はじめに
こんにちはrilmayerです。
この記事はアドベントカレンダー「Search&Discovery 全部俺」20日目の記事となります。(遅れ
本日は定番のOSS全文検索エンジンであるElastisearchを推薦システムとして使ってみようと思います。
Elastichsearchで検索結果をいじる
サンプル用の会社データ取得
今回は日本の会社を検索できるシステムを作っていじって見ようと思います。
日本の会社データはこちらのWebサイトから以下のSPARQLで取得しちゃいます。
select
?name ?abstract group_concat(distinct ?location, ";") as ?location group_concat(distinct ?stockholders, ";") as ?stockholders
where
{select
distinct ?name ?abstract ?stockholders ?location where {
?company <http://dbpedia.org/ontology/wikiPageWikiLink> <http://ja.dbpedia.org/resource/Category:東証一部上場企業> .
?company rdfs:label ?name .
?company <http://dbpedia.org/ontology/locationCity>/rdfs:label ?location .
?company prop-ja:主要株主 ?stockholders .
?company <http://dbpedia.org/ontology/abstract> ?abstract .
}
}
GROUP BY ?name ?abstract
Elasticsearchへのデータ投入
まずはESを立ち上げます。
今回は以下のDockerfileを元に立ち上げます。
FROM docker.elastic.co/elasticsearch/elasticsearch:7.5.0
RUN bin/elasticsearch-plugin install analysis-kuromoji
以下のようにbuildしてrunすれば立ち上がります。
# build
docker build -t es .
# run
docker run -it -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" es
データを投入します。
# インデックス作成
from elasticsearch import Elasticsearch
host = 'http://localhost:9200/'
es = Elasticsearch(host)
index_name = 'company'
# 今回は会社情報で作っていきます(全部テキスト)
es.indices.create(index=index_name, body={
'settings': {
'number_of_shards': 5,
'number_of_replicas': 0
},
'mappings': {
'properties': {
'name': {
'type': 'text',
'analyzer': 'kuromoji'
},
'description': {
'type': 'text',
'analyzer': 'kuromoji'
},
'location': {
'type': 'text',
'analyzer': 'kuromoji'
},
'stockholders': {
'type': 'text',
'analyzer': 'kuromoji'
}
}
}
})
# 先ほど作ったデータを "company.csv" として読みみ
import pandas as pd
csv_file_path = "company.csv"
df = pd.read_csv(csv_file_path)
# 一部データが汚いのでクリーニングする
# データのクリーニング
import re
def clean_text(text):
text = re.sub(r'[a-z0-9%-]+|\s+|\.|株', "", text)
text = re.sub(r'^;|;$|\:\/\/\/\/|\(\)', "", text)
return text
df['stockholders'] = df.stockholders.apply(clean_text)
# データを一括追加
company_list = []
for i, row in df.iterrows():
company = {'name': row["name"], 'description': row.abstract, 'location': row.location, 'stockholders': row.stockholders}
company_list.append(company)
# インデクシング
from elasticsearch.helpers import bulk
def _load_data():
index_ = 'company'
for data_ in company_list:
yield {"_index": index_, "_source": data_}
bulk(es, _load_data())
検索を行う
ここから、検索クエリの検索結果を修正していく過程を追っていきます。
今回はESのDSL書き換えのみで対応しますが、本来はシノニムやストップワード、トークナイザー、アナライザーなど多方面からの改善が必要となります。
今回は例として「自動車」と「ユニクロ」というクエリを改善してみます。
本来は個別のキーワードに対して改善を行ってしまうと別のキーワードで何らかの副作用が生まれたりするのであまり良くありません。
が、練習ということでここはとりあえず取り組みましょう。
その1: 「自動車」の検索結果を改善する
情報検索では検索意図に沿った検索結果一覧を提示することが大事です。
今回は 「自動車」と検索するユーザーは自動車に関する会社を探しており、名前や説明にそのキーワードが含まれているものが欲しい と仮定しましょう。
最初は大雑把に全部のフィールドについて対象のクエリが含まれている場合にヒットとして、並び替えもデフォルトでアイテムを取得してみます。
query = '自動車'
es_query = {
"query": {
"multi_match": {
"query": query
}
}
}
results = es.search(index=index_name, body=es_query)
検索結果をJupyter上でpandas.DataFrameとして表示してみます。

うーん、微妙ですね。
フィールドごとの重みを変える
Elasticsearchではboostという機能によってランキングを調整することができます。
これはフィールドごとに「マッチした場合の加点」を個別にブーストできる機能です。
今回は name と description に当たった場合に上位に来るようにしたいので、以下のように name と description については2倍のスコアリングをするよう設定します。
query = '自動車'
es_query = {
"query": {
"bool": {
"should": [
{"bool" : { "must": { "match": { "name": query }}, "boost": 2}},
{"bool" : { "must": { "match": { "description": query }}, "boost": 2}},
{ "match": { "location": query }},
{ "match": { "stockholders": query }},
]
}
}
}
results = es.search(index=index_name, body=es_query)
結果は以下の通りです。
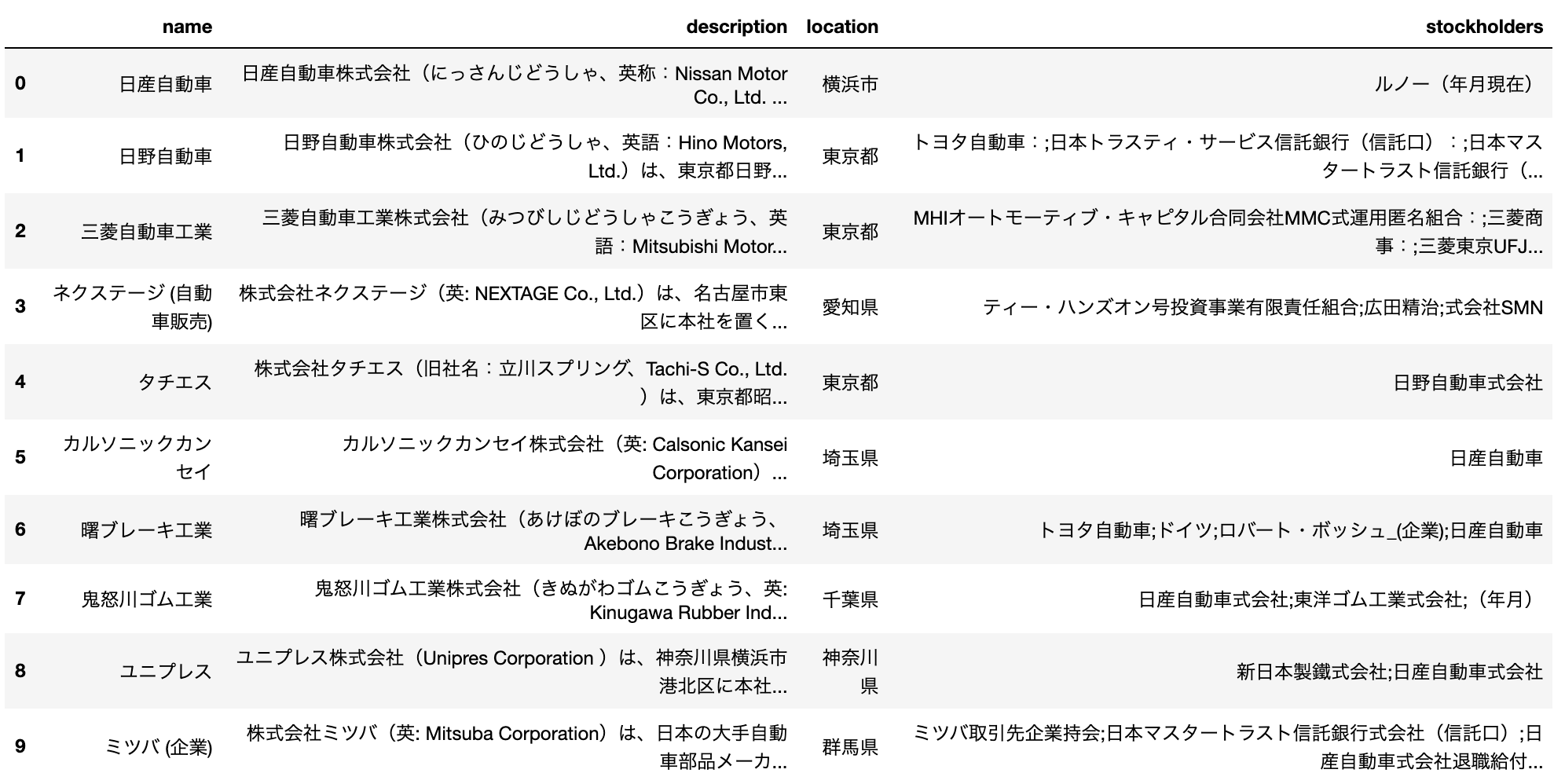
さっきよりだいぶ良くなりました。
本来はここでboostの値をチクチク変えながらチューニングを行っていきます。
その2: 「ユニクロ」の検索結果を改善する
さて、先ほどの検索クエリをそのまま使った「ユニクロ」を検索してみましょう。
query = 'ユニクロ'
es_query = {
"query": {
"bool": {
"should": [
{"bool" : { "must": { "match": { "name": query }}, "boost": 3}},
{"bool" : { "must": { "match": { "description": query }}, "boost": 1.5}},
{ "match": { "location": query }},
{ "match": { "stockholders": query }},
]
}
}
}
results = es.search(index=index_name, body=es_query)

上記の結果はElasticsearchで "match" はクエリに関して「トークン化できる場合はトークン化する」という動作が走るためです。そのため「ユニ」というトークンがヒットしてしまったりしているのです。
この現象についてはこちらの記事が参考になるかと思います。
ということで、そのままのキーワードで検索したい場合は match の代わりに match_phrase を使います。
以下、改良版クエリ。
query = 'ユニクロ'
es_query = {
"query": {
"bool": {
"should": [
{"bool" : { "must": { "match_phrase": { "name": query }}, "boost": 3}},
{"bool" : { "must": { "match_phrase": { "description": query }}, "boost": 1.5}},
{ "match_phrase": { "location": query }},
{ "match_phrase": { "stockholders": query }},
]
}
}
}
results = es.search(index=index_name, body=es_query)
結果は以下の通りです。

ちなみにdescriptionの内容は以下の通りとなっております。
株式会社ファーストリテイリング(Fast Retailing Co., Ltd.)は、株式会社ユニクロなどの衣料品会社を傘下にもつ持株会社である。東京証券取引所第一部上場。
バッチリですね。
おわりに
今回はESのヒットやランキングをクエリのみでいじる簡単な方法を実際の例に即して紹介してみました。
先ほども言いましたが、より良くしていくためにはシノニムやストップワード、トークナイザー、アナライザーなど多方面からの改善が必要となります。
ある程度のユーザートラフィックがある企業ではユーザーの行動ログを活用して、ユーザー行動に基づいたランキングやトークンの設定などを行っています。
Elasticsearchの検索クエリ、ちょっととっつきにくいですが慣れれば非常に柔軟に色々と試せるので慣れていきましょう!