情報検索・検索技術 Advent Calendar 2021 の22日目の記事です。
Motivation
検索エンジニアはバックエンドエンジニアのサブセットだと見なされることがありますが、ある程度の規模のプロダクトに携わる検索エンジニアの業務内容は新しい機能やAPIを作るというよりも、典型的な検索アプリが持っているSearch API、Auto-Completion API、Query Suggestion APIのような、すでに実装されているAPIのインタフェースを変えずに中身を変えることが多いという点で、バックエンドエンジニアとは少し違うと思っています。私自身も過去数年で新しい検索のAPIを書いた回数は片手で数えられるくらいですが、代わりにオフライン・オンラインの実験を毎日しているといった感じです。
このように検索エンジニアは新しいアルゴリズムを提案、比較、そして実験を通してベースラインを越えることで価値を提供するという職種なので、巨大な言語モデルの動向を追うなどして新しいアイデアを得るのと同じくらい、どのように手法の評価・比較を行うかというのは一つの重要なスキルだと思っています。
この記事では実際の検索システムの評価などについて最近私が読んだ文献や、それについて感じたことについて共有します。
Basics of Evaluation of Information Retrieval Systems
まず最初に、検索における機能の目的とおおまかな開発の流れについてです。検索エンジニアは検索の各機能を改善することで、たとえばe-commerceであれば流通取引総額のような、ビジネス指標の最大化をすることを最終的なゴールとしています。しかしながら、これらの指標は直接的に最適化することができません。そのため、ビジネス指標からプロダクト指標、システム指標のように分解して、手元で変化が観測できるように落とし込んでいきます。そして、思いつく限り手法を列挙して、offline experimentを通して良さそうな2、3個のvariantを残して、それらをonline experimentをしてプロダクト指標がどう動いて、その結果ビジネス指標にインパクトがあったかを観測します。
私自身も自信満々で送り出した新しい手法がオンラインで全く響かなかったということがよくあるのですが、最近聞いた話だとonline experimentで良い結果になるのは良くて3割、Googleくらいになると1割ほどだそうです。

閑話休題、具体的に私が手元で開発するときには以下のような指標を考慮します。
- Latency
- Complexity
- Recall
- Coverage of documents: Total Hits, Zero Hit Rate, ...
- Coverage of queries
- Relevancy
- Set-based metrics: Precision@k
- Rank-based metrics: NDCG@k, MAP@k, MRR, ...
- Recency
- Similarity (or Diversity)
- Jaccard Similarity
- Kendall Tau Coefficient, Rank Biased Overlap (RBO), ...
- Cosine similarity
- ...
これらの汎用的な指標に加えて、その機能独自の指標を定義してvariantの比較をします。なぜこんなにたくさん指標があるのか、あるいは専門的で難しいのでシンプルな指標を使いたいという質問を受けたことがあります。妥当性について議論するためにいくつかの指標を見てみましょう。
Relevancy
- シンプルなアイデア 1: セッション内で一つでも商品がエンゲージしたらそのセッションは1 (成功) そうでなければ0 (失敗) として扱い、セッションの成功率をパーセンテージで表す (Session Success Rate)
- シンプルなアイデア 2: セッション内でエンゲージした商品は1、そうでない商品は0として扱い、その和をセッション内の商品の総数で割る (Precsion@k)
数字はその商品の表示されたランクを、緑色はその商品がクリックされたことを表しています。これらの指標はシンプルでわかりやすいですね。順序を考慮しない指標はset-based metrics、順序を考慮する指標はrank-based metricsと呼ばれたりします。
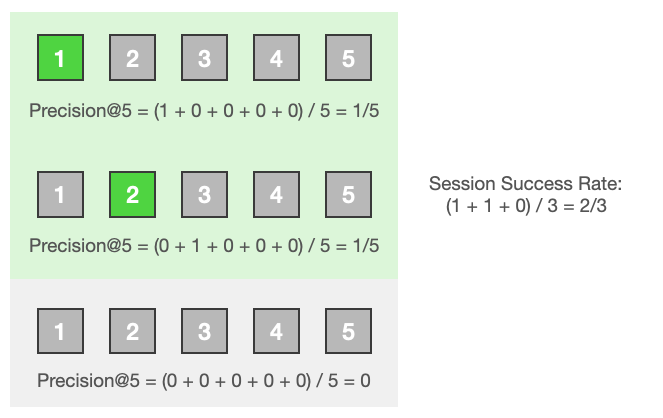
それでは実験を実施して評価を行いましょう。
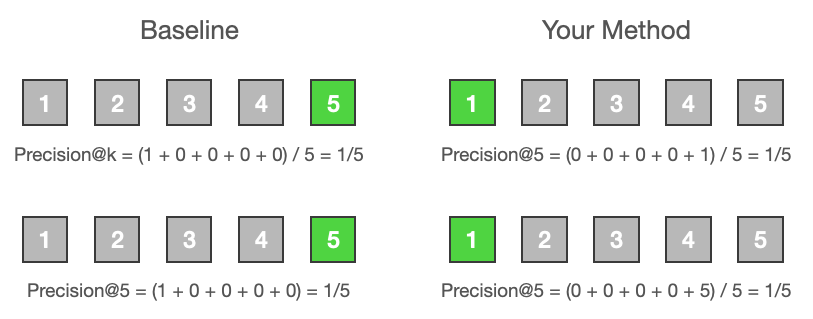
この指標においてはどちらの手法でも差がありませんでした、と言われて納得感があるでしょうか。各商品に対するアテンションはランクに応じて大きく減衰するので、relevantな商品であってもランクが低ければクリックされる確率が下がると考えられるので、もし他に観測された指標がなければ、提案手法の方が優れているはずだ、と考えることができるのではないでしょうか。
上記の理由から検索エンジニアはNDCGやMAPのようなランクに応じて減衰する指標を比較することで施策の良し悪しを判断します。それらの解説はインターネット上にたくさん資料がありますので、そちらをご覧ください (e.g. Evaluation Metrics For Information Retrieval) NDCGやMAPの妥当性の議論について後ほど見ていきます。
このような理由があったとしても、チーム外に施策の結果を共有するときにはSession Success Rateのような指標が使われることがしばしばあります。これについて同僚と話したことがありますが、NDCGが0.4でしたと言われてユーザーの行動を想像することは難しいですが、Session Success Rateが0.4でしたと言われると4/10で商品がエンゲージしたんだなと誰でも想像しやすいのだろうとなりました。
Recency
実際の検索アプリにおいては、Relevancyと同じくらいRecencyも大切なケースもあります。たとえばユーザーが "US president" で検索したときには時期によって正解が変わるという直接的な理由もありますし、ユーザーがアイテムを投稿するコミュニティベースのサービスでは、古いアイテムより新しいアイテムをマッチングした方がその後のエンゲージメントに差が出るから、という間接的な理由もあります。そのため、ランキングアルゴリズムの変更がRecencyにどのような影響を与えるのかを調べたいことがあります。どのように定量するのが適切でしょうか。
- シンプルなアイデア:
avg(user_searched_at - item_listed_at)
たとえばアイテムが上位から [1 day ago, 2 days ago, 9 days ago] と並んでいたら平均をとって 4 days ago となります。この指標は 1. ページサイズの変更に対してロバストではない 2. スコアがランクに応じて減衰されない などの問題があります。Recencyを測るスタンダードな方法ってあるんですかね。
上で述べたとおりRecencyとRelevancyを同時に最適化したいという需要もあり Ranking Relevance in Yahoo Search ではRecency-demoted NDCGという、その2つの指標をcombineしてラベルを付け直す指標を提案しています。
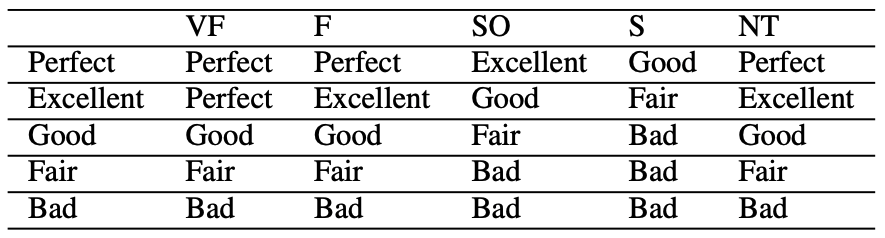
縦軸がrelevancy、横軸がrecencyになっていて、recencyはそれぞれ "very fresh (VF)", "fresh (F)", "slightly outdated (SO)", "stale (S)", "non-time-sensitive (NT)" となっています。
Similarity (or Diversity)
2つの検索結果を比較したいというときに用いられる指標です。たとえば提案手法の実装を終えてonline experimentを実施する前のsanity check (オンラインでの実験を行う前に2つの検索結果の差が小さすぎる場合にパラメーターを再調整するなど) として、適用前後でどの程度検索結果が変わるのかを調べたり、あるいはパーソナライゼーションで同じクエリに対してユーザー間でどれほど検索結果が違うのかを定量化するために用いたりします。
これらの指標にはJaccard Similarity、Kendall Tau Coefficient、Rank Biased Overlap (RBO)、Cosine Similarityなどがあります。よく使われるものとして、Kendall Tau Coefficientを紹介します。
厳密ではないのですが、分かりやすさのために「ランク付けされたリストのための相関係数です」という言いながら下の図とコードを見せることがあります。
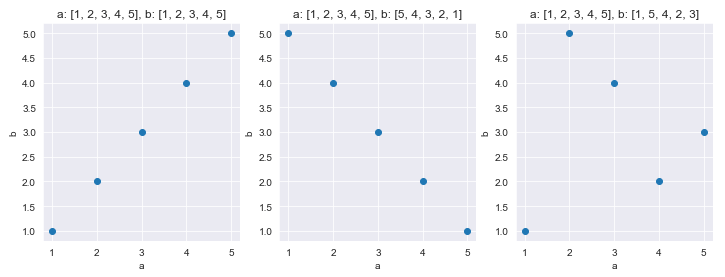
a = [1, 2, 3, 4, 5]
b = [1, 2, 3, 4, 5]
kendalltau(a, b) # => KendalltauResult(correlation=0.9999999999999999, pvalue=0.016666666666666666)
a = [1, 2, 3, 4, 5]
b = [5, 4, 3, 2, 1]
kendalltau(a, b) # => KendalltauResult(correlation=-0.9999999999999999, pvalue=0.016666666666666666)
a = [1, 2, 3, 4, 5]
b = [1, 5, 4, 2, 3]
kendalltau(a, b) # => KendalltauResult(correlation=0.0, pvalue=1.0)
正の相関がポジティブ、負の相関がネガティブなので分かりやすいですね、と紹介します。しかしこの指標には RBO v/s Kendall Tau to compare ranked lists of items で指摘されているような問題があります。
ではRBOを使うべきかというと、RBO自体もdocumentのIDを比較するため、コンテンツ自体の類似度が考慮されません。たとえばクエリが「パスタ」だったときにペペロンチーノ、カルボナーラ、ナポリタンなどが含まれる検索結果と、ペペロンチーノの分量違いだけが並んだ検索結果は同程度に似ているとしたいかという疑問が出てきます。そういう視点で考えるとKendall TauもRBOも実用上さほど違いがないかなと思います。Estyの今年の論文 Personalization in E-commerce Product Search by User-Centric Ranking でもKendall Tauを使っていました。
より厳密にしたいときは、以下のようなプロパティを持った指標が欲しいと思います。
- 2つのリストで商品のオーバーラップがなくても使える
- コンテンツの類似度を考慮する
- Rankでスコアが減衰する
しかしながら、今のところ業界のスタンダードな指標はないようなので、機能によって独自に適切に見える指標を作っているという状況です。
Real-World Metrics
基本的な指標について見たので、次は実際どのような指標が使われているかを見ましょう。
Academia
数年前に情報検索の論文の評価指標について、何を使っているか調べたものがありました。
| Model | Metrics |
|---|---|
| HCAN | Acc, Macro-F1, MAP, MRR, P@30 |
| CEDR | ERR@20, P@20, NDCG@20 |
| Passage Re-Ranking with BERT | MAP, MRR@10 |
| SNRM | MAP, NDCG@20, P@20, Recall |
| Conv-KNRM | MRR, NDCG@1, NDCG@10 |
| NPRF | MAP, NDCG@20, P@20 |
| NRM-F | NDCG@1, NDCG@10 |
| DRMM | MAP, NDCG@20, P@20 |
| DSSM | NDCG@1, NDCG@3, NDCG@10 |
やはりNDCGとMAPがpopularですね。MRRは最初にエンゲージしたdocumentしか考慮しないので、対象のクエリに対する正解が1つしかないデータセットで使われることがあります。
Industry
LinkedInがQuery Intent Prediction, Query Tagging, Query Auto-Completion, Query Suggestion, Document Rankingを5つの代表的な検索タスクとして、それらについて既存の手法とニューラルな手法での比較を行った論文 Deep Natural Language Processing for LinkedIn Search Systems を出しているので、そこから評価指標だけを抜粋しました。
| Task | Offline Metrics | Online Metrics |
|---|---|---|
| Query Intent Prediction | Accuracy, P99 Latency | CTR@5 of job posts |
| Query Tagging | F1 | |
| Query Auto-Completion | MRR@10, P99 Latency | Job Views, Job Applies |
| Query Suggestion | MRR@10, Coverage | Job Views, Job Applies |
| Document Ranking | NDCG@10, P99 Latency | CTR@5, Sat Click1, Happy Path Rate2 |
- Sat Click: The number of satisfactory searches in people search, such as connecting, messaging, or following a profile
- Happy Path Rate: The proportion of users who searched and clicked a document without using help center search again on that day.
ここでは指標の選択の意図がより明確で、オフラインにおいてはユーザーがリストから一つのアイテムしか選択できない (Query Suggestionはアイテムを選択したら検索結果に遷移するので) ものはMRR、順序に関係ないものはset-based metrics、順序に関係あるものはNDCGを採用していました。それに加えてどのタスクでもlatencyを指標においています。
オフラインとオンラインでの指標の違いというのも興味深く、Document RankingではオフラインでNDCGでオンラインではCTRになっているのですが、なぜ…。Query Auto-CompletionとQuery SuggestionにおいてはオフラインではMRR、オンラインではJob ViewsとJob Appliesを指標にしています。実際のシナリオだとMRRの改善がプロダクト指標の改善に繋がるのか、のようなことはよく議論されます。たとえば私がもしこのプロジェクトを任されたとしたら以下のようなことを検討するでしょう。
- 良いクエリはユーザーを良い検索結果に誘導するはずなので、NDCGも改善されるかもしれない。
- 最適なクエリを提案すると最短でApplyに繋がるのでViewsは減るのかもしれない。
- 最短でユーザーの目的が達成されるならFirst Job Apply TimeやSession Durationが減るかもしれない。
LinkedInに限らずどの検索アプリでもこのような議論がされているでしょう。最近も実験のためにDesign Docを書いたのですが「この機能は検索結果のRelevancyを向上させ、それによってビジネス指標を改善します。」と書いたのですが、それらの指標間にどういう因果があるか分かっているんですか?と聞かれて、そうですよね…となりました。
Potential Problems and Risks
このように指標を決めること、実験を行うこと、結果を分析することなど、どのフェーズをとってもexperimentationは難しく、人類はあらゆる分野において失敗し続けています。
- 心理学・行動経済学等の著名な研究論文が次々に追試失敗【心理学】
- Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches
- Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison
下2つはRecommendation Systemについてでしたが、Information Retrievalにおいても同じ問題があり Some Common Mistakes In IR Evaluation, And How They Can Be Avoided で著者は以下の10個の問題を指摘しており、そしてこれはその後SIGIRのkeynoteになっていたことを最近思い出しました。

Proof By Experimentation? Towards Better IR Research
この日本語の解説記事 SIGIR'20 Keynote speakerから見るInformation Retrievalの分析に関する誤り が良かったのでぜひ目を通してみてください。以下は商用の検索アプリに携わる一エンジニアの感想です。
1. Thou shalt not compute MRR nor ERR (MRRもERRも使うな)
特に問題なのはランク1と2のスコアの差がランク2と∞のスコアの差と同じになるということで、つまりinterval scaleでないということです。Interval scaleでないものの平均は計算できないのと、interval scaleで有ることが前提のsignificance test (t検定など) もできなくなってしまいます。
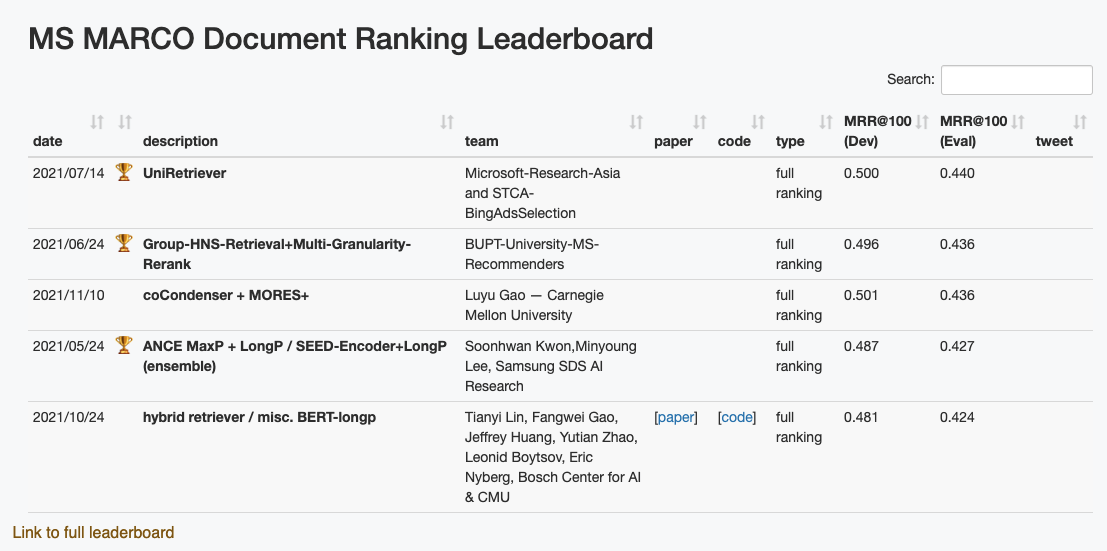
MS MARCO Document Ranking Leaderboard
著者はMS MARCOのleaderboardでMRRが使っているが上記の理由から適していないと言っていました。
本筋とは関係ないのですがMRRは検索結果にrelevantなアイテムが一つだけという仮定を置いているので、一般的なDocument Rankingというタスクに合ってないと思うのですが、MS MARCOで採用されているのでなんとなくMRRを見ているというケースをたまに見ます。
2. Thou shalt not use MAP (MAPを使うな)
MAPは以下の非現実的な仮定に基づいているので使うべきでない。
- ユーザーはちょうどrelevantなアイテムを見た直後に離脱する。
- ユーザーが離脱する確率はアイテムのランクに依らず一定である。
これを見る前から同僚とMAPとNDCGのどちらを使うべきかという議論をしたことがあります。Relevantなアイテムのランクごとのスコアは以下のようになっています (上がMAPで下がNDCG)。
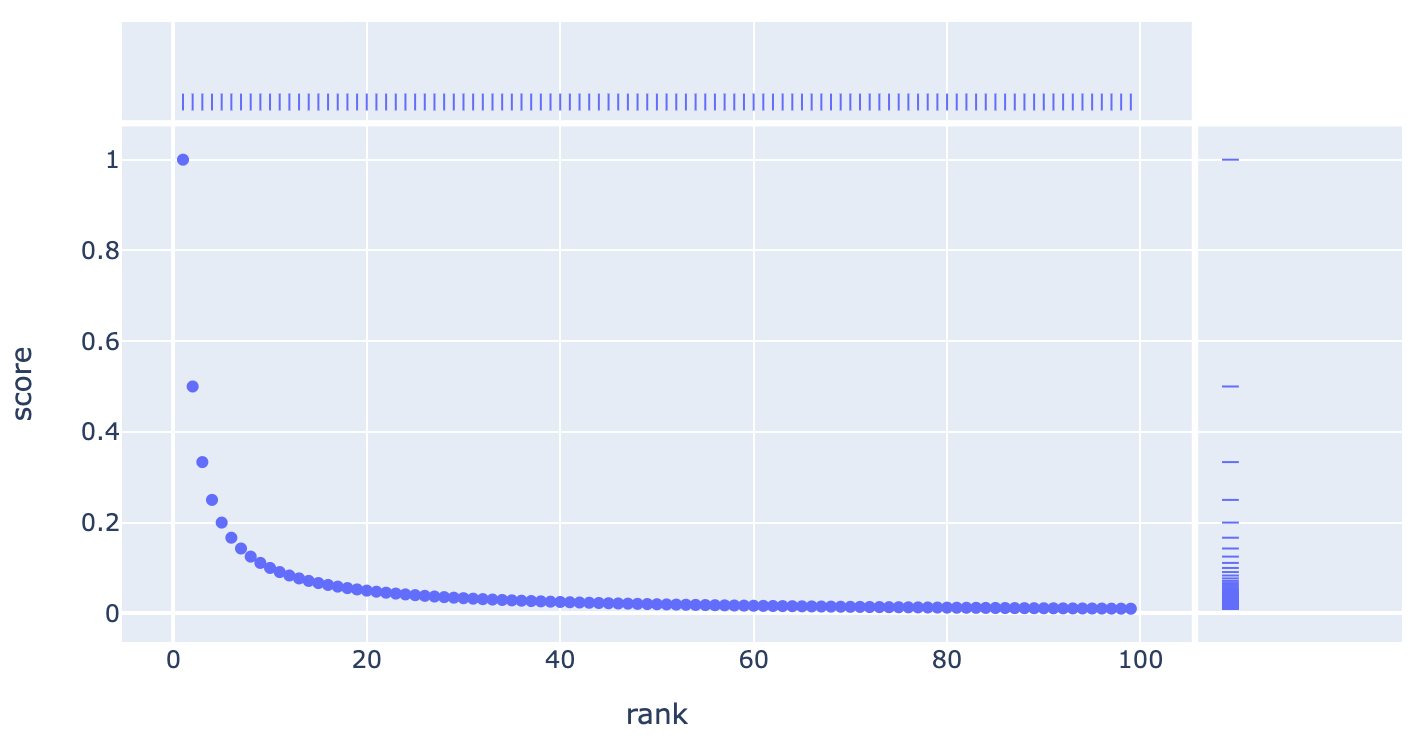
見ての通り同じような減衰しています。実際の検索ログに適用してcorrelationを見ても強い相関があって、同じシナリオ (e.g. binary relevance) で用いる場合にはどちらを使っても意思決定に影響を与えるほどの差がないのでは、とそのときはなりました。
個人的には強い理由がないならgraded relevanceに対応ができて、lossもNDCGを近似するものを使うことがあるのでNDCGを使うべきだと思っています。ただし、見ての通りどちらの指標もinterval scaleではないんですよね。
3. Thou shalt not overstate the precision of your results (Precisionを誇張するな)
50のクエリとその500の観測するときに信頼区間の幅はすごく広いからたかだか小数点以下4桁では優劣は比較できない、とのことですが商用の検索アプリだとミリオンやビリオン単位でサンプルがあることがあるので、あまり問題にはならないと思いました。
4. Thou shalt not compute relative improvements of arithmetic means (相対的な改善の算術平均を計算するな)
しかし実際のところよく行われているし、実のところ私は今日も算術平均を計算しました…。
5. Thou shalt not apply the simple holdout method (単純なholdoutを使うな)
はい!
6. Thou shalt not formulate hypotheses after the experiment (実験のあとに仮説を立てるな)
それは仰るとおりです…。しかし分析を始めてからよりユーザーの行動への解像度が上がって「これってこういうことなのでは?」となることってありませんか。
7. Thou shalt not test multiple hypotheses without correction (Correctionなしに多重検定をするな)
これは一つのexperimentで複数のvariantの検定をするときはもちろん、たとえばとある機能の分析で10個あるカテゴリー (ファッション、家電、食品、…) でそれぞれで α = 0.05 の検定を行うと 1 - (0.95)^10 ≈ 0.4 となり約40%の確率で何もしなくてもどれかが有意になってしまうので、もし多重検定をするならcorrectionしようと思いました。
8. Thou shalt not ignore effect sizes (効果量を無視するな)
社内の分析マニュアルでもEffect Sizeを見よう!とあります。
9. Thou shalt not forget about reproducibility (再現性を考慮しろ)
はい!
10. Thou shalt not claim proof by experimentation (実験をもって証明と言うな)
"our experiments prove"
証明とは、普遍的に成り立つ ∀x P(x) → Q(x) のことであって、実験では一部の結果しか見ることができないのでそもそもおかしいという話です。ビジネスだとonline experimentの結果こそがすべてですが。
Conclusion
この記事では検索エンジニアにとって "評価する" スキルの重要性について議論を見ました。業務上ではコストや説明のしやすさなどを考慮しながら実験の設計を行いますが、いくつかの指摘は現実的で、いくつかの指摘はそこまでの厳密性は要らないのではと考えさせられるものもあり、興味深く読ませていただきました。