クローラ/スクレイピングの手法と使い分け
「初めてのクローラ・スクレイピング」のようなハンズオンをする中でよく頂くご質問に対するまとめです。
クローラのニーズ
Webサイトデータの収集をし、RPAのシナリオ実行や機械学習、さらには営業活動に利用するシーンが多くなってきていると感じます。
機械学習を除いたRPAや営業活動を担当している方は、これまでプログラムの経験が少なく、本来業務の延長としてそもそものやり方や技術的な難易度を測るためにWebサイトデータの収集についてお話を聞きに来る方が増えています。
主にRPAシナリオを実装している方々は自らの手で実装をしたいとハンズオンのご要望も多いです。
ハンズオンをある程度進めるとよく頂く質問があります。
よく頂く質問・疑問
- なぜこの場合はHTTPクライアントとしてヘッドレスブラウザを利用するんですか?
- なぜこの場合はHTTPクライアントとしてrequestsのようなライブラリを利用しているのですか?
Answer
- 抽出・取得したい要素がクライアントサイドで動的に生成されているか否かにより使い分けが必要です。
と回答しているのですが、こう答えるとすんなりとは通じません。(よく意味わからんと言われます。)
初めてクローラを実装する方からするとCSSのような処理とクライアントサイドでAjax通信を行い動的にデータを取得し描画している処理の違いが難しいのだと思います。
記事の流れ
いつもこの流れでお話しているので踏襲します。
- Webの歴史
- 我々が区別すべき箇所
- 実際の対処
Webの歴史
Web初期
- 従来Webサーバに装飾のない静的なHTML(テキスト)を配備し、クライアント(ブラウザ)はHTMLをレンダリングするだけであった

oldest website(http://eo.ucar.edu/skymath/tmp2.html)より引用
Javascirpt/CSSの登場
- Javascriptやcssの登場により多少の装飾が可能となる

CGIの登場
- ついでCGIの登場により、サーバサイドアプリケーションの前進となるクライアントからの要求に応じ、データベースを利用したデータ管理、管理データの返却などが可能となる

歴史あるアクセスカウンターもCGI実装例の一つ
MVCフレームワークの登場
- 技術の進歩と合わせ、CGIに留まらずJavaで言うStruts、Rubyで言うRailsなどMVCなアプリケーションフレームワークが登場し、サーバサイドとクライアントサイドが分離され始める
- 伴いクライアントサイド(ビュー)のデザインを担当するフロントエンドエンジニアが登場するが、CSSやIMGのデザインのみで、処理(Javascript)における部分はサーバサイドエンジニアが担当していた(ことが多かった)
- CGIやMVCではあくまでクライアントサイドのデータ送出に合わせ、サーバサイドアプリケーションが同期処理で応答を返却するのみだった

TODOアプリ(Strutsなどに閉じて実装した例、新しいTODOを追加すると画面全体を再描画する)
Ajaxの登場
- クライアントサイドとサーバサイドのデータ通信において非同期処理を実現するAjaxが登場。
- AjaxはXHRというJavascript組み込みオブジェクトを利用し実現される。
- 同期処理のようにWebページ全体を再度レンダリングすることなく、インタラクティブに描画が変わるAjaxの登場によりフロントエンドエンジニアへの要求も変化していく
- サーバサイドはAjaxの要求に対しデータ(XMLやJSON)を応答するのみ
- Ajaxは要求処理を実装し、応答を補足し適切なDOMに描画する処理まで含めてフロントエンド(Javascript)で実装する
jQueryの登場
- Ajax登場により、簡易なDOM操作に閉じずJavascriptネイティブで実装を続ける事が困難となった背景もあり、DOM操作やAjax操作を簡易に行うJavascirptライブラリが登場
- Ajax、jQueryの登場によりフロントエンドエンジニアが注目を浴び始め、クライアントサイドでもプログラムが動作するようになる
クローラ実装者として区別すべき箇所
- 単純な応答の解析か?
- サーバから返却されクライアントサイドではあくまでプログラムは動作せずレンダリングのみなのか
- 複雑な解析か?
- クライアントサイドのプログラムにより動的に生成されている要素なのか
これについて意識し、HTTPリクエストを送出するクライアントを適切に選ぶ必要がある
実際の対処
単純な応答の解析で良い場合
つまりサーバサイドアプリケーションが応答を動的にhtml(template)に埋め込み描画する場合
- Pythonではrequestsとbeautifulsoup4などを使えば良い
複雑な解析の場合
つまりクライアントサイドプログラムが動的に処理を行いhtmlに描画する場合
- PythonではChromedriverのようなヘッドレスブラウザとSelenium WebDriver、加えてbeautifulsoup4などを使えば良い
判別方法
簡易に確認する
- ①該当DOMがサイト埋め込みのWidjgetっぽい場合はだいぶ怪しい
- 大抵、クライアントサイドのプログラム。Facebookの埋め込みページなど
- ②ブラウザに搭載された開発者ツールを利用し該当サイトの通信を確認しXHR系の通信がある場合は、ちょっと怪しい
- XHR系の通信がある場合は怪しい(下図でいうとXHRをクリックし、フィルタをかけ、XHRの有無を確認)
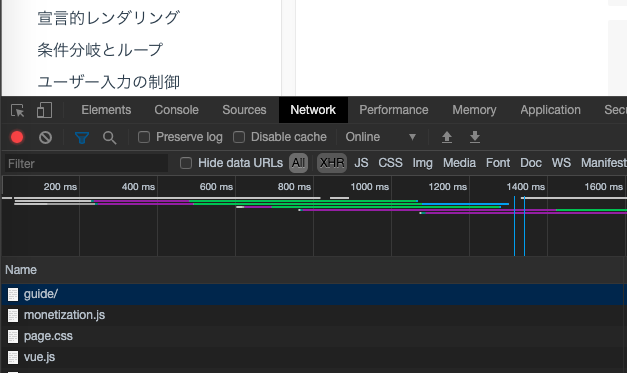
正しく確認する
- ①サイト運営者に聞く(サイト運営が自営または関係者の場合)
- ②実際にやってみる
- httpクライアントを実装し、とりあえずGETしてみる。
- beautifulsoup4などでDOMの解析をしてみる。
以上。