2024/11/02 に,Amazon Bedrock で Anthropic Claude3 Haiku の Fine-Tuning がついに GA となりました!2024/11/02 時点では,オレゴンリージョンで利用可能で,本記事で言及している利用申請は不要になりました!
同時に,Claude3 Haiku を Fine-Tuning する際のベストプラクティスをまとめた AWS 公式ブログも公開されましたので,本記事でも以下の節で追加でまとめております.是非ご覧下さい!
- Claude3 Haiku の Fine-Tuning で推奨されるユースケース
- Fine-Tuning 時のベストプラクティス
はじめに
株式会社 NTT データ デジタルサクセスコンサルティング事業部の @ren8k です.
2024/7/10 に,Amazon Bedrock で Anthropic Claude 3 Haiku の Fine-Tuning がプレビューで利用可能になりました.本稿では,Claude3 Haiku の Fine-Tuning の利用手順および,Fine-Tuning したモデルの評価結果を共有いたします.
なお,本検証で利用したコードは以下のリポジトリで公開しています.是非ご覧下さい.
Claude3 Haiku の Fine-Tuning で推奨されるユースケース
AWS 公式ブログによると,Fine-Tuning が推奨されるケースとして以下が紹介されています.
| ユースケース | 具体例 |
|---|---|
| 分類タスク | ドキュメントをカテゴリ分類するケース |
| 構造化された形式での出力 | モデルの出力を JSON スキーマのような構造化された形式に従わせるケース |
| 新しいスキルの学習 | API の呼び出し方法を学習させたり,独自のフォーマットのドキュメントから情報抽出させたいケース |
| 特定のトーンで応答 | カスタマーサービス担当者のような特定のトーンで応答させたいケース |
その他,簡潔な回答を出力するように学習データを構築することで,出力トークン数を削減することもできます.(実験では 35%削減されたようです.)
一方で,モデルに新しい知識を学習させるケースでは,Fine-Tuning の成功可能性は低いとされているため,注意が必要です.
公式ブログでは,後述するベストプラクティスに基づき Fine-Tuning を行った場合,Claude3 Haiku は,Claude3 Sonnet,Claude3.5 Sonnet よりも優れたパフォーマンスを発揮することが示されています.
Fine-Tuning 時のベストプラクティス
データセットの品質向上と学習時のハイパーパラメータの調整が,Fine-Tuning の成否に大きく影響します.
データセットの品質向上
データセットの量より質を重視すべきであり,データのクリーニングと検証を行うことが重要です.データセットの検証(評価)について,データが小規模であれば人間が行い,データが大規模であれば,LLM as a judge で実施すると効果的です.以下に,LLM as a judge のプロンプト例を示します.
LLM as a judge のプロンプト例
Your task is to take a question, an answer, and a context which may include multiple documents, and provide a judgment on whether the answer to the question is correct or not. This decision should be based either on the provided context or your general knowledge and memory. If the answer contradicts the information in context, it's incorrect. A correct answer is ideally derived from the given context. If no context is given, a correct answer should be factually true and directly and unambiguously address the question.\n\nProvide a short step-by-step reasoning with a maximum of 4 sentences within the <reason></reason> xml tags and provide a single correct or incorrect response within the <judgement></judgement> xml tags.
<context>
...
</context>
<question>
...
</question>
<answer>
...
</answer>
AWS 公式ブログより引用
また,学習データにはシステムプロンプトを含め,モデルの役割とタスクを明確に定義することが推奨されています.さらに,学習データの Ground Truth に XML タグと回答根拠を含めると,与えられたコンテキストからの情報抽出の精度が向上するようです.
学習時のハイパーパラメータの調整
学習率乗数とバッチサイズが重要なハイパーパラメーターです.このパラメータの調整により,2 ~ 10%の改善が見込まれると公式ブログには記載されています.
学習率乗数は,デフォルト値の 1.0 から試し,評価結果に基づき調整することが推奨されています.バッチサイズについては,データセットのサイズに基づき以下のように調整するとより良い結果が得られると紹介されています.
| データセットのサイズ | バッチサイズ |
|---|---|
| 1000 以上 | 32~64 程度 |
| 500~1000 | 16~32 程度 |
| 500 未満 | 4~16 程度 |
特に,大規模なデータセット (1000~10000) の場合は学習率が,小規模なデータセット (32~100) の場合はバッチサイズがパフォーマンスに大きな影響を与えるようです.また,データセットが少数の場合,epoch 数は 10 程度必要で,データセットが 1000~10000 件程度の場合は,epoch 数は 2~1 程度で十分のようです.
利用手順と検証内容
-
利用申請(2024/11/02 時点では不要になりました.) - データセットの作成
- データセットを S3 へアップロード
- fine-tuning job の実行
- プロビジョンドスループットの購入
- fine-tuning したモデルの実行
- モデルの評価
利用申請 (2024/11/02 以降は不要)
執筆時点(2024/07/27)では,Amazon Bedrock で Claude3 Haiku を fine-tuning するには,AWS サポートに申請が必要です.サポートチケット作成時,サービスとして「Bedrock」を選択し,カテゴリとして「Models」を選択して下さい.
データセットの作成
本検証では,Claude3 Haiku に「Amazon Bedrock」というドメイン知識を獲得させることを目的として,Amazon Bedrock に関する fine-tuning 用データセットを準備しました.データセットとして,AWS 公式ドキュメントから作成された質問と回答のペアを利用しています.以降,本検証を行う際に検討した事項や検証方針,データセットの準備・作成方法について説明します.
利用するデータセットの検討
オープンソースで公開されている代表的な日本語データセットとして,databricks-dolly-15k-ja や databricks-dolly-15k-ja-gozaru などが挙げられます.databricks-dolly-15k-ja-gozaru は,LLM の応答の語尾(口調)を「ござる」にするためのユニークなデータセットです.しかし,Claude3 Haiku の性能であれば,このデータセットで fine-tuning せずとも,システムプロンプトで指示するだけで同様の効果が得られると予想されます.そのため,このデータセットを使用しての fine-tuning は,その効果を実感しづらい可能性があります.
そこで,本検証では,Claude3 Haiku に出力形式を学習させるのではなく,ドメイン知識を獲得させることを目的としました.具体的には,Claude3 Haiku の事前学習データに含まれていないと考えられる「Amazon Bedrock」の知識を学習させるためのデータセットを準備することにしました.
また,以下の AWS 公式ブログでは,Claude3 Haiku の fine-tuning のパフォーマンスを最適化するために,まずは小規模かつ高品質のデータセット(50-100 件)で試すことを推奨しています.この推奨に基づき,本検証でも 100 件未満のデータセットで fine-tuning を行うことにしました.
databricks-dolly-15k は,Databricks が公開した 15,000 の指示-応答ペアを含むデータセットです.databricks-dolly-15k-ja-gozaru は,databricks-dolly-15k を日本語訳したデータセットである databricks-dolly-15k-ja の応答の語尾を「ござる」に置換したデータセットであり,LLM の fine-tuning の検証によく利用されております.
利用する訓練データ
fine-tuning 用の訓練データとして,AWS Machine Learning Blog の記事 “Improve RAG accuracy with fine-tuned embedding models on Amazon SageMaker” で利用されている Amazon Bedrock FAQs のデータセットを利用しました.データセットは以下のリポジトリで公開されています.
本データセットは,Amazon Bedrock FAQsを基に作成されており,JSON 形式で 計 85 個の質問と回答のペアが保存されています.以下に,データセットの一部を示します.JSON のキーsentence1が質問,sentence2が回答となっております.
[
{
"sentence1": "What is Amazon Bedrock and its key features?",
"sentence2": "Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with a broad set of capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features."
},
{
"sentence1": "How can I get started with using Amazon Bedrock?",
"sentence2": "With the serverless experience of Amazon Bedrock, you can quickly get started by navigating to the service in the AWS console and trying out the foundation models in the playground or creating and testing an agent."
}
]
ただし,本データセットは 85 件と多くはないため,本データを訓練データと検証データに分割するのではなく,検証データは別途作成することにしました.
本検証で上記のデータセットを選んだ理由としては,データの品質が高く,ライセンス的にも問題ないためです.また,Claude3 Haiku の事前学習データには含まれてないと考えられる Amazon Bedrock という特定ドメインの知識を学習させるための題材としては適切であると考えたためです.
検証データの作成
以下の AWS 公式ドキュメントを基に,Claude3 Opus で検証データを作成しました.その際,下記のドキュメントを PDF 化しておき,Amazon Bedrock の Converse API の Document chat と Json mode を利用することで,比較的容易に JSON 形式でかつ 品質の高い QA 形式のデータセットを作成することができました.
以下に示すコードを利用し,計 32 個の質問と回答のペアを生成しました.
Python実装(折り畳めます)
Tool use の設定を行うためのコード tool_config.py と,検証データを作成するためのコード create_val_dataset.py を示します.tool_conifg.py では,question と answer を要素とする JSON を Array 型で生成するように設定しており,プロンプトで 32 個生成するように指示しています.なお,Json mode で利用するため,ツール自体の定義は行っておりません.
class ToolConfig:
tool_name = "QA_dataset_generator"
no_of_dataset = 32
description = f"""
与えられるドキュメントに基づいて、LLMのFine-Tuning用のValidationデータセットを作成します。
具体的には、ドキュメントの内容を利用し、Amazon Bedrockに関する質問文と回答文のペアを生成します。
<example>
question: What is Amazon Bedrock and its key features?
answer: Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with a broad set of capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features.
</example>
<rules>
- 必ず{no_of_dataset}個の質問文と回答文のペアを生成すること。
- 英語で回答すること。
- JSON形式で回答すること。
- Amazon Bedrockについて、多様な質問と回答を作成すること。
</rules>
"""
tool_definition = {
"toolSpec": {
"name": tool_name,
"description": description,
"inputSchema": {
"json": {
"type": "object",
"properties": {
"dataset": {
"description": f"Validationデータ用の質問文と回答文のセット。必ず{no_of_dataset}個生成すること。",
"type": "array",
"items": {
"type": "object",
"properties": {
"question": {
"type": "string",
"description": "Validationデータ用の質問文。",
},
"answer": {
"type": "string",
"description": "Validationデータ用の回答文。",
},
},
"required": ["question", "answer"],
},
},
},
"required": ["dataset"],
}
},
}
}
create_val_dataset.py では,AWS 公式ドキュメントの PDF ファイルをバイナリ形式で読み込み,Converse API の Document chat で直接入力入力しています.加えて,Converse API の Tool use の設定値で toolChoice を指定することで,ツールの呼び出しを強制しています.これにより,Converse API のレスポンスに JSON 形式のツール呼び出しのリクエスト(生成された QA 形式の検証データセット)が確実に含まれるようになります.
import argparse
import json
from pprint import pprint
import boto3
from botocore.config import Config
from tool_config import ToolConfig
def get_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument(
"--region",
type=str,
default="us-west-2",
)
parser.add_argument(
"--model-id",
type=str,
default="anthropic.claude-3-opus-20240229-v1:0",
)
parser.add_argument(
"--order",
type=str,
default="LLM の Fine Tuning 用のデータセットを作成しなさい。",
)
parser.add_argument(
"--input-doc-path",
type=str,
default="./amazon_bedrock_user_docs.pdf",
)
parser.add_argument(
"--output-path",
type=str,
default="../../dataset/rawdata/validation.json",
)
return parser.parse_args()
def document_chat(region: str, model_id: str, prompt: str, doc_bytes: bytes) -> dict:
retry_config = Config(
region_name=region,
connect_timeout=300,
read_timeout=300,
retries={
"max_attempts": 10,
"mode": "standard",
},
)
client = boto3.client("bedrock-runtime", config=retry_config, region_name=region)
messages = [
{
"role": "user",
"content": [
{
"document": {
"name": "Document",
"format": "pdf",
"source": {"bytes": doc_bytes},
}
},
{"text": prompt},
],
}
]
# Send the message to the model
response = client.converse(
modelId=model_id,
messages=messages,
inferenceConfig={
"maxTokens": 3000,
},
toolConfig={
"tools": [ToolConfig.tool_definition],
"toolChoice": {
"tool": {
"name": ToolConfig.tool_name,
},
},
},
)
pprint(response)
return response
def extract_tool_use_args(content: list) -> dict:
for item in content:
if "toolUse" in item:
return item["toolUse"]["input"]
raise ValueError("toolUse not found in response content")
def main(args: argparse.Namespace) -> None:
prompt = f"""
{args.order}
{ToolConfig.tool_name} ツールのみを利用すること。
"""
print(prompt)
with open(args.input_doc_path, "rb") as f:
doc_bytes = f.read()
# call converse API
response: dict = document_chat(args.region, args.model_id, prompt, doc_bytes)
response_content: list = response["output"]["message"]["content"]
# extract json
tool_use_args = extract_tool_use_args(response_content)
# write to file
with open(args.output_path, "w") as f:
json.dump(tool_use_args["dataset"], f, indent=2, ensure_ascii=False)
if __name__ == "__main__":
args = get_args()
main(args)
上記のコードでは,外部の JSON ファイルに 32 個の QA 形式の検証データを保存しています.以下に,実際に生成された検証データの一部を示します.プロンプトで指示した通り,QA 形式となっていることを確認できます.
[
{
"question": "What is Amazon Bedrock?",
"answer": "Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features."
},
{
"question": "What are guardrails used for in Amazon Bedrock?",
"answer": "Guardrails in Amazon Bedrock allow you to implement safeguards for your generative AI applications to prevent inappropriate or unwanted content."
}
]
データセットのフォーマット(前処理)
Claude3 Haiku で fine-tuning を行うには,前処理として,訓練データおよび検証データを以下のフォーマットの JSON Lines (JSONL) 形式にする必要があります.具体的には,システムプロンプト,ユーザーのプロンプト,LLM のレスポンスを 各 JSON レコードとして保存します.
{"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
{"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
{"system": string, "messages": [{"role": "user", "content": string}, {"role": "assistant", "content": string}]}
本検証では,以下に示すコードで前処理を行いました.python コード実行時の引数で,システムプロンプト,入力ファイル(訓練データ or 検証データ),出力ファイル,入力ファイルで利用されている JSON のキーを指定することが可能です.
Python実装(折り畳めます)
import argparse
import json
def get_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument(
"--system-prompt",
type=str,
default="You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately.",
)
parser.add_argument(
"--input-file",
type=str,
default="../../dataset/rawdata/validation.json",
)
parser.add_argument(
"--output-file",
type=str,
default="../../dataset/preprocessed/claude3_ft_validation.jsonl",
)
parser.add_argument("--prompt-key", type=str, default="question")
parser.add_argument("--completion-key", type=str, default="answer")
return parser.parse_args()
def preprocess(args: argparse.Namespace) -> None:
"""
Preprocess the input JSON file to the format that can be used for claude3's fine-tuning.
Input JSON file should have the structure of a list of dictionaries.
Below is an example of the input JSON file.
[
{
"question": "What is the capital of France?",
"answer": "Paris"
},
...
]
"""
with open(args.input_file, "r") as f_in, open(args.output_file, "w") as f_out:
input_json = json.load(f_in)
for data in input_json:
prompt = data[args.prompt_key]
completion = data[args.completion_key]
new_data = {}
new_data["system"] = args.system_prompt
new_data["messages"] = [
{"role": "user", "content": prompt},
{"role": "assistant", "content": completion},
]
f_out.write(json.dumps(new_data) + "\n")
def main(args: argparse.Namespace) -> None:
preprocess(args)
print("Conversion completed!")
if __name__ == "__main__":
args = get_args()
main(args)
例えば,訓練データの前処理を行いたい場合,以下の shell のようなコマンドを実行します.(argparseの default 値は検証データに合わせているため,検証データの前処理を行う際は,引数指定は不要です.)
#!/bin/bash
INPUT="../../dataset/rawdata/training.json"
OUTPUT="../../dataset/preprocessed/claude3_ft_training.jsonl"
PROMPT_KEY="sentence1"
COMPLETION_KEY="sentence2"
python3 preprocess.py \
--input-file $INPUT \
--output-file $OUTPUT \
--prompt-key $PROMPT_KEY \
--completion-key $COMPLETION_KEY
上記のコードでは,外部の jsonl ファイルに 指定のフォーマットでデータセットを保存しています.参考に,実際にフォーマットした訓練データの一部を示します.
{"system": "You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately.", "messages": [{"role": "user", "content": "What is Amazon Bedrock and its key features?"}, {"role": "assistant", "content": "Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models along with a broad set of capabilities for building generative AI applications, simplifying development with security, privacy, and responsible AI features."}]}
{"system": "You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately.", "messages": [{"role": "user", "content": "How can I get started with using Amazon Bedrock?"}, {"role": "assistant", "content": "With the serverless experience of Amazon Bedrock, you can quickly get started by navigating to the service in the AWS console and trying out the foundation models in the playground or creating and testing an agent."}]}
訓練データ,および検証データには,以下の要件があります.
- データの件数の上限・下限
- 訓練データ: 32~10000
- 検証データ: 32~1000
- データセットのサイズ
- 訓練データ: 10GB 以下
- 検証データ: 1GB 以下
- データセットのフォーマット
- JSON Lines (JSONL) 形式
- システムプロンプト,ユーザーのプロンプト,LLM のレスポンスを Claude3 用のフォーマットで保存
fine-tuning には時間や費用がかかるため,事前にデータセットが要件を満たしているかを確認することを推奨します.本検証では,以下で公開されている AWS 公式の Data Validation ツールを利用することで,事前に確認を行っています.
データセットを S3 へアップロード
作成した訓練データ,検証データを,米国西部 (オレゴン) リージョンの S3 バケットにアップロードする必要があります.本リポジトリでは,先程のステップで作成した前処理済みのデータセットを公開しております.本リポジトリ上のデータを利用する場合,以下のコマンドで,本データセットのアップロードが可能です.コマンド中の <your bucket> は、任意のバケット名に置き換えてください。
aws s3 cp dataset/preprocessed/ s3://<your bucket>/claude3-haiku/dataset --recursive
fine-tuning job の実行
コンソール上での実施手順
以降,Amazon Bedrock コンソール上での,Claude3 Haiku の fine-tuning の実施手順を説明します。
オレゴンリージョンで、Amazon Bedrock コンソールから、左側にあるナビケーションペインの [基盤モデル] セクションから [カスタムモデル] を選択します。
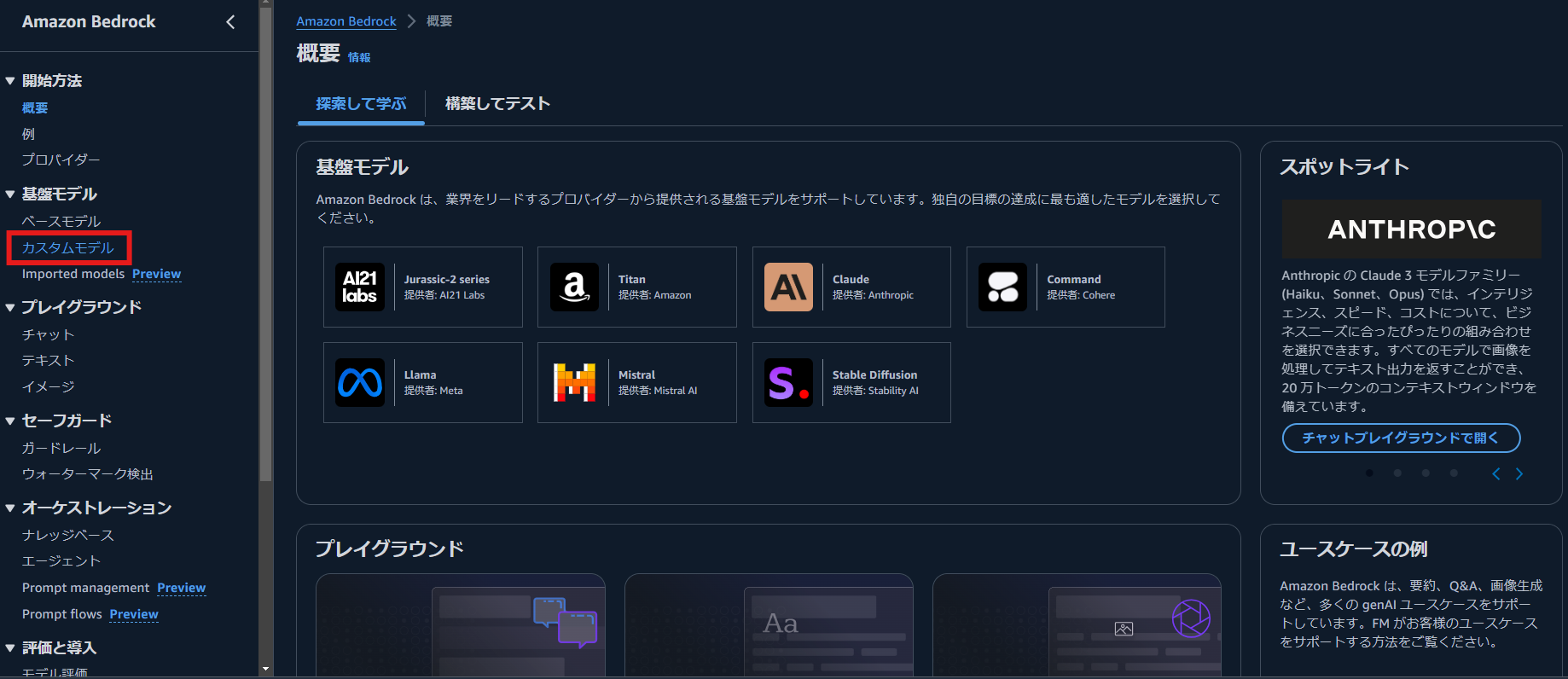
右側の [モデルをカスタマイズ] を選択し,[微調整ジョブを作成] を選択します.
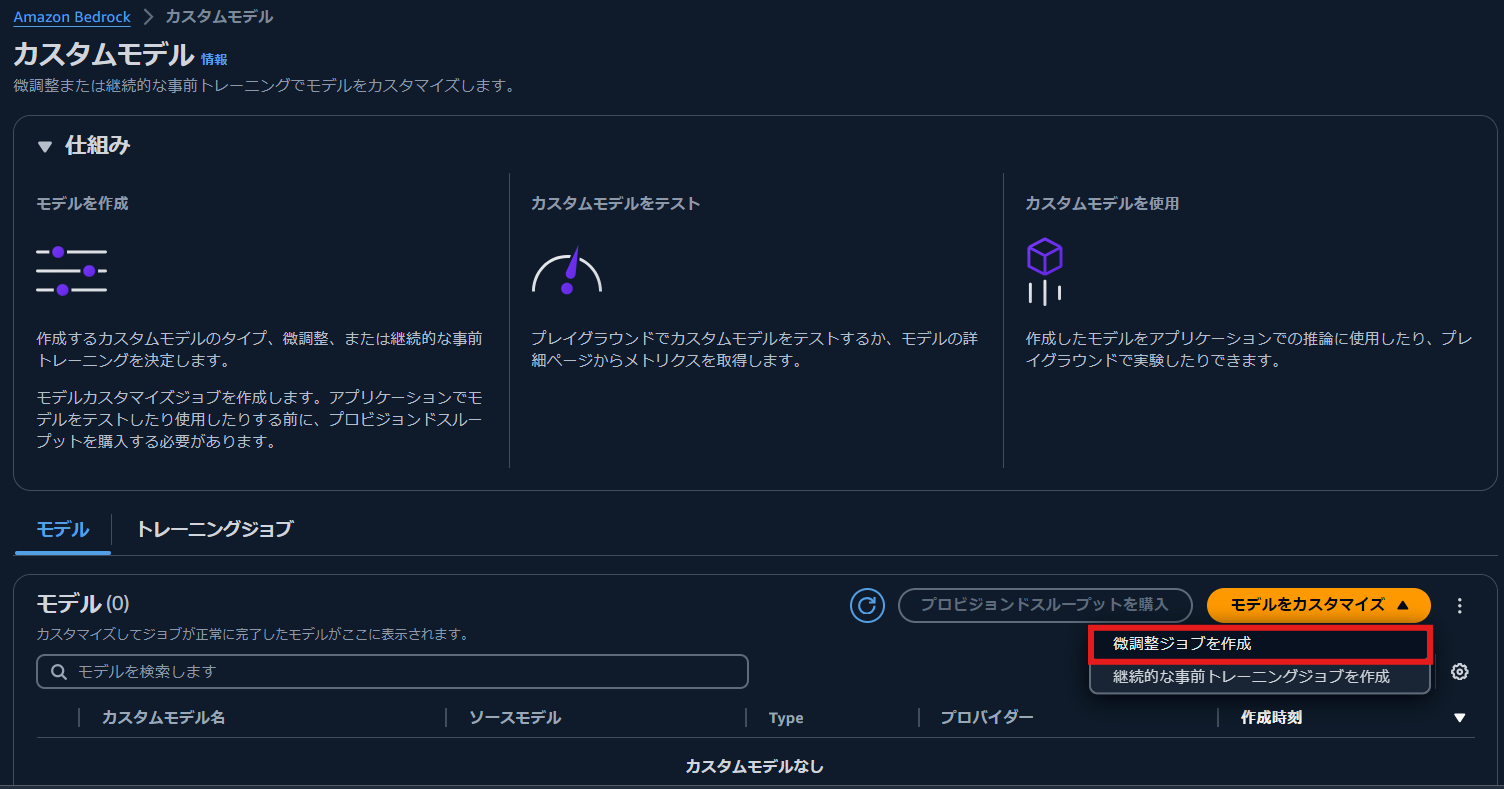
微調整ジョブ (fine-tuning job) の作成画面の [ソースモデル] の [モデルを選択] を選択します.

Claude3 Haiku を選択し,[適用] を押下します.

fine-tuning job の設定画面で,以下の情報を入力します.
- 微調整されたモデル名: 任意のモデル名
- ジョブ名: fine-tuning job 名
- 入力データ: 先程アップロードした訓練データと検証データの S3 パス

fine-tuning job のハイパーパラメータを設定します.なお,エポック数のデフォルト値は 2 ですが,本検証は 10 エポックで実施し,その他のパラメータはデフォルト値としました.
| ハイパーパラメータ | 内容 |
|---|---|
| エポック | 訓練データセット全体を繰り返し学習する回数(最大 10epoch) |
| バッチサイズ | モデルのパラメータ更新で使用するサンプル数 |
| Learning rate multiplier | 基本学習率 (base learning rate) を調整するための乗数 |
| Early stopping (早期停止) | validation loss が一定のエポック数で改善しない場合に学習を停止する,過学習を防ぐための手法 |
| 早期停止のしきい値 | Early stopping を判断するための validation loss の改善幅のしきい値 |
| 早期停止ペイシェンス | Early stopping を判断するまでに許容するエポック数 |

fine-tuning 実行時の training loss, validation loss の推移を記録するため,保存先の S3 URI を指定します.また,サービスロールは新規作成します.その後,[モデルを微調整] を選択し,fine-tuning job を実行します.

fine-tuning job が開始されます.ステータス が トレーニング から 完了 に変わるまで待ちます.
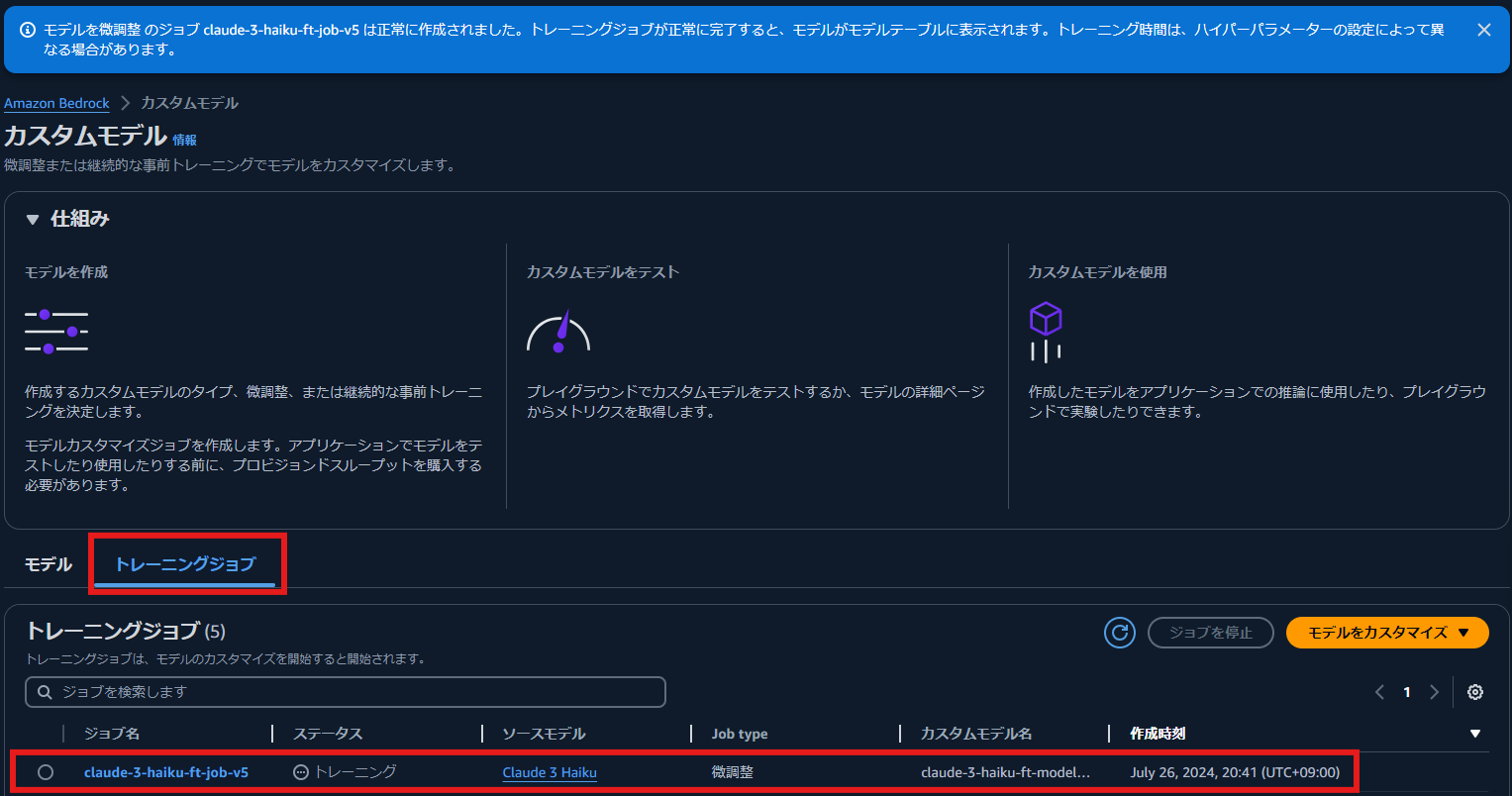
fine-tuning job が完了すると,ステータスが 完了 に変わります.今回の検証では,2 時間程度で完了しました.
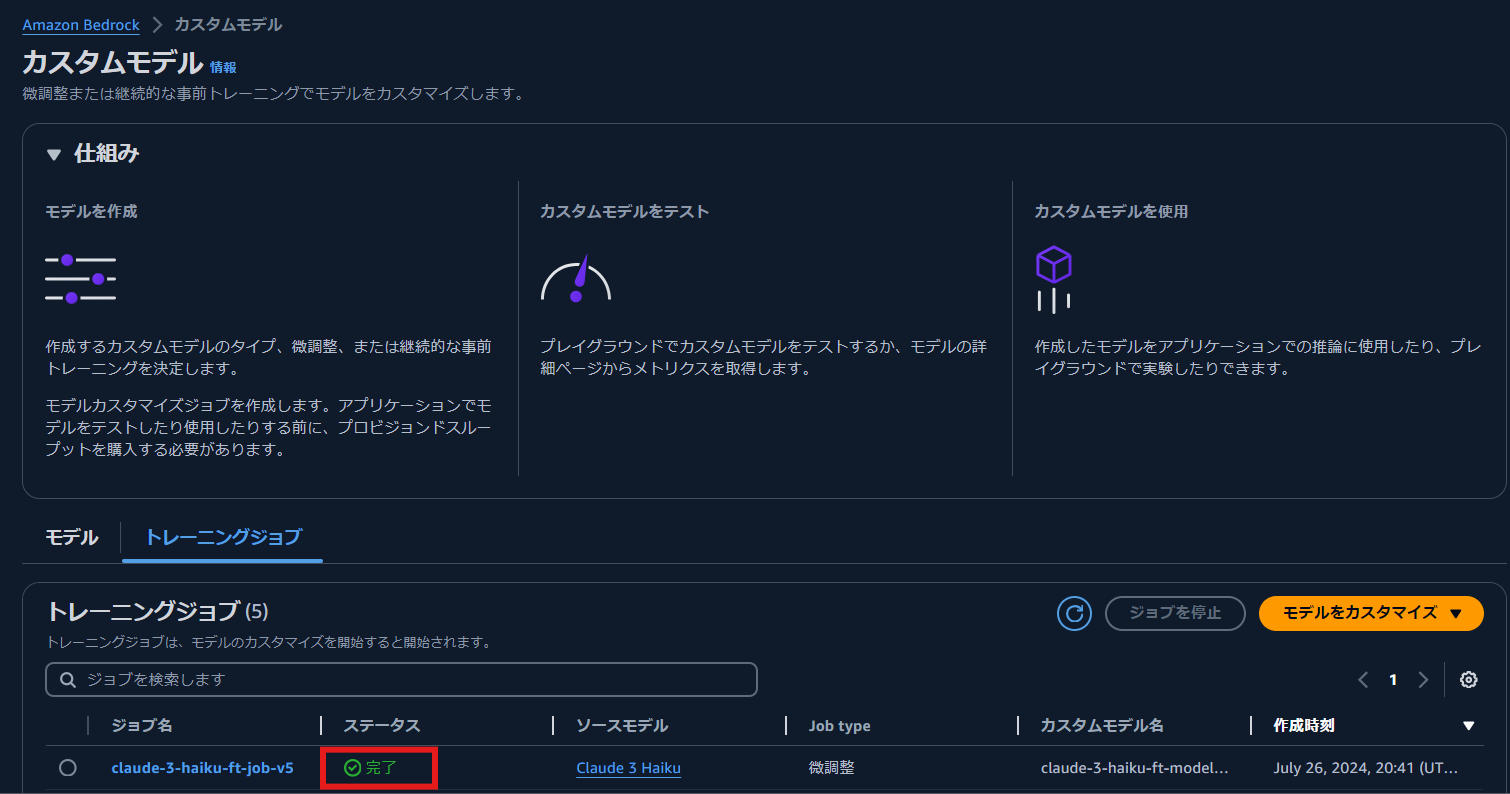
[モデル] を選択し、モデル名を選択すると、モデル ARN ジョブ ARN,出力データ(epoch 毎の training loss, validation loss の値)の保存先などの詳細情報を確認できます。
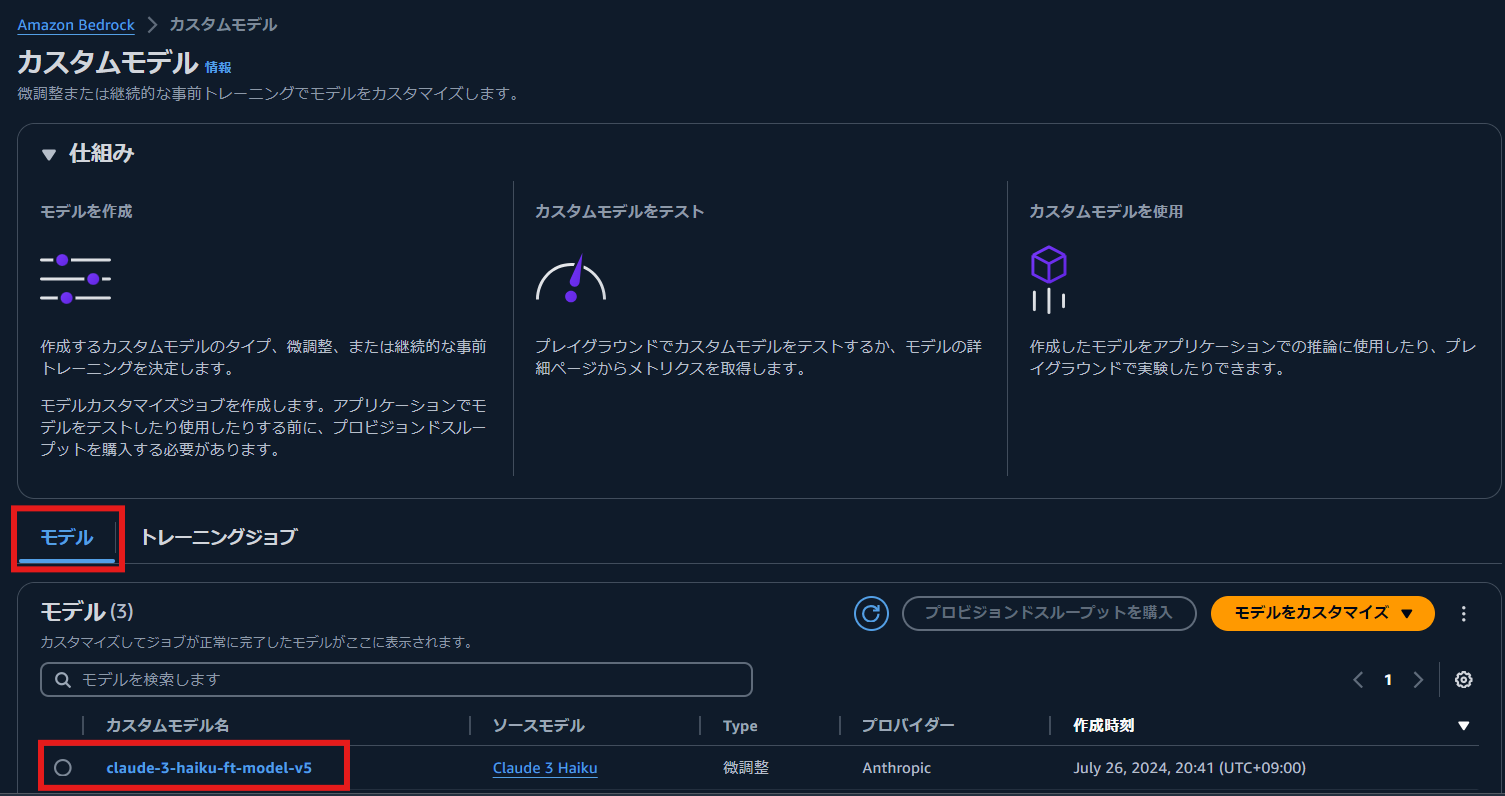
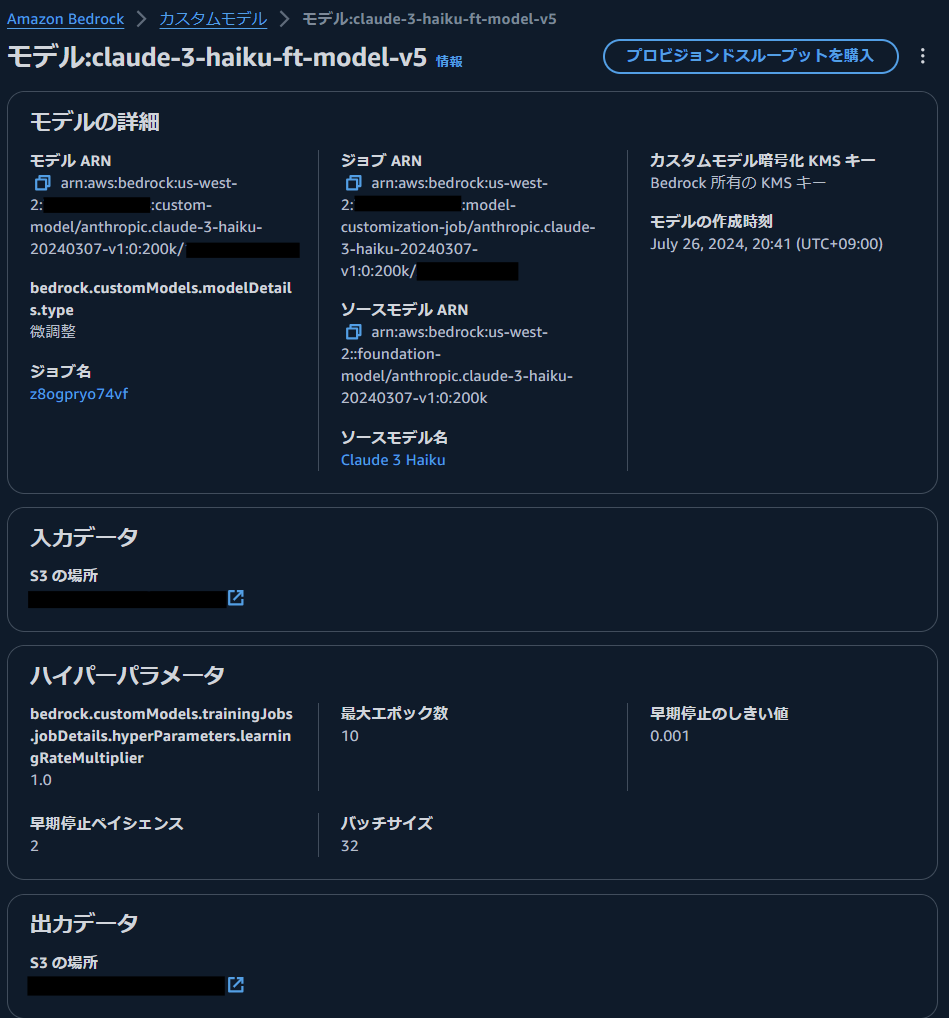
training loss,validation loss の観察
出力データとして,エポック毎の training loss, validation loss の値が記録された CSV ファイルが S3 に保存されます.これらの値を観察することで,fine-tuning が正常に行えているかを判断することができます.
以下に fine-tuning 実行時の trainin loss, validation loss の推移を示します.training loss, validation loss 共に,エポック数が増えるにつれて減少しており,適切に学習が行えていることが確認できます.また,5 ~ 7 エポック目で validation loss が改善しておらず,7 エポック目で Early stopping が発生していることが確認できます.
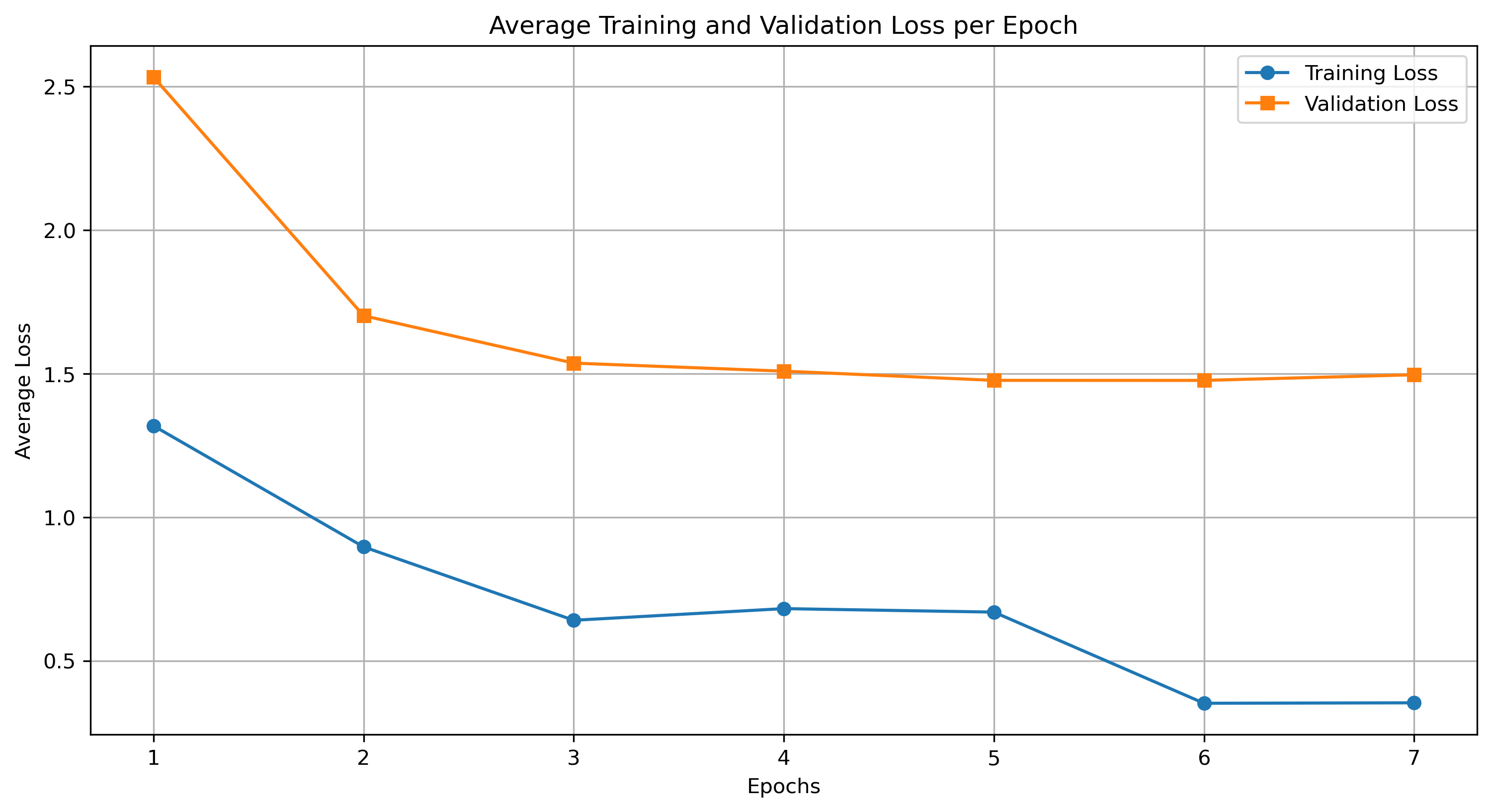
CSV ファイルにはステップ毎の loss が記録されていますが,上図ではエポック毎の loss の平均値を示しています.
プロビジョンドスループットの購入
fine-tuning したモデルをデプロイするために,プロビジョンドスループットを購入する必要があります.以降,コンソール上でのプロビジョンドスループットの購入手順を説明します.
Bedrock コンソールの [カスタムモデル] の画面で微調整されたモデルを選択し,「プロビジョンドスループットの購入」を選択します.
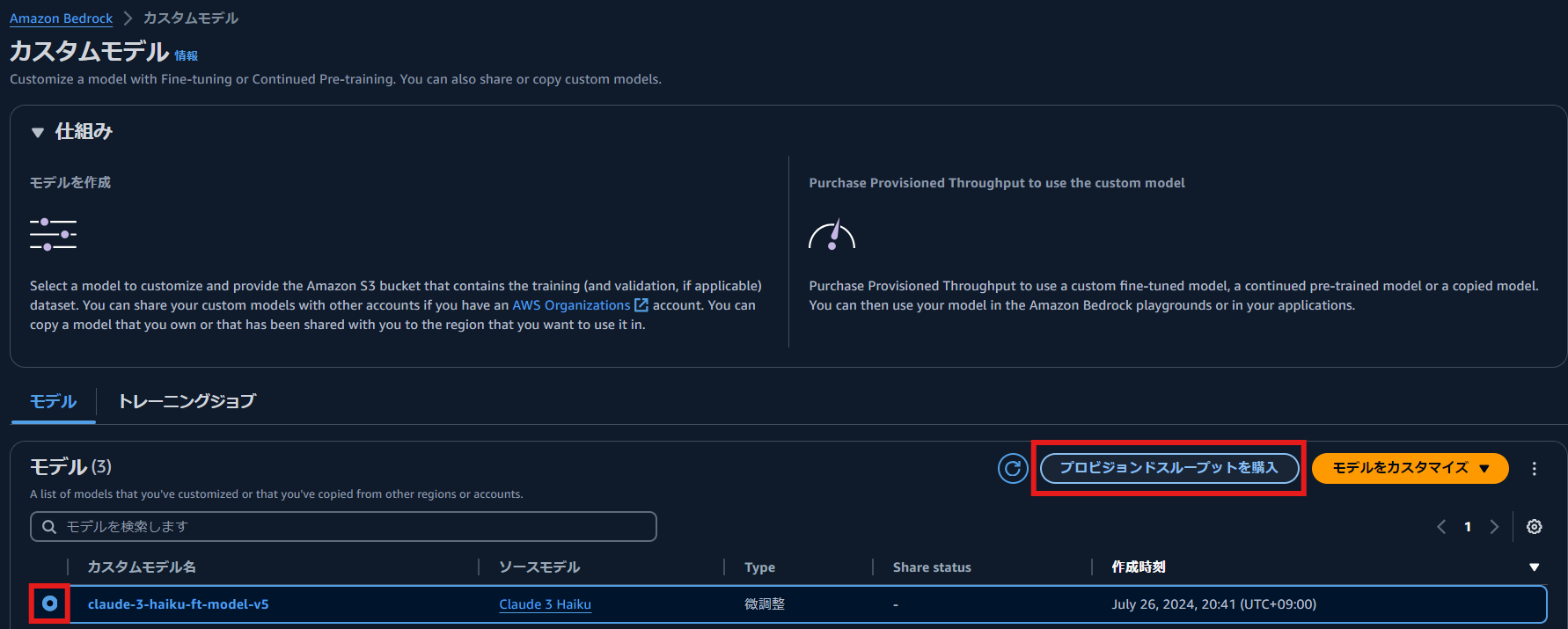
プロビジョンドスループットの名前を入力し,契約期間を選択します.今回の検証では 1 時間程度しか利用しないため, 時間単位の課金である No commitment を選択しました.その後,[プロビジョンドスループットを購入] を選択します.

購入確認画面が表示されるので,チェックボックスを付け [購入を確認] を選択します.

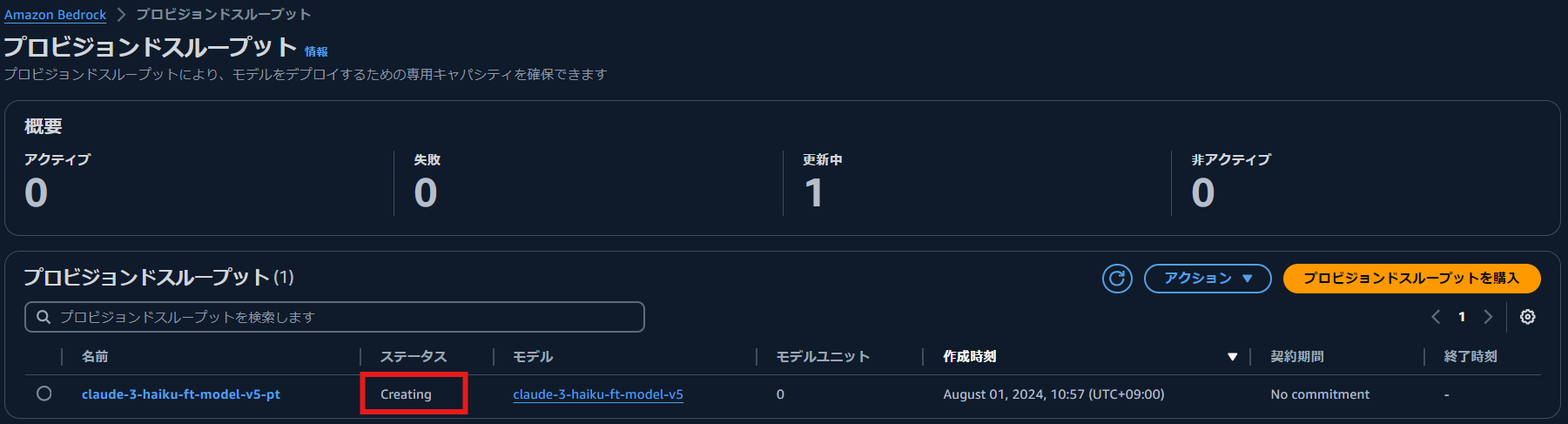
今回の検証では,20 分程度で完了しました.
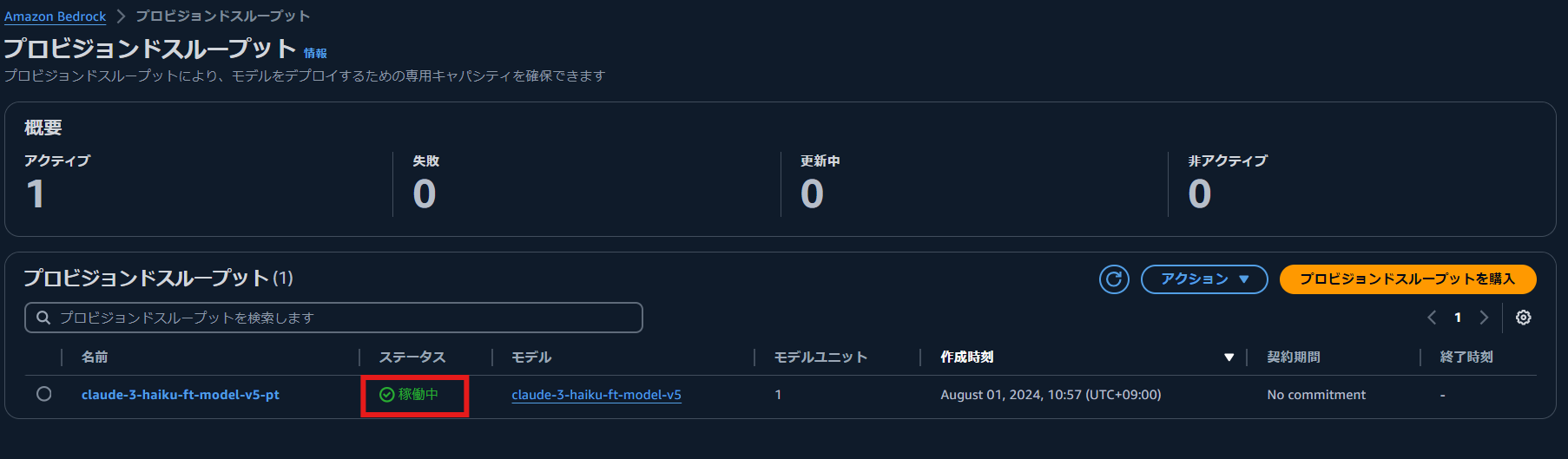
作成されたプロビジョンドスループットを選択すると,プロビジョンドスループットの ARN などを確認できます.こちらは,Boto3 を利用してモデルで推論する際に利用します.
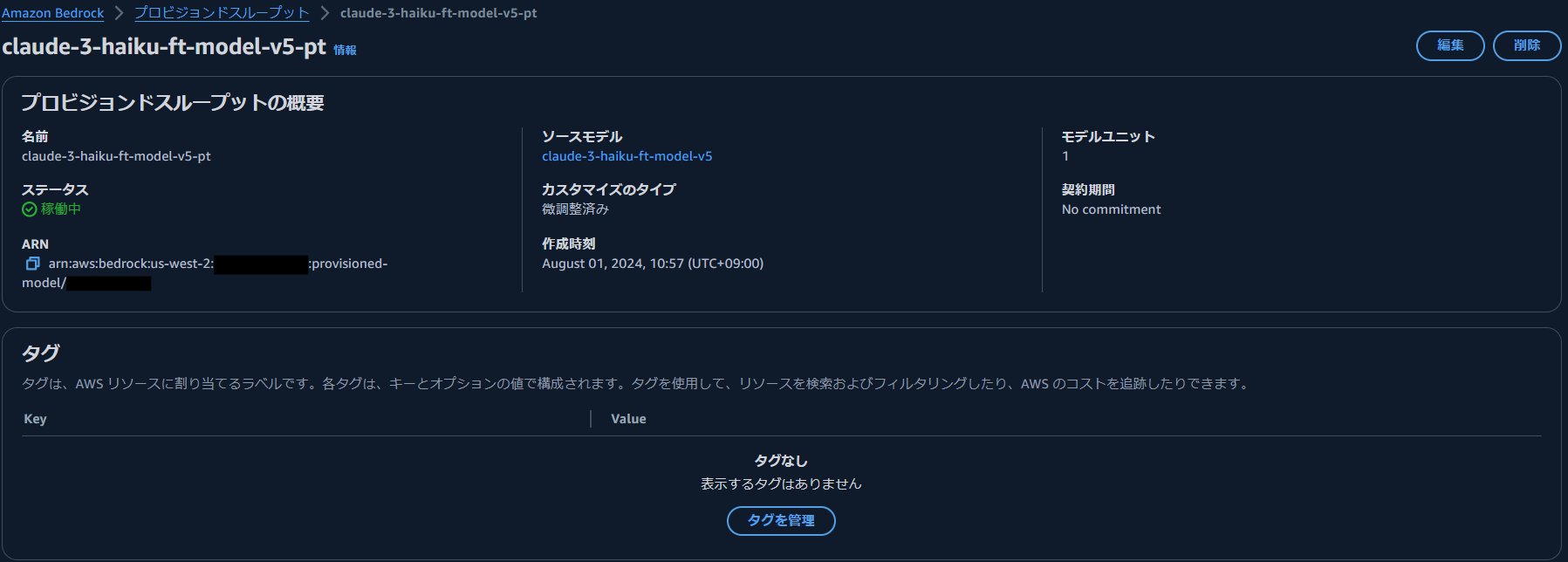
1 時間あたり 132 ドルの課金が発生するので,利用後は迅速にプロビジョンドスループットを削除することをお勧めします!
fine-tuning したモデルの実行
Amazon Bedrock のプレイグラウンドおよび,AWS SDK for Python (Boto3) を利用して,実際に fine-tuning したモデルで推論してみます.
プレイグラウンドで実行
Amazon Bedrock コンソール上でプレイグラウンドの[チャット]を選択し,モデルを選択します.その際,カスタムモデルを選択し,先程 fine-tuning したモデルを選択します.
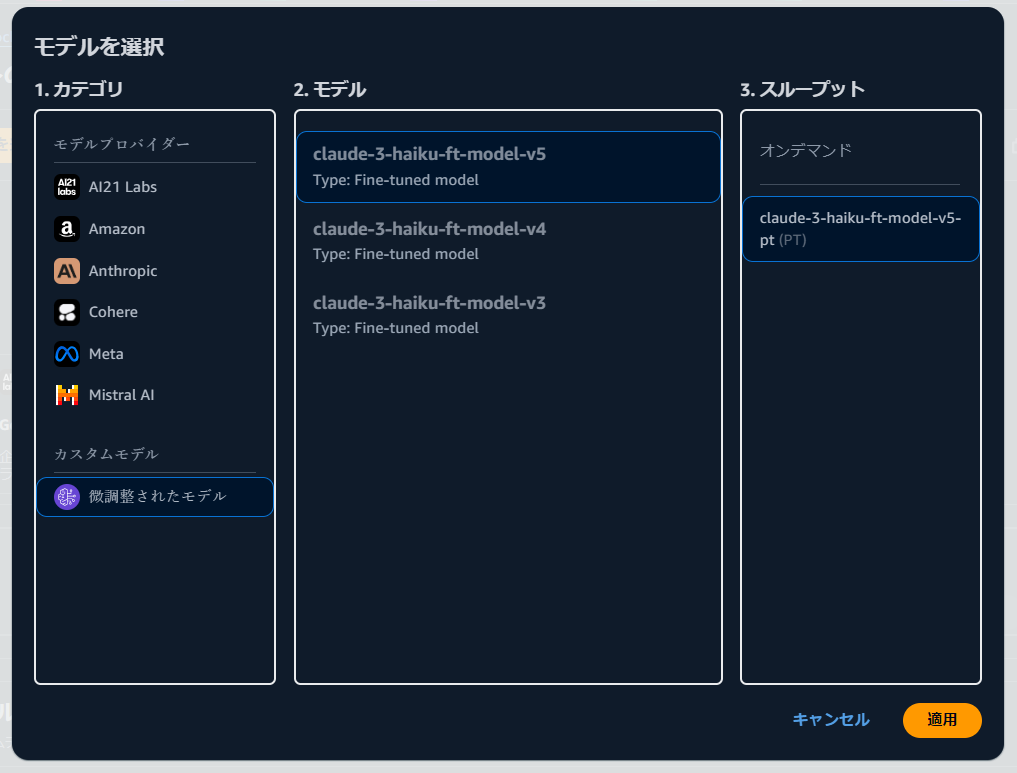
プレイグラウンドで利用されるモデル名が,fine-tuning したモデル名になっていることが確認できます.今回は,What is Knowledge Bases for Amazon Bedrock? という質問を入力し,[実行] ボタンを押下しました.
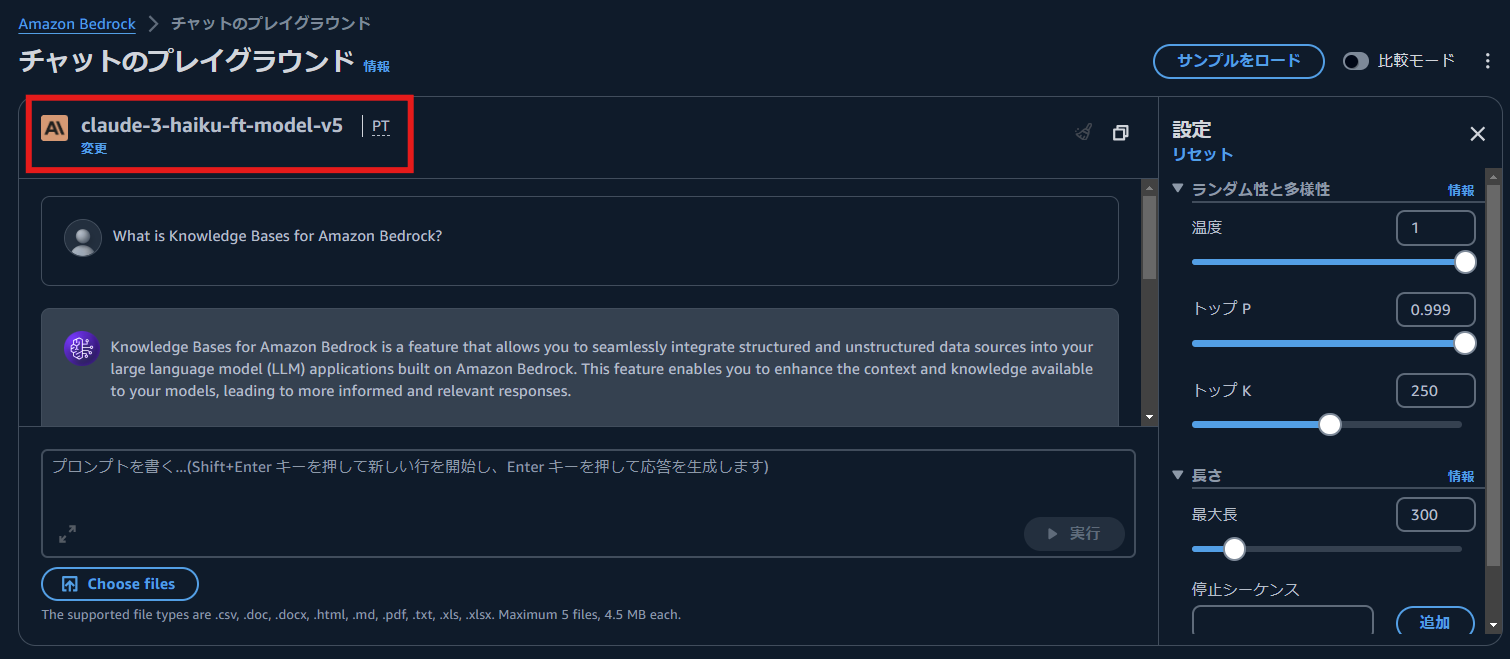
以下に fine-tuning したモデルの回答を示します.回答の前半については適切な内容ですが,回答の後半については一部ハルシネーション(執筆時点では,Knoeledge Bases for Amazon Bedrock は,JSON や XML などのデータ形式には未対応)が見られました.
Knowledge Bases for Amazon Bedrock is a feature that allows you to seamlessly integrate structured and unstructured data sources into your large language model (LLM) applications built on Amazon Bedrock. This feature enables you to enhance the context and knowledge available to your models, leading to more informed and relevant responses.
With Knowledge Bases for Amazon Bedrock, you can connect your LLM applications to a variety of data sources, including databases, content management systems, enterprise applications, and file storage services. The feature supports a wide range of data formats, including structured data (e.g., CSV, Excel, SQL), unstructured data (e.g., PDF, Word, HTML), and semi-structured data (e.g., JSON, XML).
コンソール上からは,システムプロンプトを設定することはできないようでした.
比較のため,fine-tuning していない通常の Claude3 Haiku でも同様の質問を行いました.
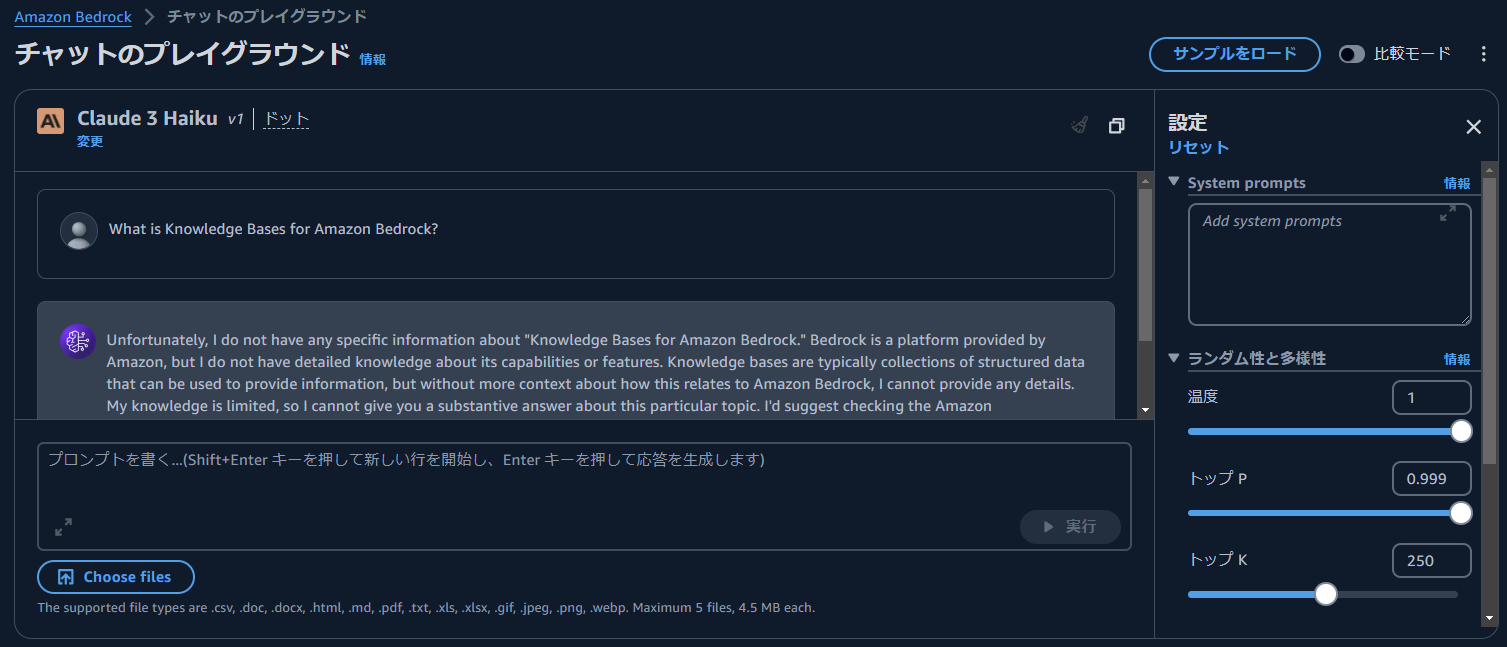
以下に,Claude3 Haiku の回答を示します.Claude3 Haiku の事前学習データに Knowledge Bases for Amazon Bedrock に関する情報が含まれていないことを示唆する回答が得られました.fine-tuning したモデルの回答結果と比較すると,fine-tuning の効果が確認できます.
Unfortunately, I do not have any specific information about "Knowledge Bases for Amazon Bedrock." Bedrock is a platform provided by Amazon, but I do not have detailed knowledge about its capabilities or features. Knowledge bases are typically collections of structured data that can be used to provide information, but without more context about how this relates to Amazon Bedrock, I cannot provide any details. My knowledge is limited, so I cannot give you a substantive answer about this particular topic. I'd suggest checking the Amazon documentation or other reliable sources to learn more about Amazon Bedrock and any associated knowledge base capabilities.
AWS SDK for Python (Boto3) で実行
AWS SDK for Python (Boto3) を利用し,API 経由でインポートしたモデルを呼び出すことも可能です.具体的には,Amazon Bedrock の InvokeModel API を利用し,引数の modelId にインポートしたプロビジョンドスループットの ARN を指定することで,推論を行えます.
import json
import boto3
model_id = "<provisioned throughput arn>"
system_prompt = "You are a high-performance QA assistant that responds to questions concisely, accurately, and appropriately."
prompt = "What can you do with Amazon Bedrock?"
client = boto3.client(service_name="bedrock-runtime", region_name="us-west-2")
response = client.invoke_model(
body=json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 2048,
"messages": [{"role": "user", "content": f"{prompt}"}],
"temperature": 0.1,
"top_p": 0.9,
"system": f"{system_prompt}",
}
),
modelId=model_id,
)
output = response.get("body").read().decode("utf-8")
response_body = json.loads(output)
response_text = response_body["content"][0]["text"]
print(response_text)
上記のコードを実行すると、以下が出力されました。What can you do with Amazon Bedrock? という質問に対して,適切な回答が得られています.
Amazon Bedrock is a fully managed service that enables developers to build, deploy, and scale generative AI applications quickly and easily. With Amazon Bedrock, you can create generative AI applications that can generate human-like text, images, code, and other content, as well as engage in open-ended conversations and complete a variety of tasks.
モデルの評価
fine-tuning したモデルを評価するため,評価用データセットを作成し,LLM-as-a-Judge によって評価を行いました.
設定
評価用データセットは QA 形式で作成し,質問に対する想定回答を事前に 4 つ用意しました.以下に,今回の評価で用いた質問を示します.
- What can you do with Amazon Bedrock?
- What is Knowledge Bases for Amazon Bedrock?
- What are Agents for Amazon Bedrock?
- What are Guardrails for Amazon Bedrock?
また,比較手法として,fine-tuning 前の Claude3 Haiku (以降,Base model と呼ぶ) を用いました.
評価指標
評価指標として,LLM-as-a-Judge による Correctness (正確性) を利用しました.LLM-as-a-Judge の実行には,LangChain の Scoring Evaluator の evaluate_strings メソッドを利用しました.evaluate_strings メソッドを利用することで,LangChain で用意されている様々な評価指標を用いて LLM-as-a-Judge で評価することが可能です.定量評価のため,LLM の推論結果に対して 1~10 のスコアを付ける labeled_score_string を利用し,評価用の LLM として,Claude3.5 Sonnet を利用しました.
結果
以下に,モデル毎の 4 つの質問に対する Correctness (正確性) の平均値を示します.fine-tuning したモデルの方が,Base model よりも正確性が高く,評価値としても比較的良好であることが確認できます.
| Model | Correctness (平均) |
|---|---|
| Fine-tuning model | 7.0 / 10.0 |
| Base model (Claude3 Haiku) | 2.5 / 10.0 |
以降,fine-tuning の効果を確認するため,質問毎の評価値と,各モデルの回答内容を観察します.
質問毎の評価値
以下に,質問毎の Correctness の評価値を示します.fine-tuning したモデル は,項番 1, 2, 4 の質問については高い正確性を示していますが,項番 3 の質問については,低い正確性となっています.Base model については,全体的に正確性が低いことが確認できます.
| # | 質問 (プロンプト) | Correctness (Fine-tuning model) | Correctness (Base model) |
|---|---|---|---|
| 1 | What can you do with Amazon Bedrock? | 8.0 / 10.0 | 3.0 / 10.0 |
| 2 | What is Knowledge Bases for Amazon Bedrock? | 8.0 / 10.0 | 2.0 / 10.0 |
| 3 | What are Agents for Amazon Bedrock? | 4.0 / 10.0 | 2.0 / 10.0 |
| 4 | What are Guardrails for Amazon Bedrock? | 8.0 / 10.0 | 3.0 / 10.0 |
質問毎の回答内容
以下に,質問毎の各モデルの回答内容を示します.fine-tuning したモデルの回答内容は,Base model と比較すると適切な内容となっていることが確認できます.特に,Correctness の高かった項番 1, 2, 4 の回答の品質は高いです.一方,項番 2 や項番 3 の回答の一部にハルシネーションが見られます.また,項番 3 の回答内容について,他の項番と比較すると情報量が乏しく,あまり適切に回答することができていないことがわかります.
Base model の回答内容を観察すると,項番 2, 3 では,「そのような知識は持っていない」と回答しています.また,その他の項番の回答についてもハルシネーションが非常に多く見られ,全体的に Correctness が低いことが確認できます.
以上の結果から,fine-tunning により,Claude3 Haiku に Amazon Bedrock の知識をある程度獲得させることができていると考えられます.
| # | 質問 (プロンプト) | Fine-tuning model の回答 | Base model の回答 |
|---|---|---|---|
| 1 | What can you do with Amazon Bedrock? | Amazon Bedrock is a fully managed service that provides a quick, effective, and secure path to building generative AI applications powered by foundation models from Amazon, Anthropic, Stability AI, Cohere, and other integrated providers. It simplifies the creation and deployment of cutting-edge customized models and foundational models for a wide range of natural language processing (NLP), text-to-image, and speech-to-text use cases, all while focusing on security, data privacy, and responsible AI. | Amazon Bedrock is a platform that provides developers with a set of tools and services to build, deploy, and manage conversational AI applications. Here are some of the key things developers can do with Amazon Bedrock: 1. Build conversational AI models: Bedrock provides access to pre-trained language models that can be fine-tuned for various natural language processing (NLP) tasks, such as text generation, intent detection, and entity extraction. 2. Deploy and manage models: Bedrock makes it easier to deploy and manage conversational AI models by providing a scalable, cloud-based infrastructure. Developers can use Bedrock to host, monitor, and update their models. |
| 2 | What is Knowledge Bases for Amazon Bedrock? | Knowledge Bases for Amazon Bedrock is a feature that allows you to seamlessly integrate structured and unstructured data sources into your large language model (LLM) applications built on Amazon Bedrock. This feature enables you to enhance the context and knowledge available to your models, leading to more informed and relevant responses. With Knowledge Bases for Amazon Bedrock, you can connect your LLM applications to a variety of data sources, including databases, content management systems, enterprise applications, and file storage services. The feature supports a wide range of data formats, including structured data (e.g., CSV, Excel, SQL), unstructured data (e.g., PDF, Word, HTML), and semi-structured data (e.g., JSON, XML). |
Unfortunately, I do not have any specific information about "Knowledge Bases for Amazon Bedrock." Bedrock is a platform provided by Amazon, but I do not have detailed knowledge about its capabilities or features. Knowledge bases are typically collections of structured data that can be used to provide information, but without more context about how this relates to Amazon Bedrock, I cannot provide any details. My knowledge is limited, so I cannot give you a substantive answer about this particular topic. I'd suggest checking the Amazon documentation or other reliable sources to learn more about Amazon Bedrock and any associated knowledge base capabilities. |
| 3 | What are Agents for Amazon Bedrock? | Agents for Amazon Bedrock are pre-built AI agents like Claude or Exporter that can be easily added via APIs while maintaining flexibility and customization. They are ready-to-use capabilities for rapid development of conversational AI apps and workflows. | I do not have any specific information about "Agents for Amazon Bedrock". Amazon Bedrock is a machine learning platform, but I don't have details on what "Agents" may refer to in that context. My knowledge is limited, so I cannot provide a more complete answer about this. You may need to check Amazon's documentation or other resources for more information about the features and capabilities of the Amazon Bedrock platform. |
| 4 | What are Guardrails for Amazon Bedrock? | Guardrails for Amazon Bedrock is a feature that allows you to manage and mitigate potential risks associated with the use of large language models (LLMs) in various applications. Guardrails for Amazon Bedrock provides a set of controls and policies that can be applied to the input and output of the LLM to help ensure responsible and ethical use, alignment with organizational policies, and protection against potential misuse or harm. These controls can include content filtering, sensitive data detection, profanity filtering, hate speech detection, and other safeguards. With Guardrails for Amazon Bedrock, you can implement controls to prevent or mitigate the generation of inappropriate, harmful, or biased content, as well as ensure compliance with regulations and organizational policies. |
Guardrails for Amazon Bedrock are a set of default security and compliance configurations that help protect Bedrock models and deployments. They are designed to provide a secure baseline for Bedrock usage and help customers adhere to best practices and industry standards. Some key features of Bedrock Guardrails include: 1. Encryption: Guardrails ensure that all data stored and transmitted by Bedrock is encrypted at rest and in transit using industry-standard encryption protocols. 2. IAM-based access control: Guardrails enforce strict access control policies using AWS Identity and Access Management (IAM), ensuring that only authorized users and services can interact with Bedrock resources. |
考察
fine-tuning したモデルで観察された点について考察します.
項番 3 の回答の正確性について
fine-tuning したモデルの項番 3 の回答内容は,他の項番の回答内容に比べて文量が少なく,情報量が乏しいことが確認されました.項番 3 の質問内容は,Agents for Amazon Bedrock に関する質問であり,他の項番の質問と比べても複雑な質問ではありません.項番 3 以外の質問にはかなり正確に回答できている点を踏まえると,Agents for Amazon Bedrock の知識をうまく獲得できていないことが考えられます.この原因は,fine-tuning に用いたデータセットで,Agents for Amazon Bedrock に関する情報が不足していたためでした.
訓練データにおける,Agents for Amazon Bedrock に関する QA ペア数を確認したところ,85 個中 1 個のみで,単語としての出現数は 2 回のみでした.項番 1, 2, 4 に関する QA ペア数は 最低 7 個以上あり,単語としての出現数も 14 回以上ありました.これらの結果から,Agents for Amazon Bedrock に関するデータが不足していることが確認できます.
本課題を解決するためには,Agents for Amazon Bedrock に関する QA ペアを増やす必要があると考えられます.
回答の品質について
fine-tuning したモデルの回答の Correctness が高いことを確認しましたが,詳細に確認すると一部ハルシネーションが含まれていました.この原因としては,訓練データのサイズが小さく,知識獲得のためのデータが不足していることが考えられます.
本課題については,品質の高いデータセットを追加で用意することで,回答の正確性が向上し,結果的にハルシネーションを減らすことができると考えられます.また,LLM-as-a-Judge では,これらのハルシネーションを正確に検出することが難しいため,人手での評価も必要であると考えられます.
出力形式について
本検証の Base model に限らず,Claude3 Haiku の回答には,番号付きリスト (箇条書き) が多用されますが,fine-tuning したモデルの回答内容には含まれていません.これは,番号付きリストのデータが含まれておらず,QA 形式でのデータで学習した結果,回答の出力形式にも影響が出たと考えられます.
評価時のコード
参考のため,今回の検証で利用したコードを掲載します.fine-tuning したモデルの回答内容,Base model (Claude3 Haiku)の回答内容,および,評価用のラベルデータを外部ファイルに保存しておき,それらを読み込み,LangChain で評価を行っています.
Python実装(折り畳めます)
import argparse
import json
from langchain.evaluation import Criteria, EvaluatorType, load_evaluator
from langchain_aws import ChatBedrock
def get_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument(
"--prediction-file",
type=str,
default="../../dataset/eval/fine-tuning-model_prediction.json",
)
parser.add_argument(
"--label-file",
type=str,
default="../../dataset/eval/label.json",
)
return parser.parse_args()
def load_json(file_path: str) -> list:
with open(file_path, "r") as f:
return json.load(f)
def llm_as_a_judge(predictions: list, labels: list) -> None:
model = ChatBedrock(
model_id="anthropic.claude-3-5-sonnet-20240620-v1:0",
region_name="us-east-1",
model_kwargs={
"temperature": 0.0,
},
)
evaluator = load_evaluator(
evaluator=EvaluatorType.LABELED_SCORE_STRING,
criteria=Criteria.CORRECTNESS,
llm=model,
)
scores = []
for prediction, label in zip(predictions, labels):
# print(f"Prediction: {prediction}, Label: {label}")
eval_result = evaluator.evaluate_strings(
prediction=prediction["answer"],
reference=label["answer"],
input=label["question"],
)
print(eval_result)
print(eval_result["score"])
scores.append(eval_result["score"])
score_average = sum(scores) / len(scores)
print(f"Average score: {score_average}")
def main(args: argparse.Namespace) -> None:
predictions = load_json(args.prediction_file)
labels = load_json(args.label_file)
llm_as_a_judge(predictions, labels)
if __name__ == "__main__":
args = get_args()
main(args)
補足: 利用する評価指標について
本検証の評価指標として LLM-as-a-Judge の Correctness を利用しましたが,文章生成タスクで利用される評価指標には,ROUGE, BLEU, BERTScore などがあります.特に,BERTScore は,事前学習済みの BERT から得られる文脈化トークン埋め込みを利用し,テキスト間の類似度を計算する評価指標であり,文章生成や要約タスクではよく利用されております.検証時に BERTScore でも評価を行っていたため,その結果を以下に示します.以下の表では,各モデルでの Precision, Recall, F1 Score の平均値を示しています.
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Fine-tuning model | 0.74 | 0.76 | 0.75 |
| Base model (Claude3 Haiku) | 0.67 | 0.71 | 0.69 |
LLM-as-a-Judge の Correctness の結果と同様,fine-tuning したモデルの方が Base model よりも評価値が高く,想定回答に似た文章を生成できていることが確認できます.また,各モデルにおいて,Precision よりも Recall が高い傾向にあります.この原因は,回答文が長く,参照文(想定回答)に含まれる単語の類似表現が比較的多く含まれていたためです.(ROUGE-1 を確認したところ,Precision よりも Recall が高い傾向でした.)
一方,Base model の評価値はそこまで悪い値ではありませんでした.この原因は,回答内容にハルシネーションを多く含む場合でも,回答文中の単語やその類似単語が参照文(想定回答)に多く含まれているためだと考えています.
今回の検証では,LLM-as-a-Judge のみで評価を行いましたが,意味的類似性の観点で BERTScore を,論理的整合性や事実的正確性の観点で LLM-as-a-Judge の Correctness を併用することで,より多角的な評価が可能になると考えられます.
参考に,BERTScore の評価コードを以下に示します.
Python実装(折り畳めます)
import argparse
import json
from bert_score import score
def get_args() -> argparse.Namespace:
parser = argparse.ArgumentParser()
parser.add_argument(
"--prediction-file",
type=str,
default="../../dataset/eval/fine-tuning-model_prediction.json",
)
parser.add_argument(
"--label-file",
type=str,
default="../../dataset/eval/label.json",
)
return parser.parse_args()
def load_json(file_path: str) -> list:
with open(file_path, "r") as f:
return json.load(f)
def get_target_sentences(qa_list: list) -> list:
sentences = []
for qa in qa_list:
sentences.append(qa["answer"])
return sentences
def calc_bert_score(cands: list, refs: list) -> tuple:
Precision, Recall, F1 = score(cands, refs, lang="ja", verbose=True)
return Precision.numpy().tolist(), Recall.numpy().tolist(), F1.numpy().tolist()
def bert_score(predictions: list, labels: list) -> None:
cands = get_target_sentences(predictions)
refs = get_target_sentences(labels)
P, R, F1 = calc_bert_score(cands, refs)
for p, r, f1 in zip(P, R, F1):
print(f"precision: {p}, recall: {r}, f1_score: {f1}")
print(f"Average precision: {sum(P) / len(P)}")
print(f"Average recall: {sum(R) / len(R)}")
print(f"Average f1_score: {sum(F1) / len(F1)}")
def main(args: argparse.Namespace) -> None:
predictions = load_json(args.prediction_file)
labels = load_json(args.label_file)
bert_score(predictions, labels)
if __name__ == "__main__":
args = get_args()
main(args)
補足: 日本語での実験
日本語で Amazon Bedrockについて教えて と質問した場合の回答を確認しました.
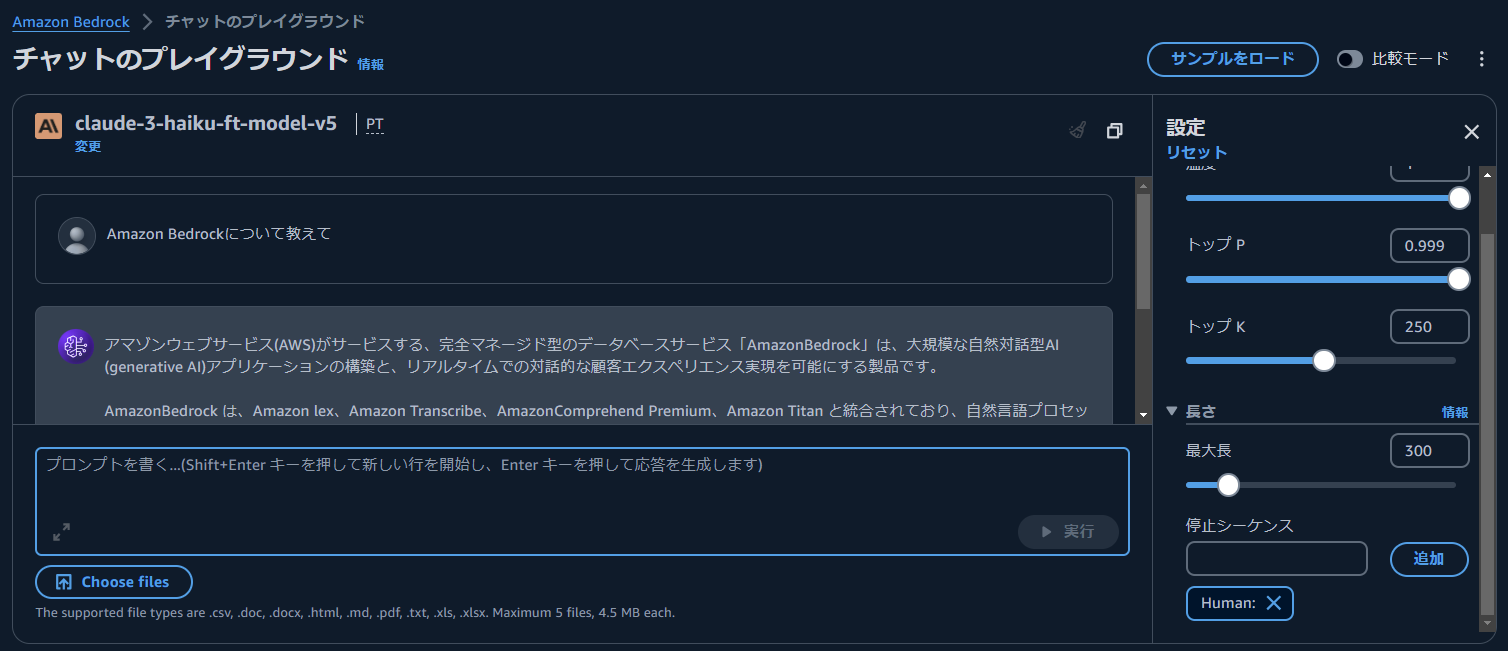
以下に fine-tuning したモデルの回答を示します.英語の場合と比較すると,ハルシネーションが多く見られます.また,大規模な自然対話型 AI という不自然な単語も利用されており,回答の品質としては低いです.日本語での対話を自然に行うためには,日本語のデータセットを追加で用意する必要があると考えられます.
アマゾンウェブサービス(AWS)がサービスする、完全マネージド型のデータベースサービス「AmazonBedrock」は、大規模な自然対話型 AI (generative AI)アプリケーションの構築と、リアルタイムでの対話的な顧客エクスペリエンス実現を可能にする製品です。
AmazonBedrock は、Amazon lex、Amazon Transcribe、AmazonComprehend Premium、Amazon Titan と統合されており、自然言語プロセッシング (NLP)、音声変換、感情分析、ドキュメントランダム化などの広範囲にわたるジェネレーティブ AI 機能を提供しています。
また、AmazonChatGPT、AmazonPaLM、Amazon Anthropic Charles などの LLM を統合し、ハイパフォーマンスな自然対話型 AI 体験を実現します。
まとめ
本稿では,Amazon Bedrock 上で Claude3 Haiku を fine-tuning する方法を紹介し,実際に fine-tuning したモデルを評価しました.データセットとして,Amazon Bedrock FAQs のデータを利用し,検証データを Bedrock Converse API の Document chat と Json mode を利用して作成しました.モデルの評価では,評価指標として,LLM-as-a-Judge の Correctness および BERTScore を利用しました.評価の結果,fine-tuning により,Amazon Bedrock の知識獲得に成功していることを確認しました.
一方,ランニングコストの観点では,Claude3 Haiku のプロビジョンドスループットの費用はかなり高額な印象を受け,現時点では RAG の方がコストパフォーマンスが高いと感じました.(6 ヶ月の契約でも 1 ヶ月あたり $48180.)しかし,Claude3 Haiku のような高性能なモデルを fine-tuning することができる点は非常に魅力的であり,今後の改善が期待されます.
本検証では小規模なデータセットでの fine-tuning を行いましたが,より大規模なデータセットを利用することで精度が向上する可能性があります.本記事を参考に,是非試してみて下さい.
仲間募集
NTT データ デジタルサクセスコンサルティング事業部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL 領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様の DX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobot をはじめとした AI ソリューションやサービスを使って、
お客様の AI プロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内での AI 活用を拡大、NTT データが提供する AI ソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearning などデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高く DX 推進を実現できます。
TDF-AM(Trusted Data FoundationⓇ - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援 (Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様の DX を成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AM は、データ活用を Quick に始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用は NTT データが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズから AI/BI などのデータ活用支援に至るまで、End to End で課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームの Tableau と 2014 年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに 2019 年度には Salesforce とワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまで Partner of the Year, Japan を 4 年連続で受賞しており、2021 年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020 年度からは、Tableau を活用したデータ活用促進のコンサルティングや導入サービスの他、AI 活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx 導入の豊富な実績を持つ NTT データは、最高位にあたる Alteryx Premium パートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryx を活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTT データは DataRobot 社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストが AI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として 10 年以上取り組んできたプロ集団である NTT データは、データマネジメント領域でグローバルでの高い評価を得ている Informatica 社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTT データではこれまでも、独自ノウハウに基づき、ビッグデータ・AI など領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflake は、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTT データはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。