TrOCRとは
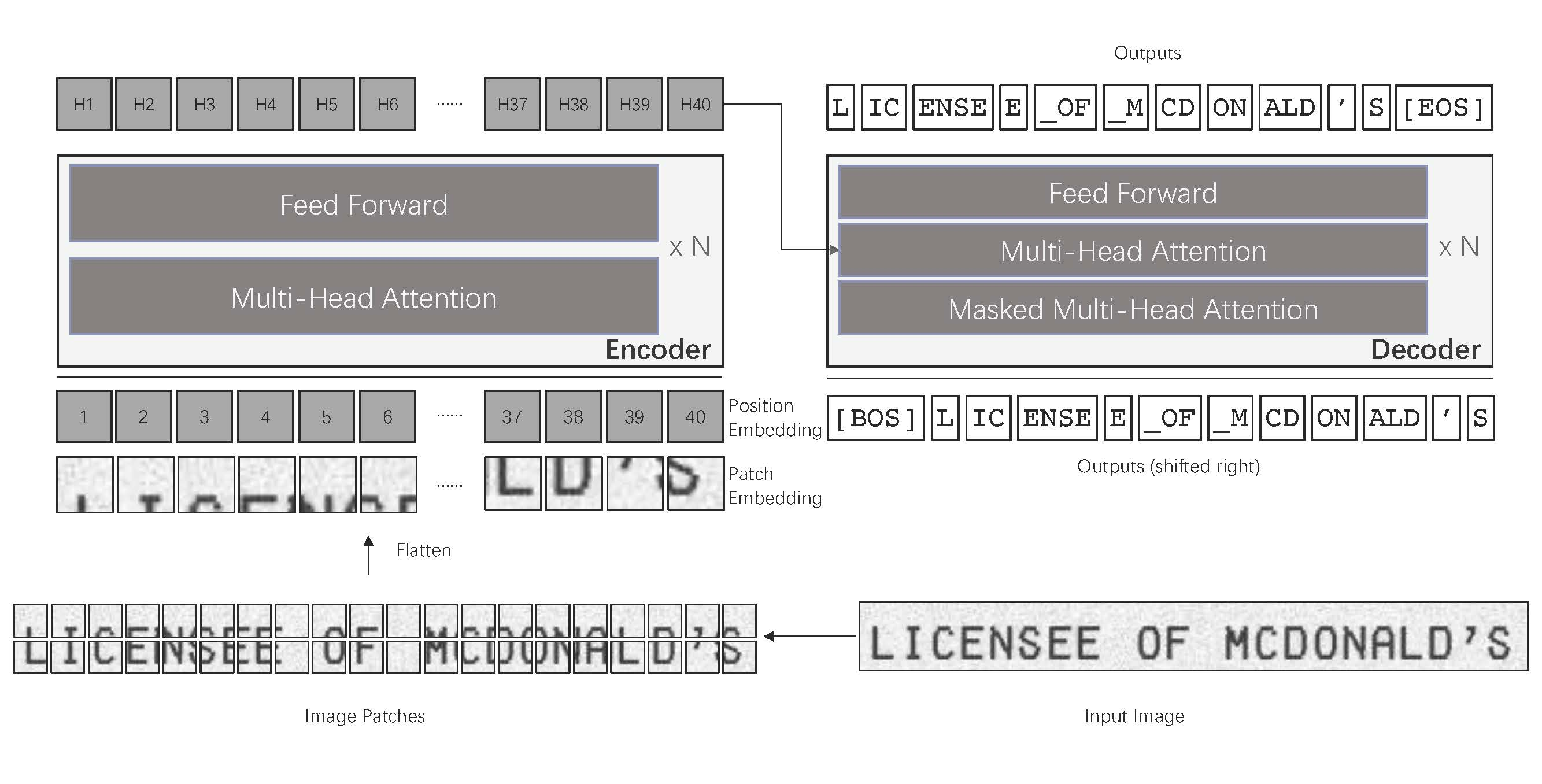
VisionTransformerとRoBERTaを合体させてEnd2EndでOCRするアプローチです
Captchaでファインチューニングしてみた
コードはこちら
https://colab.research.google.com/drive/14MfFkhgPS63RJcP7rpBOK6OII_y34jx_?usp=sharing

画像を用意
!wget https://github.com/AakashKumarNain/CaptchaCracker/raw/master/captcha_images_v2.zip
!unzip -q captcha_images_v2.zip
OCRProcessorを準備
from transformers import TrOCRProcessor
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-small-printed")
TrOCRProcessorは、特徴抽出器とトークナイザをラップしただけです。任意の特徴抽出器とトークナイザを使えます。google/vit-base-patch16-224-in21k や cl-tohoku/bert-base-japaneseなど
事前学習モデルを選択
事前学習モデルが9種類ありますが、すべて10epochsほど試し一番いいので学習させるのがよいかもです。
from transformers import VisionEncoderDecoderModel
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-small-printed")
model.to(device)
Train
from transformers import AdamW
from tqdm.notebook import tqdm
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(200): # loop over the dataset multiple times
# train
model.train()
train_loss = 0.0
for batch in tqdm(train_dataloader):
# get the inputs
for k,v in batch.items():
batch[k] = v.to(device)
# forward + backward + optimize
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss += loss.item()
print(f"Loss after epoch {epoch}:", train_loss/len(train_dataloader))
# evaluate
model.eval()
valid_cer = 0.0
with torch.no_grad():
for batch in tqdm(eval_dataloader):
# run batch generation
outputs = model.generate(batch["pixel_values"].to(device))
# compute metrics
cer = compute_cer(pred_ids=outputs, label_ids=batch["labels"])
valid_cer += cer
total_cer = valid_cer / len(eval_dataloader)
print("Validation CER:", total_cer)
if total_cer < 0.005:
import datetime
save_pretrained_dir = f'drive/MyDrive/{total_cer}_{epoch}_{datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=9),"JST")).strftime("%Y%m%dT%H%M%S")}'
model.save_pretrained(save_pretrained_dir)
model.save_pretrained(".")
良いモデルが出来たら、GoogleDriveに退避させてColabがいつ終了してもいいようにしときましょう。TensorFlowみたいにrestore_best_weightsがあればいいのですが...
バッチサイズ
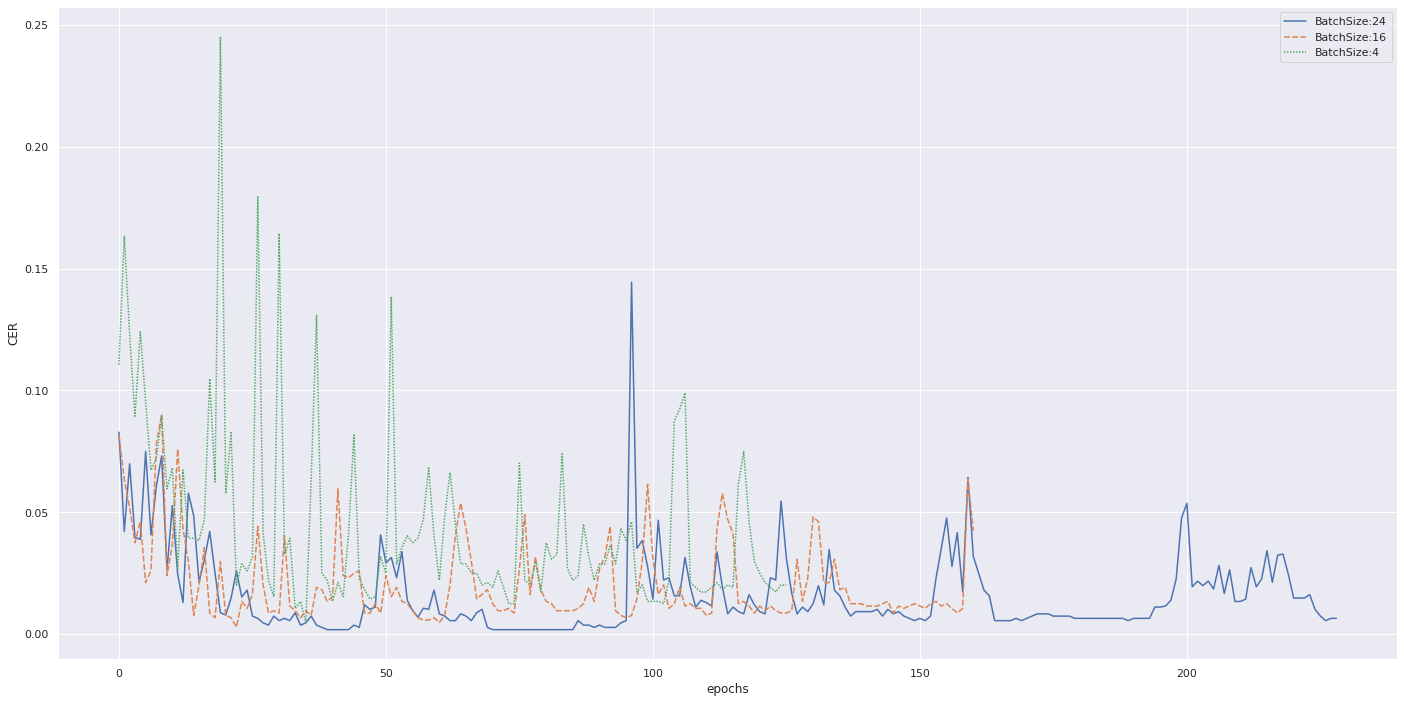
大きいバッチサイズを使うことで速く学習でき、精度もよいです。
-
batch size: 24P100 -
batch size: 16K80 -
batch size: 4K80
上記構成で試しました。Colab Pro+してますが、GPUガチャ運が悪くV100/A100が出ません![]()
既存手法との比較
| CNN+BiLSTM+CTC | TrOCR | |
|---|---|---|
| CER | 3.84 | 0.18 |
| 認識精度(100-CER) | 96.16% | 99.82% |
CER(Character Error Rate)

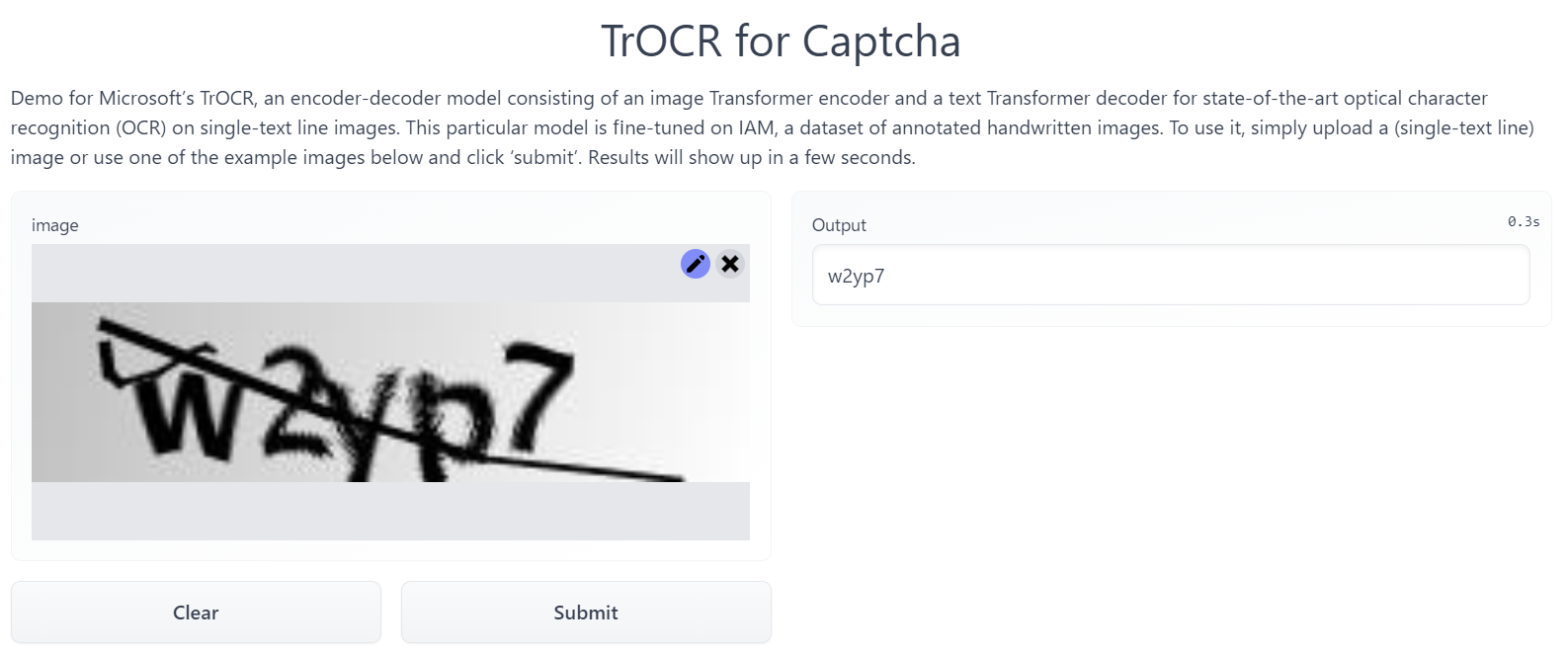
デモ
Hugging Space作成しました。ぜひ、試してみてください。300msぐらいで結果が返ってきます。largeのモデルだと5sくらいでした
https://huggingface.co/spaces/tomofi/trocr-captcha
まとめ
- 自然な文章ではなく、ランダムな文字列でもOCRできた
- バッチサイズがでかい方が学習が速く、精度も高い
- 日本語のモデルもMSから公開されるらしい https://github.com/microsoft/unilm/issues/619
TrOCR著者の方にツイートいただきました![]()
https://twitter.com/wolfshowme/status/1502685497616863234