現在私は深層学習を勉強していて、CNN(Convolutional Neural Network)について学んだことをアウトプットするために今回Qiitaに投稿することにしました。
CNN(Convolutional Neural Network)とはなんなのか
Convolutional Neural Network(畳み込みニューラルネットワーク)
- 深層学習の応用的な手法の一つ
- 画像認識で特に優れた実績を収めている
CNNがなぜ画像認識に適しているのか
- CNNは生物の脳の視覚神経系からヒントを得たニューラルネットワークの一種である
- CNNは視覚系における受容野をモデル化している
では実際に受容野のモデルを見てみましょう
視覚系における受容野モデル
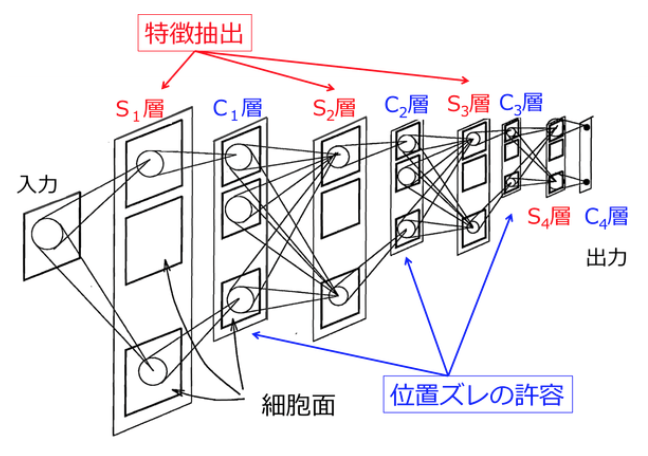
Deep learningで画像認識③〜ネオコグニトロンとは?〜
ここで図中のS層C層は以下の役割をしています
|S層 (単純細胞層 – simple cell)|図形の特徴を抽出|
|:--:|:--:|:--:|
|C層 (複雑細胞層 – complex cell)|位置ズレを吸収する|
上の図は何をしているかというと、
__入力された情報はS層とC層が交互に結合する構造により、 『S層による特徴抽出』と『C層による位置ずれの許容』を繰り返しながら上位の各層に伝搬される様子__を表しています
CNNでは『S層』を『畳み込み層』として、『C層』を『プーリング層』として実装しているため__CNNは画像認識に適している__と言われているのです
| 視覚系における受容野 | Convolutional Neural Network | |
|---|---|---|
| 図形の特徴を抽出 | S層 (単純細胞層–simplecell) | 畳み込み層 |
| 位置ズレを吸収する | C層 (複雑細胞層–complexcell) | プーリング層 |
では次にConvolutional Neural Networkにおける畳み込み層とプーリング層について見ていきましょう
畳み込み層の役割
CNNは入力のあらゆる位置で特徴の比較と一致点の検出を試み、
画像全体にわたって特徴の一致件数を計算し特徴マップを作成します。
この時に実行する演算が__畳込み__といい、__畳み込みニューラルネットワーク__の名称の元となっています。
畳み込みの計算方法
- 特徴の各ピクセルを画像内の対応するピクセル値で掛ける
- 答えを合計し、特徴のピクセルの総数で割る
両方のピクセルが白(値が1)なら1×1=1、両方が黒なら(-1)×(-1)=1となり、
ピクセルが一致する場合の計算結果は全て1で、一致しない場合は全て-1となります
文字だけではわかりづらいので、実際に計算してみましょう
まず入力画像・フィルター・特徴マップを用意します。

入力画像をフィルターを使って畳み込み、特徴マップを埋めていくことが目標となります。

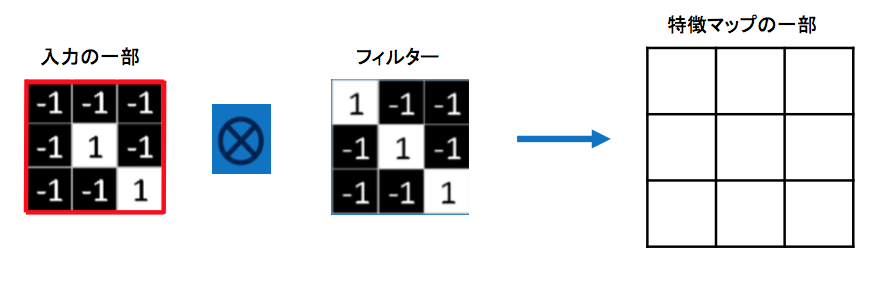
最初に入力画像の一部の赤枠で囲まれた部分をフィルターを使って畳み込んでみます
計算前
計算後
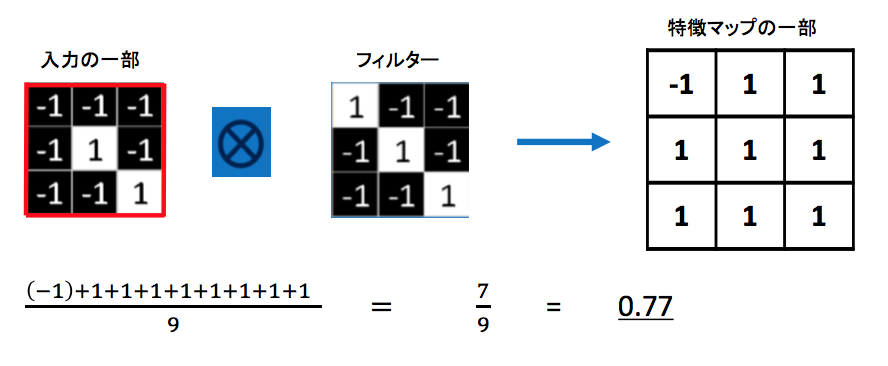
入力の一部の画像ピクセルとフィルターのピクセルを、左上から対応するピクセルごとに掛け合わせていき、足し合わせ、
-1×1 = -1
-1×-1 = 1
-1×-1 = 1
-1×-1 = 1
1×1 = 1
-1×-1 = 1
-1×-1 = 1
-1×-1 = 1
1×1 = 1
(-1) + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 = 7
画像のピクセル数(今回は9)で割り、結果を特徴マップに書き込みます
7 ÷ 9 = 0.77

フィルターを徐々にスライドさせていき、同様に特徴マップに書き込んでいきます
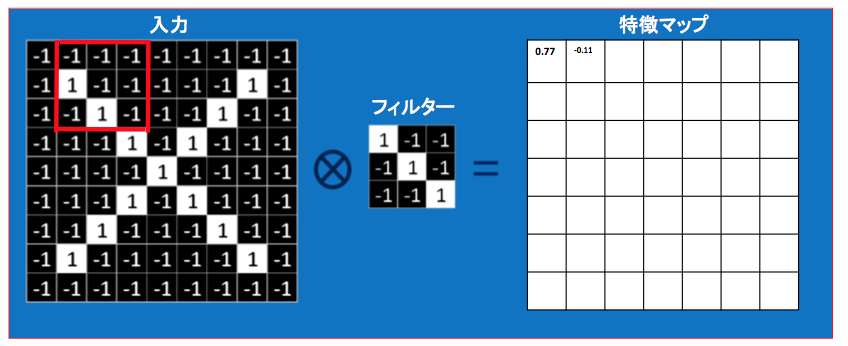
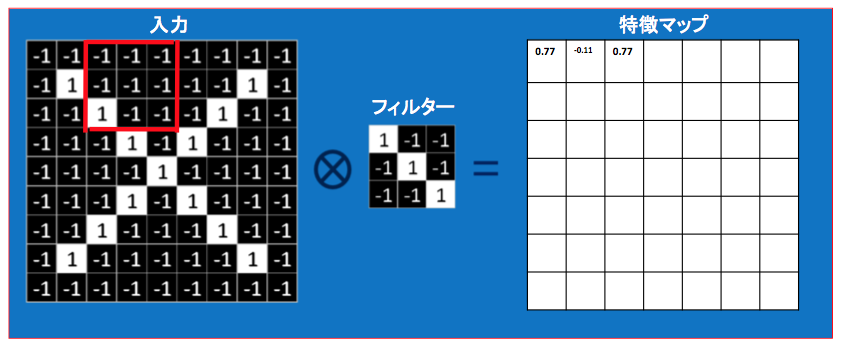

特徴マップを埋め終わったら畳み込みは終了です
プーリング層の役割
- 畳み込み層から出力された特徴マップを縮小し、新たな値を求める
- 大きな画像を重要な情報は残しつつ縮小する方法
- 画像内を小さなウィンドウに区切り、区切ったそれぞれのウィンドウから最大値を取る(max pooling)
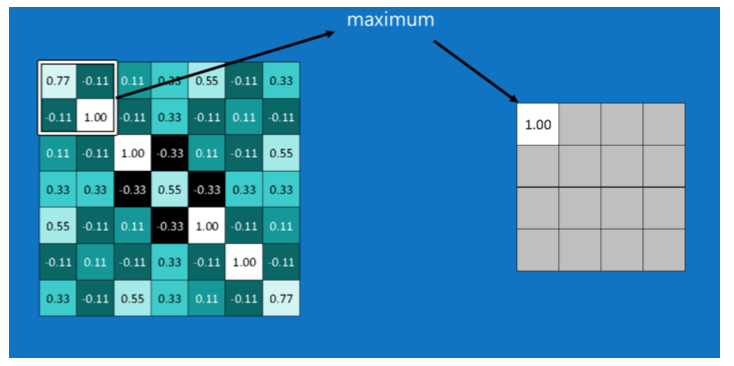
結果として出力される画像枚数は同じだが、それぞれのピクセル数が減少し、
計算の負荷を管理するのにとても便利です

以上となります。
不適切な点や、誤りがありましたらご指摘いただけると幸いです。