どうも、fripSideは南條さんよりnaoさん派
白金御行<プラチナ☆みゆき>です。

ところで、皆さん好きな曲ってどうやって見つけていますか?
簡単に思いつくのは、
- 好きなアーティストの過去の曲を調べる
- 同じゲームやアニメの収録曲を調べる
くらいかと思いますが、これでは偶発的な発見が期待できませんね。
好きなアーティストや、好きなゲームがすでに存在していないといけないですし、新しい発見も好きなアーティストやゲーム内に閉じてしまいます。
そこで今回は偶発的な発見に有効なリコメンドシステムについて書いていこうかと思います。
AmazonやYoutubeなどがおすすめ欄に搭載しているアレですね。
アニメや書籍のリコメンドシステムを作った人はいくらでもいると思いますが、過去にエ□ゲソングのリコメンドシステムを作った人がいたでしょうか。
今宵、第一人者の扉を叩きたいと思いますので、お時間の許す方は是非お付き合いください。
※本記事は前回記事の続編となりますが、本記事だけでもお楽しみいただけます。
目次
- データの収集
- リコメンドシステムの構築
- エ□ゲソングをリコメンドさせて遊ぶ
使用技術
言語: Python3
データ処理ライブラリ: pandas
機械学習ライブラリ: scikit-learn
開発環境: VS Code, Jupyter Notebook
1. データの収集
お馴染みエ□ゲー批評空間のSQL実行フォームから、エ□ゲソングのデータとユーザ評価のデータを取得していきます。
まずは音楽データから取得していきましょう。
SELECT id as music_id, name as music_name
FROM musiclist;
有効なデータは全部で15180件でした。
エ□ゲソングって、批評空間に登録されてるだけでも15000曲以上もあるんですね。まったく、ジャパンは最高だぜっ!
取得したデータは以下のような形式になっています。
このデータをなにかに保存したいのですが、今回はお手軽にcsv形式で保存していきたいと思います。
id name
7783 琥珀の祈り
3727 Déjà vu
33 バトルできゅんっ!なキングダム☆
さて、上記のようなデータをいったんVS Codeでテキスト形式でコピペし、テキストからcsvに変換するようなコードを書いていきたいと思います。
import re
# テキストファイルをutf-8形式で読み取り
with open('musics.txt', 'r', encoding='utf-8') as rf:
d = rf.read()
# id, name間のタブをカンマに変換。nameの前後に""を設置
re_d = re.sub('\t', ',"', d)
re_d = re.sub('\n', '"\n', re_d)
# カンマ加工したデータをcsvとして保存
with open('musics.csv', 'a', encoding='utf_8_sig') as wf:
wf.write('\n')
wf.write(re_d)
処理内容ですが、データのidとnameの間にタブがあるので、それをカンマに置換してnameの前後を""で囲みました。
""で囲む処理が何故必要かというと、楽曲名が「no rain, no rainbow」のようにカンマを含むものが勝手に改行されてしまうのを防止するためですね。
さて、それでは続いてユーザ評価データを取得していきましょう。
SELECT music, uid,
CASE
WHEN tokuten = 200 THEN 10
WHEN tokuten = 150 THEN 9
WHEN tokuten = 120 THEN 8
WHEN tokuten = 100 THEN 7
WHEN tokuten = 95 THEN 6
WHEN tokuten = 90 THEN 5
WHEN tokuten = 85 THEN 4
WHEN tokuten = 80 THEN 3
WHEN tokuten = 75 THEN 2
WHEN tokuten = 70 THEN 1
ELSE tokuten
END
FROM usermusic_tokuten
-- OFFSET 10000
LIMIT 10000;
批評空間の得点データは少し特殊な構造をしていて得点を[70, 75, 80, 85, 90, 95, 100, 120, 150, 200]から付けることができるようになっています。
なので、上記コードのように70 = 1, 200 = 10となるようにマッピングしました。
もともと、数値型なのでマッピングに拘る必要はないかもしれませんが、データサイエンスの慣習的に一応。
sqlをoffsetを変えて80000件ほどのデータを取得しました。
結果、ユーザ評価データは以下のようなものが79609件得られました。
music uid tokuten
14762 scycsw09 7
14158 scycsw09 9
14876 scycsw09 10
では、こちらもcsv形式に変換していきます。
テキストファイルは8ファイルに分けて格納してあるので、8つのテキストファイルを1つのcsvファイルにまとめる操作になっています。
import re
for i in range(1,9):
with open('row_data/ratings_'+str(i)+'.txt', 'r', encoding='utf-8') as rf:
d = rf.read()
re_d = re.sub('\t', ',', d)
with open('ratings.csv', 'a', encoding='utf_8_sig') as wf:
wf.write('\n')
wf.write(re_d)
2. リコメンドシステムの構築
さて、データが用意できたところで早速リコメンドシステムを構築していきましょう。
今回、機械学習アルゴリズムとしては**k nearest neighbor(knn)**と呼ばれるものを使っていきます。
knnというのは、あるデータがどのクラスに帰属するかというのを多数決で決めるアルゴリズムとなっています。
イメージで言うと、下図のようになります。
下図はk = 4で結局赤のクラスか青のクラスか決まっていない残念な図となっております。なので、一般的にはk = odd(奇数)に設定しますね。
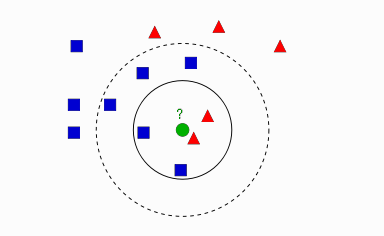
knnに関して詳しく知りたい方は、OpenCVのドキュメントが分かりやすかったので是非。
ここからの処理ですが、データサイエンス的なものになっていきますので、私はJupyter Notebookを使っています。
開発環境はなんでも良いと思いますがデータ処理系の環境で試されることをオススメいたします。
さて、では作成したcsvのデータをpandasで処理していきます。
まずは、データを読み込みましょう。
import pandas as pd
ratings = pd.read_csv('./data/ratings.csv')
musics = pd.read_csv('./data/musics.csv', engine='python', encoding='utf_8_sig', sep=',', quotechar='"', error_bad_lines=False)
次に、問題なくデータが読み込まれているかユーザ評価データ、楽曲データに対して見ていきます。
ratings.head()
musics.head()
music uid score
0 155 ahoudori 9
1 377 ahoudori 9
2 572 熊谷 10
3 550 熊谷 10
4 157 熊谷 9
music_id music_name
0 7783 琥珀の祈り
1 3727 Déjà vu
2 33 バトルできゅんっ!なキングダム☆
3 32 Jumping Star
4 34 キラキラ☆恋ゴコロ
問題なく読み込めていそうですね。
では、各データのオーダーを確認していきましょう。
ratings.info()
musics.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 79609 entries, 0 to 79608
Data columns (total 3 columns):
music 79609 non-null int64
uid 79609 non-null object
tokuten 79609 non-null int64
dtypes: int64(2), object(1)
memory usage: 1.8+ MB
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 15181 entries, 0 to 15180
Data columns (total 2 columns):
music_id 15181 non-null int64
music_name 15180 non-null object
dtypes: int64(1), object(1)
memory usage: 237.3+ KB
ユーザ評価データが79609件で、楽曲データが15180件ですね。
今回のデータは欠損値も外れ値もなく、得点も1 - 10の整数値にスケーリングしているので特に前処理は行いません。
では次に、ユーザ評価データを可視化していきましょう。
ratings['score'].hist(bins=10, figsize=(10,10))
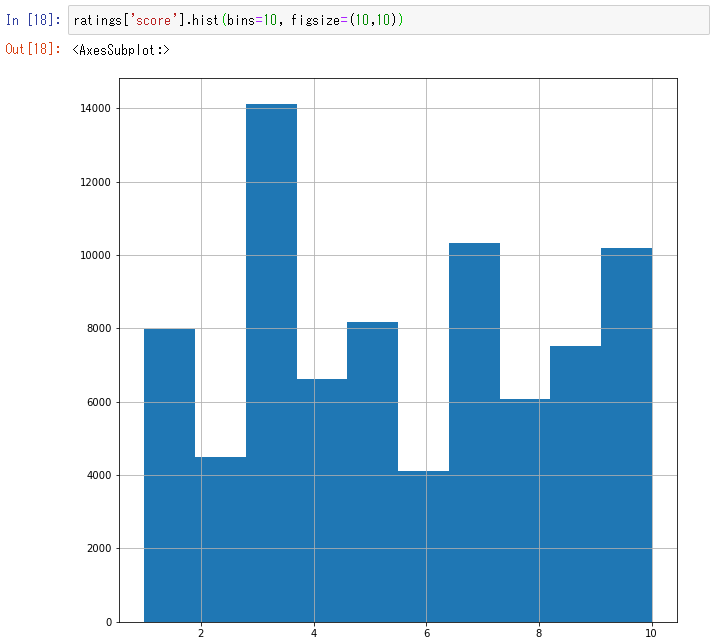
得点の分布をヒストグラムで可視化したものが上図となります。
3点、つまり、元の点数に80点を付けた人が多いことがわかりますね。
それでは、データを結合していきましょう。
# music_idをキーにしてマージ
merged_df = ratings.merge(musics, left_on='music', right_on='music_id', suffixes=['_user', ''])
merged_df.head()
music uid score music_id music_name
0 155 ahoudori 9 155 Glorious Days
1 155 aiko1122 6 155 Glorious Days
2 155 ihave 3 155 Glorious Days
3 155 selfeena 8 155 Glorious Days
4 155 twinklestar_act2 5 155 Glorious Days
今回作るリコメンドシステムに必要な特徴量(カラム)を抽出していきます。ユーザ名と楽曲名、得点が分かれば良いですね。
# 学習に用いる特徴量を抽出
merged_df = merged_df[['uid', 'music_name', 'score']]
# 重複を削除
merged_df = merged_df.drop_duplicates(['uid', 'music_name'])
merged_df.head()
uid music_name score
0 ahoudori Glorious Days 9
1 aiko1122 Glorious Days 6
2 ihave Glorious Days 3
3 selfeena Glorious Days 8
4 twinklestar_act2 Glorious Days 5
ここで、機械学習に必要なライブラリをimportします。
# import Machine-Learning library
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
そして、全てのユーザ、全てのゲームソングに対して得点をマッピングしていきます。得点をつけていない楽曲に対しては0が付与されるので、自然にほとんど0の行列が生成されます。この行列のことを疎な行列ということで、スパース行列と呼んだりします。
# ゲーソンを軸にグルーピング
musics_pivot = merged_df.pivot(index='music_name', columns='uid', values='score').fillna(0)
musics_pivot_sparse = csr_matrix(musics_pivot.values)
musics_pivot.head()
uid 00999 01040228 0321445 0495ex 050325 0504 0824064 09848754 0987643 0rdinary ... 霧雨 響季 騎羅大和 魔中年 鳳 黄昏の統括者 (光)エロゲの罪 (^p^) c1095161 ktm715
name
NaN 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
(I will) be with you 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
(^3^)chu☆でれ☆らぷそでぃ 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
(a)SLOW STAR 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 9.0 0.0 0.0 0.0 0.0
*bloom* 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 ... 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
得られたスパース行列に対して、k = 9でknnを実装し、モデルを訓練させていきます。
# k=9, 距離=コサイン類似度でknnインスタンスを作成
knn = NearestNeighbors(n_neighbors=9, algorithm='brute', metric='cosine')
# モデルを訓練
model_knn = knn.fit(musics_pivot_sparse)
では、最後に引数に入れたエ□ゲソングに似たエ□ゲソングを返す関数を作成します。
引数に入れるゲーソンから類似する順に10個のゲーソンを返す
def music_recommend(music):
distance, indice = model_knn.kneighbors(musics_pivot.iloc[musics_pivot.index == music].values.reshape(1,-1),n_neighbors=11)
for i in range(0, len(distance.flatten())):
if i == 0:
print('Recommendations if you like the music {0}:\n'.format(musics_pivot[musics_pivot.index== music].index[0]))
else:
print('{0}: {1} with distance: {2}'.format(i,musics_pivot.index[indice.flatten()[i]],distance.flatten()[i]))
これにて、完成です!
では、実際に使っていきましょう!!
3. エ□ゲソングをリコメンドさせて遊ぶ
冒頭にもありました通り私はfripSideは南條さんよりnaoさん派です(勿論、南條なんも大好きですが)
ということで、最初の楽曲はnaoの**「ツクモノツキ」**としましょう。
music_recommend('ツクモノツキ')
Recommendations if you like the music ツクモノツキ:
1: 永遠なる絆と想いのキセキ with distance: 0.4043812050860093
2: 4SEASONs with distance: 0.4268013986276725
3: Beautiful Harmony with distance: 0.4751978478152129
4: ANGELIC DESTINY with distance: 0.4781220299313246
5: sword of virgin with distance: 0.4840186802736701
6: 恋のレシピ with distance: 0.4861049944667929
7: 星空へ架かる橋 with distance: 0.4863100112682016
8: Focus love with distance: 0.4980975532021864
9: 茜色の奇跡 with distance: 0.4987228118840149
10: 恋する姉妹☆ラ☆六重奏 with distance: 0.5115867098284432
結果はこんな感じでした。1番の「永遠なる絆と想いのキセキ」はnaoさんの曲ですが、2位や7位は星空へ架かる橋の楽曲だったり、5位の「sword of virgin」は同じfripSideでも南條さんの曲だったりと、良い感じに"近い"曲が推薦されていますね。
じゃあ、まあ、有名すぎて知らない人なんていないとは思いますが、今回はこちらを聴いていただきましょう。
それでは、聴いてください。
星空へ架かる橋OPで**「星空へ架かる橋」**
さて、のみこさんの歌声で存分に癒されたところで次にいきましょう。
まあ、エ□ゲといえばゆずソフトですよね(?)
ということで、次は榊原ゆいさんの「Scarlet」で探索してみましょう。
music_recommend('Scarlet')
Recommendations if you like the music Scarlet:
1: 君だけの僕 with distance: 0.45976596484984467
2: Blue-Love Chime with distance: 0.5462507645500085
3: Change&Chance! with distance: 0.5860762222757152
4: 恋せよ乙女! with distance: 0.6020481963152964
5: 天色 with distance: 0.625171537496535
6: Be Ambitious,Guys! with distance: 0.6426514430199537
7: メチャ恋らんまん☆ with distance: 0.6434559775309062
8: Floating up with distance: 0.6451025055674662
9: 幻想の城 with distance: 0.6475571285044504
10: やがて消える幻でも with distance: 0.6499461353139242
はい、出ました!
同じくゆずソフトの曲が多いですが、橋本みゆきさんの「Be Ambitious,Guys!」やKOTOKOさんの「Floating up」が見受けられますね。
まあ、でも、
この中だったらこれを聴いてもらうしかないでしょう。
それでは、聴いてください。
天色*アイルノーツEDで**「天色」**
いやー、やっぱり桐谷華なんだよなぁ~という声が聞こえてきそうですね(???)
おわりに
さて、初心者向けの機械学習記事と見せかけた巧妙なエ□ゲソング布教記事だったわけですが、いかがだったでしょうか?
Kaggleや競技プログラミングに辟易したエンジニアの皆さま、是非エ□ゲソングで一休みしていってください。
Data
今回用いたdataはこちらにありますので、気になった方はご自由にお使いください。