AutoTrain🚂🚂🚂とは
ノーコードでテキスト分類や要約や構造化データの機械学習などがstate-of-the-artできるサービスです。本日より構造化データもサポートされました🎉
AutoNLPだとググラビリティが低かったのではなく、構造化データもサポートしたかったから名称変更したようです。
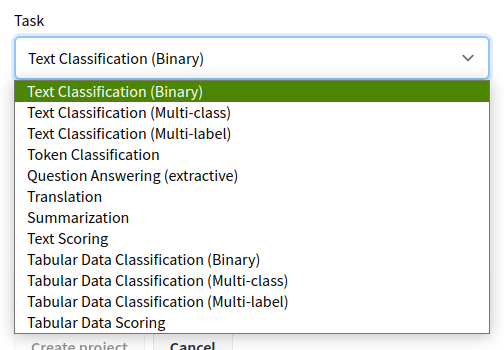
データ準備
アヤメの品種を花びらの長さやがくの幅から3品種に分類します。
CSVファイルをダウンロードしましょう。
wget https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv

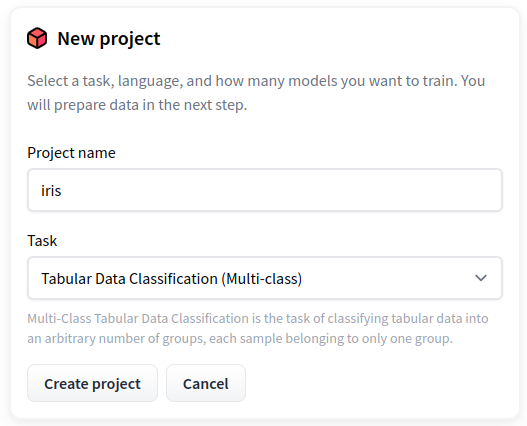
プロジェクトの作成
Tabular Data Classification (Binary) を選択し、プロジェクトを作成します。
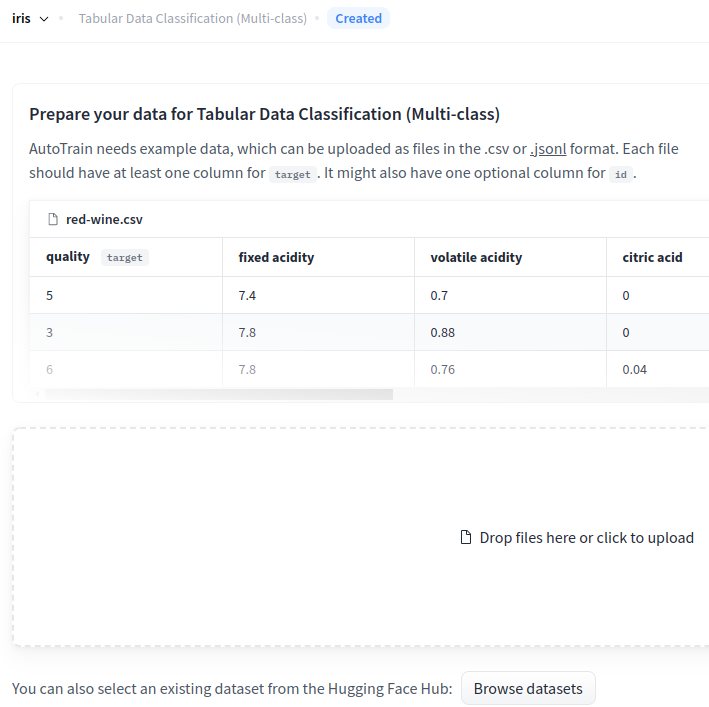
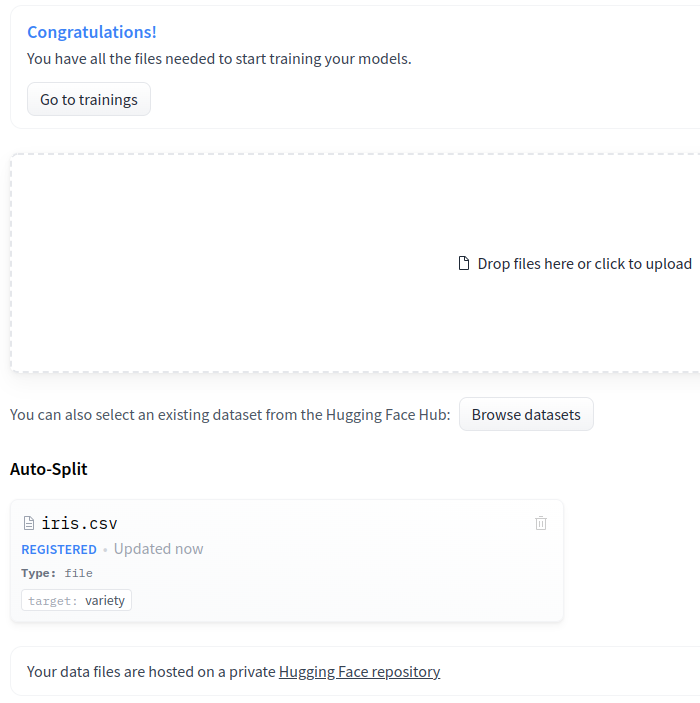
csvファイルをアップロード
jsonlでもアップロードできます。
今回はcsvファイルをドラッグ・アンド・ドロップし、target:varietyカラムを選択し、プロジェクトに追加します。
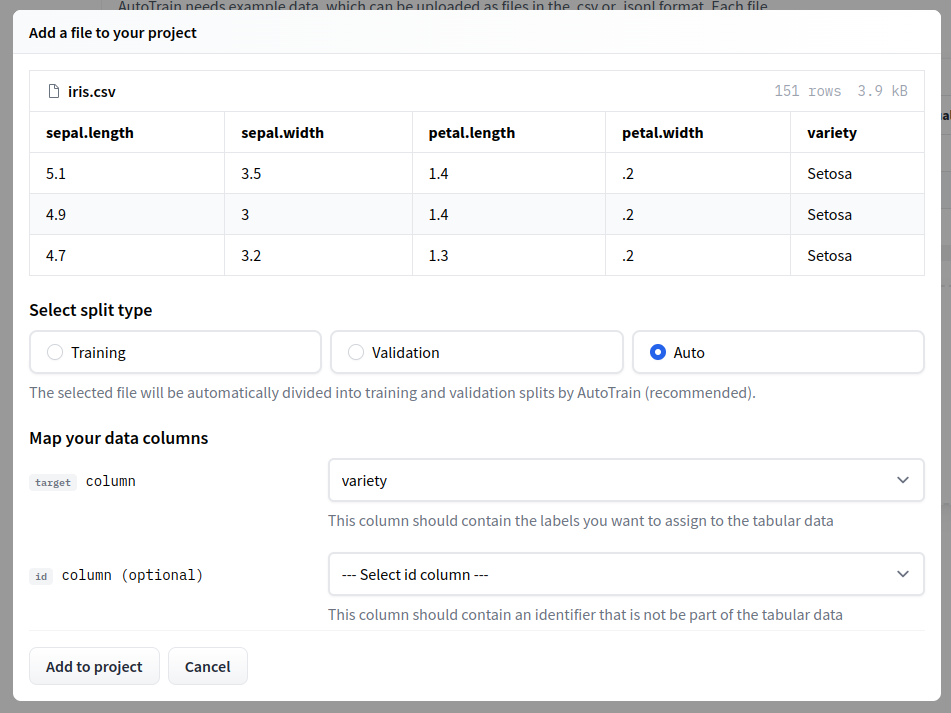
Go to trainingsをクリックします。
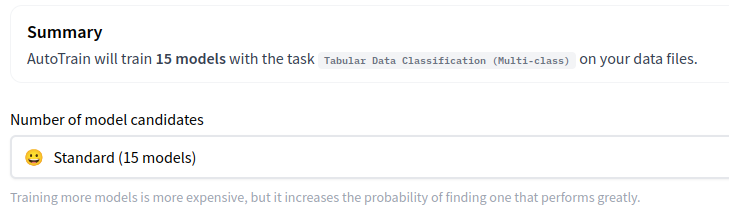
学習
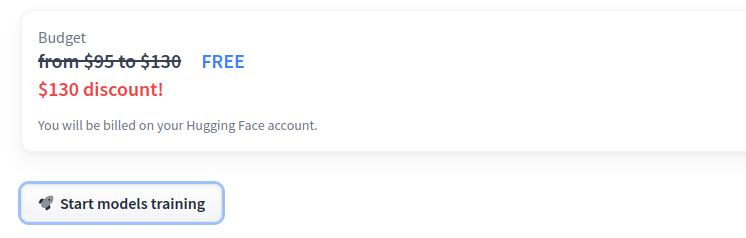
Start models trainingsをクリックします。
推論
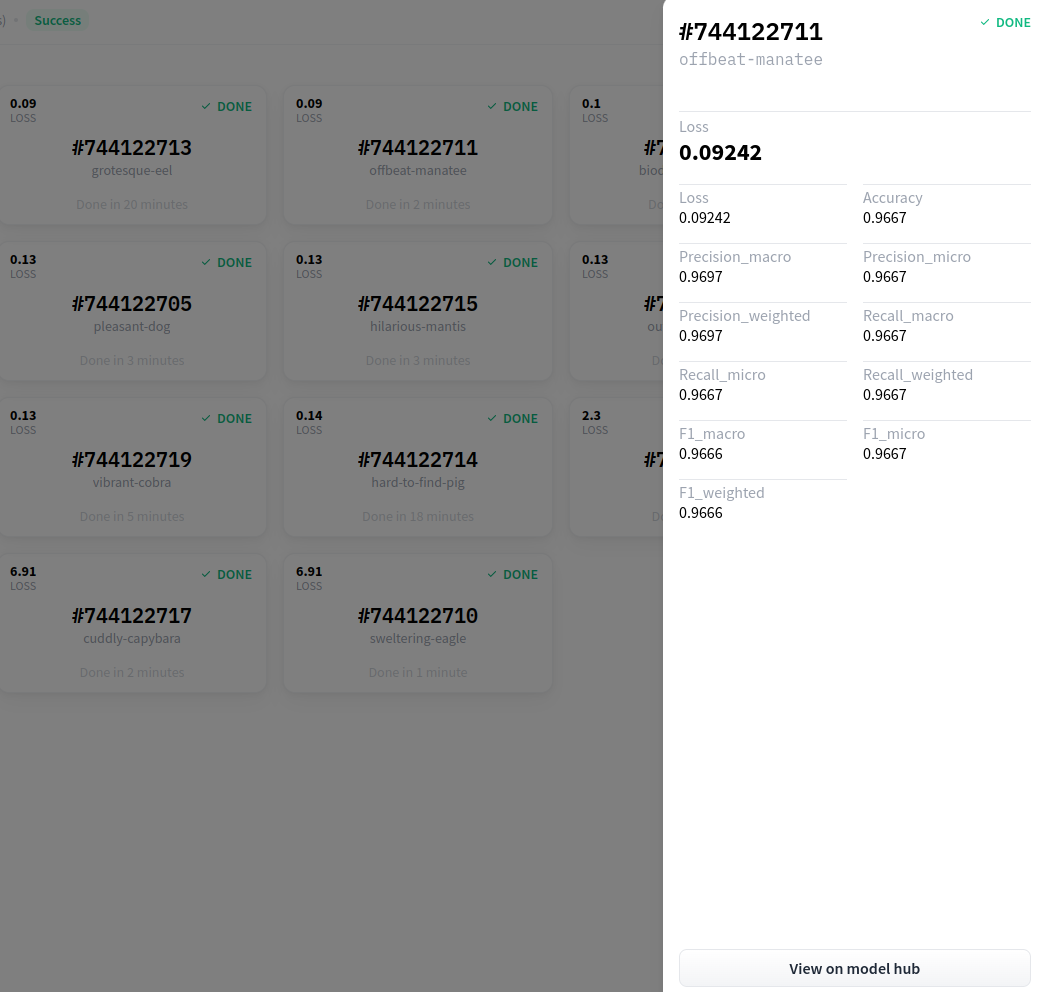
96%の精度で分類できました。modelをクリックし、model hubで推論できます。
AutoTrainは決定木を使っているのでxgboostと同じくらいの精度ですね
モデルをダウンロード
モデルをダウンロードすることでオフラインで推論できます。
モデルをダウンロード
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
!sudo apt-get -qq install git-lfs
!git lfs install
#!git clone "https://$USERNAME:$PASSWORD@huggingface.co/vabadeh213/autotrain-iris-744122711" # set username/password for private model
!git clone https://huggingface.co/vabadeh213/autotrain-iris-744122711
joblibで推論
import json
import joblib
import pandas as pd
model = joblib.load('model.joblib')
config = json.load(open('config.json'))
features = config['features']
df = pd.read_csv('iris.csv')
X = df[features]
X.columns = X.columns.map(lambda x: 'feat_' + x)
predictions = model.predict(X) # or model.predict_proba(data)
df['predicted'] = [{v: k for k, v in config['target_mapping'].items()}[i] for i in predictions]
df
| sepal.length | sepal.width | petal.length | petal.width | variety | predicted |
|---|---|---|---|---|---|
| 5.2 | 4.1 | 1.5 | 0.1 | Setosa | Setosa |
| 5.6 | 3 | 4.5 | 1.5 | Versicolor | Versicolor |
| 5.3 | 3.7 | 1.5 | 0.2 | Setosa | Setosa |
| 6.5 | 3 | 5.8 | 2.2 | Virginica | Virginica |
まとめ
- クレカ登録しない限り無料で使えてとても便利
- ノーコードで高性能なモデルを作れる