検索に役立てて行くのもやっていく予定です。
このような工夫によって、ユーザーに特集レベルの目次を提示できたり、目次の各タイトルレベルで検索結果を提供できたりできるようにナルト良いなと思っています。
ケース2. e-learning教材検索サービス Libora

こちらは自分が副業で働いている会社です。
こちらも0からのサービス立ち上げです。
検索サービス立ち上げ当初
当初の要件として検索サービスであることが明らかで、アイテム数も数万以上のオーダーだったので検索エンジンの導入を検討しました。
こちらはお仕事ということで、先ほどのinkの例と比べると比較的カチッと進めています。
まずは以下のようなデザインドキュメントを元に認識の齟齬をなくしてからのスタートとしています。
デザインドキュメント

(英語なのはチームメンバーに英語話者がいるため。)
またLiboraではマーケターと一緒に進めているため、トラフィック量のスケールについて見立てを立てることができました。
そのため、マーケターによるグロース計画を参考にしながら、システムのスケール戦略をきちんと考える必要がありました。
そして、開発に着手する前に以下のように観点を整理しました。
- 更新頻度は1月に1度くらい(管理者によってアイテムの拡充が行われたタイミング)
- 検索結果の改善はプロダクトオーナーを中心として他のメンバーの意見を聴きながら開発者(自分)が行う
- アイテムはタイトルとその説明、その他複数の項目あり、クエリは基本的にキーワードだが料金や時間など細かな指定もしたい
- ユーザーは何らかの主題に関して学習をすることができる自分に合った動画を見つけたい
- 改善サイクルは1ヶ月くらい(inkチームの振り返りと施策実施がだいたい一ヶ月周期)
- クイックに検証できることは重視しつつ、長期のスケール性は犠牲にしない
- 運用資金は比較的余裕あり
以上のような整理を踏まえ、以下のようなゴール/ノンゴールを明確にしておくことは検索システムに関わらず、システムを構築する際に非常に有用です。

(メンバー共有資料より抜粋)
これらの点に注意して以下のような要件でシステムを作成してみました。
システム構成
検索システムは緑の点線内側です。
このように外部のシステムを含めた上で境界を示すと分かりやすいかもしれません。

- シングルノード全部載せ
- ただし、各コンポーネントはDocker化しておき、必要に応じてkubernetes等の環境に移行しやすくする
- Elasticsearchを利用(今後クラスタを組めるように)
- 薄いラッパーとしてのAPIをElasticsearchのフロントに配置
- インターフェースを決めてフロントから呼び出せるように設計
- インデックス用のプログラムはサーバーで都度実行
- RDBからアイテムを取得して、Elasticsearchにインデクシング
- GUIによる手動操作を可能に
- Nginxで各種認証とルーティングを行う
- アイテムは多くヒットするようにしたいが、できるだけキーワードとのマッチ度を重視したランキングにする
リリース後の感触
- システムは安定 ... 今のところ障害起きていない
- リリース作業・インデクシングが苦でない ... Dockerの恩恵
- カスタマイズが簡単 ... ElasticsearchなのでDSL書き換えるだけでOK
その他感想
事前にドキュメント等で認識合わせをしておき、早い段階でモックレベルのAPIのインターフェースを用意しておいたので、システム面ではリリースに当たって齟齬やトラブルがほとんどありませんでした。
一方、検索結果の精度や思想に関してはプレリリース後に色々と意見が出て、何度か修正することになりました。
事前に「こういうロジックで検索結果を出す」と説明していても、実際に使ってみるとドキュメント外の発見が多くあるので、地道にちょっとずつ改善していきました。
2つのケースを通して学んだこと(小規模な検索システムのリリース前後の作業)
上記のような検索サービスを構築したり運用する中で、「リリースする前にやっておけば良かった・・・!」ということや「ぶっちゃけリリース後でもなんとかなる。」ということなどがありました。
新規サービスでは通常「出来るだけ早く出したい」という力が働きますので、一般的なやるべきをあれこれやってからリリースすることは通常できません。
さらに、この先どうなるかも分からない状態で高い実装コストをかけるのはあまり良い手ではありません。
検索システムの初期ローンチにおいては、いかに最低限の基盤を素早く作って、クイックに色々試せるかというのがにおいてはなかなか大事なのかなと思っております。
ということで、今回の経験から「サービスローンチ前にやっておきたいこと」と「ローンチ後でもぶっちゃけなんとかなること」をまとめておしまいにしようと思います。
サービスローンチ前にやっておきたいこと(検索に限らず)
ざっと箇条書きですが、簡単にいうと修正がめっちゃ大変なことは事前に、リリース後の検索ロジックの修正は意思決定・システム実装の両観点共にできるだけささっとできるようにしておくということです。
- システムのコンテナ化 ... 最低限各コンポーネントはDokcerイメージにしておきたい
-
デプロイの簡易化 ... デプロイだけは楽にしておかないと改善サイクルに入りにくい
- 検索だと再インデクシングもデプロイのうちの作業だったりするので、この辺は自動化したい
- 検索ロジックの解説ドキュメント ... 意外とみんな気にしている
- システムモニタリングの設定 ... 特に検索サービスとしてはQPSやアイテム数等が確認できると概要が一目でわかって良いかも
-
ユーザーフィードバックをどのように得るかの設計
- これがないとメンバー内の感想ベースで改善(?)するしかない
- 初期はフィードバック取れなくても今後どのようにフィードバックを得るかの計画はあると良い
- サービスローンチ後に手を付ける積み残し作業のリストアップと必ずやるという強い意思
ローンチ後でもぶっちゃけなんとかなること/もしくはローンチ後が良いこと
検索サービスの思想や目標
理想的にはサービス初期に「検索システムを通してユーザーにこういう価値を提供したい」といった目標を設定で着れば良いですが、実際のところ検索結果が出るようにならないと「どうなっていると良いか」というのはなかなか言語化できないのが現実です。
なので、ある程度システムが出来上がって、リリースした後でも「いや、なんかこの検索結果違うな・・・」というのを集めて言語しながらでも良いのかなと思いました。
そもそもそのような個別具体の積み重ねを提示しないと、プロダクトオーナーから「検索に関する思想や目標」はなかなか出てこないかもしれません。
その他
ユニットテストやCI/CDなど、本当はリリース前にやりたいですが、小規模トラフィックのサービスならリリース後でもなんとかなる場合も多いです。
まとめ
ということで、最近リリースした2つの検索サービスを元にどんなこと考えながら検索システム作ってるかというのを振り返って見ました。
みなさまの「検索サービスリリース時の考慮ポイント」があればぜひ教えて欲しいと思います。
もしくは大規模検索サービス編などもあると嬉しいかもです。
最後までお読みいいただきありがとうございました!