はじめに
今回はpandasの使い方をまとめていきます。
pandasについては多くの人が使い方をまとめているので、特に目新しいことはないかもしれませんがお付き合い頂ければ幸いです。
前回の記事でnumpyの使い方についてまとめているので、よろしければご確認ください。
Seriesの生成
以下のようにすればSeriesを生成できます。Seriesは配列にindexがついた形になります。
import numpy as np
import pandas as pd
series = pd.Series(data=[1, 2, 3, 4, 5], index=['A', 'B', 'C', 'D', 'E'])
print(series)
A 1
B 2
C 3
D 4
E 5
dtype: int64
numpyと組み合わせて生成することもできます。
series = pd.Series(data=np.arange(5), index=['A', 'B', 'C', 'D', 'E'])
print(series)
A 0
B 1
C 2
D 3
E 4
dtype: int64
Seriesからデータを抽出
Seriesはインデックス指定してデータを取り出すことができます。辞書型に近いですね。
series = pd.Series(data=np.arange(5), index=['A', 'B', 'C', 'D', 'E'])
print(series['A'])
0
スライスを用いることもできます。
series = pd.Series(data=np.arange(5), index=['A', 'B', 'C', 'D', 'E'])
print(series['A':'D'])
A 0
B 1
C 2
D 3
dtype: int64
通常のスライスの感覚では、Dの一つ前のCまでのデータが抽出されるはずなんですが、Seriesの場合はインデックスで指定した範囲まで抽出されています。
locを用いて
しかし、このようにインデックスを指定してデータを取り出すときは、慣習的にlocメソッドが用いられます。
series = pd.Series(data=np.arange(5), index=['A', 'B', 'C', 'D', 'E'])
print(series.loc['A':'D'])
A 0
B 1
C 2
D 3
dtype: int64
スライスを用いずに、インデックスを二つ指定することができます。
series = pd.Series(data=np.arange(5), index=['A', 'B', 'C', 'D', 'E'])
print(series.loc[['A', 'D']])
A 0
D 3
dtype: int64
ilocを用いて
Seriesのindexを用いるのではなく、頭から割り振られる数字のインデックスを指定して取り出すこともできます。
series = pd.Series(data=np.arange(5), index=['A', 'B', 'C', 'D', 'E'])
print(series.iloc[[0]])
A 0
dtype: int64
DataFrameの生成
以下のようにすればDataFrameが生成できます。
df = pd.DataFrame(data=[[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['A', 'B', 'C'], columns=['A1', 'A2', 'A3'])
print(df)
A1 A2 A3
A 1 2 3
B 4 5 6
C 7 8 9
このように、DataFrameはindexとcolumnsを指定した二次元のデータになっています。
機械学習で用いるときは、indexはデータの種類を、columnsはデータの特徴量について表しています。
ファイルの読み込み
基本的にpandasはファイルを読みこんで使用するので、この作業は非常によく行います。
ここでは、自分が適当に作ったcsvファイルを読みこみます。以下のデータです。
 読みこんでみましょう。
読みこんでみましょう。
df = pd.read_csv('train.csv')
print(df)
以下が実行結果です。

コピペしても見えにくかったのでスクショしました。
takashやkentaをインデックスにしたかったのですが、デフォルトではインデックスになっていません。
このように、インデックスがあるデータを読みこむときには、index_colで指定する必要があります。この例では、一番左のデータをインデックスとして扱うので、index_col = 0とします。
df = pd.read_csv('train.csv', index_col=0)
print(df)

また、デフォルトでは一番最初の行がヘッダーとして扱われています。一番最初の行をヘッダーとして指定しない場合にはheader = Noneを指定しましょう。
df = pd.read_csv('train.csv', header=None)
print(df)

データの内容の確認
形状を確認
データの形状を確認しましょう。numpyなどと同じく、shape変数に次元のデータが格納されています。
df = pd.read_csv('train.csv', index_col=0)
print(df.shape)
(3, 3)
統計量の確認`
describeメソッドを用いれば、データの統計量を確認できます。
df = pd.read_csv('train.csv', index_col=0)
print(df.describe())

このように、各々のcolumnsに対してデータの数、平均、標準偏差、最小値、最大値、四分位数を得ることができます。
データの数と型を確認
以下のコードで確認できます。
df = pd.read_csv('train.csv', index_col=0)
print(df.info())
<class 'pandas.core.frame.DataFrame'>
Index: 3 entries, takash to yoko
Data columns (total 3 columns):
math 3 non-null int64
Engrish 3 non-null int64
society 3 non-null int64
dtypes: int64(3)
memory usage: 96.0+ bytes
None
こんな感じのデータが確認できます。解説は不要ですね。
重複を除いたデータの確認
nuniqueメソッドを用いれば、書くcolumnsごとの重複を除いたデータを確認できます。
df = pd.read_csv('train.csv', index_col=0)
print(df.nunique())
>math 3
Engrish 3
society 3
dtype: int64
今回は重複が一つもないので、以上のような結果になりました。
行名、列名の確認
index変数にインデックスが、columns変数に列名が格納されています。確認してみましょう。
df = pd.read_csv('train.csv', index_col=0)
print(df.index)
print(df.columns)
Index(['takash', 'kenta', 'yoko'], dtype='object')
Index(['math', 'Engrish', 'society'], dtype='object')
欠損値の合計を確認
以下のコードで、各々のcolumnsにおける欠損値の場所を確認できます。
df = pd.read_csv('train.csv', index_col=0)
print(df.isnull())
math Engrish society
takash False False False
kenta False False False
yoko False False False
それぞれの値は欠損値ではないのでFalseが返ってきます。
それでは、次のコードで欠損値の合計を取得しましょう。
df = pd.read_csv('train.csv', index_col=0)
print(df.isnull().sum())
math 0
Engrish 0
society 0
dtype: int64
DataFrameのデータの選択と抽出
それでは、DataFrameからデータを抽出していきましょう。とりあえず、以下のDataFrameを生成しました。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
print(df)

np.random.seed(0)により、np.random.randで生成する乱数を固定することができます。しかし、自分は毎回コードを実行するので、乱数は毎回変更されています。
np.random.randは0から1までの乱数を生成するコードです。
以下のコードでcolumunsを選択して抽出してみましょう。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
print(df['A1'])
A 0.165899
B 0.144862
C 0.974517
D 0.144633
E 0.806085
Name: A1, dtype: float64
このように、columnsを抽出することができました。
locメソッドを用いるとインデックスを指定して抽出することができます。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
print(df.loc['A'])
A1 0.687867
A2 0.243104
A3 0.568371
A4 0.125892
A5 0.749777
Name: A, dtype: float64
インデックスを指定して抽出と書きましたが、DataFrameにおけるlocメソッドでの指定方法はnumpyの二次元配列の指定にかなり近いです。
loc[行:列]と指定することができます。
以下で使い方をみていきましょう。
print(df.loc[:, 'A1'])
A 0.108650
B 0.819086
C 0.250341
D 0.950634
E 0.852035
Name: A1, dtype: float64
行の部分に:を指定したので、全ての行を指定したことになり、列にA1を指定したため、A1のcolumnsが抽出されています。
print(df.loc['C', ['A2', 'A4']])
A2 0.129296
A4 0.367573
Name: C, dtype: float64
このようにすれば、C行のA2とA4のデータを抽出できます。
条件による選択
DataFrameから、条件を選択して抽出しましょう。以下のコードでdf > 0.5の挙動を確認しましょう。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
print(df)
print(df > 0.5)

このように、DataFrameの中の値が条件を満たすときにはTrueが、条件を満たさないときにはFalseが格納されます。
これを利用すると、以下のように条件を満たさない値を除くことができます。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
print(df > 0.5)
print(df[df > 0.5])

また、次のようにすれば特定のcolumnsが条件を満たす行のみを抽出することができます。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
print(df)
print(df[df['A3'] > 0.5])

以下のように、&を用いて条件を追加することもできます。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
print(df)
print(df[(df['A3'] > 0.2) & (df['A3'] < 0.6)])
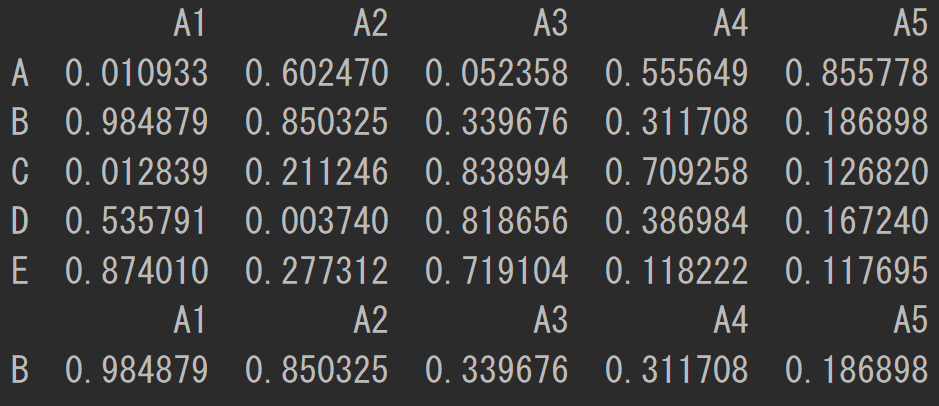
DataFrameのデータの追加と削除
以下のようにすればcolumnsを追加することができます。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
df['new'] = np.arange(5)
print(df)

列名を指定することで列を削除することができます。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
df = df.drop(columns=['A1', 'A3'])
print(df)
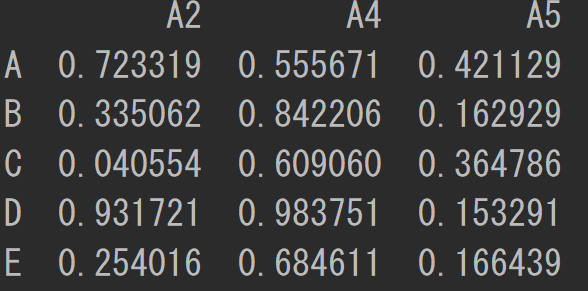
行名を指定することで行を削除することができます。
df = pd.DataFrame(data=np.random.rand(5, 5),
index=['A', 'B', 'C', 'D', 'E'],
columns=('A1', 'A2', 'A3', 'A4', 'A5'))
np.random.seed(0)
df = df.drop(index=['A', 'D'])
print(df)

欠損値の処理
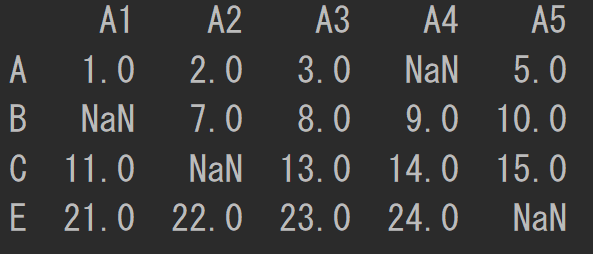
以下のようにデータを準備しましょう。
df = pd.DataFrame([[1, 2, 3, np.nan, 5],
[np.nan, 7, 8, 9, 10],
[11, np.nan, 13, 14, 15],
[16, 17, np.nan, 19, 20],
[21, 22, 23, 24, np.nan]],
index=['A', 'B', 'C', 'D', 'E'],
columns=['A1', 'A2', 'A3', 'A4', 'A5'])
print(df)

dropnaメソッドを用いれば、欠損値が含まれる行を削除してくれます。
df = df.dropna()
print(df)
Columns: [A1, A2, A3, A4, A5]
Index: []
今回のデータは全ての行に欠損値が含まれているため、全て消えてしまいました。このように、強い制限をかけるとなかなかデータが残りません。
特定の列の欠損値を削除
次のようにすれば、特定の列に対して欠損値がある部分を削除できます。
df = pd.DataFrame([[1, 2, 3, np.nan, 5],
[np.nan, 7, 8, 9, 10],
[11, np.nan, 13, 14, 15],
[16, 17, np.nan, 19, 20],
[21, 22, 23, 24, np.nan]],
index=['A', 'B', 'C', 'D', 'E'],
columns=['A1', 'A2', 'A3', 'A4', 'A5'])
df = df[df['A3'].isnull() == False]
print(df)

isnullを用いると、そのデータがnanであればTrueが、nanでなければFalseが返ってきます。そのため、上のようにA3に欠損値が含まれる行のみを削除できます。
欠損値ではない数を指定して削除
dropnaの引数threshの引数を指定することで、引数で指定した数以上の欠損値ではない値を持つ行以外を削除することができます。
例えば、thresh=4とすると、欠損値ではない数が4以上ない行が削除されます。
df = pd.DataFrame([[1, 2, 3, np.nan, 5],
[np.nan, 7, 8, 9, 10],
[11, np.nan, 13, 14, 15],
[16, np.nan, np.nan, 19, 20],
[21, 22, 23, 24, np.nan]],
index=['A', 'B', 'C', 'D', 'E'],
columns=['A1', 'A2', 'A3', 'A4', 'A5'])
df = df.dropna(thresh=4)
axis=1とすれば、列に対して同様の操作が行えます。
df = pd.DataFrame([[1, 2, 3, np.nan, 5],
[np.nan, 7, 8, 9, 10],
[11, np.nan, 13, 14, 15],
[16, np.nan, np.nan, 19, 20],
[21, 22, 23, 24, np.nan]],
index=['A', 'B', 'C', 'D', 'E'],
columns=['A1', 'A2', 'A3', 'A4', 'A5'])
df = df.dropna(thresh=4, axis=1)
print(df)

欠損値を別の値で置換
以下のようにすると、特定の列に対してその列の欠損値にその列の平均を代入することができます。
df = pd.DataFrame([[1, 2, 3, np.nan, 5],
[np.nan, 7, 8, 9, 10],
[11, np.nan, 13, 14, 15],
[16, np.nan, np.nan, 19, 20],
[21, 22, 23, 24, np.nan]],
index=['A', 'B', 'C', 'D', 'E'],
columns=['A1', 'A2', 'A3', 'A4', 'A5'])
df['A3'] = df['A3'].fillna(df['A3'].mean())
print(df)

以下のようにすると、全ての列に対して欠損値に平均値を代入することができます。
df = pd.DataFrame([[1, 2, 3, np.nan, 5],
[np.nan, 7, 8, 9, 10],
[11, np.nan, 13, 14, 15],
[16, np.nan, np.nan, 19, 20],
[21, 22, 23, 24, np.nan]],
index=['A', 'B', 'C', 'D', 'E'],
columns=['A1', 'A2', 'A3', 'A4', 'A5'])
df = df.fillna(df.mean())
print(df)

カテゴリカルなデータの欠損値
以下のDataFrameを作成しましょう。
df = pd.DataFrame({'A1': ['A', 'A', 'B', 'B', 'B', 'C', np.nan],
'A2': [1, 2, 3, 4, 5, 6, 7],
'A3': [8, 9, 10, 11, 12, 13, 14]})
print(df)

以下のコードでカテゴリとデータの数を確認しましょう。
print(df['A1'].value_counts())
B 3
A 2
C 1
以下のコードで特定のカテゴリのデータだけを取り出すことができます。
print(df[df['A1'] == 'B'])
A1 A2 A3
2 B 3 10
3 B 4 11
4 B 5 12
以下のコードで、カテゴリカルなデータの欠損値を埋めることができます。mode()[0]により最頻値が返ってくるので、その最頻値を欠損値に代入しています。
df = pd.DataFrame({'A1': ['A', 'A', 'B', 'B', 'B', 'C', np.nan],
'A2': [1, 2, 3, 4, 5, 6, 7],
'A3': [8, 9, 10, 11, 12, 13, 14]})
df['A1'] = df['A1'].fillna(df['A1'].mode()[0])
print(df)

以下のコードでカテゴリカルなデータの割合を計算しましょう。
df = pd.DataFrame({'A1': ['A', 'A', 'B', 'B', 'B', 'C', np.nan],
'A2': [1, 2, 3, 4, 5, 6, 7],
'A3': [8, 9, 10, 11, 12, 13, 14]})
print(round(df['A1'].value_counts() / len(df), 3))
B 0.429
A 0.286
C 0.143
以下のコードで、カテゴリカルなデータをグループ化して統計量を計算することができます。
df = pd.DataFrame({'A1': ['A', 'A', 'B', 'B', 'B', 'C', np.nan],
'A2': [1, 2, 3, 4, 5, 6, 7],
'A3': [8, 9, 10, 11, 12, 13, 14]})
print(df.groupby('A1').sum())
print(df.groupby('A1').mean())
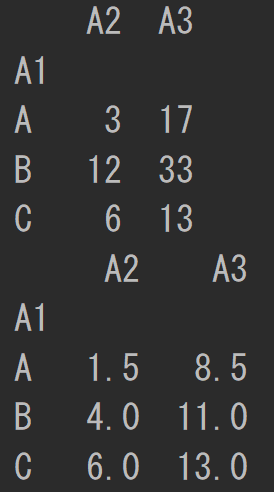
DataFrameの結合
デフォルトではaxis=0となっているため、縦方向に結合されます。
df1 = pd.DataFrame(data=np.random.rand(3, 3),
index=['A', 'B', 'C'],
columns=['A1', 'A2', 'A3'])
df2 = pd.DataFrame(data=np.random.rand(3, 3),
index=['D', 'E', 'F'],
columns=['A1', 'A2', 'A3'])
df3 = pd.concat([df1, df2])
print(df3)

以下のようにaxis=1を指定すれば、横方向に結合することができます。
縦方向に結合するときにはcolumnsを、横方向に結合するときはindexをそれぞれ合わせる必要があります。
df1 = pd.DataFrame(data=np.random.rand(3, 3),
index=['A', 'B', 'C'],
columns=['A1', 'A2', 'A3'])
df2 = pd.DataFrame(data=np.random.rand(3, 3),
index=['A', 'B', 'C'],
columns=['A4', 'A5', 'A6'])
df3 = pd.concat([df1, df2], axis=1)
print(df3)

DataFrameへの関数の適用
applyを用いることで、特定のデータに関数を適用することができます。
df = pd.DataFrame(data=np.random.rand(3, 3),
index=['A', 'B', 'C'],
columns=['A1', 'A2', 'A3'])
print(df)
df['A1'] = df['A1'].apply(lambda x: x ** 2)
print(df)

複数の引数を持つ関数をDataFrameに適用する場合は、DataFrameを引数にもつ関数を定義すると便利です。
df = pd.DataFrame(data=np.random.rand(3, 3),
index=['A', 'B', 'C'],
columns=['A1', 'A2', 'A3'])
print(df)
def matmul(df):
return df['A1'] * df['A2']
df['A4'] = df.apply(matmul, axis=1)
print(df)

複数の戻り値がある場合、以下のようにすれば受け取ることができます。
df = pd.DataFrame(data=np.random.rand(3, 3),
index=['A', 'B', 'C'],
columns=['A1', 'A2', 'A3'])
def square_and_twice(x):
return pd.Series([x**2, x*2])
df[['square', 'twice']] = df['A3'].apply(square_and_twice)
print(df)

終わりに
ここまでで今回の記事は終了です。
お付き合い頂きありがとうございました。