Elasticsearchはデフォルトで文字列を要素解析して格納する。
例えば、URL情報を格納するケースでURL文字列が要素解析されてしまうと正しく集計できないため、
通常は要素解析されないよう"not_analyzed"を指定することが多いと思われる。
一方で、"not_analyzed"とした場合、KibanaでVisualizeする時にURLに含まれる
特定の文字列で部分一致検索が上手く効かなくなる事象が確認されている。
そこで、URL文字列をそのままの状態で正しく集計をしつつ、部分一致検索も出来るよう、
"not_analyzed"と"analyzed"の2つのフィールドをElasticsearchに格納する手法を紹介する。
動作を確認したバージョン
- Elasticsearch: 2.3.2
- Logstash: 2.2.2
- Kibana: 4.5.0
やり方
下記の様なテンプレートを用意してElasticsearchに対してPUTする。
PUT _template/sample
{
"template": "sample-*",
"mappings": {
"_default_": {
"properties": {
"hoge": {
...
}
"url": {
"type": "string",
"fields" : {
"raw" : {
"type" : "string",
"index" : "not_analyzed"
}
}
},
"fuga": {
...
}
}
}
}
}
上記のテンプレートを適用すると、下記2つのフィールドがindexに作られる。
- "analyzed"である"url"
- "not_analyzed"である"url.raw"
注意点
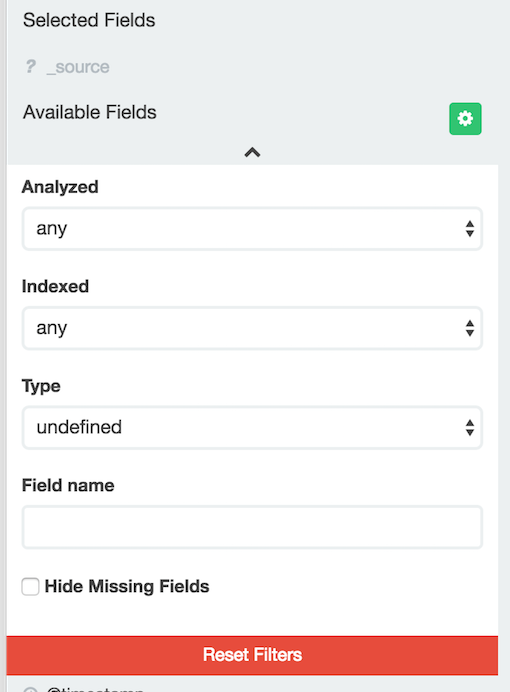
"not_analyzed"である"url.raw"は隠しフィールドであり、
KibanaのDiscoverメニューからindex選択しても表示されない。
下図の"Hide Missing Fields"チェックボックスのチェックを外し、
隠しフィールドを表示するよう変更を行う必要がある。