はじめに
Apache Sparkの機械学習ライブラリーmllibを弊社のサービス、分析業務に使えるかを検討するために各種ベンチマークを実施する予定でいます。
その第一弾として、spark mllibの教師あり分類アルゴリズムの精度評価を実施したので、その結果を共有します。
spark mllib 教師あり分類アルゴリズム
Spark mllibの教師あり分類アルゴリズムには
- Naive Bayes (NB)
- SVM (SVM)
- Logistic Regresssion (LR)
- Decision Tree (DT)
- Random Forest (RF)
- Gradient Boosted Tree (GBT)
があります。
詳細な特徴などは、参考リンクを参考していただくとして、我々は、今回、次の観点からこれらのアルゴリズムの精度評価を実施しました。
-
線形分類器と非線形分類が可能な分類器との比較
-
並列分散処理のための実装により、既存機械学習ライブラリと比べて精度性能などに変化があるか?
-
各アルゴリズムの特徴把握
mllibのNB,SVM, LRは線形分類器のクラスに入ります。DT, RF, GBTなどは、線形分離できないデータを分類できる非線形分類が可能なアルゴリズムになります。線形分離不可能なデータに対して、線形分類器と非線形分類器の精度評価を実施しました。
mllibのSVMは並列分散処理のために、オリジナルのSVMとは異なる方式で実装されています。LRも同じような実装になっており、この実装による精度変化はあるか?の観点で既存のライブラリとの精度比較を実施しました。
また、各アルゴリズム固有の精度面、処理時間の観点での特徴なども調査しました。
精度測定
今回は、精度性能評価が主目的なので、sparkはlocal modeで起動させ、各種分類アルゴリズムの精度性能を測定しました。
測定は、下記設定で実施しました。
- Spark 1.5 (https://github.com/apache/spark)を使用
- 今回は、2値分類器の精度評価のみを実施
- 分類器のパラメータに関して主要なものを1つだけ変化させ精度評価. 他は、Machine Learning Library (MLlib) Guideの exampleと同じパラメータを使用
使用したデータは (libsvm dataから取得)
| data | データ数 | 正例数 | 特徴空間の次元 |
|---|---|---|---|
| a9a | 48842 | 11687 | 123 |
| news20 | 19996 | 9999 | 1355191 |
| rcv1 | 20242 | 10491 | 47,236 |
になります。
a9aは、世帯収入が一定以上かどうかを判別するタスクのデータで、特徴量は全て1.0. 線形分離不可能なデータになっています。
news20は news groupのテキスト分類データで、rcv1はReuter newsのテキスト分類用データです。
a9aは、線形分類器、非線形分類器の比較用に、news20, rcv1 dataは線形分離可能なデータです。一般的な分類器であれば高精度がだせるデータなので、sparkでも良い結果をだせるかどうかを見るために使用しました。
精度測定方法
精度は10 fold cross validationをa9a, news20, rcv1 dataに対して実施。
精度評価値としては、全データの正解率、正例F1値を採用
\begin{eqnarray}
正解率&=& \frac{分類正解数}{正例データ数}, \\
F1値&=&\frac{2}{(1/正例適合率+1/正例再現率)}, \\
正例適合率&=& \frac{正例分類正解数}{正例出力数}, \\
正例再現率&=& \frac{正例分類正解数}{正例データ数}. \\
\end{eqnarray}
精度測定結果
a9a, news20, rcv1 dataに対する分類精度は以下になりました。
a9a data分類精度
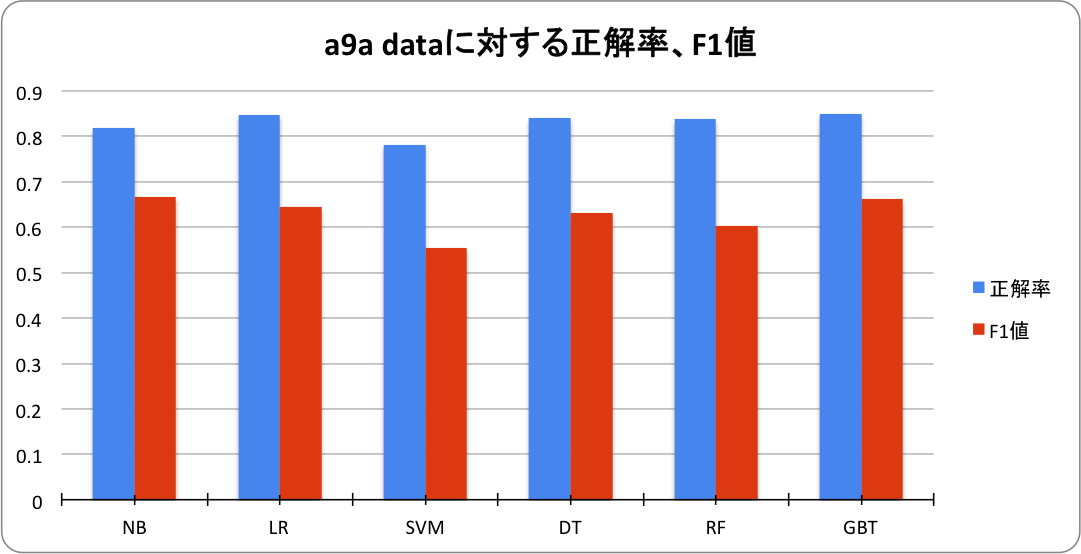
| アルゴリズム | 正解率 | F1値 | parameter設定 |
|---|---|---|---|
| NB | 0.817 | 0.660 | Lambda = 1.0 |
| LR | 0.849 | 0.650 | C = regParam = 0.01 |
| SVM | 0.781 | 0.554 | C = regParam = 0.1 |
| DT | 0.841 | 0.632 | maxDepth = 9 |
| RF | 0.838 | 0.603 | maxDepth = 9 |
| GBT | 0.849 | 0.661 | maxDepth = 7 |
正解率で最も性能が良いのはGBTで、F1値ではNBでした。線形分類不可能なデータなので、特徴の組み合わせを考慮できる決定木系のアルゴリズムが優位になると予想していたのですが、今回の測定では、NB, LRとGBTの性能差は思ったほどなかったです。local modeのためか、GBTの学習時間は、NB, LRの数十倍になっており、分散モードでも学習に時間がかかる場合、実用的な観点でのGBTの優位性は低くくなるとの印象を持ちました。
news20 data分類精度
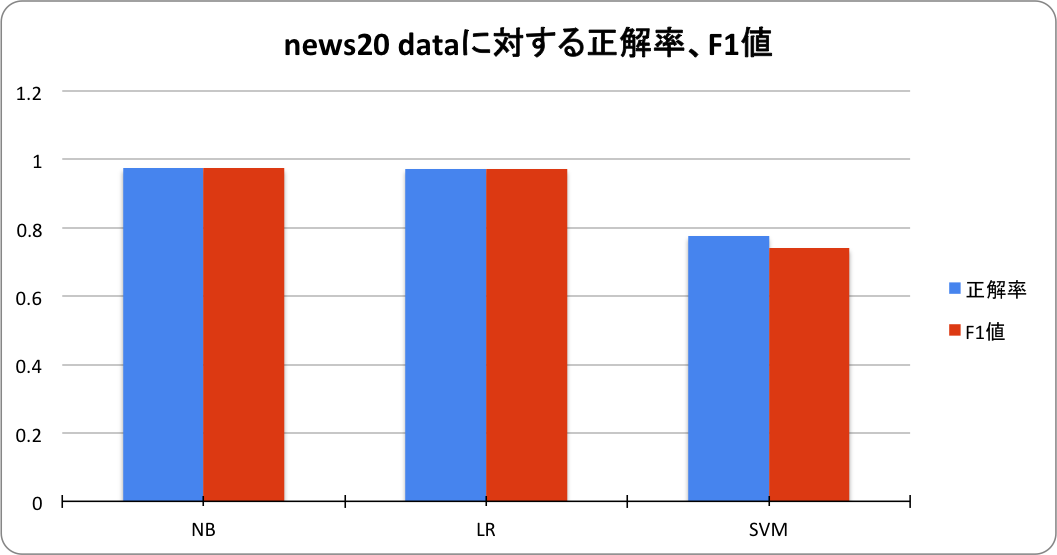
| アルゴリズム | 正解率 | F1値 | parameter設定 |
|---|---|---|---|
| NB | 0.974 | 0.974 | lambda = 0.001 |
| LR | 0.972 | 0.972 | regParam = 0.01 |
| SVM | 0.777 | 0.741 | 1.0 |
線形分類器のみの結果を記載します。決定木系のアルゴリズムは実時間内で学習を完了できなかったので記載していません。
このデータに関しては、NBが最も高精度でした。一般的にはSVMが最も高性能とされるが、全データでSVMは良い結果を示していませんでした。
決定木系のアルゴリズムは、特徴空間の次元が非常に高い場合には、特別なparameter設定をするなどして対処しないと動作させることが難しい可能性があるかもしれません。
決定木の深さを浅くして、木の数を大きくするなどして、文書分類などの高次元データにも対応できると思っていたのですが、すくなくても、parameter設定が適切でないと動作しないのではという印象を持ちました。今後、実装まで踏み込んで、調査したいと思っています。
rcv1 分類精度
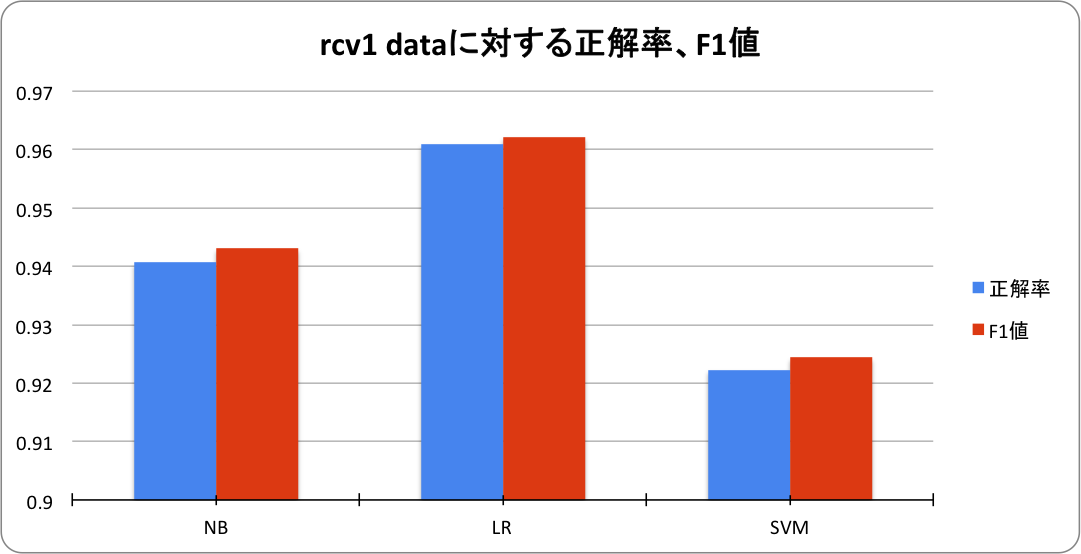
| アルゴリズム | 正解率 | F1値 | parameter設定 |
|---|---|---|---|
| NB | 0.940 | 0.943 | lambda = 0.1 |
| LR | 0.960 | 0.962 | regParam = 0.2 |
| SVM | 0.922 | 0.924 | regParam = 1.0 |
LRが最も高精度でした。news20 dataとほぼ同じ傾向でした。
各分類アルゴリズムの特徴
今回の精度測定により各分類アルゴリズムに対して下記のような評価を持ちました。
NaiveBayes (NB)
実装は簡易で、理解しやすく、性能も予想通りの性能をだしてくれました。学習も全データを1なめするだけでよく速い。多値分類にも対応しており、使いやすく、拡張も容易という印象を持っています。(Complement NB, Semi-Supervised NB etc.)
Logistic Regression (LR)
NBと同じく、予想通りの性能を安定して出してくれました。評価はSGDとL-BFGSの双方を実施したが、SGDは収束性が悪いのか、maxIter=100では性能が出なかったので、L-BFGSの結果を記載しています。
news20 dataでは最も精度が高かったが、学習時間、パラメータ設定などを考えるとNBの方が今回のデータに関しては優れているという印象を持ちました。
今回は、L2正則化のみを評価したが、L1正則化項のバージョンも評価したいと思っています。
SVM
線形SVMのspark実装で、SGDで学習、mini batch学習対応、ヒンジ損失関数、L1, L2正則化項に対応している。今回の評価では、SGD学習、mini batch fraction=1.0, 反復回数=100を全てに設定した。
今回の評価では、良い精度を出すことはなかったです。parameter設定などを見直すなどして、これが本来の性能なのかを確認したいと思っています。(反復数が少なく収束していないなど)
さらに、defaultのparamter設定でも高精度がだせる最新online学習系アルゴリズムなどに拡張したいと思っています。
Gradient Boosted Tree(GBT)
決定木を弱学習器にしたboostingのspark実装。他の実装では高精度との噂を聞くことが多く期待していました。a9aでは、最も正解率が高く、性能の高さを見せたが、news20では学習が実時間で終了できなかったです。また、a9aでも、木の深さが深くになるにつれて学習時間が大きくなり、NB,LRの数十倍の 学習時間がかかっていました。完全分散modeで再度、詳細な評価をしたいと思っています。
Random Forest (RF)
教師あり分類アルゴリズムとしては、最も高性能とされるアルゴリズムの1つ。SVMと同じ、今回は目立った性能を示さなかったです。
Decision Tree (DT)
決定木のspark実装。決定木は単純でわかりやすいが精度はさほど高くないというのが、一般的な評価ですが、今回の評価でも同じ印象を持ちました。Sparkでの実装は私にはやや複雑で、分類器として利用する動機はあまりなく、ルールを抽出するデータマイニング用途には使ってみたいと思っています。
a9aデータに対する分類学習では、最大深さ=9で最高精度を出していました。GBT, RFともども、非線形分類器の優位性がでるユースケースでさらに性能を調査、確認したいと思っています。
他の機械学習library, toolとの比較
今回評価に使ったデータは、並列分散処理させてなくても十分高速に学習、分類が実行できます。そこで、既存の機械学習ライブラリーとの精度比較を実施してみました。
比較対象は、 SVMの実装の1つlibsvmと online学習アルゴリズム Confidence Weighted アルゴリズムのオリジナル実装の2つです。
評価方法はsparkの場合と同じです。
a9a data分類精度
| 実装 | 正解率 | parameter設定 |
|:-----------|------------:|:------------:|--:|
| Spark GBT | 0.849 | maxDepth=6 |
| libsvm Gaussian Kernel | 0.848 | C=1.0 |
libsvmのGaussian KernelとSpark GBTはほぼ同じ精度を出していました。
news20 データ分類精度
| 実装 | 正解率 | F1値 |
|:-----------|------------:|:------------:|--:|
| Spark NB | 0.975 | 0.975 |
| original CW | 0.992 | 0.993 |
online学習器で最も精度性能が高いアルゴリズムの中の1つであるConfidence Weightedアルゴリズム(CW)は、news20で最も高精度だったSpark NBに比べてより精度が高く、学習も高速に行えていました。このアルゴリズムを含む最新のonline学習アルゴリズムをSparkに精度を落とさずに実装できればと考えています。
おわりに
最後に、Sparkの教師あり分類アルゴリズムの想定ユースケースについて私見を書いてみたいと思います。
教師あり分類アルゴリズムの主なユースケースは下記の2つと考えています。
- リアルタイムで入ってくるデータに対して、オンラインで学習、分類、予測するようなタスク
- 大量に保持されているデータから、特徴エンジニアリングを実施して、高性能な分類器を構築し、分類器を分散実行して、大量のデータを分類、予測する。
1. はいわゆるonline処理、streaming処理になります。2. はバッチ処理になります。
Spark mllibでのonline学習は、現在、LogisticRegressionのみに対応しているようですので、
最新online学習アルゴリズムの適用や、modelの配置法、streaming処理での精度の担保方法などを今後検討してみたいと思っています。
2.のバッチ処理において、正解データを、保持している大量データから作成するような場合、現在のsparkではうまく扱えないように思います。
例えば、文書のクラス分類タスクの場合、クラスラベルを文書に付与する必要がありますが、この作業はコストがかかるため、少量データのみにクラスラベルを付与して、少量の正解データと、大量の正解なしデータから、高性能な分類器を構築したいと考えたとします。
いわゆる、半教師あり学習アルゴリズムですが、現在のSpark mllibには半教師あり学習アルゴリズムはありません。現実のユースケースでは、クラス分類は行いたいが、その学習データの作成はめんどいということは よくあると思いますので、半教師あり学習アルゴリズムのSpark実装を今後行っていきたいと思っています。
今回、Spark NaiveBayesの半教師あり学習アルゴリズムへの拡張プロトタイプ NaiveBayesEMを実装しました。この実装で、news20 dataでは教師データ数が少ない場合にはNBよりも精度が高いという下記のような結果を得ています。
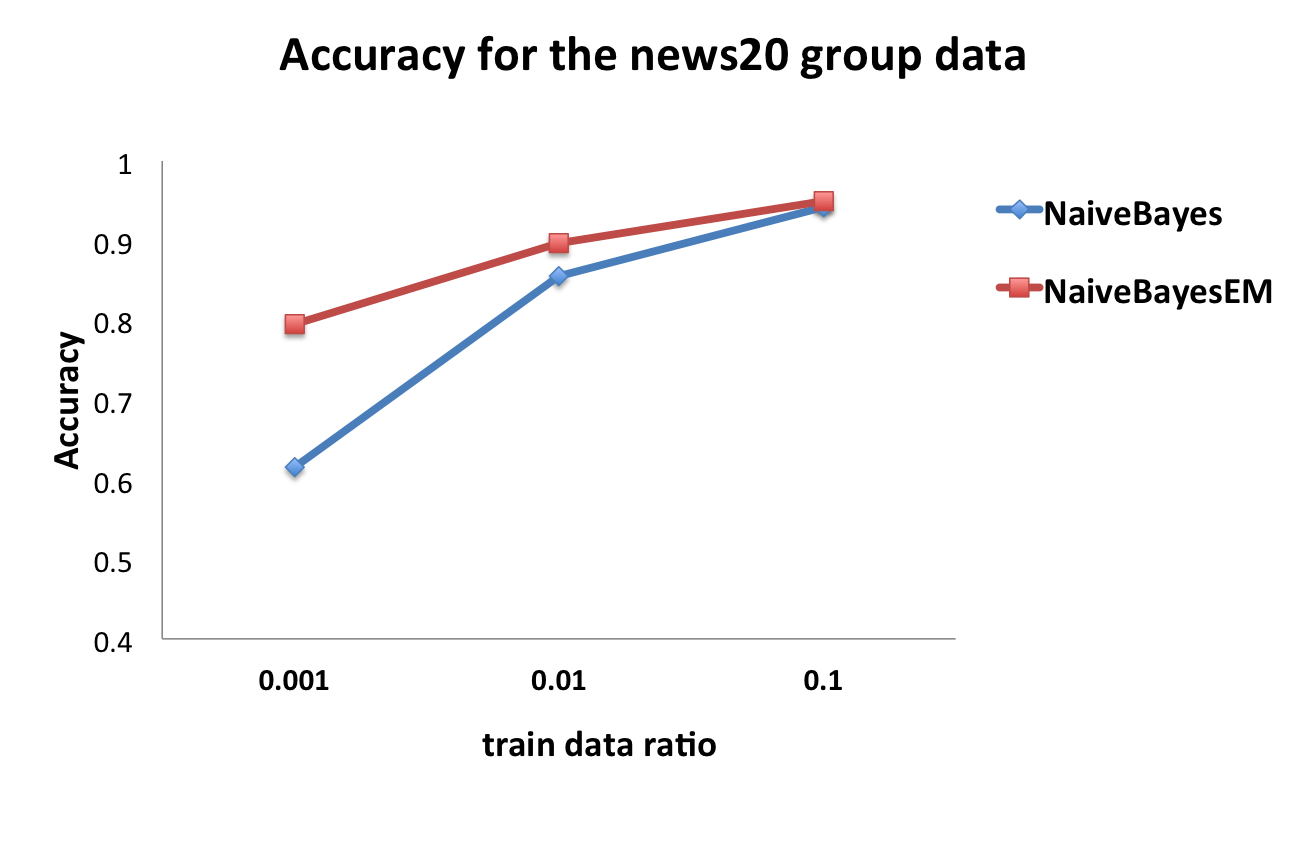
今後は、弊社のユースケースにあうSpark mllib関連の機能、実装に関しては、積極的にApache Spark本体にcontributeできたらと思っています。
参考リンク
[1] Apache Spark : http://spark.apache.org/ , https://github.com/apache/spark
[2] はじめてのSpark : http://www.oreilly.co.jp/books/9784873117348/
[3] Spark Summit : https://spark-summit.org/
[4] Machine Learning Library (MLlib) Guide : http://spark.apache.org/docs/latest/mllib-classification-regression.html
[5] libsvm dataset: https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary.html
[6] libsvm : https://www.csie.ntu.edu.tw/~cjlin/libsvm/
[7] Confidence-Weighted Linear Classification : http://www.cs.jhu.edu/~mdredze/publications/icml_variance.pdf