初めまして。
データサイエンティストの金の卵です。
本記事の目的
階層クラスタリングについて、理解から実践までを行う
抽象的な表現を避け、具体的な例を用いて階層クラスタリングを理解してもらう
前提
テーマの豚汁について早速触れていきます。
先輩から豚汁は「栄養が取れる、おかずにもなる、簡単に作れる」と教わりました。
しかし料理初心者には大問題が発生しました。
何を入れたらいいかわからない。
豚汁は何を入れても美味しい。
つい沢山入れてしまい、野菜炒めになってしまいます。
なんとか具材を厳選して、汁を迎え入れる体制を整えたいところです。
そこで階層クラスタリングを用いて、類似している具(≒なくても良い具)を炙り出し、豚汁レシピをアップデートしようと思いました。
それぞれの具の比較に用いた観点は7つです!!
(甘み、旨み、歯応え、食べ応え、カロリー、タンパク質、調理時間)
階層クラスタリングとは
階層を作り、データをチーム分けすることで、データ同士の類似度を可視化する手法。
マーケティングやブランディングに活用されています!
具体的には、デンドログラムと呼ばれるトーナメント表型の樹形図を作成します。
強み
クラスターの構成要素と要素間の距離がわかりやすい
クラスター数を決めずに分析を始められ、途中でクラスター数の変更もできる
弱み
データ量が100個を超えると計算量が増え、分析が複雑になる
→非階層クラスタリングを使用する!!
いざ実践!!
今回は階層クラスタリングでデータ同士の類似度を可視化して、代替可能な類似している複数の具材(=一つの具材で十分な豚汁を作れるグループ)を判断します!
以下、Google Colaboratory で分析を行います。
# ChatGPTで作成したCSVファイルをデータポータルにアップロード
from google.colab import files
uploaded = files.upload()
# データフレームとして読み込む
import pandas as pd
df_gu = pd.read_csv("gu.csv")
# クラスタリングに使う数値データが入ったカラムを選択
# 比較する数値の尺度を揃えるため標準化
from sklearn.preprocessing import StandardScaler
features = df_gu[["Flavor_Sweetness", "Flavor_Umami", "Texture_Hardness",
"Texture_Crunchiness", "Nutrition_Calories", "Nutrition_Protein", "Cooking_Time"]]
scaler = StandardScaler()
scaled_features = scaler.fit_transform(features)
# 階層クラスタリング(今回は結合にウォード法を用いた)
# デンドログラム(樹形図)の描画
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
linkage_matrix = linkage(scaled_features, method='ward')
plt.figure(figsize=(10, 7))
dendrogram(linkage_matrix, labels=df_gu["Ingredient"].values, leaf_rotation=90)
plt.title("Dendrogram")
plt.show()
出力された豚汁デンドログラム
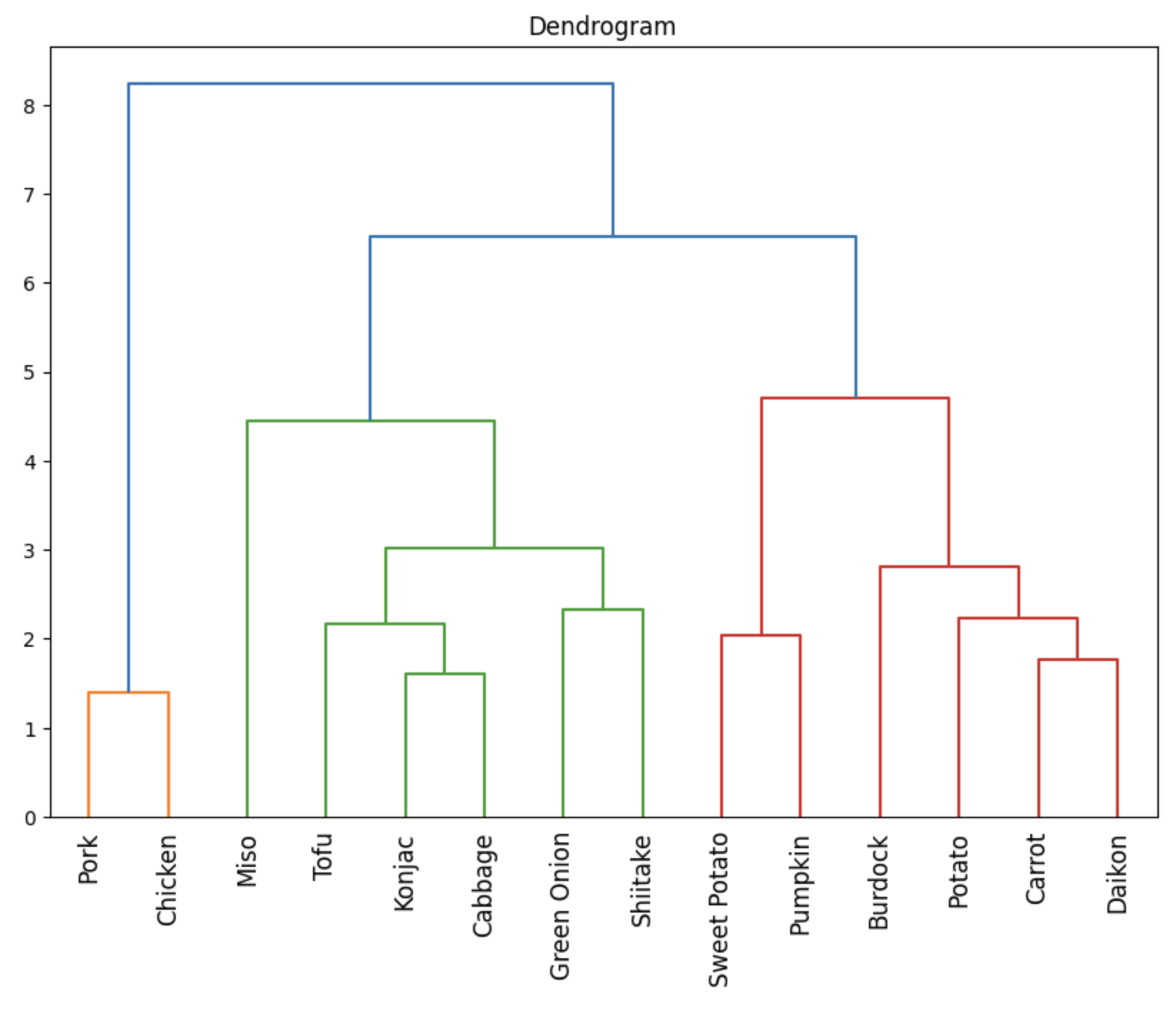
デンドログラムの読み取り
デンドログラムでは、
低い位置で合流しているほど類似度が高い
高い位置で合流しているほど類似度が低い
今回全体の中で最も低い位置で合流しているのが豚肉と鶏肉、
高い位置で合流しているのが動物性食品と植物性食品です。(ラベリングは勝手にしています)
従って一番類似度が高い具材は豚肉と鶏肉!
なので、どちらかがあれば豚汁を構成できます。
具材削減対象として最優先のグループです!
一方で、動物性食品と植物性食品の互換性が最も低いということもわかりました!
どちらを欠いても豚汁ではなくなるということですね!
クラスター数を指定する
いよいよクラスター数(具材の数)を決めていきます!
ここで重要なのは、他のクラスター(具材)と結合するまでの線の長さです。
隣のクラスターまでの線が長い=類似度が高くない
隣のクラスターまでの線が短い=類似度が高い
つまり、長い所を残し、短い所を消すと最も最適なクラスター分けができます!
ここでは縦軸が2.5や4のところで分割するのが良さそうです!
なので今回は、5つと7つの2種類のクラスター数でレシピの組み合わせを考えます!
結果を元にレシピ作成
-
5つのクラスター(縦軸が4の時)
- 豚肉、鶏肉
- 味噌
- 豆腐、こんにゃく、キャベツ、長ネギ、しいたけ
- さつまいも、かぼちゃ
- ごぼう、じゃがいも、にんじん、大根
5つのクラスターから一つずつ選ぶと、、、
豚肉、味噌、長ネギ、かぼちゃ、ごぼう!
確かに比較指標のバランスが良い!!
(※比較指標:甘み、旨み、歯応え、食べ応え、カロリー、タンパク質、調理時間) -
7つのクラスター(縦軸が2.5の時)
- 豚肉、鶏肉
- 味噌
- 豆腐、こんにゃく、キャベツ
- 長ネギ、しいたけ
- さつまいも、かぼちゃ
- ごぼう
- じゃがいも、にんじん、大根
7つのクラスターから一つずつ選ぶと、、、
鶏肉、味噌、キャベツ、しいたけ、さつまいも、ごぼう、大根!
具沢山でこちらも比較指標のバランスが良い!
結論
- 入れる材料が5つの簡単豚汁の場合
- 豚肉、味噌、長ネギ、かぼちゃ、ごぼう
- 入れる材料が7つの具沢山豚汁の場合
- 鶏肉、味噌、キャベツ、椎茸、さつまいも、ごぼう、大根
学びと今後の展望
今回の記事を書く前と後で階層クラスタリングへの理解度が格段に向上。
抽象的な言葉で逃げるのではなく具体的に説明することにより、
理解できていない点を発見できました。
実践して、それを言語化するフローの大切さを改めて認識しました。
階層クラスタリングは、
データの構成要素間の関係性が複雑な場合でも視覚的に類似度を表現できるため、
具体的にデータの中身を理解しながら進めたい場合に有効な手法だと感じました。
また、中身を見てからクラスター数を後から決められるのも強みです!
非階層クラスタリングではできない部分です。
データ同士の結合方法には、今回用いたウォード法だけでなく、多くの種類があります。
同じデータセットに対して、様々な結合方法を適用して結果の違いを比較してみると面白そうです!!
今回使用したデータフレーム
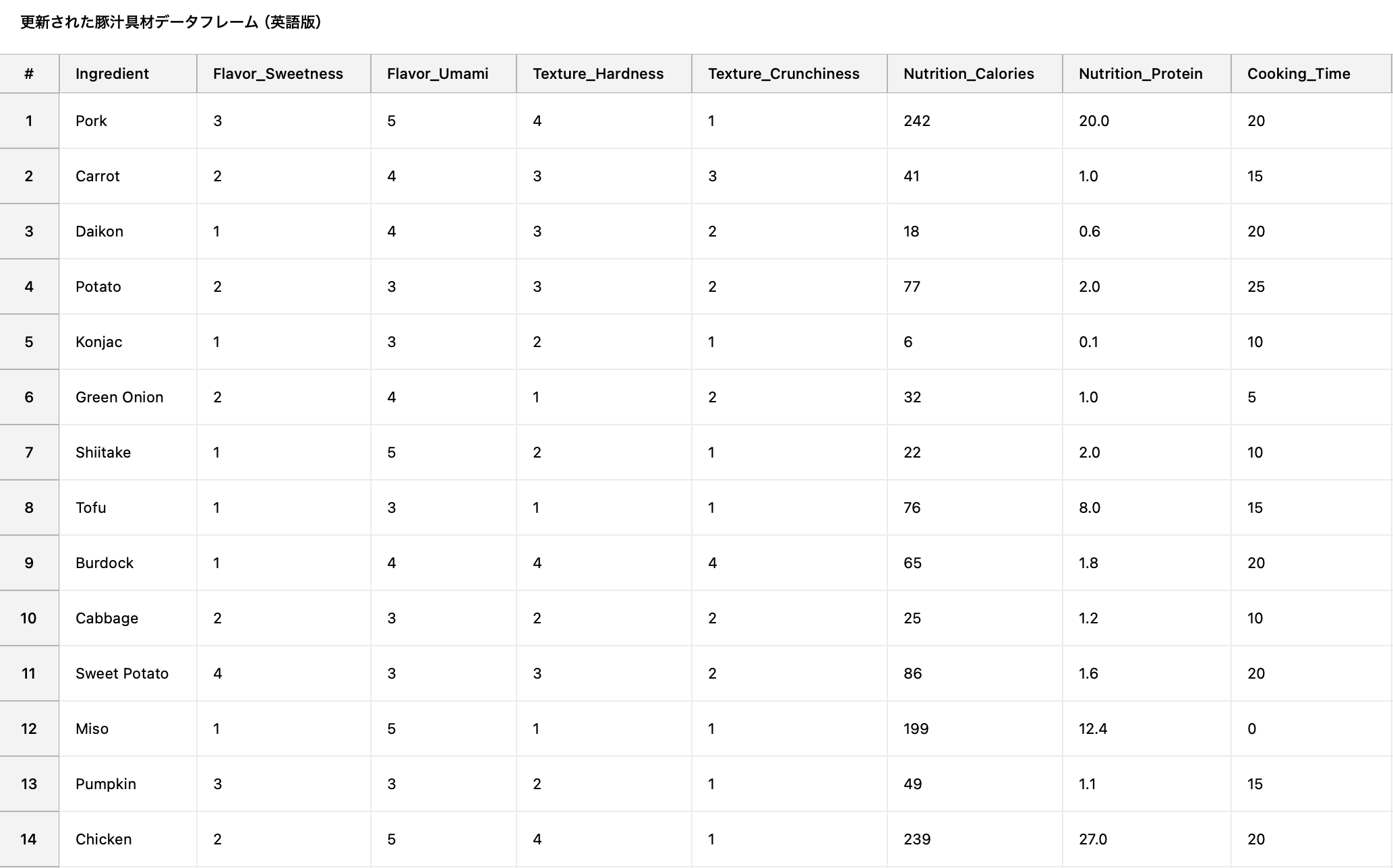
甘み、旨み、歯応え、食べ応え、カロリー、タンパク質、調理時間で比較しました!
Burdock:最初ブルドッグ?と思いましたがゴボウでした。