概要
この記事は、「TTDC Advent Calendar 2024」の10日目です。
本記事では、「単語」の類似度・距離に着目し、その代表例として「コサイン類似度」と「ユークリッド距離」を取り上げます。これらを理解することで、テキスト全体の類似度を考える際の基礎を押さえることを目指します。さらに、具体例を用いて単語間の関係性を可視化し、それらがどのように類似性や距離として表現されるかを考察します。
はじめに
昨今では、数多の高性能生成AIが台頭し、日常生活や業務の一部として利用される場面が増えてきました。私自身も生成AIツールに触れない日はほとんどありません。そんな生成AIは、大量のテキストデータを学習し、「前の単語に続く最適な単語は何か?」を予測することで文章を生成しています。学習時に、モデルは単語やフレーズ間の「意味的な関連性」や「文脈の近さ」を捉え、適切な単語を予測できるようになります。この技術の背後には、「テキストの類似性」を定量的に測る仕組みが深くかかわっています。
テキストの類似性を測る技術は、生成AIだけでなく、さまざまな場面で重要な役割を果たしています。たとえば、検索エンジンでは適切な結果を返すために文書間の類似性を計算し、レコメンドシステムではユーザーの好みに合った商品や情報を提案する際に活用されています。さらに、校正ツールや重複検出といった業務支援ツールでも、類似性指標は欠かせません。
生成AIが高度に進化した現在でも、類似性を示すこれらの技術は次のようなメリットを持っています。
- 定量的:類似性をスコアとして示すことで、結果を客観的に評価できる。
- 軽量で効率的:簡易な計算で結果を得られる。
- 特化型タスクへの最適性:特定のタスクやデータに合わせた柔軟な活用が可能。
このように、生成AIの時代においてもテキストの類似性を測る技術は、生成AI技術の中核を支える役割を果たすだけでなく、応用領域を広げることで、生成AI時代においても重要な基盤技術として活用されています。
本記事では、コサイン類似度とユークリッド距離の特徴や使い分けについて、具体的な例や可視化を交えながら考察します。生成AI時代における基盤技術としての「テキストの類似性」について、理解を深めるきっかけとなれば幸いです。
類似度と距離の基本概念
テキストの類似性を測る指標には、大きく分けて「類似度」と「距離」の2種類があります。これらはどちらも、異なるテキスト間の関係を定量的に評価するために使用されますが、視点や用途が異なります。今回は代表的な類似度、距離として、「コサイン類似度」と「ユークリッド距離」について取り上げます。
類似度や距離を計算するためには、テキストをベクトルとして扱う必要があります。詳しい説明を省きますが、本記事では、埋め込みベクトルに日本語BERTモデルtohoku-nlp/bert-base-japanese-v3を使用します。
コサイン類似度(Cosine Similarity)
「類似度」は値が大きいほど2つのテキストが似ていることを意味する指標です。コサイン類似度は、2つのベクトルがなす角度のコサイン値を測り、その類似性を評価する指標です。
コサイン類似度の値は次の範囲を取ります:
- 1:完全に同じ方向(非常に類似)
- 0:直交(関連性なし)
- -1:完全に反対方向(全く逆の意味)
ユークリッド距離(Euclidean Distance)
「距離」は値が大きいほど2つのテキストが似ていないことを意味する指標です。ユークリッド距離は、2点間の直線距離を計算し、空間内でどれだけ離れているかを数値で表します。
類似度と距離の関係
類似度と距離は実質的に逆の概念です。両者は異なる視点でテキスト間の関係をとらえるものであり、どちらを選ぶかはタスクに依存します。
例えば、検索エンジンでは、ユーザが入力した検索語と文書の類似度を計測し、最も関連性の高い結果を表示します。これは、「旅行 プラン」の検索に対し、「観光計画」や「旅行ガイド」が関連性の高さから表示されるようなケースです。
一方、重複検出や文書比較では距離を用い、文書間の差異を測定します。例えば、異なる翻訳者が訳した同じ原文に対して、訳文の表現の違いを分析する際に距離が適しています。
このように、類似度と距離はタスクに応じて使い分けられる相補的な指標です。
以降の計算における前提
本記事では、テキスト間の関係性を視覚的にわかりやすく示すため、テキストを表す高次元の埋め込みベクトルをPCA(主成分分析)を用いて2次元に削減した値を使用します。PCAにより、データの分散が大きい方向に基づく特徴を強調し、平面上で直感的に関係性を把握できるようにします。ただし、実際の類似度や距離の計算は、削減されていない元の高次元ベクトルを使用して行うことが一般的です。これは、次元削減によって元のデータの情報が一部失われるためです。特に、埋め込みベクトルは高次元空間での部妙な関係性や特徴を保持しており、次元削減による情報の欠損が類似度や距離の計算結果に影響を与える場合があります。そのため、高次元のまま計算する方が、元データの正確な関係性を反映できます。
検証条件
- ライブラリ
- numpy==1.26.4
- matplotlib==3.9.2
- japanize-matplotlib==1.1.3 # 日本語化のため必要
- scikit-learn==1.5.2
- scipy==1.13.1
- torch==2.5.1
- transformers==4.46.3
単語・文章の関係性の可視化
距離や類似度を活用する場面は多々ありますが、数値で示された結果だけでは直感的に理解しにくいことがあります。そこで今回は、単語や文書のベクトルを用いて、2次元空間上にプロットし、その関係性を視覚的に捉える方法を紹介します。
実装例:単語空間の可視化
以下の手順で単語間の関係をプロットします:
- 単語を埋め込みベクトルで表現
- ベクトルをPCA(主成分分析)で2次元に削減
- プロットを作成
import numpy as np
from sklearn.decomposition import PCA
from scipy.spatial.distance import cosine
from scipy.spatial.distance import euclidean
from transformers import AutoTokenizer, AutoModel
import torch
import matplotlib.pyplot as plt
import japanize_matplotlib
# 埋め込みを計算する関数
def get_embedding(word):
inputs = tokenizer(word, return_tensors="pt", padding=True, truncation=True).to(device)
with torch.no_grad():
outputs = model(**inputs)
# トークンごとの埋め込みの平均を取る
return outputs.last_hidden_state.mean(dim=1).squeeze().cpu().numpy()
# モデルとトークナイザーの読み込み
model_name = "cl-tohoku/bert-base-japanese-v3"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# CPUで実行
device = torch.device("cpu")
model = model.to(device)
# 単語リスト
words = ["海外旅行", "観光", "飛行機", "ホテル", "パスポート", "車", "自転車"]
# 各単語の埋め込みを取得
embeddings = {word: get_embedding(word) for word in words}
# 2次元に削減
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(list(embeddings.values()))
# プロット
fig, ax = plt.subplots(figsize=(8, 8))
# 色の設定(ランダムまたは特定の色を指定)
colors = {"海外旅行": "b", "観光": "g", "飛行機": "r", "ホテル": "c", "パスポート": "m", "車": "y", "自転車": "k"}
# 各単語のベクトルをプロット
for word, coord in zip(words, embeddings_2d):
ax.scatter(coord[0], coord[1], label=word, color=colors[word])
# 原点からその点に向けて破線を引く
ax.plot([0, coord[0]], [0, coord[1]], linestyle='--', color=colors[word], alpha=0.7)
ax.annotate(word, (coord[0], coord[1]), fontsize=12, color='k')
# 軸ラベルの設定
ax.set_xlabel('PCA Dimension 1')
ax.set_ylabel('PCA Dimension 2')
# プロットの表示
ax.legend()
plt.title('単語間の可視化(PCAによる次元削減)')
plt.show()
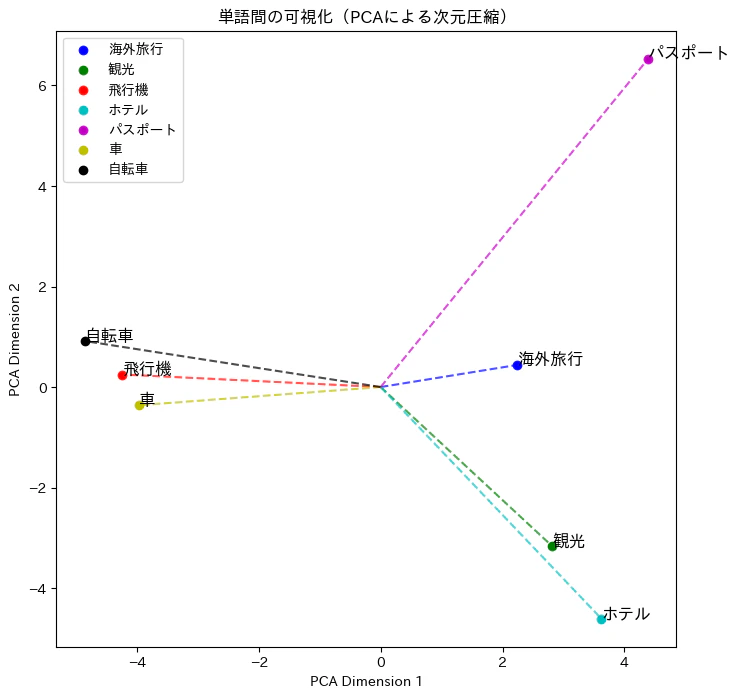
図を見ると、以下のような解釈が得られます。
- 飛行機・車・自転車の類似性
これらのデータポイントは空間的に近く、コサイン類似度も高い結果となりました。これから、「移動手段」という概念で共通点があると解釈できます。 - 飛行機と海外旅行の負の類似性
飛行機と海外旅行は直感的に関連性が高いように思えますが、コサイン類似度は低い結果となりました。この結果は、主成分分析による次元削減の過程で、「移動手段」と「目的地」というような構図が浮かび上がり、それぞれが別の方向性を示したことが原因と考えられます。
このように、次元削減によりデータの関係性が削減され、特定の特徴が強調される一方で他の関係性が埋もれることがあります。そのため、次元削減後の結果を活用する際には注意が必要です。「どのような特徴が強調され、どのような関係が埋もれる可能性があるか」を把握し、目的に応じて適切に結果を補足的に利用することが重要です。
続いて、コサイン類似度とユークリッド距離の違いを図に示してみます。コサイン類似度の高い上位30%、ユークリッド距離の近い上位30%のペアをつなぎ、その他はつながないようにします。
# ユークリッド距離を計算
def calc_distance(embeddings):
cos_similarities, distances = {}, {}
for i, word1 in enumerate(words):
for j, word2 in enumerate(words):
if i < j:
cos_sim = 1 - cosine(embeddings[i], embeddings[j])
dist = euclidean(embeddings[i], embeddings[j])
cos_similarities[(word1, word2)] = cos_sim
distances[(word1, word2)] = dist
return cos_similarities, distances
cos_similarities, euclidean_distances = calc_distance(embeddings_2d)
# 上位30%の閾値を計算
sort_cos_values = sorted(list(cos_similarities.values()), key=float, reverse=True)
cos_threshold_index = int(len(sort_cos_values) * 0.3)
cos_threshold_distance = sort_cos_values[cos_threshold_index - 1] # 30%位置の距離
sort_distances_values = sorted(list(euclidean_distances.values()), key=float)
euc_threshold_index = int(len(sort_distances_values) * 0.3)
euc_threshold_distance = sort_distances_values[euc_threshold_index - 1] # 30%位置の距離
# 色の設定(ランダムまたは特定の色を指定)
ori_colors = {"b", "g", "r", "c", "m", "y", "k"}
colors = dict(zip(words, ori_colors))
# プロット
fig, axes = plt.subplots(1, 2, figsize=(15, 8))
# コサイン類似度のプロット(左)
ax1 = axes[0]
for word, coord in zip(words, embeddings_2d):
ax1.scatter(coord[0], coord[1], label=word, color=colors[word])
ax1.annotate(word, (coord[0], coord[1]), fontsize=12, color='k')
# ユークリッド距離の線(距離が短いペアに線を引く)
for (word1, word2), dist in cos_similarities.items():
if dist > cos_threshold_distance: # 距離が短いペアに線を引く
i = words.index(word1)
j = words.index(word2)
ax1.plot([embeddings_2d[i][0], embeddings_2d[j][0]],
[embeddings_2d[i][1], embeddings_2d[j][1]],
linestyle='-', color='gray', alpha=0.5)
# 距離を表示
mid_point = [(embeddings_2d[i][0] + embeddings_2d[j][0]) / 2,
(embeddings_2d[i][1] + embeddings_2d[j][1]) / 2]
ax1.text(mid_point[0], mid_point[1], f'{dist:.2f}', fontsize=10, color='blue')
ax1.set_xlabel('PCA Dimension 1')
ax1.set_ylabel('PCA Dimension 2')
ax1.set_title('コサイン類似度による可視化')
# ユークリッド距離のプロット(右)
ax2 = axes[1]
for word, coord in zip(words, embeddings_2d):
ax2.scatter(coord[0], coord[1], label=word, color=colors[word])
ax2.annotate(word, (coord[0], coord[1]), fontsize=12, color='k')
# ユークリッド距離の線(距離が短いペアに線を引く)
for (word1, word2), dist in euclidean_distances.items():
if dist < euc_threshold_distance: # 距離が短いペアに線を引く
i = words.index(word1)
j = words.index(word2)
ax2.plot([embeddings_2d[i][0], embeddings_2d[j][0]],
[embeddings_2d[i][1], embeddings_2d[j][1]],
linestyle='-', color='gray', alpha=0.5)
# 距離を表示
mid_point = [(embeddings_2d[i][0] + embeddings_2d[j][0]) / 2,
(embeddings_2d[i][1] + embeddings_2d[j][1]) / 2]
ax2.text(mid_point[0], mid_point[1], f'{dist:.2f}', fontsize=10, color='blue')
ax2.set_xlabel('PCA Dimension 1')
ax2.set_ylabel('PCA Dimension 2')
ax2.set_title('ユークリッド距離による可視化')
# プロットの表示
plt.tight_layout()
plt.show()
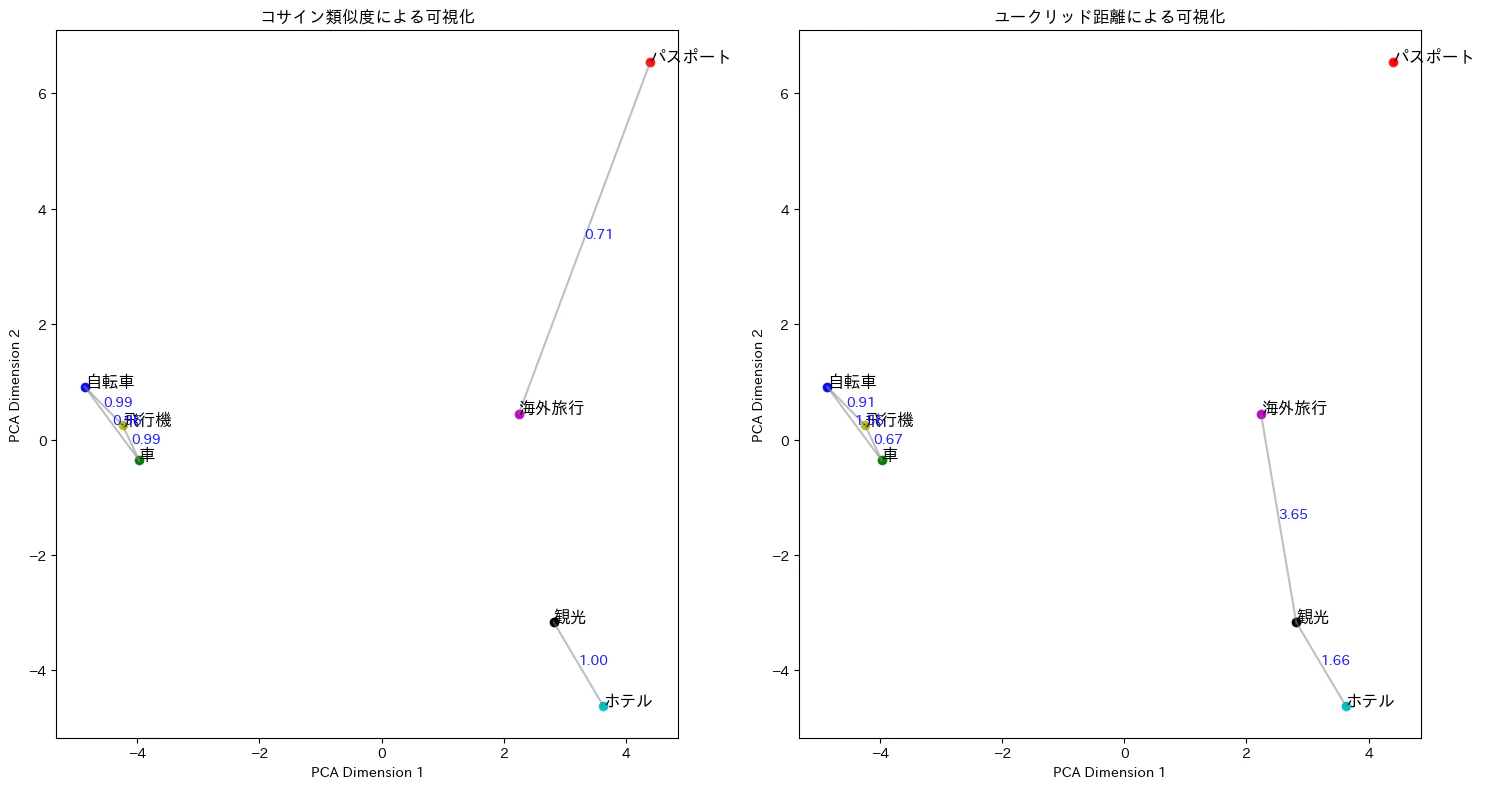
「パスポート」、「海外旅行」、「観光」の3語に着目すると、コサイン類似度が大きいのは「パスポート-海外旅行」ですが、ユークリッド距離が近いのは「観光-海外旅行」です。このように、選ぶ指標によってより似ていると判断されるものは変わります。この結果から実際にあり得るシチュエーションを考えてみます。
- 情報検索のシステムにおいて、検索ワード「海外旅行」に関連する文書を探す際、コサイン類似度を用いることで、意味的に関連の深い単語を含む文書が優先的に表示されます。
- 観光業関連の用語をクラスタリングする場合、ユークリッド距離を使うことで、「観光」、「海外旅行」、「ホテル」などが近くにグループ化され、単語の全体的な分布に基づいたクラスタリングが実現します。
このように、コサイン類似度は文脈や意味的な関係を重視する一方、ユークリッド距離は空間的な分布を基に評価を行います。次元軸に明確な意味がありベクトルの絶対値が重要な場合(例: 単語分布を基にしたクラスタリング)にはユークリッド距離が、方向性や相対位置が重要なタスク(例: レコメンドシステム)ではコサイン類似度が使われることが多いです。データ特性やタスクに応じて適切な指標を選び、必要に応じて両方試すことが有効です。
さいごに
今回は「単語」の類似度・距離に着目し、その代表例である「コサイン類似度」と「ユークリッド距離」を取り上げました。また、具体例を通じて単語間の関係性を可視化し、それらの特徴や違いについて考察しました。
注意点として、関係性の可視化を活用する際には、その過程で行われる次元削減の影響や埋め込みモデルの選択が結果に与える影響も考慮する必要があります。特に次元削減では、元データの情報が一部失われることや、手法ごとの特性によって解釈が異なる可能性があります。一方で、場合によっては次元削減を必要としないケースもあり、タスクやデータに応じた柔軟な判断が求められます。詳しくはこちらをご覧ください。また、本記事で使用した事前学習モデルや可視化・分析手法は一例にすぎません。 他にも多くのモデルや手法が存在し、タスクに応じて適切に選ぶことで深い洞察を得られます。これらのポイントを踏まえ、今後の分析や実践に役立てていただければ幸いです。
最後までお読みいただきありがとうございました。本記事の内容に誤りなどあればコメントにてご教授お願いいたします。
参考
レコメンドシステムではなぜユークリッド距離ではなくコサイン類似度が用いられる?
高次元データの次元削減:理論から実践まで
tohoku-nlp/bert-base-japanese-v3