新年明けましておめでとうございます。
アドベントカレンダー2020が終わって1週間と少し、暦も変わってしまったことでもう誰もアドベントカレンダーを見ないかもしれませんが、過去のアドベントカレンダーと照らし合わせてトレンドの変遷を見ていきましょう。
やったこと
- 2015年から始まった過去6年間分のアドベントカレンダーを取得してカレンダーごとにcsv化
- トレンド技術の変遷を見る
結果
表1.プログラミング言語
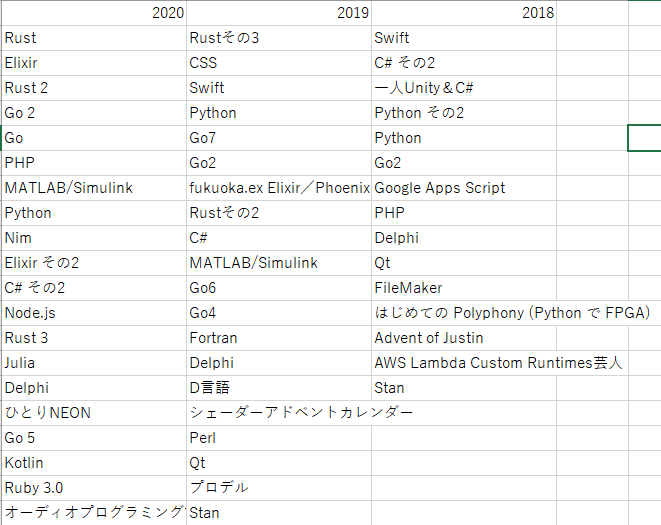
2019年からRustが人気のようですね。Goで開発している企業も増えてきているのか着々と人気が上がっていますね。MATLABやPythonなどのデータ解析系の言語も依然人気です。
表2.ライブラリ
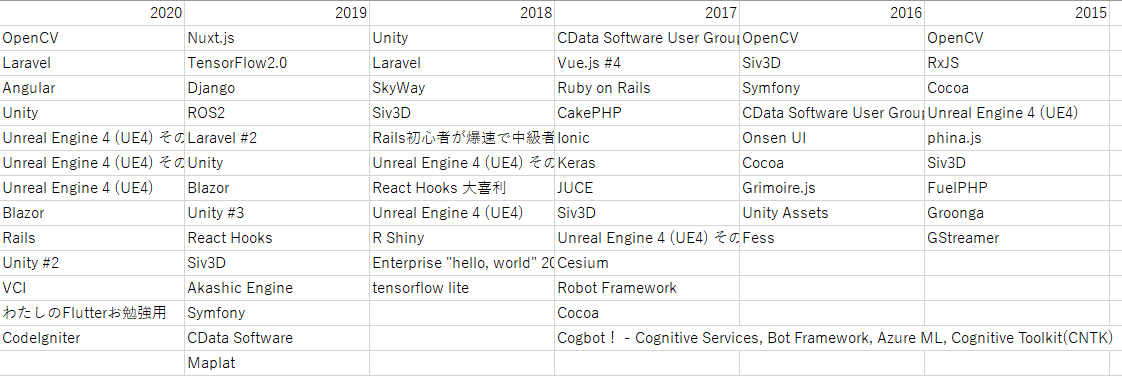
言語フレームワークではLaravelが人気ですね。あと、2020年はUnityやUnreal EngineのようなVRエンジンが人気でした。雑な言い方をしますが、プラットフォームがモバイルからVRに移行する日も近いかもしれませんね。
表3.データベース
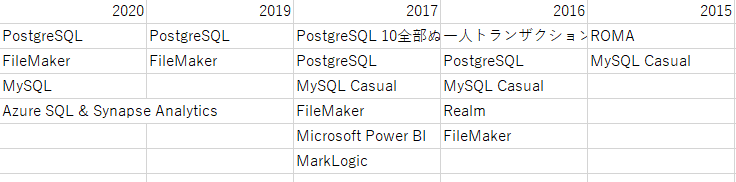
相変わらずPostgreSQLが人気のようです。NoSQL系の記事が入っても良いような気がするんですけどね。
表4.モバイル

クロスプラットフォーム開発で、GoogleのFlutter、FacebookのReact Nativeが人気ですね。GoogleのFirebase等と組み合わせてモバイルアプリ開発は更に簡便化していくでしょう。
表5.DevOps

CI/CDツールでCircle CI、Infrastructure as CodeでAnsibleやTerraform、Kubernetesが人気ですね。インフラ界隈ではDockerでコンテナ化してGitHubでブランチ管理してCIで自動化してみたいなのが定型化している証左でしょうか。
おわりに
Qiitaのアドベントカレンダーを振り返ることで、今年のトレンドもなんとなく予想できてくるのではないでしょうか。
個人的に2021年は、VR開発環境が劇的に向上し、モバイルアプリ開発が更に活性化した後飽和し、環境の自動化が進むことでインフラエンジニアの需要が上がるんじゃないかと推察します。
技術は流行り廃りが激しいので、これからも定点観測していきたいですね。
Code
import requests
import pandas as pd
import numpy as np
from tqdm import tqdm
from bs4 import BeautifulSoup as bs
year = '2020'
url = 'https://qiita.com/advent-calendar/'+year+'/ranking/'
feed = 'feedbacks/categories/'
keyword_list = ['feedbacks', feed+'programming_languages', feed+'libraries', feed+'databases', feed+'web_technologies', feed+'mobile', feed+'devops', feed+'iot', feed+'os', feed+'editors', feed+'academic', feed+'services', feed+'company', feed+'miscellaneous']
columns_list = ['feedbacks', 'programming_languages', 'libraries', 'databases', 'web_technologies', 'mobile', 'devops', 'iot', 'os', 'editors', 'academic', 'services', 'company', 'miscellaneous']
def get_item_name(keyword):
key_url = url+keyword
res = requests.get(key_url)
if res.status_code == 200:
soup = bs(res.text, 'html.parser')
items = soup.find_all('a', class_='ad-Item_name')
else:
pass
for item in items:
items_list.append(item.text)
return items_list
df_list = []
for keyword in keyword_list:
items_list = []
items_list = get_item_name(keyword)
df_items = pd.DataFrame(items_list)
df_list.append(df_items)
np_list = np.arange(1, 21)
np_list = list(np_list)
df = pd.DataFrame(np_list)
for i in range(len(df_list)):
df[columns_list[i]] = df_list[i]
df.to_csv('ad_cal/'+year+'.csv', encoding='utf-16', index=False, sep='\t')
import pandas as pd
years = ['2020', '2019', '2018', '2017', '2016', '2015']
columns_list = ['feedbacks', 'programming_languages', 'libraries', 'databases', 'web_technologies', 'mobile', 'devops', 'iot', 'os', 'editors', 'academic', 'services', 'company', 'miscellaneous']
for column in columns_list:
dic_year = {}
for year in years:
df = pd.read_csv('ad_cal/'+year+'.csv', encoding='utf-16', sep='\t')
try:
df = df[column]
dic_year[year] = df
except:
continue
df_cat = pd.DataFrame.from_dict(dic_year)
df_cat.to_csv('ad_cal/'+column+'.csv', encoding='utf-16', sep='\t', index=False)