はじめに
癒されたい。
現代社会に生きる我々は常に何かに追われ、休まることのない日々を送り続けています。
そんな我々に必要なものは何か。そう、癒しです。テクノロジーの力で癒されましょう。
1/fゆらぎ
近年リラクゼーション効果があるとして注目されている[誰によって?]のが1/fゆらぎです。1/fゆらぎはこのように定義されています。
1/fゆらぎ(エフぶんのいちゆらぎ)とは、パワー(スペクトル密度)が周波数 f に反比例するゆらぎのこと。ただし f は0より大きい、有限な範囲をとるものとする。
- Wikipedia 「1/fゆらぎ」2022/6/30 10:38 (UTC)
は?(半ギレ)
1/fゆらぎの音
ここはもう少しわかりやすい具体例として音を使いましょう。ご存知の方も多いと思いますが、音は波として表すことができます。例えばこれが波の形が正弦波になるような音です。最初の方は音が聞こえない方もいるかもしれませんが、それは周波数が我々人類の可聴域ギリギリだからです。PCの故障ではありません。
ここで驚くべきことに、あらゆる音は振幅・周波数・位相をうまく調整した正弦波をいっぱい足すことで作ることができます。
1/fゆらぎを作るときにも正弦波音をいっぱい重ね合わせることを考えます。ただしここで、振幅が周波数に反比例するようにします。 つまりこんな感じです。
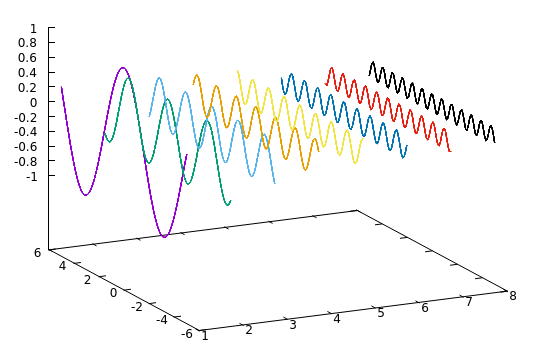
こんな感じに正弦波をいっぱい重ね合わせて作れる音(というか波)が1/fゆらぎです。自然界に存在する様々な現象、例えば炎の揺れ方とか川の音とかが1/fゆらぎになっているそうです。1/fゆらぎに癒し効果があるとされるのもこの辺と関係があるんですかね。
また、このようにして作られる波は別名ピンクノイズとも呼ばれます。「ピンク」の由来はちゃんと説明するのが面倒なのでWikipedia見てください
作ってみよう
というわけで、どうやらピンクノイズは$\frac{1}{x}$を逆フーリエ変換するだけで作れちゃいそうです。なのでこんなことを試します。
import numpy as np
import sounddevice as sd
# 再生するときのサンプリング周波数 [Hz]
audio_sampling_rate = 44100
# 再生時間 [s]
audio_play_time = 1
# 必要なサンプル数
audio_sample_num = audio_sampling_rate * audio_play_time
# 周波数領域におけるピンクノイズ
## 一番最初の0は直流成分。
## ただどうせ後で波全体が-1~1の範囲に収まるように調整するので、直流成分は何でもいい
pink_in_freq_dom = [0, *[1 / (i + 1) for i in range(audio_sample_num // 2)]]
# 逆フーリエ変換で周波数領域から時間領域へ
pink = np.fft.irfft(pink_in_freq_dom)
# -1~1の範囲に調整
pink = (pink - pink.min()) / pink.ptp() * 2 - 1
# 再生
sd.play(pink, samplerate=audio_sampling_rate)
sd.wait()
ですがこれではまだ駄目です。
ハマりポイントその1
上のプログラムで作れるピンクノイズはこんな形をしています。なんだこれ...

フーリエ変換に深入りするのはここでは避けます何より私が理解していないが、適当な波のフーリエ変換を$F$とすると$|F(f)|$が周波数$f$の波の振幅、$\arg F(f)$が周波数$f$の波の位相を表しています。
ここでさっきのコードを見てみましょう。
pink_in_freq_dom = [0, *[1 / (i + 1) for i in range(audio_sample_num // 2)]]
これを逆フーリエ変換してピンクノイズを作ることを試みたわけですが、1 / (i + 1)は当然全部実数です。よって偏角も全部0なので、すべての波の位相がそろってしまっていることになります。その結果がさっき見たU字型みたいな変な波です。
ところでどうやらこの変なのは$\sum_{n=1}^\infty \frac{\cos(nx)}{n}=-\frac{\ln(2-2\cos(x))}{2}$のようです。もちろんこれでもピンクノイズの定義自体は満たしているのですが、音としてはまともに再生できないので何とかしましょう。
ハマりポイントその2
そういうわけなので適当に位相をずらしてやりましょう。あまり深く考えていませんが、乱数を使って適当にばらつかせるだけでも大丈夫なはずです。
pink_in_freq_dom = [0, *[complex(1 / (i + 1), np.random.rand() * 2 * np.pi) for i in range(audio_sample_num // 2)]]
ヨシ!🐱👉 (よくない)
これでもまだ駄目です。complexは実部と虚部を受け取るものなので、絶対値と偏角を渡してはいけません。こんなつまらないミスで数時間が溶けた complexの代わりにcmath.rectを使いましょう。
完成品
これでやっとまともに動くようになります。使いやすく関数化してこんな感じになります。
import cmath
import numpy as np
import sounddevice as sd
from collections.abc import Sequence
def create_pink_noise(sample_size, normalization=None):
"""
@fn create_pink_noise()
@brief ピンクノイズ作るマン
@param sample_size 欲しいサンプル数
@param normalization Noneまたは長さ2の数シークエンス。[a, b]や(a, b)などが渡されたら最小値がa,最大値がbになるように調整する。
"""
pink_in_freq_dom = [0, *[cmath.rect(1 / (i + 1), np.random.rand() * 2 * np.pi) for i in range(sample_size // 2)]]
pink = np.fft.irfft(pink_in_freq_dom)
if normalization is None:
return pink
elif not isinstance(normalization, Sequence):
raise TypeError(f'parameter "normalization" is not sequence.')
elif len(normalization) != 2 or normalization[0] > normalization[1]:
raise ValueError(f'parameter "normalization" is invalid.')
else:
pink = (pink - pink.min()) / pink.ptp() # [0, 1]
pink *= normalization[1] - normalization[0] # [0, normalization[1] - normalization[0]]
return pink + normalization[0] # [normalization[0], normalization[1]]
# 再生するときのサンプリング周波数 [Hz]
audio_sampling_rate = 44100
# 再生時間 [s]
audio_play_time = 1
# 必要なサンプル数
audio_sample_num = audio_sampling_rate * audio_play_time
# ピンクノイズ
pink = create_pink_noise(audio_sample_num, [-1, 1])
# 再生
sd.play(pink, samplerate=audio_sampling_rate)
sd.wait()
ところでこれが本当にピンクノイズになっているかちゃんと確かめたいところです。というわけでこんな関数を作ります。各周波数成分の音量を表示するやつです。
import matplotlib.pyplot as plt
def show_frequency_response(data):
data_fft = np.fft.rfft(data)
plt.xscale('log')
plt.xlabel('Frequency [Hz]')
plt.ylabel('Intensity [dB]')
plt.plot(20 * np.log10(np.abs(data_fft)))
plt.show()
show_frequency_response(pink)はこんな感じになります。縦軸の単位はデシベル、横軸は対数軸になっていることに注意してください。
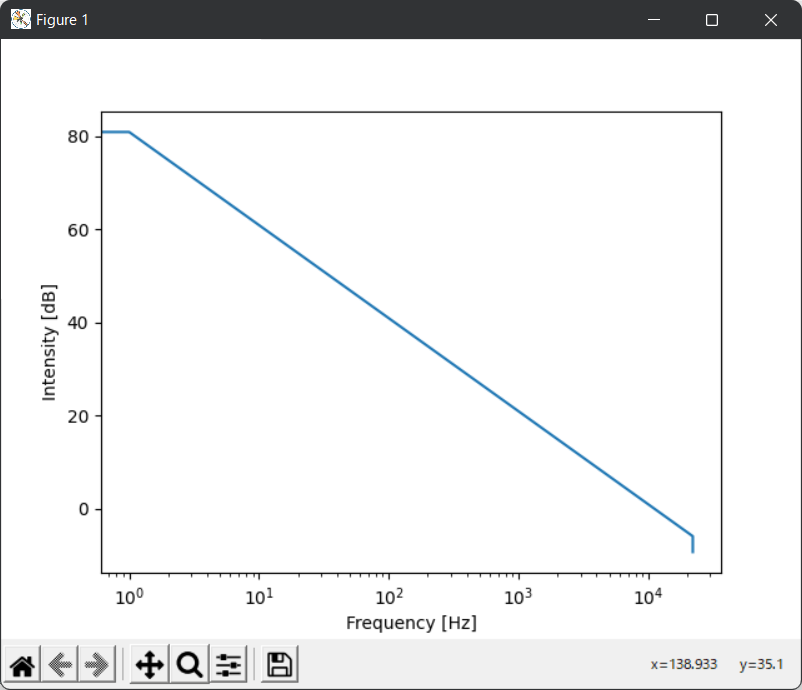
大丈夫そうですね。
1/fの音
これがテクノロジーの力で生み出された癒しの音です。画像はイメージ(image is image)です。
う~ん、よくわからん。 言われてみれば滝の音や草木のそよぐ音に聞こえないこともないような...
色を揺らがせてみる
なんかよくわからなかったので、別の例も試してみましょう。1/fゆらぎを使って色を揺らがせてみます。
import colorsys
import tkinter
from itertools import cycle
class Gradater(object):
def __init__(self, ms_interval):
"""
@fn __init__()
@param ms_interval 色が変わる周期(ミリ秒)
"""
self.__name__ = self.__class__.__name__
self._ms_interval = ms_interval
self._pink_hue = cycle(create_pink_noise(44100, [0, 1]))
def __call__(self, window):
window.configure(background=Gradater._hsv_to_rgb_string(next(self._pink_hue), .3, 1))
window.after(self._ms_interval, self, window)
def _hsv_to_rgb_string(h, s, v):
r, g, b = colorsys.hsv_to_rgb(h, s, v)
return f'#{int(r * 255):02x}{int(g * 255):02x}{int(b * 255):02x}'
gradation_window = tkinter.Tk()
gradation_window.after(0, Gradater(1), gradation_window)
gradation_window.mainloop()
結果がこちらです。
なんかめっちゃチッカチカしてます。これでは癒されるどころではありません。
チカチカしすぎているのは周波数が高い成分のせいです。なのでピンクノイズの合成に用いる波の数を指定できるようにし、高周波は入ってこないようにしましょう。
def create_pink_noise_n(sample_size, wave_count, normalization=None):
"""
@fn create_pink_noise_n()
@brief n個の波からピンクノイズ作るマン
@param sample_size 欲しいサンプル数
@param wave_count ピンクノイズの合成に使う波の個数
@param normalization Noneまたは長さ2の数シークエンス。[a, b]や(a, b)などが渡されたら最小値がa,最大値がbになるように調整する。
"""
pink_in_freq_dom = [0, *[cmath.rect(1 / (i + 1), np.random.rand() * 2 * np.pi) for i in range(wave_count)]]
pink = np.fft.irfft(pink_in_freq_dom, n=sample_size)
if normalization is None:
return pink
elif not isinstance(normalization, Sequence):
raise TypeError(f'parameter "normalization" is not sequence.')
elif len(normalization) != 2 or normalization[0] > normalization[1]:
raise ValueError(f'parameter "normalization" is invalid.')
else:
pink = (pink - pink.min()) / pink.ptp() # [0, 1]
pink *= normalization[1] - normalization[0] # [0, normalization[1] - normalization[0]]
return pink + normalization[0] # [normalization[0], normalization[1]]
def create_pink_noise(sample_size, normalization=None):
return create_pink_noise_n(sample_size, sample_size // 2, normalization)
10個の波だけでピンクノイズを作るとこんな感じになります。
う~ん、癒されるようなそうでもないような...
まとめ
一部の人は1/fゆらぎを含む声が出せるそうです。
1/fゆらぎが一部の人間の歌声にも現れると主張されることもある。代表的な例としてMISIA、美空ひばり、宇多田ヒカル[15]、徳永英明[16]、Lia[17][18]、Aimer[19]、宇徳敬子[20]、大野智[21]などが持つとされる。
また、声優の大本眞基子[22]、花澤香菜[23]、俳優・ナレーターの森本レオやモノマネ芸人の青木隆治、更にはダチョウ倶楽部の肥後克広が森本の声真似をしているときの声も該当すると言われる[15]。
- Wikipedia,同前
結論: 癒されたいならこんなわけのわからないプログラム作ってないで花澤さんの声を聴いてください。~おわり~