はじめに
2023年度の春休みに取り組んだpythonプログラミングの学習内容を記載します。教材は、以下の「Python機械学習プログラミング[PyTorch & scikit-learn編]」を用いています。
第3章 分類問題 機械学習ライブラリscikit-learnの活用
本章では分類を目的とした教師あり学習のアルゴリズム間の相違点を学びながら、それらの長所と短所を見極める力を養う。
ここからは、以下のような構成で分類アルゴリズムを紹介する。
- ロジスティック回帰
- サポートベクトルマシン
- 決定木
- k最近傍法
1.1 ロジスティック回帰と条件付き確率
ロジスティック回帰は、線形分類問題と二値分類問題に対する単純ながら強力なアルゴリズムの1つである。また名前とは裏腹に、回帰ではなく分類のためのモデルである。
早速、主な仕組みについて理解していく。
ロジスティック回帰では、活性化関数にシグモイド関数を利用する。
ここで、シグモイド関数は以下のように定義されている。
σ(z) = \frac{1}{1+e^{-z}}
この関数を図に表すと以下のようなS字形(シグモイド)曲線が表示される。
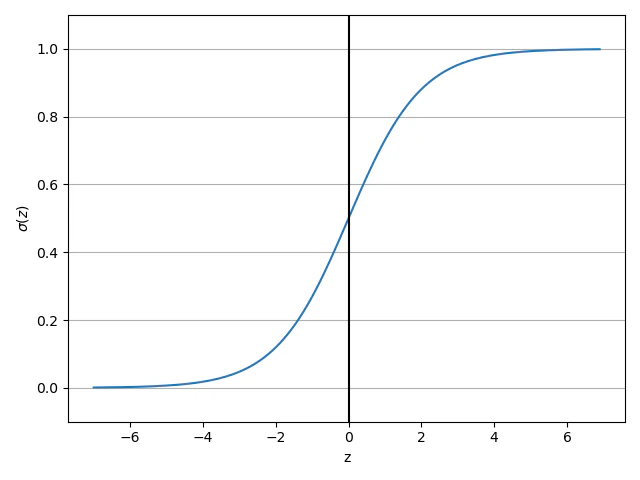
図を見てみると、シグモイド関数は、z→∞では σ(z)が1に近づくことが分かる。同様に、z→-∞では σ(z)は0に向かう。したがって、このシグモイド関数は、入力として実数値を受け取り σ(0) = 0.5を切片として、それらの入力を[0,1]の範囲の値に変換すると結論付けることが出来る。
ここで、これまでに示したシグモイド曲線を活性化関数に用いてロジスティック回帰の全体像を図で確認しててみよう。
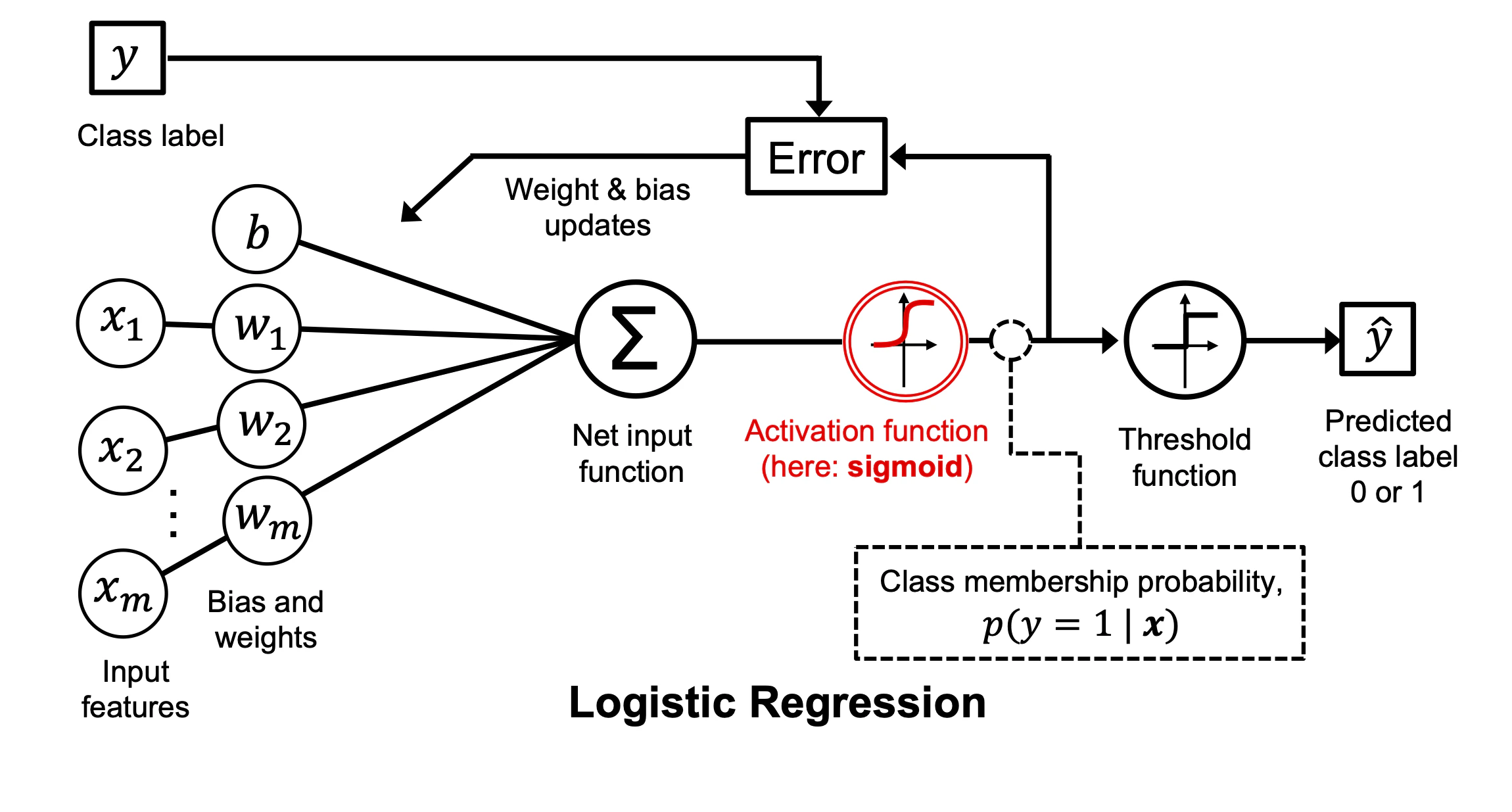
特定のデータ点の特徴量がxで、重みとバイアスでパラメータ化されるとすれば、このシグモイド関数の出力は、このデータ点がクラス1に所属している確率 σ(z) = p(y=1| x; w, b)として解釈される。
図では、クラスラベルの予測値が最終的な結果として用いられているが、
実際には、クラスの所属関係の確率(閾値関数を適用する前のシグモイド関数の出力)を見積もることに特に価値がある。
1.2 ロジスティック損失関数を使って重みを学習
重みwとバイアスbといったモデルのパラメータを適合させる方法について簡単に説明しておく。
まず、平均二乗誤差(MSE)の損失関数を以下のように定義する。
L(\boldsymbol{w},b|\boldsymbol{x}) = \sum_{i} \frac{1}{2} (σ(z^{(i)})-y^{(i)})^2
さらに、分類モデルのパラメータを学習するために、この関数を最小化する。まず、ロジスティック回帰モデルの構築時に最大化したい尤度Lを定義する。式は以下のようになる。
L(\boldsymbol{w},b|\boldsymbol{x})= p(y|\boldsymbol{x};\boldsymbol{w},b) = \prod_{i = 1}^{n}p(y^{(i)}|\boldsymbol{x}^{(i)};\boldsymbol{w},b) = \prod_{i = 1}^{n}(σ(z^{(i)}))^{y^{(i)}}(1-σ(z^{(i)}))^{1-y^{(i)}}
実際には、この式の対数を最大化する方が簡単である。これを対数尤度(log-likelihood)関数と呼ぶ
l(\boldsymbol{w},b|\boldsymbol{x})= logL(\boldsymbol{w},b|\boldsymbol{x}) = \sum_{i = 1}[y^{(i)}log(σ(z^{(i)}))+(1-y^{(i)})log(1-σ(z^{(i)}))]
まず、対数関数を適用すると、アンダーフロー(下位桁あふれ)の可能性が低下する。アンダーフローが発生する可能性があるのは、尤度が非常に小さい場合である。次に、対数関数を適用して係数の積を和に変換すると、加算を用いてこの関数の導関数が簡単に得られる。