はじめに
こんにちは。IT企業でデータ活用プロダクトの開発に従事しているrilmayerです。
この記事はアドベントカレンダー「Search&Discovery 全部俺」9日目の記事となります。
前回の記事ではSearch&Discoveryなシステム評価の概要を説明しました。
今日は検索や推薦で用いられる評価方法や指標についてまとめていこうと思います。
検索・推薦の評価
ここでは検索や推薦に関する評価について、どのような考え方をするかについて説明したいと思います。
検索や推薦では基本的にN個のアイテムからユーザーに対してn(≦N)個のどのアイテムをどんな順番で提供できたら良いのかという課題感をベースとして、評価を行ってきます。
どんな順番でアイテムを提供するの良いかというのは「ランキング問題」と言われており、昨今の検索や推薦システムでは提供するアイテム数は膨大なことがほとんどなので、実際のほとんどはランキング問題となります。
評価の基本コンセプト
検索も推薦もオフラインテストとオンラインテストの2つの考え方をおさえておくと良いかと思います。
ユーザーや検索クエリに対して正解となるアイテム群が用意されている場合(オフライン)と、実際の本番環境にシステムを導入してビジネス的な指標を計測する場合(オンライン)です。
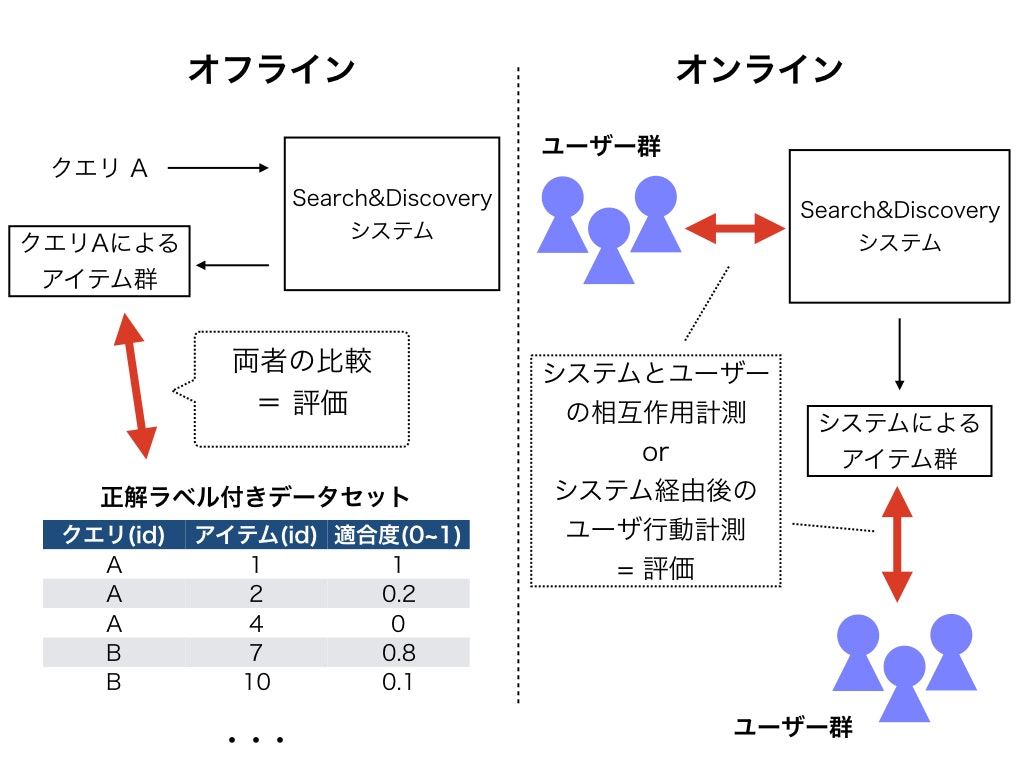
検索評価
古典的な情報検索の世界では、ユーザーがニーズ(情報要求)を持っており、それをクエリとして表現しシステムに問い合わせてアイテム集合を得るというようなフレームで考えられています。
その時に、提供されたアイテムがどれだけ情報要求に合致(適合)しているかを明らかにすることが、伝統的な検索システムの評価でした。
この「適合(relevance)」という言葉は情報検索の専門用語で、ユーザーの情報要求に対してシステムにより提供されたアイテムが適していることを表します。
きちんとしたオフラインテストでは専門家がクエリに対して以下のようにドキュメントの適合・非適合が判断したものを評価のために用いたりします。
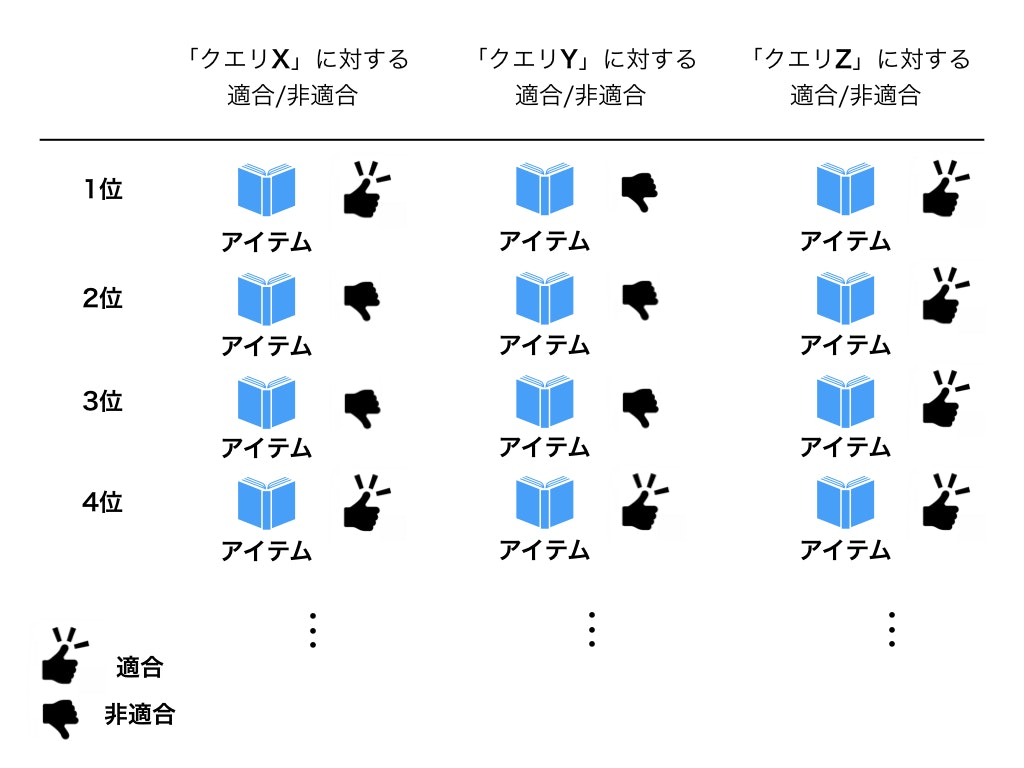
上記の例ではなんとなく、適合アイテムが上位にあるクエリZが良さそうで、上位に適合アイテムがないクエリYが悪そうに見えます。
検索評価ではこのような「とあるクエリに対して適合したアイテムがどのように検索結果一覧に並んでいるか」というのが中心的な評価方法となります。
そのため、適合アイテムが上から順に並んでいるほど良くなるような評価指標が開発され用いられてきています。
ちなみに、この「適合」ですがWebサービスなどではユーザーのクリックやコンバージョンをシグナルとして利用する場合もあります。そのため「とあるクエリに対してユーザーによるクリックが発生した場合は適合とみなし」て、正解となるデータセットを作成するということも良くあります。
推薦評価
検索評価と比較して推薦でも同様に「推薦されたアイテムがどんな順番で並んでいるか」によって評価がなされるため、情報検索で用いられている評価方法が良く利用されています。
一方で推薦評価では伝統的にユーザーのレイティング予測を元にランキングを行うこともあるため、「どれだけレイティングを当てられているか」という評価指標も用いられてきています。
例えば、推薦システムの世界で非常に話題となったNetflix Prizeでは、予測した動画に対するユーザーのレイティングが実際のレイティングにどれだけ近いかという「平均二乗誤差」という指標が使われるなどしました。
一方、どのようなアイテムをどのような順番で提供するかという課題設定においては、検索評価と同じような評価が行われてきています。
評価指標
ここでは、検索や推薦システムの性能について、どのような評価指標が存在するのか、それらを使うとどんな評価ができるのかについて説明していきたいと思います。このあたりは多くの方がWebページや書籍で丁寧な解説をしてくれているでサラッと行こうと思います。
評価指標の詳細について気になる方は、以下のリンクで非常に良くまとまっているため参考にしていただけると良いかと思います。
レコメンドつれづれ ~第3回 レコメンド精度の評価方法を学ぶ~ - Brain Pad Blog
集合検索指標
集合検索指標は、システムによって提供されたアイテムについて、ランキングを無視してそれらがどのようにユーザーに適合しているかとを表す評価指標です。
システムにより提供されるアイテムリストの中にはできるだけ適合アイテムが入っていたら嬉しいですし、提供されたアイテムリストの中にはできるだけ適合アイテム以外入ってて欲しくないと言うような要望を指標に落としたものとなります。
再現率と適合率
- 再現率(Recall) ... 適合アイテムのうち、どれだけ検索結果に適合アイテムが含まれるか
- 適合率(Precision)... 検索結果に含まれる適合アイテムの比率
これらはランキングを考慮しない評価指標です。
Recall=\frac{検索結果に含まれる適合アイテムの数}{全ての適合アイテムの数}
Precision=\frac{検索結果に含まれる適合アイテムの数}{検索結果に含まれる全てのアイテム数}
F値(F-measure)
そこでF値はそれらの課題を解決するために、上記の再現率と適合率のバランスをとった指標です。
F=\frac{1}{\frac{α}{Precision}+\frac{(1−α)}{Rrecall}}
このαを1/2、つまり再現率と適合率の重みを半々にした場合がF1値となります。
ランク指標
ランク指標の考え方のポイントは、適合アイテムの数を加算していく際に「適合アイテムが下位にくるほど減点されるようにする」というところです。
ランキングの上位ほど大きく、下位ほど小さくなるような係数をかけた上で合計をしてあげると目的に沿った結果を得ることができます。
このような係数を「減損利得(discounted gain)」と言います。
ランク指標に関しては色々出てきますが、基本的にはこの減損利得を工夫しているというのを意識すると読み解きやすくなると思います。
以下に良く使われるランク指標を紹介します。
MRR
最初に現れた適合アイテムの順位の逆数の平均をとったものです。
以下のようなイメージです。一番最初にユーザーに適合したアイテムが重要という考え方です。
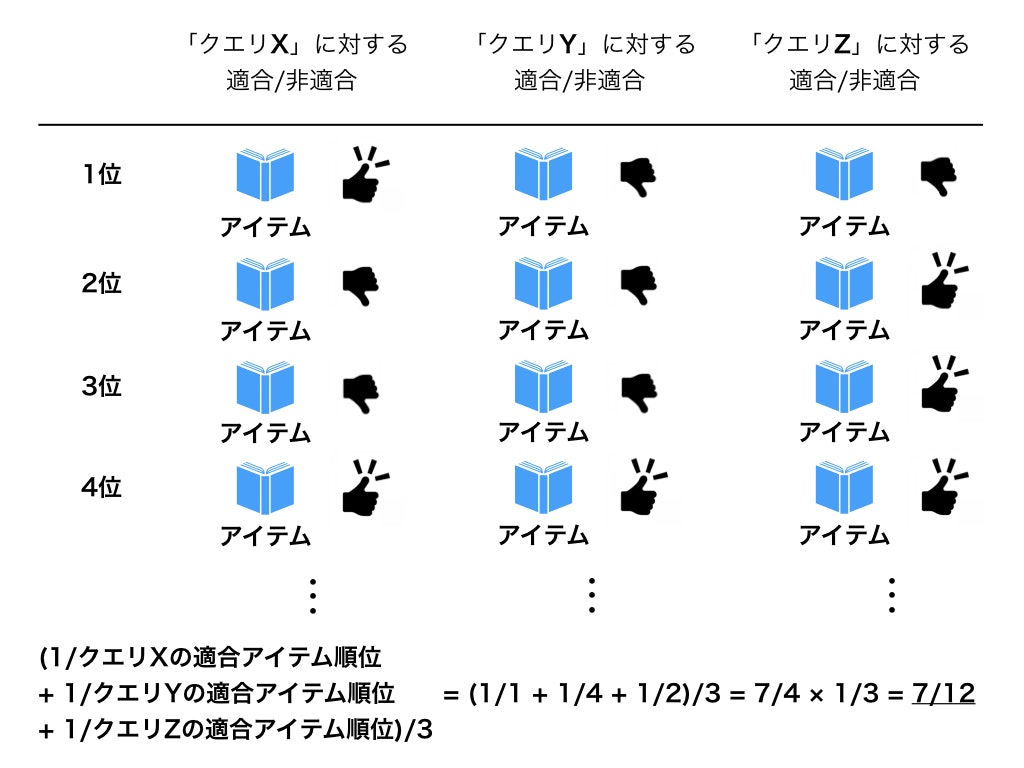
nDCG
nDCGは減損利得がlogで 1/log1, 1/log2, 1/log3, ... と増えていくランク指標です。
そして最終的に理想的なランキングでの計算結果により正規化するというランク指標になります。
またnDCGでは適合度を数値で表せるという特徴があります。
計算方法としては、以下の合計をとった値を理想的な順序で並び替えたリストで同じ計算を行った結果で割るだけです。
DCG = 1位の適合度 + 2位の適合度/log2 + 3位の適合度/log3 + ...
イメージは以下のような形となります。

数値予測指標
検索で適合度の得点が明確な場合や、レコメンドにおいてランキングにアイテムのレーティングなどを用いる場合はそれらのスコアを直接評価する場合もあります。これらの評価指標は正解となる値と予測した値がどれだけ乖離しているか、というのをどのように測るかという点に注意すると理解しやすいかと思います。
ただし、これらの指標はあくまでも「モデルがどの程度良く予測しているか」を示しているものであって、Search&Discoveryにおけるユーザー体験の向上とは必ずしも一致しないことに注意が必要です。
ここでは特に有名な指標を説明します。
二乗平均平方根誤差(RMSE: Root Mean Square Error)
推定した値と正解の値の差の二乗を平均した値です。
RMSE = \sqrt{\frac{\sum_{テスト集合} (テストの予測値 - 正解の値)^2 }{テスト集合の合計}}
平均絶対誤差(MAE: Mean Absolute Error)
推定した値と正解の値の差の絶対値を平均した値です。
RMSE = \sqrt{\frac{\sum_{テスト集合} |テストの予測値 - 正解の値| }{テスト集合の合計}}
オフライン評価指標まとめ
繰り返しになりますが、ここまでの指標はあくまでも「このクエリ(アイテムやユーザーも可能)ではこれこれのアイテムが正解になるというデータセット(=テストコレクション)」がある上でのオフライン評価指標となります。
ただし、適合をユーザーのアクションログなどで定義できればオンラインの評価としても用いることができます。
さらに、通常は業務などでは複数のシステムを並行して比較する場合も多いと思われます。
それらのシステム間でオフラインの指標がどう変わるかというのを比較することによってより良い評価ができるようになると思われます。
オンラインテスト向けの指標
これから紹介する指標は、検索や推薦のシステムにおいてinterleavingやA/Bテストといったテスト手法を用いて評価する際に用いることの多い評価指標です。
これらの手法についての概要はWantedly Engineerブログの記事が詳しいのでこちらを参照してください。
A/Bテストのより厳密な方法はこちらの本(『推薦システム』 p.81~)がおすすめです。
マーチャンダイジングコントロール指標
あまり聞きなれない言葉かもしれないですが、検索や推薦でのマーチャンダイジングコントロールというのはビジネス的な観点から提供するアイテム集合を変更していくことをさします。
例えば、動画検索サービスで会社としてプッシュしていきたいアイドルが出演している動画の検索順位を上げることや、ECサイトでグレーな商品を多く出品する店舗の商品を検索結果に表示しないこと、マッチングアプリでいいねがあまりもらえていないユーザーの推薦頻度を上げるなどがこれに当たります。
これらの施策に関して、以下のように指標を計測して評価することができます。
ただしこれらは細かな例であって、実際はビジネスニーズに応じて様々な指標を作成する必要があります。
- アイテムの特定項目分布 ... プッシュしたいカテゴリが存在する場合などは提供されたアイテムの特定項目に関する分布を元に評価を行うことができます
- NGアイテムの出現頻度 ... 基本的に0であることを目指しますが、対象となるようなアイテムの露出率を計測します
- 目的のアイテム・カテゴリ等への遷移率 ... システムを通してユーザーの遷移先をコントロールしたい場合などに計測します
- アイテムごとのPV数のジニ係数 ... システムによるアイテムビューが偏らないような仕組みを導入した際に偏り全体が是正されるかを計測します
サービス品質指標
ビジネスの目標は利益や売り上げであることが多いですが、検索や推薦システムではそれらに貢献する可能性の高いものとして以下のような指標が良く用いられています。
- コンバージョン率 ... サービスによってコンバージョンは購入や、問い合わせや、視聴など様々なものが存在しますが、検索・推薦システムを通してどれだけコンバージョンが生まれたかは重要な指標です
- CTR(Click Through Rate) ... システムを通してアイテムをクリック(タップ)がどのくらい生まれたかを計測する指標です
- アクション指標 ... サービスによっては「いいね」や「コメント」、「ブックマーク」等のアクションを計測することができます
- 詳細ページ滞在時間 ... 検索結果や推薦されたアイテムの飛び先ページでどの程度ユーザーが時間を過ごしたかを表し、一定の閾値を設けて滞在時間が短い場合のみを集計して不満足なクリックとして指標として使うこともできます
- リテンションレート ... 一定期間をとった時に、期間の開始時にシステムを利用したユーザーのうち、期間の終了時にもシステムを利用しているユーザーの率
その他指標
ここでは適合・非適合やビジネス目標とは異なり、検索・推薦システムのシステム面の状態や、アイテム状況等の変化を検知することなどに有効な指標をいくつか紹介します。一部システム品質評価の話も含まれます。
- インデックス遅延 ... 新たなアイテムがデータベースに追加されてからどのくらい遅れてアイテムを提供できるかです
- レスポンスタイム ... レスポンスタイムが落ちてしまうとユーザー体験に相当な悪影響があることが知られています
- アイテム数 ... システムで提供できる全体のアイテム数です
- QPS: Query/Sec ... 1秒あたりのクエリ数です
- Index Item/Sec ... リアルタイムにアイテムが追加されるようなサービスでは重要な指標となります
おわりに:評価はなぜ必要?
最後はややポエミーです。
評価せずに改善はできない
システムを改善する際には、そもそも基準がなければ改善したかどうかが分かりません。今よりも良くしたいと思った瞬間に評価は必ず必要になります。
そんな時にきちんとした手法を用いることができなければ、変化も分からなければ道筋すら立てられなくなってしまうかもしれません。
評価について知識を身に付けることはシステムを作ったり、サービスを改善したりする仕事に関わる際に役に立つかと思います。
多角的な視点で評価をしたい
今回の記事は実は検索・推薦の評価の中でもアイテムリスト品質ととでも言うような部分が中心でした。
検索や推薦では確かにユーザーに対するアイテムのリストがいかに良いものか、と言うことが非常に重要ではあるものの、その周りにも評価すべきポイントは多く存在しています。
最後に少し触れましたが、システム的な観点もその一つで、こうした多角的な評価によって実サービスの中で実際に役立つシステムの作っていけるのではないかと思っています。
おわりに
やや長くなってしまいましたが、お読みいただきありがとうございます。
参考資料
- Tetsuya Sakai. Metrics, Statistics, Tests. https://pdfs.semanticscholar.org/3551/46c49d983f5c35c6033374a7252ac0141fd8.pdf
- AIアルゴリズムマーケティング 自動化のための機械学習
- 情報アクセス評価方法論
おまけ
検索サービスに限定されますが、自分が仕事などで検索サービスを多角的に評価したい場合に利用する指標一覧です。
検索結果一覧のアイテム情報ログが不要な指標
つまり一般のサービスでも計測しやすい指標です。
SERPはSearch result Page(検索結果一覧ページ)のことです。
- Search Execute [UU/Actions] … 検索[ユーザー数/回数]
- Paging [UU/Actions] in SERP … 検索ページング[ユーザー数/回数]
- Abandon [UU/Actions] … 検索放棄[ユーザー数/回数]
- SatTap / DsitTap [UU/Actions] … 検索経由後アイテム閲覧時間N秒以上/以下のタップ
- Item View [UU/Actions] via Search … 検索経由アイテム閲覧[ユーザー数/回数]
- Dwell Time in Item via Search … 検索経由アイテム閲覧時間
- Action [UU/Actions] via Search … 検索経由アクション(いいね、コメントなど)[ユーザー数/回数]
- Conversion [UU/Actions] via Search … 検索経由コンバージョン[ユーザー数/回数]
- N Days Continuing Search Execute UU … N日間継続検索ユーザー数
- Unique SERP[UU/Actions] … ユニークな検索条件数
- Abandon[UU/Actions] … 検索後に何も操作がない(スクロールなど一部操作を除く)
検索結果一覧情報利用指標
つまり、ちょっと計算がめんどくさい指標。
- 検索結果一覧のアイテム情報統計
- HitRatio ... 平均何件ヒットしているか
- 0HitRatio ... 0件ヒットのクエリがどのくらいあるか
- アイテム特徴統計(価格、カテゴリなど) ... ECサイトであればクエリごとの平均価格など
- ユーザー行動
- Click in SERP@k … SERP上位@kのクリックアイテム数
- First Click Rank in SERP@k … SERP上位@kの最初にクリックされたアイテムの順位
- Precision by Click@k … [Click in SERP@k] / k
- MRR(Mean Reciprocal Rank) by Click … avg(1 / [First Tap Rank in SERP@k])
- NDCG@k … SERP上位@kのアイテムクリックを元にNDCGを計算