概要
情報検索・検索エンジン Advent Calendar 2019 の二日目の記事です。この記事では現在の主流になっている手法やその問題の背景を眺めつつ、最近の情報検索のトレンドを知ることがゴールになります。
(追記) 単語の独立性に関する記述の追加とNeural Index Constructionの論文の実装をして可視化をした英訳をこちらに投稿しました: From Cranfield Experiments to Neural Information Retrieval
情報検索の始まりと発展
情報検索の歴史はCyril Cleverdonによって1960年代から繰り返し行われたクランフィールド検索実験に遡り、Vector Space Modelの発明とその論文の中でTF-IDFを導入したことで情報検索の父と呼ばれるGerard Saltonは1968年に「情報検索は情報の生成、格納、分類、解析、検索に関する諸問題を扱う学問である」と定義されました。それから60年の月日が流れ、そのアプリケーション形態は図書検索、デスクトップ検索、ソーシャルメディア、モバイル検索、質問応答、チャットボットとよって時代によって変化してきました。またその変化に追随するように研究のトレンドも変わってきました。

Approaches to Research in IR (PDF)
ここ数年ではNeural Information Retrieval (Neural IR)、機械翻訳や音声認識やコンピュータビジョンの分野で大きな成果をもたらしたニューラルネットワークを情報検索に応用する研究のトレンドが顕著になっており、その傾向は SIGIR (Special Interest Group on Information Retrieval) で採択されたNeural IRの論文の比率からも見て取れます。

An Introduction Neural Information Retrieval
Googleが1ヶ月前に公開した記事 Understanding searches better than ever before では昨年Googleが公開したContextualized Language ModelのBERTをGoogle検索に使い始めたということで話題になりました。従来は助詞や接続詞のようなBag-of-Wordsモデルにおいては関連度を推定する上でノイズになるとされて捨てられていた語が、新しい手法では文脈を理解する上で重要な役割を果たすようになりました。このように検索を取り巻く環境は日々変化しており、私もキャッチアップする必要を感じていたので、概要を一緒に眺めてみましょう。
これまでの情報検索
最近の手法を見る前に提案の背景を理解するために、おそらく現在の主流であろうBag-of-WordsとBM25による検索システムの実装を見てみます。ここに以下の二つの文章があるとします。
- Doc1: The quick brown fox jumps over the lazy dog
- Doc2: Fox News is the number one cable news channel
この転置インデックスは以下のようになります。
| Term | Doc1 | Doc2 |
|---|---|---|
| quick | x | |
| brown | x | |
| fox | x | x |
| jumps | x | |
| over | x | |
| lazy | x | |
| dog | x | |
| number | x | |
| one | x | |
| cable | x | |
| news | x | |
| channel | x |
このテーブルからクエリが「quick」ならDoc1が「news」ならDoc2が「fox」なら両方の文書が関連しているドキュメントとして候補になることがわかります。ドキュメントを絞り込んだ後どのように並べるかですが、おおまかに分けるとクエリと文書をベクトルに変換して類似度を比較するVector Space Modelと、関連度を文書とクエリが与えられたときの条件付き確率 $P(rel \mid q, d)$ と定義するProbabilistic Modelがあります。その中でも70年代に発明されたBM25というアルゴリズム ("Best Matching" の頭文字) はElasticsearchに採用されていることもあり広く使われているので、検索に携わっている方ならば一度はこの式を見たことがあるのではないでしょうか。
$$
BM25(q, d) = \sum_{t_{q} \in q} idf(t_{q}) \cdot \frac{tf(t_{q}, d) \cdot (k_{1}+1)}{tf(t_{q}, d)+k_{1} \cdot (1-b+b \cdot \frac{|d|}{argdl})}
$$
BM25の理論的背景はやや複雑なので、気になった方は「Binary Independence Model」「Eliteness」「Two-Poisson Model」などで検索してみてください。ここではBM25は以下の仮定に基づいているということを覚えておきましょう。
- 仮定1: ユーザのニーズと文書の関連度はクエリのみによって決まる
- 仮定2: 文書に出現する単語は互いに独立している
2000年代に入るとLanguage Modelを情報検索に取り入れる研究が盛んになり始めました。この手法では、各文書をある言語モデルのサンプルとみなし、与えられたクエリがその文書を生成しそうか、という事後確率でランク付けをします。それをベイズの定理を使い、$P(q)$ はすべての文書に対して同じで、かつ $P(d)$ がuniformだと仮定すると
$$
P(d|q) = \frac{P(q|d)P(d)}{P(q)} \propto P(q|d)P(d) = P(q|d)
$$
$P(q|d)$ はクエリが文書 $d$ からランダムにサンプルされる確率を示しています。クエリ内の単語の出現確率が独立していると仮定すると
$$
P(q | d) = \prod_{t_q \in q} P(t_q | d)
$$
となり、文書に対するクエリ内の単語の出現確率は以下のとおりです。
$$
P(t_q | d) = \frac{tf(t_q, d)}{|d|}
$$
実際にはsmoothingを行なったりするためバリエーションがあります。参考: A Comparative Study of Probabilistic and Language Models for Information Retrieval
これらの手法は提案された時代では、ユースケースとして司書の図書検索やパラリーガルの法的書類の検索などが想定されており、これらの手法は純粋な文書検索においてはうまくいっていました。しかし「単語が互いに独立している」や「関連度はクエリによってのみ決まる」という仮定と、誰が検索するのか、何を検索するのか、どのように検索するのかなどの現実のアプリケーションの性質が変わってきたため、それに合わせて新しい仮定やモデルが求められるようになってきました。いくつか現代の検索アプリが抱える問題を見ていきましょう。
スペルの不一致問題
上の転置インデックスではstemmingやlemmatizeをせずにそのままtokenizeしたtermを索引付けしているため「jumps」がそのまま載っていますが、ユーザーは「jump」で検索するかもしれません。クエリが日本語ならひらがなカタカナ漢字の表記が混ざっている (きつね、キツネ、狐) かもしれませんし、多言語対応をしようと思ったらアクセントの有無、簡体字・繁体字、ネイティブ文字とアルファベットの混合 (Transliteration、例えば Greeklish) ということもあります。また検索システムの評価はインターフェースや言語に対する習熟度にも左右されます。モバイル端末での入力に慣れていないユーザーや、ある単語を耳で聞いたことがあるが正確なスペルを知らないというときには、入力されたスペルが正しくないかもしれません。Amazonのデータによると10-15%のクエリはスペルが正しくないと言われています。

近くに大きなトランポリンの施設がある聞いて検索しようとした私と正しいスペルを教えてくれるGoogle
意味的な理解不足問題
自然言語は人間の営みを反映しているため複雑で曖昧性を持ちます。その言葉が違う階級で使われていた、輸入される際に現地語が1対1で対応できなかった、伝わる過程で訛ったなど様々な理由で同一の概念に対して違う文字が割り当てられるということがしばしば起こります。たとえば「味噌汁」と「御御御付け」と「ミソスープ」、「film」(イギリス語) と「movie」 (アメリカ語)、「グルジア」 (ロシア語読み) と「ジョージア」 (英語読み)。これらの問題の解決策として同義語辞書を用いるなどが考えられます。このアプローチは問題をある程度軽減することができると思われます。しかしながら、もしあなたがリストランテに行って「味噌汁」「御御御付け」「ミソスープ」というメニューを見たらそれぞれ違うディッシュがサーヴされることをイメージするように、ぶんしょうがひらがなでかかれているとちがういんしょうをうけるように、同義性はバイナリより程度や属性の違いで表現されていそうな気がします。また、なんらかの方法であなたは「hot」と「warm」を、「dog」と「puppy」を同義語として登録したとします。そしてクエリ「hot dog」が与えられたとき、あなたの検索システムは「warm puppy」を検索語に加えるでしょうか。意味の理解はもう一歩越えなければならないギャップがあるように感じます。
同じ概念に複数の単語がマッピングされるのとは逆に、同じ単語に対して違う概念がマッピングされることもあります。以下の文章を「bank」に注目して読んで見てください。
- I arrived at the bank after crossing the street.
- I arrived at the bank after crossing the river.
前者は「bank = 銀行」で後者は「bank = 岸」を指していると思われます。または同じ単語を含むクエリであっても順序によって尤もらしさが変わってくることもあります。「渋谷」と「凛」からなるクエリは順序によってはアイドルマスターの渋谷凜さんを表示すべきか、渋谷にあるラーメン屋凛を表示すべきかが変わってきます。
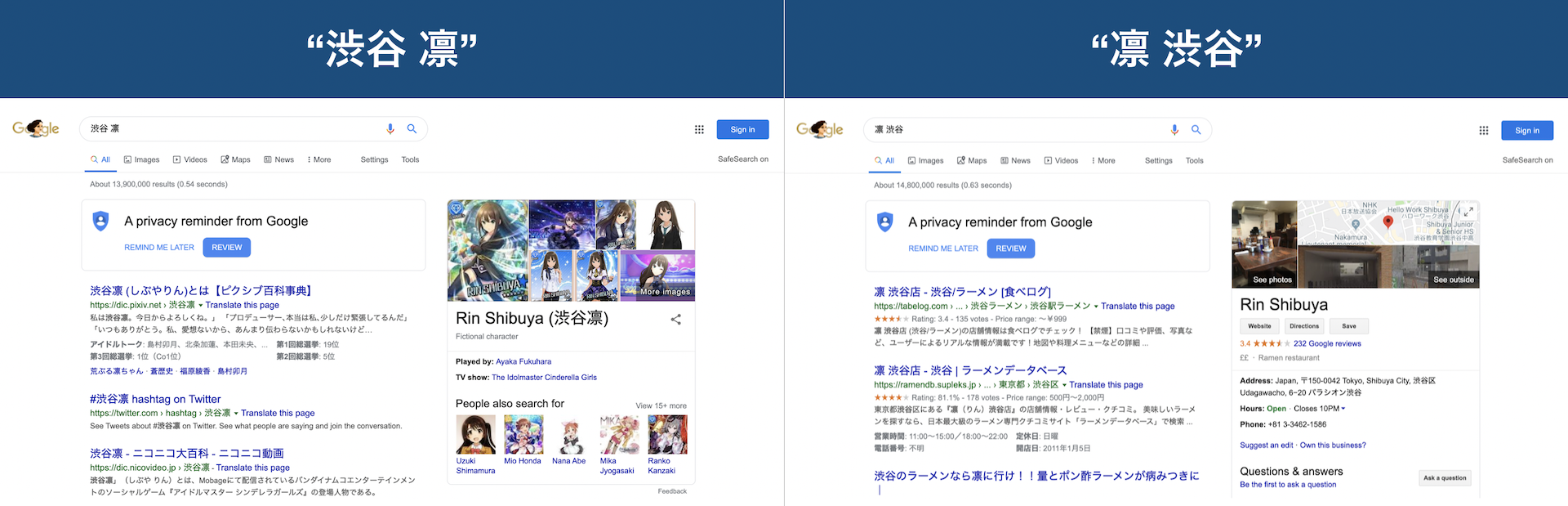
上記の転置インデックスの例に戻ると「fox」は文章1と2の両方が一致しますが、文章1は動物に関する文章で、文章2の「Fox News」は固有名詞でケーブルチャンネルか何かの文章なので、「fox (animal)」のクエリが与えられたときは文章1の方が適合度が高そうです。このような私たちの直感は本当に正しいでしょうか。また、どのようにそれをランキングに反映すればいいでしょうか。
曖昧なクエリ問題
「クリスマスの料理」、「景観の良いホテル」、「落ち着く音楽」のようにおそらく文書中に含まれていない単語で検索をしたいというシナリオも考えられます。この解決方法にはナレッジベースを用いて下位語や関連語を引っ張ってくるなどの方法が考えられますが、同義語と違って曖昧な概念に対しては関連するクエリが無数に存在する場合があります。さらに自然言語に近い質問のクエリでは、ユーザーは検索結果にlexicalなマッチ度が高くなるような似た質問文が見たいのではなく、質問の答えを得ることを期待します。まさに最近のGoogle検索は「あの…思い出せないけど、なんか〜みたいなやつ」と入力すると意外と意図した検索結果を表示してくれます。

入力されたクエリのほとんどがドロップされているが正しい
半構造化された文書のランキング問題
商品検索なら商品名、説明文、価格、レビュー、ホテル検索ならホテル名、ロケーション、部屋タイプなど、現実世界においては検索対象のドキュメントが複数のフィールドで構成されていることがあります。タイトルと本文のようなテキストフィールドであれば型が同じなので技術的には連結可能ですが、タイトルと本文だと情報の密度に差があるはずなので、実際に自分で実装して使ってみると何か思っているのと違う…という経験したことのある人は多いのではないでしょうか。ヒューリスティックな解決策として title * 10 + desc * 3 + comments * 1 のようにフィールドの重み付けをしてスコアの算出を行うことが考えられますが、検索システムが複雑化していくにつれて属性ごとの重みの最適値を見つけることは困難になっていきます。
ランキングのコンテキスト問題
「pizza」というクエリが与えられたとき、そのユーザーが英語を話さないイタリア人だったらイタリア語の検索結果を表示してほしいと思います。またアメリカでは「ジャイアンツ」は野球のチームとアメフトのチームがあるのですが、「giants match highlights」というクエリに対してはどちらを表示するのが正解でしょうか。

「統計」というクエリに対して統計學 (Traditional Chinese)、统计学 (Simplified Chinese)、統計学 (Japanese) のどれを表示すべきかは私にとっては明確なのですが
このように関連度の評価には主観が入るのですが、実装方法もさることながら実際にそのパーソナライゼーションがどれくらいインパクトがのあるものなのか定量的に知りたくなると思います。
ニューラルネットワークを用いた情報検索
大きく分けてマッチングとランキングの2つの問題があることが分かってきました。それぞれの問題に対してどのようにニューラルネットワークを応用しているかというのを最近の論文を紹介しながら見ていきましょう。
各論文の説明を書いていたら長くなってしまったのでコンセプトの紹介に絞って文章を削りました。「言われています」「示されています」と言っているところは論文内で示されているのであるので興味があれば論文を参照してください。
マッチング
このセクションでは文書候補の生成について見ていきます。伝統的なlexical matchingは文字コード上で一致するかどうかのバイナリ情報ですが、現実的には「一致」とは編集距離的な近さや意味的な近さなどもあり、どのクエリに対して何を優先的に考慮すべきかを決めるのは難しい問題です。また、後述されていますが研究の設定によってはマッチングとランキングが明確に区別できないものもあることをご留意ください。
プロダクト検索における意味的一致
Amazonの [2019] Semantic Product Search では単語の形態の変化に弱い純粋な字句一致なシステムを補助するために意味的一致にフォーカスしたニューラルモデルを提案しています。例えばクエリが「countertop wine fridge」だった場合に「beverage mini refrigerator」というアイテムは意味的に近く、このようなアイテムも含めて後のランキングを行いたいというのが目的です。

NLPでは意味の獲得というのは長く研究されていて、例えばword2vecのようなベクタースペースで関連する単語を近くに配置するようなものを用いてquery expansionを行ったりモデルの入力として文書のランキングに使う研究もあります [2016] A Dual Embedding Space Model for Document Ranking。彼らはテキストを違う粒度 (Word Unigram, Word N-gram, Character Trigram) で分解結合し、unseen wordsに対してhashing trickを行なっています。このアプローチは FastText - Facebook Research と似ています。この方法では「artistic iphone 6s case」というクエリを以下のように表現します。
-
Word Unigram:
["artistic", "iphone", "6s", "case"] -
Word Bigram:
["artistic#iphone", "iphone#6s", "6s#case"] -
Character Trigram:
["#ar", "art", "rti", "tis", "ist", "sti", "tic", "ic#", "c#i", "#ip", "iph", "pho", "hon", "one", "ne#", "e#6", "#6s", "6s#", "s#c", "#ca", "cas", "ase", "se#"]
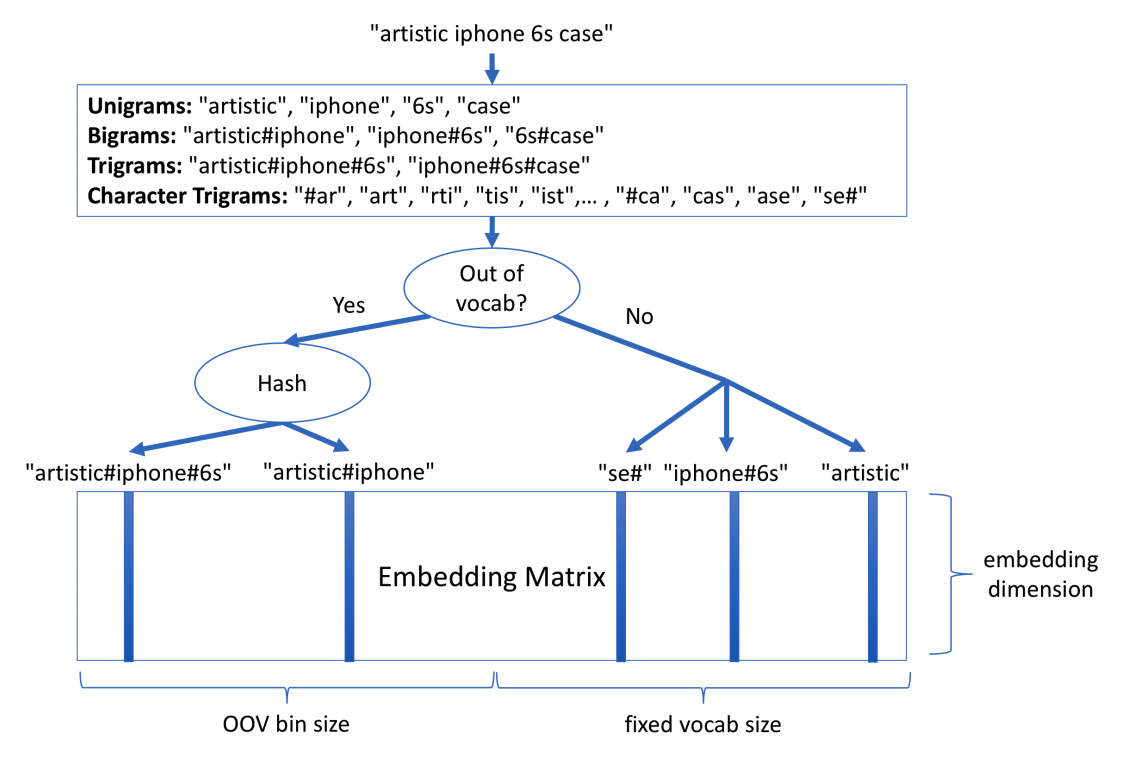
そしてvectorのaverage pooling (= 平均を取る) を行いますが、これではBag-of-Wordsと変わらないのではと思うかもしれませんが、Word N-GramとCharacter Trigramがある程度のコンテキストの理解とスペリングの耐性を高めるのを助けているらしいです (「hot dog」と「dog hot」は遠く、「hot dog」と「hotdog」は近くなるでしょう)。LSTMも試したそうですが、このシンプルな方法の方がうまくいったと書かれています。おそらくAmazonではクエリが自然言語寄りではなくコンテキストを持たないキーワードのセットとして与えらることが多いので、この手法の方が優っているのでしょうか。
もう一つ面白いのがプロダクションでテストする際に既存のlexical matchと新しく実装したsemantic matchの両方の結果をマージしてからランク付けしていることで、理由は論文内では述べられていませんが、パフォーマンスの低下が売り上げにダイレクトに影響をするので影響を小さくするためにこの方法でテストしたのではないかと思いました。
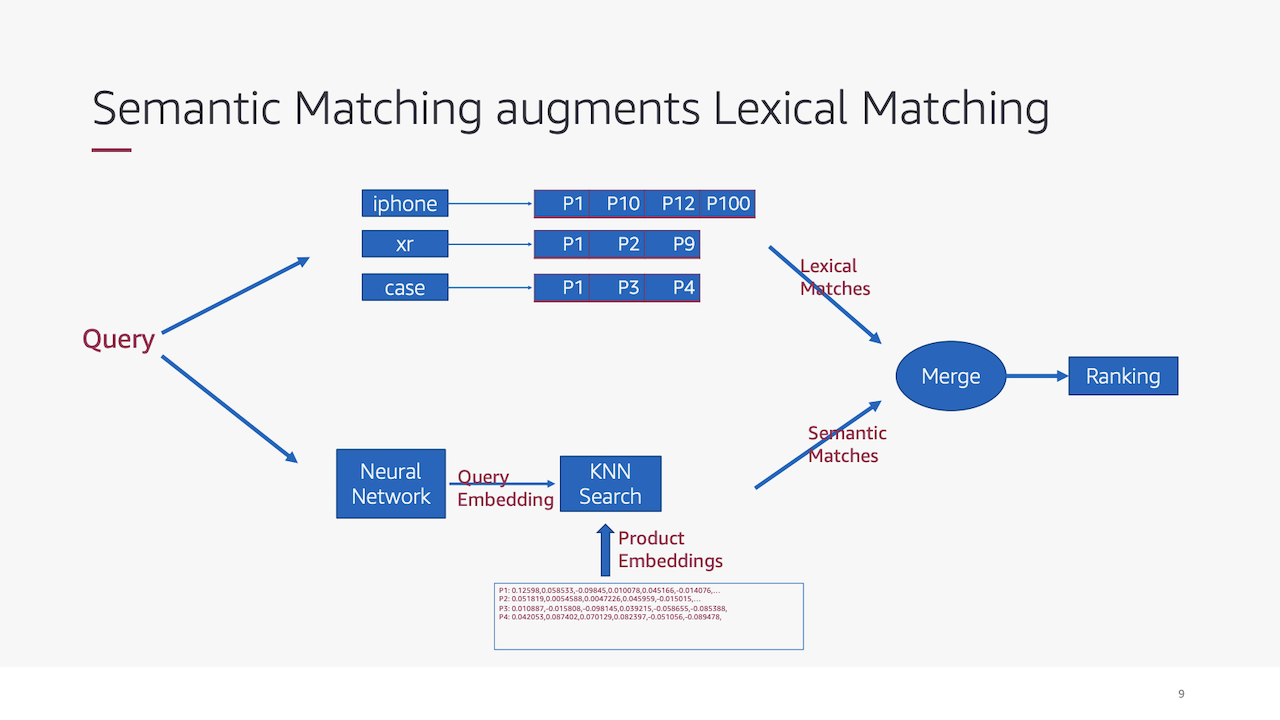
画像は著者のスライドから引用しました: https://wsdm2019-dapa.github.io/slides/05-YiweiSong.pdf
ウェブ検索における意味的一致
冒頭でGoogle検索の記事を紹介しましたが、情報検索コミュニティでもすでに学習済みの言語モデルを用いる手法はベンチマークにおいてSOTAな結果を示しています。下の図はTREC Robust04というウェブ検索で一般的にベンチマークに使われるデータセットのNDCGによるSOTAの時系列の図ですが、18年からの伸びは言語モデルの応用によるものです。
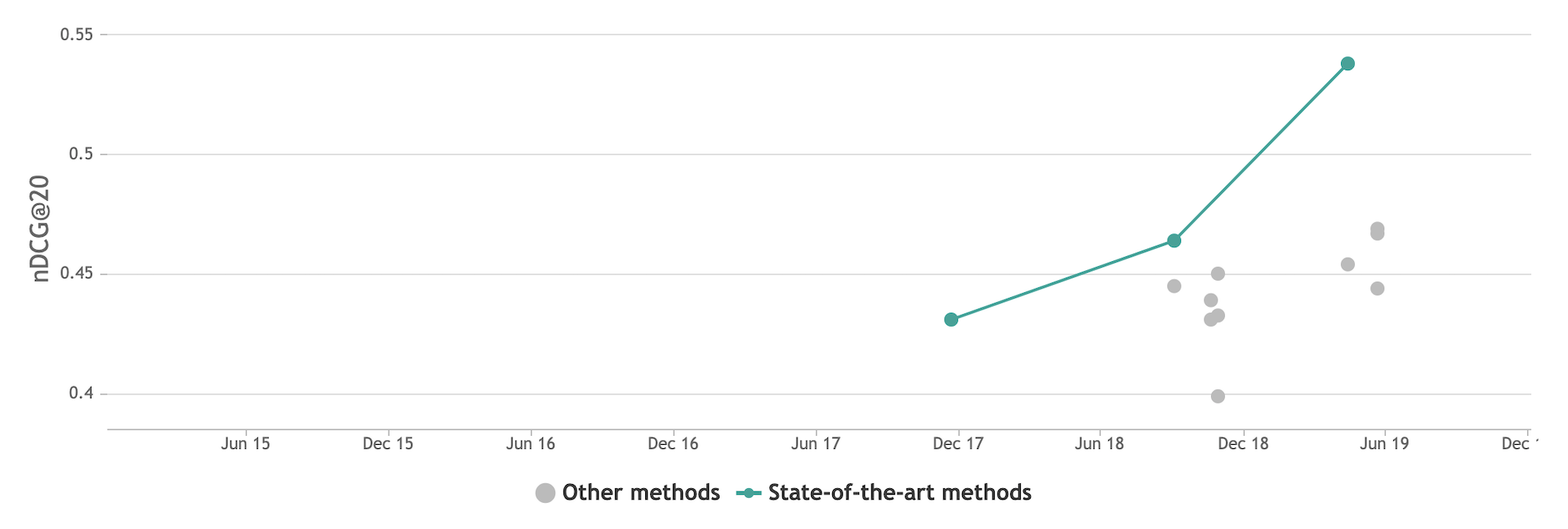
State-of-the-art table for Ad-Hoc Information Retrieval on TREC Robust04
[2019] CEDR: Contextualized Embeddings for Document Ranking は既存のモデル (DRMMやPACRRなど) の入力にContextualized Embeddings (文脈によって "bank" が表す値が変わるELMoやBERTのようなLanguage Model) を使ったというものですが、SOTAを達成しています。このような手法はQuoraのようなQAサイトや音声検索のような、クエリが自然言語に近いほど有効だと思います、おそらく。
ランキング
候補となる文書を絞り込んだ後、私たちはなんらかの合理性に基づき文書を並べたいのですが、「まず最初に、関連度を推定するのは非常に難しい問題であると理解すべきである」という書き出しの本があるように (どの本だったか忘れてしまった…) そもそも関連度、類似度、有用性がそれぞれ意図するところ、つまるところ問題の定義や結局このモデルは何を学んだのかについて、多くの検索エンジニアが頭を悩ませていると思います。
ランキングといえば既存のLearning to Rankとニューラルモデルは何が違うのかというと、既存の機械学習のテクニックは主に手で作った特徴に依存するのですが、ニューラルモデルでは表現を学ぶことができるので、その代わり大量のパラメータを学習させるためより多くの訓練データが必要になりますが、潜在的により複雑な問題を解くことができると言われています。
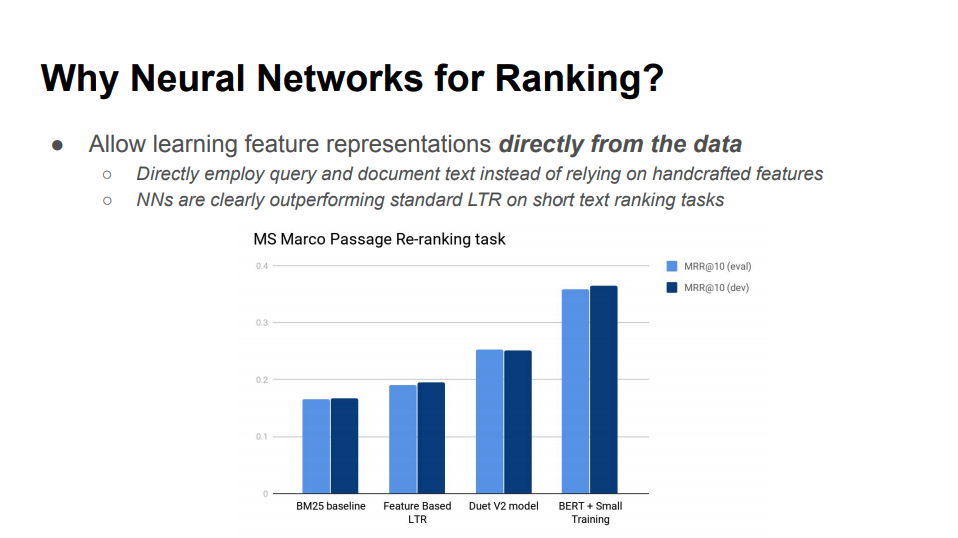
スタンフォード大学のIRの講義の資料 Week 10 Personalization : http://bendersky.github.io/res/TF-Ranking-ICTIR-2019.pdf
ランキング問題の中でもマルチフィールドやパーソナライゼーションなど、私が気になった論文をいくつかピックアップしました。
マルチフィールドとランキング
かつて情報検索の分野では多くの研究では検索対象が一つのある程度の長さのテキストフィールドで構成されている前提で手法が提案されてきましたが、現実的にはショートテキストだったり属性の集合、数値、画像、音声とより複雑な構成をしていることがあります。また検索対象がテキストフィールド一つだけで構成されていたとしても、なんらかの方法でその文書のメタデータをスコアリングに追加した方が精度が高くなることがあるというのは驚くことではないでしょう。例えばその文書がクリックされたときのクエリを活用することは効果的であると示されています。このように複数のフィールドをミックスするのに既存の方法ではBM25Fというのがありますが、それをもじって [2017] Neural Ranking Models with Multiple Document Fields ではニューラルモデルでマルチフィールドの文書を扱う手法「NRM-F」を提案しています。
このフレームワークではフィールドは複数のインスタンスを持てるようになっていて、n-gram hashing vectorで構成される各インスタンスの表現、フィールドレベルのアグリゲーション、ドキュメントレベルのアグリゲーションの3つのコンポーネントで構成されています。
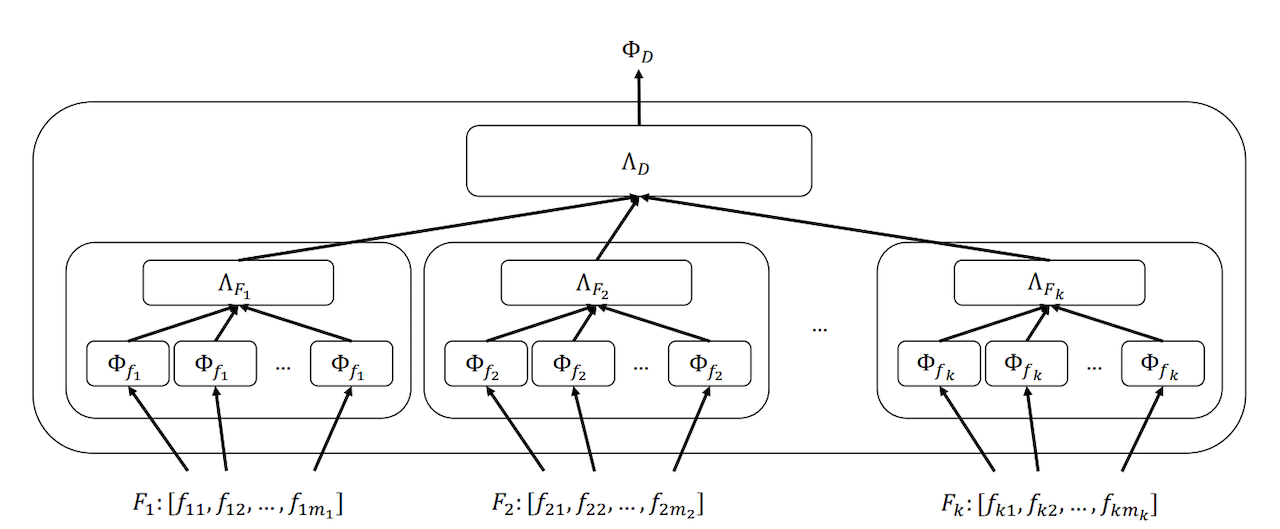
ナイーブな実装では重要なフィールドの有無がスコアリングに強く影響を与えてしまうため以下の工夫をしています。
- Field-level masking: フィールドに含まれるインスタンスの数が違うので存在しないインスタンスに対してBackprop時の勾配をゼロにするためのテクニック
- Field-level dropout: 対象となるフィールドが存在しないことがある場合に、スコアリングがそのフィールドに依存し過ぎてしまうのを避けるにフィールドに対するユニットをランダムに全て落とすテクニック
パーソナライゼーションとランキング
もし、あなたがクエリに対して完璧な検索結果を表示する検索エンジンを作ったとしても、クエリはユーザーのニーズを表す氷山の一角でしかなく、ユーザーの行動を決定付ける潜在的な要因が他にもあるためNDCGは1にはならないでしょう。ユーザーの情報をランキングに考慮し下の図のギャップを埋めるのがパーソナライゼーションです。

https://web.stanford.edu/class/cs276/handouts/personalization-lecture-1-per-page.pdf
Amazonのようなプロダクト検索では、ユーザーの行動履歴や経済状況がダイレクトに意思決定に影響することが知られています。パーソナライゼーションは常に検索にポジティブな影響をもたらすのか、そしてその情報をどのようにモデルに取り入れるのかという議論をしたのが [2019] A Zero Attention Model for Personalized Product Search です。これまでの研究で実のところパーソナライゼーションはクエリによってはネガティブな結果をもたらすことが知られています。そのため、パーソナライゼーションが効くときにだけ自動的に適用するモデルが作るというのが基本的なコンセプトになります。
通常の検索ではクエリに対するアイテムがエンゲージする確率は $i$ をアイテム $q$ をクエリとして $P(i | q)$ と表されます。パーソナライゼーションでは加えてユーザー $u$ でもパラメタ化されるので $P(i | q,u)$ となります。ユーザーの行動が現在の検索のコンテキスト (例えばクエリ $q$) にのみ依存すると仮定すると $P(i | q)$ は以下のようになります。
$$
P(i | q) = \sum_{u \in \mathcal{U}}P(i | q,u) \cdot P(u)
$$
この仮定のもとパーソナライゼーションが効くときの条件は以下のように定めます。
1. パーソナライゼーションは検索結果の多様性が高いときに有用である
クエリ $q$ が特定のアイテムの購入を意図している場合に $P(i | q,u)$ は $P(i | q)$ より良くならないというのは理解できると思います。論文ではこのクエリの特性はクエリのエントロピーを求めることで分析しています。
2. パーソナライゼーションはそのユーザーの嗜好が他のユーザーから離れているときに有用である
この条件を言い換えると、パーソナライゼーションは $P(i | q,u)$ の分布が $P(i | q)$ と明らかに違うときに性能が良くなると言えます。そこでMean Reciprocal Rank (MRR) を以下の式で求めます。
$$
MRR(q) = \sum_{u \in \mathcal{U}}RR(P(i | q),P(i | q,y)) \cdot P(u)
$$
$MRR(q)$ が高くなればなるほど $P(i | q,u)$ と $P(i | q)$ が近づいていきパーソナライゼーションの効果が低くなることがわかります。
論文ではこれらを自動的に適用するZero Attention Strategyというものを導入しています。この論文はただニューラルネットワークに適用して結果を見るというものではなく、分析を行いその結果を用いてモデル化するというプロセスを踏んでいるので好感が持てました。またモデルを作らなくてもエントロピーとMRRを計測することで自分の検索システムではどの程度パーソナライゼーションが効くのかというのを見積もることができるかもしれません。
コンテキストとランキング
プロダクト検索においてパーソナライゼーションはユーザーの購買意欲を引き出すのに効果があるとわかりましたが、長期的な嗜好のモデリングは常に短期的な目的達成の役に立つのでしょうか。以前情報推薦系の論文で「Eコマースサイトで、あるユーザーがスターウォーズが好きということ、直近でTシャツを探していることが行動履歴からわかったのでスターウォーズがプリントされたTシャツをレコメンドしました」というのを見た記憶がありますが、正直なところ「それは嬉しいのか?」と思いました。どうやら情報検索・推薦システムでは「日本語と英語の情報だけ見たい」のような長期的な嗜好と、「このスピーカーが良さそう、これと似たようなものが見たい」のようなセッション内だけで適応される短期的な嗜好がありそうです。また、もしユーザーの購入履歴が少ない、あるいは全くない (ゲストユーザーなど) 場合はパーソナライゼーションの恩恵を受けることができないという点も考慮すべきでしょう。
[2019] Leverage Implicit Feedback for Context-aware Product Search では短期的な嗜好にフォーカスしてどのように検索結果を最適化するかを議論しています。プロダクト検索はウェブ検索とは違ってユーザーは比較のために詳細ページへのリンクをより多くクリックするので、著者はプロダクト検索を動的なランキング問題であると再定義して、前のページでクリックされたアイテムを暗黙的なシグナルとして現在のページのアイテムリランクしています。
研究からプロダクションへ
情報検索・推薦システムは、現実世界においては数億の文章セットから数十ミリ秒以内にレスポンスを返すなどパフォーマンスの制約があるため、キャッシュしやすくしたり一部モジュールだけを切り替えてテストできるようにするために、マッチングとランキングの多層構成になっていることが多いです。運用されている大きなアプリケーションとして "Scalability is extremely important" と言っているYouTubeのレコメンデーションの例だと、スケーラビリティのためにまずsimilarityで候補の絞り込みをしたのちにpointwiseでランク付けをしているそうです (理論的にはlistwiseの方がmetricsを最適化するのに良いと言われている: An Analysis of the Softmax Cross Entropy Loss for Learning-to-Rank with Binary Relevance – Google AI)。
This approach of making predictions for each candidate is a point-wise approach. In contrast, pair-wise or list-wise approaches learn to make predictions on ordering of two or multiple candidates. Pair-wise or list-wise approaches can be used to potentially improve the diversity of the recommendations. However, we opt to use point-wise ranking mainly based on serving considerations. At serving time, point-wise ranking is simple and effcient to scale to a large number of candidates. In comparison, pair-wise or list-wise approaches need to score pairs or lists multiple times in order to find the optimal ranked list given a set of candidates, thereby limiting their scalability.
Recommending what video to watch next
Googleはとんでもなく高性能なマシンと秘密のアルゴリズムによって数億のアイテムセットからlistwiseを1msで計算していると思っていましたが、そんなことはなかったので安心しました (?)。このように、実際に検索システムを運用するにはパフォーマンスを無視することはできません。論文を読んでいると検索システムの実験の設定にいくつかのパターンがあることに気が付きます。
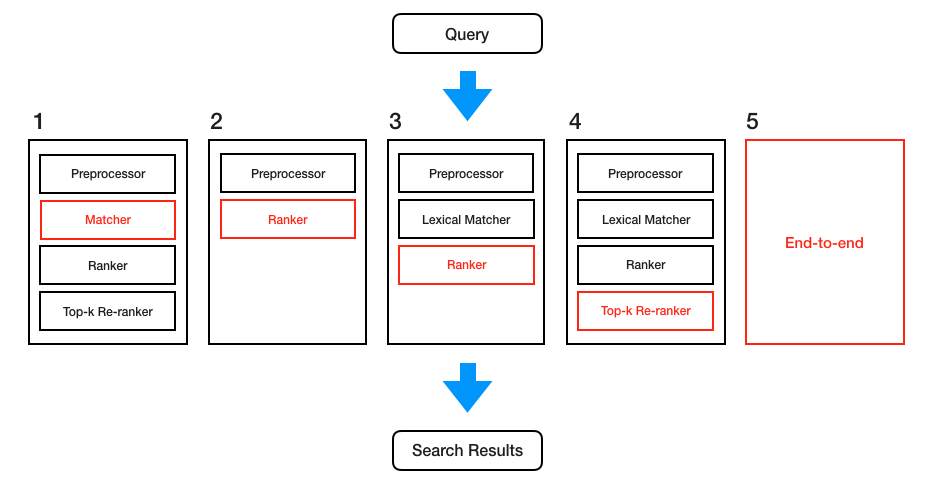
(1)では従来のlexical matchingでは候補にならなかったものをヒットさせたいという設定で、うまくいけば1セッション内のクエリの書き換え回数が減るでしょう。うまくいかないケース、例えば「hot dog」のクエリで「warm puppy」が検索結果に入ってしまった場合はNDCGなどのスコアが下がるでしょう。
(2)はクエリと文書とラベルがあるという標準的な設定だと思われます。しかし、すべての文書に対して関連度を計算をするのは運用上は現実的ではないので、他の設定とそのままパフォーマンスを比べたり、そのままプロダクションに持っていくのは難しいかもしれません。
(3)はなんらかの方法ですでに候補の絞り込みがされた文書に対してランキングを行うという設定で、(4)ではさらに既存のランカーでランク付けされたものに対してリランクするという設定です。(3)では絞るプロセスで何件になるかが事前にわからないため(4)の方がより現実的だと思いますがTop-kをいくつにするかでパフォーマンスとモデルの影響力のトレードオフが発生します。
さて、多層の検索システムにおいてもしマッチングレイヤーがrecallを重視している場合には実際には関連度の低いアイテムが候補に入る可能性があるためランキングレイヤーではより高い品質が求められ、ランキングレイヤーの関連度が強くない (たとえば日付順など) 場合にはマッチングレイヤーの品質が高くなければ検索結果がノイジーになってしまいます。レイヤーが分かれている場合、この関係性が不明瞭でヒューリスティックな調整が必要になります。そのため、パフォーマンスの問題がなければ同時に学習させたい、そこで(5)のend-to-endのシステムも研究されています。[2018] From Neural Re-Ranking to Neural Ranking: Learning a Sparse Representation for Inverted Indexing ではニューラルモデルでクエリと文書のスパースな表現を学んで転置インデックスとして使う提案がなされています。このようにニューラルモデルでいかにパフォーマンスの問題に対処するかというトピックも積極的に議論されており、今後解決されると情報検索に大きなインパクトを与えるかもしれません。
「十分なデータがない」
ニューラルモデルは表現を学ぶためにより多くの学習データが必要なので、十分な学習データを得ることが難しいかもしれません。[2017] Neural Ranking Models with Weak Supervision ではクリックデータを使わずにBM25のランク付けされた (あるいはヒューリスティックなランキングでも構わない) クエリと文書のセットを訓練データとして使うことで実質無限に学習できるようにして、その上 (なぜか) BM25の性能を上回ったと言われています。また [2018] Joint Modeling and Optimization of Search and Recommendation ではレコメンデーションと検索システムは本質的に同じである (とBelkinとCroftは1992年に結論付けた) ことに着目して、multi-objective learningにして相互にパフォーマンスを改善するという取り組みをしました。なのですでにレコメンデーションか検索システムかどちらかが存在している場合に、そのログを使うことでもう片方を改善できるという可能性を示しています。
まとめ
情報検索の全体像を眺めました。尺の都合上かなり説明を省略しましたが、要点は以下の通りです。
- BM25は古典的な文書検索には良い
- しかしながら情報検索の要件が多様化、複雑化してきたため新しいモデルが求められている
- Neural IRは問題を解決する可能性があり様々な手法が提案されている
もし既存の検索システムがあるところにNeural IRの導入を検討するとしたら、以下のような流れになるでしょうか。
- 文書の特徴を把握: マルチフィールドか、マルチメディアか、意思決定に関わるファクターは何か
- クエリの傾向を分析: 語彙のミスマッチの確認、キーワードか自然言語か
- 検索行動の分析: MRR、MAP、NDCG、エントロピーなどの計測
- ゴール設定: 上記の分析からマッチングとランキングのどちらがクリティカルか
- 検索ボリュームとパフォーマンス要件の確認: 上の実験設定のどのパターンを用いるか
私はすべての検索アプリがニューラルモデルを導入すべきとは思っていません。むしろヒューリスティックなアルゴリズムを検討したり、たとえ完璧でなくてもword embeddingsによるquery expansionを行うことにも価値があると思います。というのも今のところNeural IRはコストが高い技術なので、ある程度大きい検索チームがあって、検索のアルゴリズムの改善によって直接的に売上に貢献したりプロダクトそのものが大きく改善される場合でない限り、コストに見合うのかというのを常々考えているからです。しかし、少しづつ学んだことや事例を共有することでコストが下がり、いずれ導入コストが下がって検索体験がずっと良くなるようになるといいですね。
最後に、私のお気に入りのGoogle検索の擬人化の動画をシェアします: If Google Was A Guy (Full Series)