はじめに
Life is Tech ! Mentor アドベントカレンダーついに最終日ですね。最終日は6期iPhoneコースメンターのへむへむ(@rikky0611)が担当します。昨年はメンターとパンサーを人工知能に区別させてみた - Qiitaで画像認識をやりました。
2017年、人工知能技術はどんどん加速し、たくさん面白いこともできるようになってきましたね。今回も面白いことに挑戦して見たいです。
概要
Neural StoryTellerという、画像からストーリーを生成する技術を使って、画像からRADWIMPSっぽいストーリー文章を生成します。
上記ブログの例では、恋愛小説っぽいストーリーを生成しています。例えば、

このように、お相撲さんの取り組みをロマンティックに描写しています。
今回は
- 日本語で
- 誰かの文章っぽく
できないかということで挑戦しました。
背景
Life is Tech ! のメンターにはポエマーがいます。彼らは頻繁に、自身のInstagramで良い写真にポエムをつけて投稿をします。例えば、Webコースのたいてぃーくん。
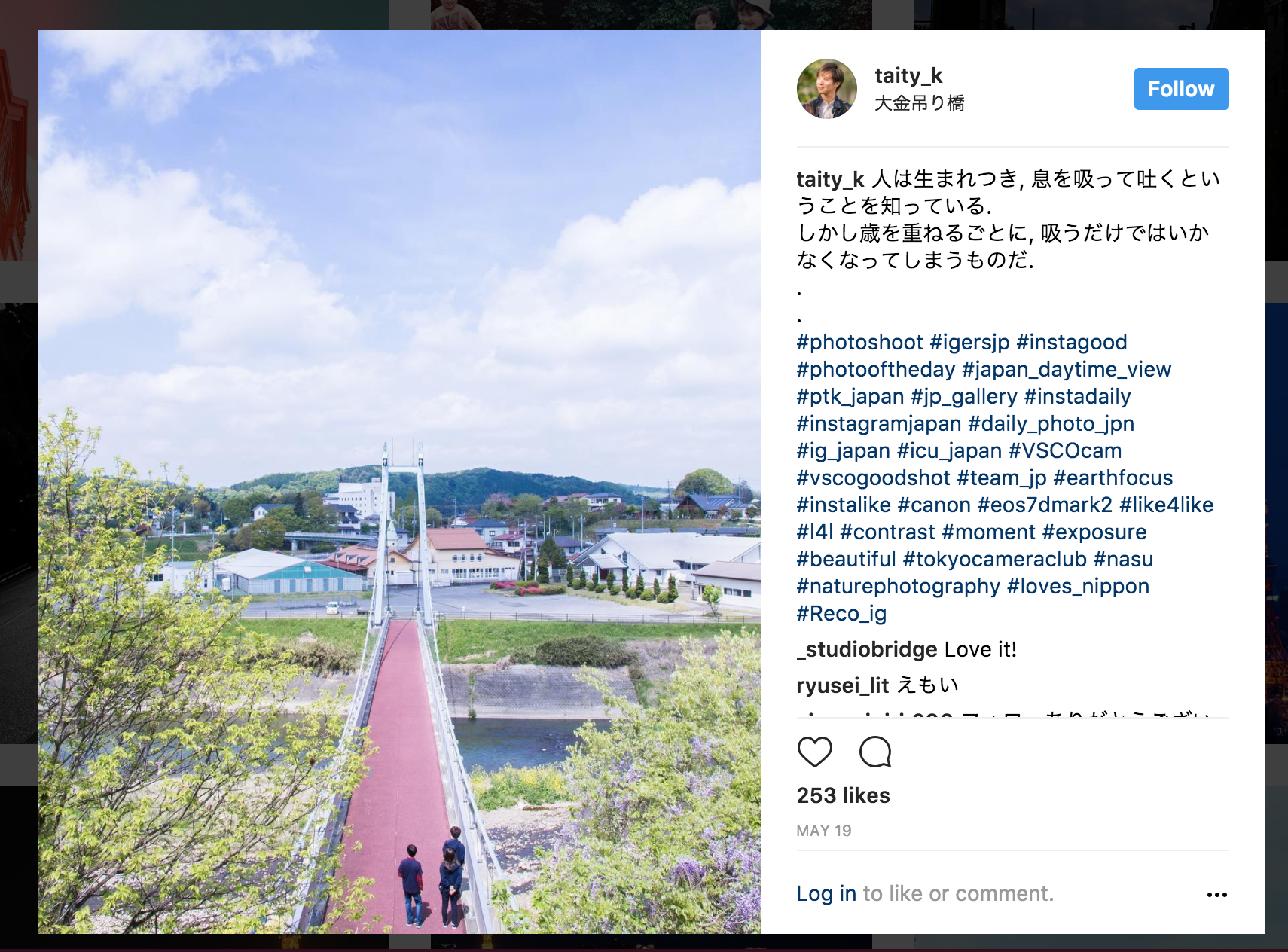
心に響くいいポエムですね。
PoeTech宣言 - あっちのブログ
こちらのブログでも言及されていますが、現代社会においてPoemの重要性はますます上昇してきていると感じます。
しかし一方で、次のような弊害もあります。
やべ、ポエム考えてたら電車降り忘れた...💦
— Riku Arakawa (@rikky0611) December 16, 2017
「良い写真は撮れた! でもポエムが思いつかないからシェアできない!」ということで日常生活に支障をきたしてしまっている例です。
今回はこれをサポートできるような技術を開発しようと思って取り組みました。
ポエムを生成する技術は、人工知能は「詩人」になれるのか──グーグルの試み|WIRED.jp(元論文: https://arxiv.org/abs/1511.06349 ) など、過去の事例が多かったので、今回は画像と紐づいたポエムを生成したいと考えました。
オリジナルのブログでは英語の恋愛小説の他にTaylor Swiftさんの歌詞で実験していましたが、今回は日本語でやってみたかったため、ファン歴8年のRADWIMPSの野田洋次郎さんの歌詞で実験してみました。
(※ アドベントカレンダーのネタとして画像とポエムをくっつけたいなぁと漠然と考えていましたが、方向性を定めたのが22日で、ライブラリに闇(後述)があったりで、なんとか1回動かすのがやっとでした。そのためチューニングなどはできておらず、ライブラリコードの修正も手当たり的だったので、その辺は深入りしません。また、Life is Tech ! アドベントカレンダーということで、高校生がなんとなく雰囲気がわかって楽しめるように努めます。参考論文やリンクをつけてますので、深く知りたい人は調べて見てください。)
技術解説
今回の全体の仕組みは次のようなマッシュアップ(組み合わせ)になっています。

※ 機械翻訳をのぞいてnewral-storytellerの元プロジェクト(https://github.com/ryankiros/neural-storyteller) に従います。
1. 画像キャプション
画像の様子を説明する自然言語の文章を、生成する技術のことです。
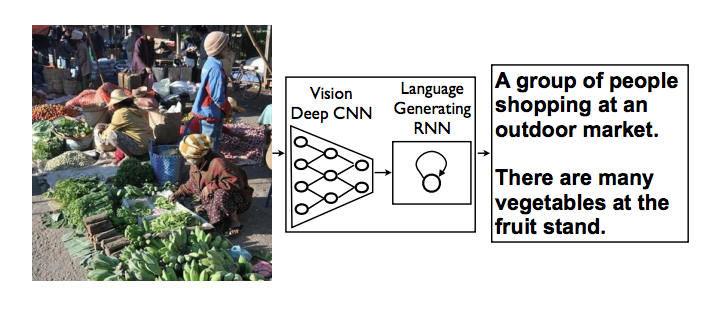
出典: Show and Tell: A Neural Image Caption Generator, 2015
すごいざっくり言うと、画像と説明文のペアをたくさん与え(MSCOCOという有名なデータセットでは328,000枚)、画像を説明する文章を学習します。
Chainerで画像のキャプション生成 - Qiita にわかりやすくまとめられています。画像を認識するネットワークと文章を生成するネットワークをつなげて一貫して学習させているのですね。
進展の早い深層学習の世界では、この技術は新しいものではなく、現在はこれをベースに、画像に対する質問と回答、動画キャプションといった発展タスクも行われています。
※ 日本語用の画像キャプションデータセットもあり、(日本語画像キャプションデータセット「STAIR Captions」公開 | STAIR: Software Technology and Artificial Intelligence Research Laboratory, 2017) これらを使えば機械翻訳の要素はいりませんが、今回は時間がなく学習済みモデルの持っているMSCOCOでここは対応しました。
2. skip thought ベクトル
まずskip thoughtについてです。こちらのポストがかなり丁寧にまとまっていて非常に参考になりました。(Skip-thoughtを用いたテキストの数値ベクトル化 - Platinum Data Blog by BrainPad) (元論文: https://arxiv.org/abs/1506.06726 ,2015)

skip thoughtは文のベクトル化を行います。文同士が似ている、意味が近い、などをコンピュータの中で議論する上で、欠かせないのがこのベクトル化です。 文に限らず、単語、画像やその他様々なものがベクトルに表されて議論されるなぁと自分は感じます。
少し話がそれますが、2017年のはじめに作った音楽bot APOLOでは、楽曲同士の類似性を議論するために楽曲のベクトル化を試みようとしました。(LINE BOT AWARDS に向けて~APOLO計画で実現したかったもの~ – APOLOチームブログ – Medium)
文をベクトルにする手法はいくつかありますが、skip thoughtは、特に前後の文脈と関連したベクトル表現を教師なし(文章を入れるだけで良い)学習方法になります。今回は、入力の一文に対し、前後の文脈も一緒に生成してストーリー(ポエム)を表現して欲しいのでこのベクトルを選びました。
skip thoughtは一般にエンコーダーデコーダーモデルという構造を取っています。(ここでは再帰構造などについては説明しません。詳しくは上記ポストを見てください。)

この真ん中に現れるベクトルが今回でいうskip thoughtベクトルになります。すなわち、エンコーダーは文をskip thoughtベクトルに直し、デコーダーはskip thoughtベクトルから文に直す役目を果たします。
具体的な入出力ですが、今回の場合例えば、RADWIMPSの前前前世の歌詞
a 君の前前前世から僕は、君を探し始めたよ
b そのぶきっちょな笑い方をめがけてやってきたんだよ
c 君が全然全部なくなって、チリヂリになったって
ではbを入力文章とし、その前後のaとcを出力として学習します。
一度エンコーダーとデコーダーを用意できれば、あとは双方をばらばらに使用してもよいのがポイントです。実際次のスタイルシフトではエンコーダーとデコーダーを分けて使用します。
3. スタイルシフト
ここは面白いところで、Neural Storytellerの本質的な箇所なので力点をおいて説明します。
まず2番で用意したエンコーダー・デコーダーはRADWIMPSについて学習しています。一方、1番の画像キャプションで得たキャプションを日本語にした文は、RADWIMPSの歌詞には到底ないようなものです。
すなわち、単純に2番で得た画像キャプションをエンコーダー・デコーダーに入れるだけではダメなのです。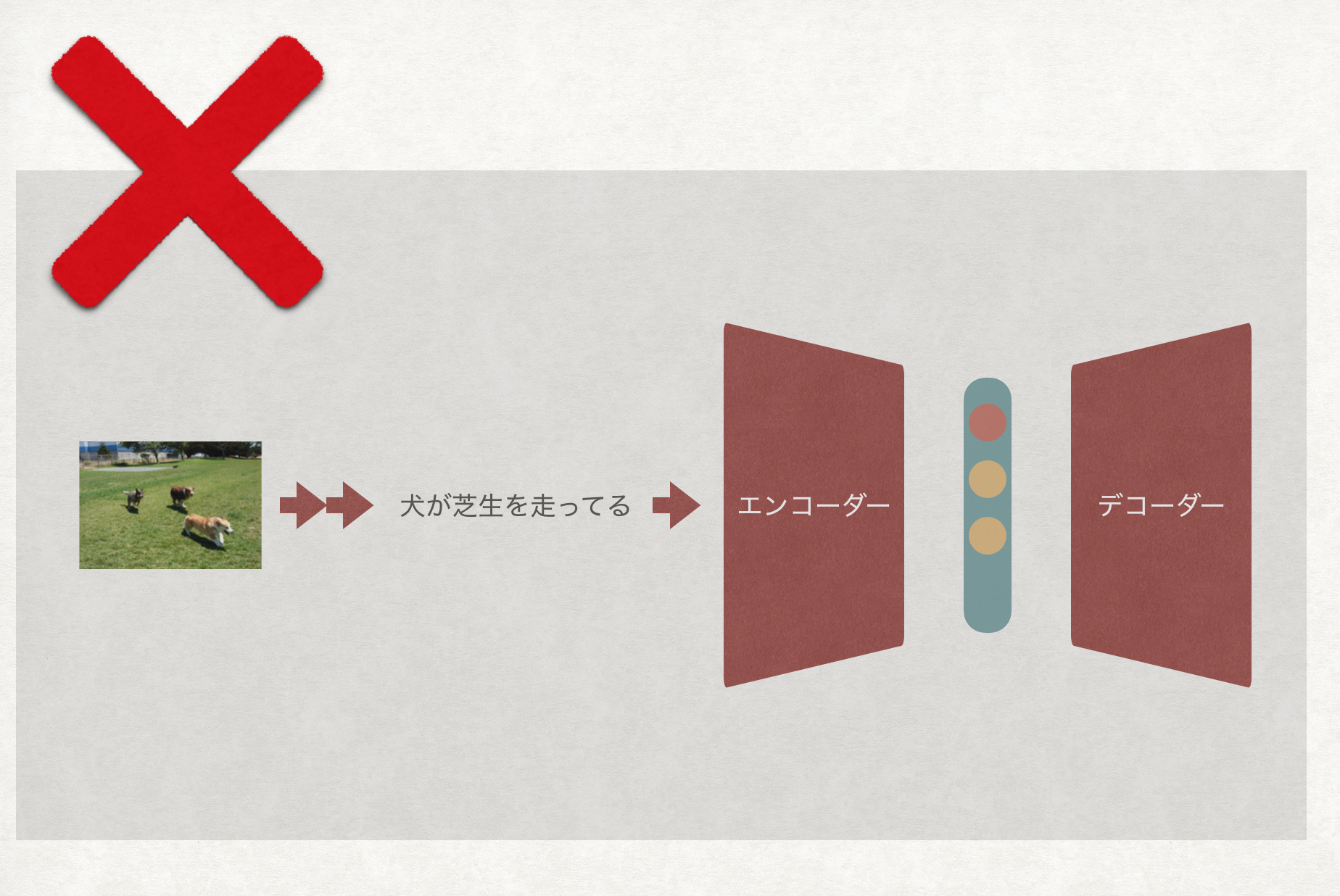
実際、「犬が芝生を走っている」を学習させたエンコーダー・デコーダーに通し、4文ほど出力させてみると、
一世一代 』 が 君 を
『 一世一代 』 の 愛 を
『 一世一代 』 の 愛 を
『 一世一代 』 の 愛 を
となり確かによくわかりません。
これを解決するのがスタイルシフトです。
結論から言いますと、次のような工夫をします。
エンコーダーの出力のskip thoughtベクトルを $\vec{x}$ 、
画像キャプションの文集合に対し、それぞれのエンコーダーの出力のskip thoughtベクトルの平均を $\vec{c}$
学習データ(今の場合RADWIMPS)の文集合に対し、それぞれのエンコーダーの出力のskip thoughtベクトルの平均を $\vec{b}$
とすると、デコーダーに入力するベクトルを、
$\vec{x} - \vec{c} + \vec{b}$
にします。

これは気持ち的には、普通の文っぽさ($\vec{c}$)を引いて、RADWIMPSの歌詞っぽさ($\vec{b}$)を足していることになります。文のベクトル化とうことを繰り返し言ってきましたが、これは単語をベクトルに埋め込むword2vecの有名な例と似ていると思います。

では実際「犬が芝生を走っている。」をエンコーダーに通したあと、このように変換してデコーダーに通すとどのようになるのでしょうか。結果はこちら。
言葉 が 君 を 抜け 駆け て
言葉 が 溢れ て ください
『 一世一代 』 の やり場 を
『 一世一代 』 の 愛 を
うーん、まぁ、「走っている」と「抜け駆けて」が近いんでしょうか! style shift以前よりはしっくり来る気がします。
実験
実験環境は以下です。
Anaconda 2.5.0
python 2.7.11
theano 0.7.0
gensim 3.2.0
MeCab 0.996
画像キャプションについては、今回は時間のなかったため学習済みのモデルを使用しました。
翻訳は、まぁ、googleですね。。。
skip thoughtとスタイルシフトについては著者の実装を使いました。(https://github.com/ryankiros/skip-thoughts) skip thoughtベクトルはデフォルト値の2400次元です。
実はこのライブラリ、依存関係が分かりづらかったりパッケージ化されてなかったり、エンコーダー・デコーダーの学習が別々でモデルの持つパラメタの数が違ったりと、大変でしたが、なんとか微修正を重ね動きました!
元のレポジトリでは英語でしたが、日本語に変えたことで、読み込むword2vecを日本語にしたり、前処理を日本語用に変えたりする必要がありました。
RADWIMPSの学習データとしては、英語の歌詞を除いたデータを頑張って集めて、頑張って文ごとに分けて前処理をしました。ここが一番しんどかった。
全体では117楽曲、3577文で学習を行いました。エンコーダー・デコーダー合わせてGPUで5epoch, 4時間くらいかかりました。
まとめ
今回は、画像からポエム生成を行いました。画像と言語を繋げる研究は盛んですが、実際に手を動かして実験してみると上手くいかないことが多く大変でした!
結果は、元のブログほど良質な文は生成できていませんが、贔屓目で見れば気持ちが感じられますね。
時間のなかったため、デフォルト値で学習をさせており、学習epochも5回しか行えなかったりと、まだまだ改良の余地があるかなと感じます。特に、文のデータが少なかったため、歌詞で見たことあるような文に偏って出力されてしまっています。(元ブログの恋愛小説では、1400万文のデータセットを使っているそうなので、レベルが違いました...他のアーティストの歌詞も加えてもいいかもしれないですね!)
一文の長さを短く区切ってしまったのも改善点になるかもしれません。(よく読むと、元ブログでは$\vec{b}$は100単語以上の文のskip-thoughtベクトルの平均らしいです...)
本記事が少しでもPoeTechの発展に貢献できましたら幸いです。
(Life is Tech ! のメンバーが少しでも取り上げた技術に興味をもってくれたら幸いです。)
最後はポエムで
では最後は実際に今回作ったものを使って締めましょう。
いまLife is Tech ! はクリスマスキャンプ2017 なのでそこにいるメンバーに想いを込めて、二年前のクリスマスキャンプの外でのライトアップの写真で...
メリークリスマス!
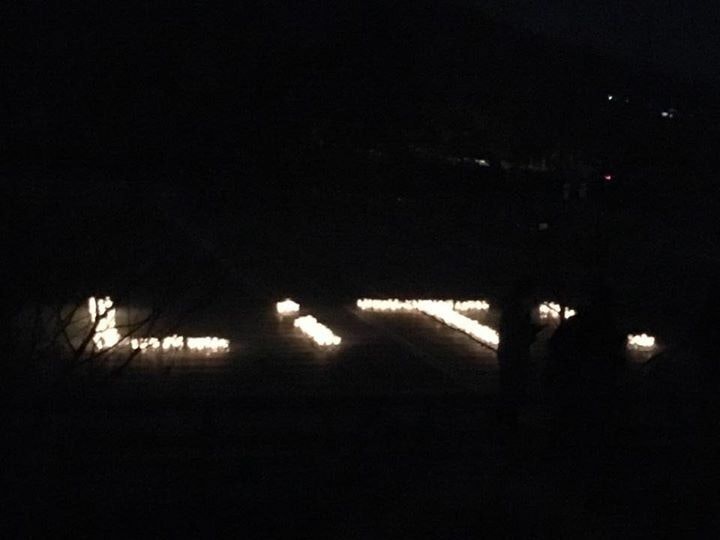
僕 が 好き で い て くれる と
僕 が い ない と の よう に
こんな こと を 忘れ た の に
こんな こと を 知る 術 も ない