はじめに
この記事は、シリーズ作です。
今回は、概要編で少しだけ触れたData Layerについての項目を要約していきます。
Data Layer編はかなり長いので、要約の意義が出てきますね。
分量を 1 / 3 くらいにすぼめています。
目次
- Data Layerとは?
- データの公開
- ビジネスロジックの複雑化
- 信頼できる情報源
- スレッド
- インスタンスのライフサイクル
- 良いビジネルモデル
- いろいろなビジネルロジック
- エラーの公開
- 実例
Data Layerとは?
概要編にまとめてあります。
データの公開
データやデータ操作の機能を公開する時は
- suspend関数を用いる
- 時間経過に伴うデータ変更に関しては、Flow(推奨)で購読する
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
ビジネスロジックの複雑化
下記図式では、データ操作において様々なソースが必要なものは、情報源の一元化させてもの達をさらに一元化させていく例です。
また、ログインやユーザー登録などのそれぞれの責務においてカプセル化も実現しています。
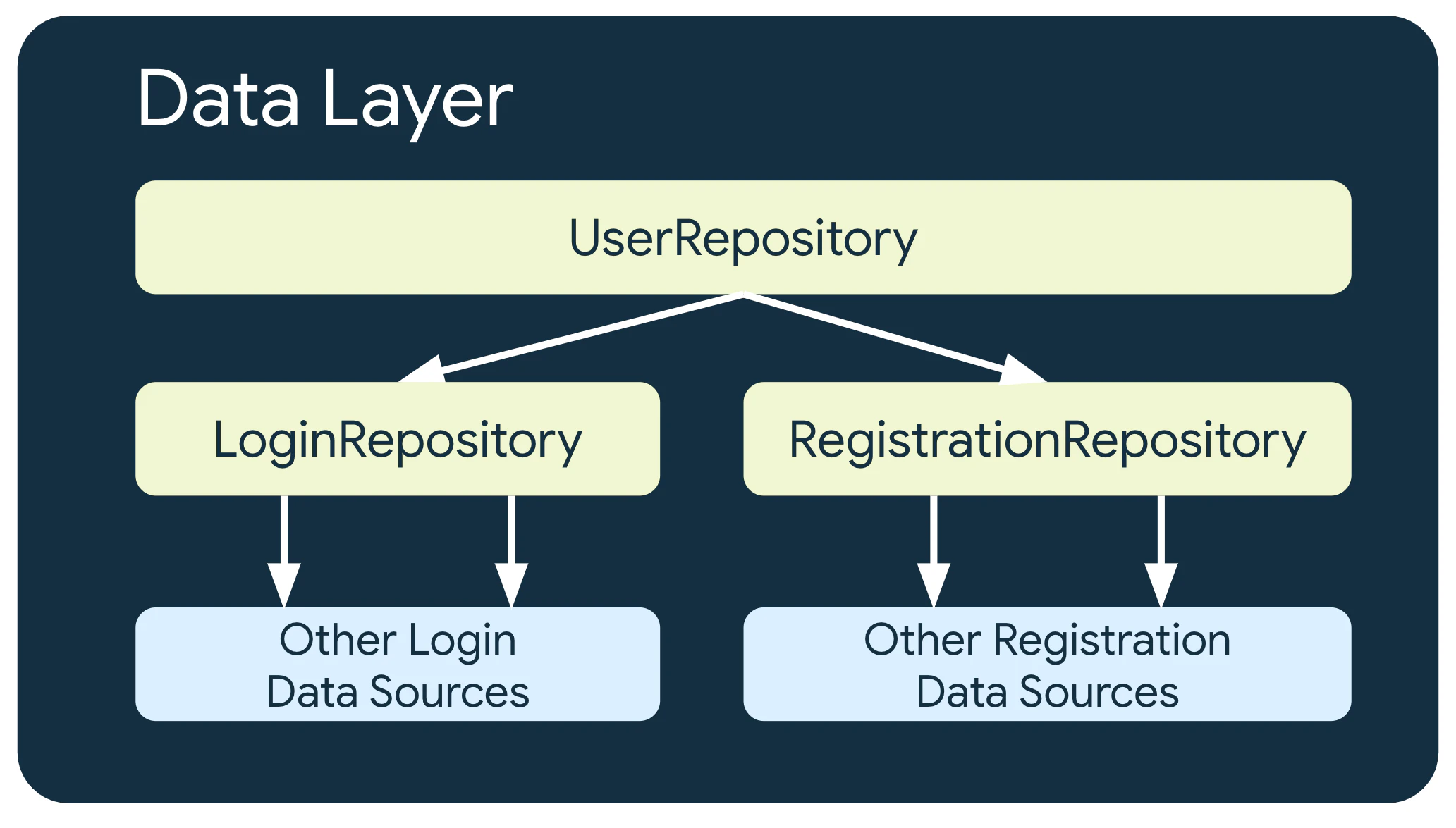
信頼できるデータソースの条件
UI LayerがRepositoryから引っ張ってくるデータは、アプリの唯一の情報源であるため、信頼のおけるものである必要があります。
信頼できるデータソースがローカルDB等のキャッシュや通信処理によるデータなど、異なる場合もありますが、重要なのは、
- データの不変性
- 出来る限り最新であること
スレッド
メインスレッドは、適切なスレッドに移動させる責務があります。
そのため、Repositoryの呼び出しはsuspend関数にてメインスレッドで行うのがベストです。
インスタンスのライフサイクル
ローカルDBクラスが保持しているキャッシュをどのスコープで、生存させるかは重要です。
良いビジネスモデル
ビジネスモデルとは、データ操作で使われる型ですね。
Google的、理想のビジネスモデルは「サブセット(一部)」であるとのことです。
the data layer might be a subset of the information that you get from the different data sources
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
例えば、こちらはニュースアプリで必要なデータ。
しかし、これは網羅的なもので「サブセット」ではありません。
ニュースアプリにおいて、削除したい場面ではこのようなビジネスモデルが好ましいです。
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
メリット
- メモリの節約につながる
- アプリで使用される形に適合できる(?)
- 関心の分離が向上
いろいろなデータ操作
Data Layerで行われるデータ操作のパターンを具体的に見ていきます。
UI指向
特定の画面を表示している間に行われるもの。
ライフサイクルをViewModelに合わせます。
アプリ指向
アプリを開いている間に行われるもの。
例)キャッシュデータ
ライフサイクルをApplicatoinクラスやData Layerのクラス(Reposiotoryなど)に合わせます。
ビジネス指向
保存や更新などのデータ操作。
例)アップロード処理
この処理は、必ず遂行する必要があります。
WorkManager の使用を推奨しています。
エラーも公開する
Data Layerは純粋にデータを他の責務に公開する役割がありますが、エラーを公開するという責務も持ちます。
Kotlinがサポートしているエラー処理機構を使用します。
例)Coroutine exception handling / Flow catch
実践してみる
データソースの定義
ポイント
- ディスク操作やネットワーク IOに最適化されたスレッドで処理する(メインセーフ)
-
interfaceを用いることで、可変性高める
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
Repositoryの定義
ポイント
- 追加ロジックなし
- データソースとViewModelの仲介役として機能する
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
キャッシュの実装
先程のアプリ指向による実装です。
ポイント
- 2回目以降のリクエストは、キャッシュデータを用いる
- キャッシュデータの保存期間や方法はさまざま
-
Mutexで他のスレッドから保護
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
画面 < 操作!?(アプリ指向)
Repositoryのロジックが、呼び出し元のCoroutineScopeを使用している場合、ネットワークリクエスト中にアプリが閉じられたり、他のアプリに移ったりすると中断されてしまいます。
そのため、CoroutineScopeは、呼び出し先のRepositoryクラスのライフサイクルと同期させる必要があります。
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
ディスク操作
ニュースアプリの例だと、ブックマークされた記事やユーザー設定のデータを保存するとき、プロセスの停止を乗り越えて、オフライン実行できるためにディスクに保存する必要が出てきます。
- 大規模なデータセットには、
Room - 更新不要な小規模なデータセットには、
DataStore - JSONのようなデータの集合体には、ファイル
その際に、データソースはデータがどのように保存されているのかの内部事情を知ってはいけません(関心の分離)
ビジネス指向のデータ操作
前述した通り、ビジネス指向のデータ操作は、必ず遂行される必要があるのでWorkManagerを使用します。
下記は、最新のニュース記事を取得する操作をスケジューリングしています。
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
ポイント
- 個別のデータソースに切り分ける
- 条件が満たされた時に実行が始まるようにする
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
おわりに
いかがだったでしょうか?
次回は、Domain Layerについて要約します。
参考