どうも。引き続き「人間とAIの文章を見分けるコンペ」で頑張っています。前回、LBスコアを0.963に伸ばせたご報告をしてから、着実にスコアを刻んできており、0.967まできました。金メダル圏内の上位0.2%まであと3人というとこに迫ってきています。
当初はメモリオーバーフローやセッション切れの壁に泣かされてきていたものの、いろいろと努力した甲斐あって、スムーズに実験のサイクルが回せるようになってきました。少なくとも、「Submit後のエラーにむせび泣く」といったことは発生していません。とはいえ、元のソースコードの中で、とても重たい処理をする分類器があったので、最終的にはその分類器とはサヨナラして、もっと軽量な複数の分類器に入れ替えてます。副次的な効果として、利用できるデータ量が増えたり、特徴量の種類を増やせたり、実験の安定性が高まったりと、いいことづくめでした。
幸いなことに、ここ数日間は新たな特徴量の作りこみなども必要なく、これまで作った特徴量の組み合わせや、パラメーター調整だけで、スコアをあげてられています。締め切り10日前の追い込み時期にしてはえらく落ち着いた感じです。前日の夜に、翌日Submitする5回分の実験計画を立て、パラメーターを設定してSave&Runさせておくと、夜中のうちに実行が完了します。朝起きて、軽く実行結果を確認して問題なければ、ブラウザでポチポチすればその日のSubmitは完了。昼休み頃に結果が出るので食事しながらちょっと考察。そして、仕事が終わったら、また実験計画を立ててパラメータを設定してSave&Run...の繰り返しです。
「人間とAIの書く文章の違い」について、探索的データ解析をやってみた
開発に余裕が出てきたので、今回のコンペのデータセットに関する探索的データ解析(EDA)も行ってみました。解析結果のノートブックをコンペのページで共有してみたところ、「いいね」にあたるupvoteが5つもらえて、コードの銅メダルも獲得できました。やった~。
最初に着手したのは、データセット間の関係性の解析です。参加直後の記事で書いた通り、このコンペでは主催しているオーガナイザから、ほんのちょっとのデータしか提供されていません。そこで、有志がいろいろとデータセットを構築して共有してくれているのですが、データセットも乱立気味で、どのデータセットがどのデータセットに取り込まれているのかとか、お互いどのくらい重複があるのかなどの情報が、データセットの説明ページを見てもよく分からないことが多いです。そこで、自動的にデータセット間のデータの重複関係を解析し、ダイヤグラムで可視化するプログラムを作成しました。

コンペに参加してない人には「なんのことやら」という図かもしれませんが、これは現在、私が見つけた11のデータセットを結合すると、どれとどれが最終的な結合結果に含まれているか、を可視化した図になります。真ん中の一番上にある「original:1378」というのが、主催者から提供されているオリジナルのデータセットです。で、これだとデータ量が少なくて話にならんので、daigtがclaudeやpalm、persuadeなどからデータを集めてきてデータセットを作っている。とか、falconとかmixtral、mistralといった生成AIのデータはまだ他のデータセットには取り込まれていないので、データ拡張に使えそう...といったことが、この図から読み取れます。最終的に結合されたデータセットとして、約7.5万件を入手できました。
AIの語彙は人間の語彙よりも少ない?
結合されたデータセットを解析していると、面白い発見が一つありました。それは「人間の語彙に比べると、AIの語彙は少ない」ということです。文章中に出てくる単語の種類をカウントすると、下記のグラフのように、AIの文章で使われている単語の種類は、人間に比べて半分以下になっており、著しく少ない傾向があるのが分かります。
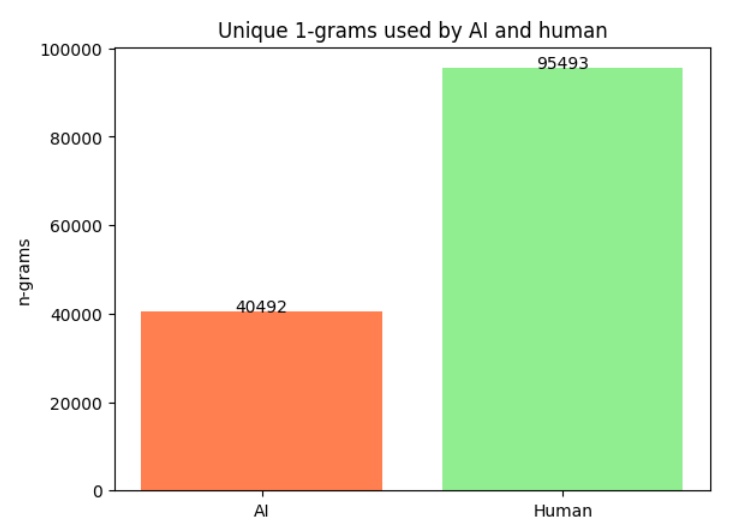
これは、「なるべく生起確率の高い文章になるように語彙を選択する」という、生成AIの性質によるものと思われます。生成AIはいかにも、「誰かが言ってそうなこと」を「誰かが言ってそうな言いまわしで」表現しているということですね。この発見は、人間とAIを見分ける何かのヒントになるかもしれません。どのように特徴量に落とし込むか、といったところでまだ苦戦はしていますが...
上記の語彙の差は、「人間の文章とAIの文章の長さが違うからでは?」と思われた方もいるかもしれませんね。一応確認しておくと、たしかに、文章の長さの分布には下図のように若干ずれがあります。人間の文章の長さについて着目すると、2000文字前後の文章がAIよりも多くなっています。また、人間の文章の長さの方が、ロングテールに分布しています。数は少ないけれど、長文のエッセイが含まれているということですね。

そして、文章長さの分布は上記のようにずれているものの、長さの平均値は、下図の通りほぼ同等となっています。

人間しか使わない語彙には、タイプミスが大量に含まれている
もう一つ、面白い発見がありましたので、シェアしておきます。それは、「人間の文章だけに出現した語彙」と「AIの文章だけに出現した語彙」を比較してみると、「人間の文章だけに出現した語彙」には、タイプミスが大量に含まれている、ということです。下記に、「人間の文章だけに出現した語彙(=人間だけが使った単語)」と「AIの文章だけに出現した語彙(=AIだけが使った単語)」の出現頻度上位の一覧を示します。
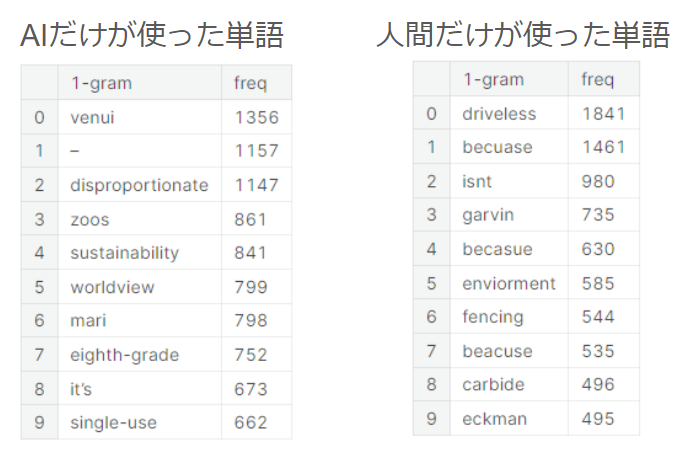
「AIだけが使った単語」の方は理由がちょっとよく分からないものが並んでいますが、「人間だけが使った単語」の方は、明らかにタイプミスや人間独特のくだけた省略表現が原因と思われる表現が集まっていますね。「becuase」や「becasue」「beacuse」は、本来なら「because」のタイプミスでしょう。「driveless」は一応存在する単語ですが、書かれている文脈を見ると「driveless car」になっており、これは「driverless car」のタイプミスと考えられます。「enviorment」は「環境」を意味する「environment」のタイプミスですね。「isnt」は「isn't」でシングルクォーテーションを省略した表現です。ちょっとくだけた感じがするので、生成AIでは明示的に「くだけた表現で書いて」と指示しない限り、書かなさそうな表現です。
「人間は過ちを犯す」
そして、生きている限り繰り返されるタイプミスもその過ちの一つでしょう。それは、「データセット構築のために駆り出され、学校の宿題か何かでエッセイを書かされる学生」だって例外ではありません。実は「タイプミス」こそが、「人間であることの証明」なのかもしれない!
面白かったので、勢いで「人間だけが使った単語」の中から、「タイプミスの可能性の高い単語」を抽出するアルゴリズムを作り、そのタイプミスを基準に人間かAIかを分類するコードを作成しました。SubmitしてLBスコアもゲットして、満を持してシェアしようとしていたのですが...ちょっとした操作ミスで、ノートブックもろとも削除してしまいました。解説文も英語で気合入れて書いていたのに。。。

まあ、「そんな他人のタイプミスなんかに気を取られていないで、しっかり本命のアルゴリズムをきっちりやりなさい」という神様からのメッセージだと受け取って、残り10日間、気を取り直してがんばります。