はじめに
国土交通省が公開している「水文水質データベース」は、様々なデータを提供している。しかし、データのダウンロードがなんか複雑で、複数年に対するダウンロード機能はサポートしていない。
Github上にはこのような難しさの解決のため、多数のコードやプロジェクトが公開されているが、コードだけで実行するものや、積極的なGUI要素を利用したプロジェクト・プログラムはその数が未だ少ない。
以上のような現状の問題を踏まえて、PyQt5やPyInstallerなどのライブラリを利用し、水文水質データベース上のデータの簡単な取得・確認のためのプログラムの作成を始めた。
機能の追加・修正は現在進行形ではあるが、一部の機能の実装やexeファイルの実装は終わっており、実際に複数のデータにおいて有効に使えるため、そのリンクを貼っておく。
以下のページからexeプログラムのダウンロードができる。
簡単な説明や利用方法に関してはこのページで確認できる。
水文水質データベースからのデータ取得方法
mainコード (WIS_InfoWindow.py)
・サイトの基本情報へのアクセス
水文水質データベースのリンクの構造は以下のようになっている。

このリンクは要するに、項目(KOMOKU)、水系(SUIKEI)、県(KEN)に有効な値を与えるだけで表面的な情報に接近することができる。
また、各々の項目に対する情報は、次のようにサイトのhtml上で確認できる。
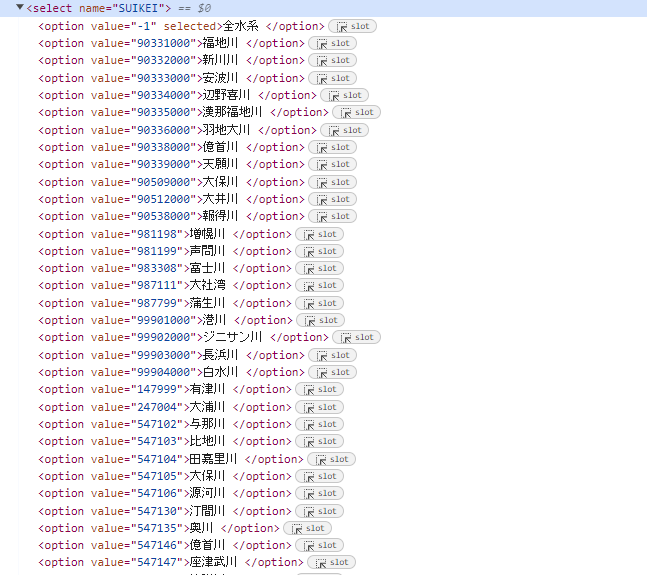
また、各々のValueに正しい値を与えれらば、tableにその値に該当該当するリストが表示される。
このような構造から、PyQt5や多数のライブラリを利用し、プログラム上の表示した。
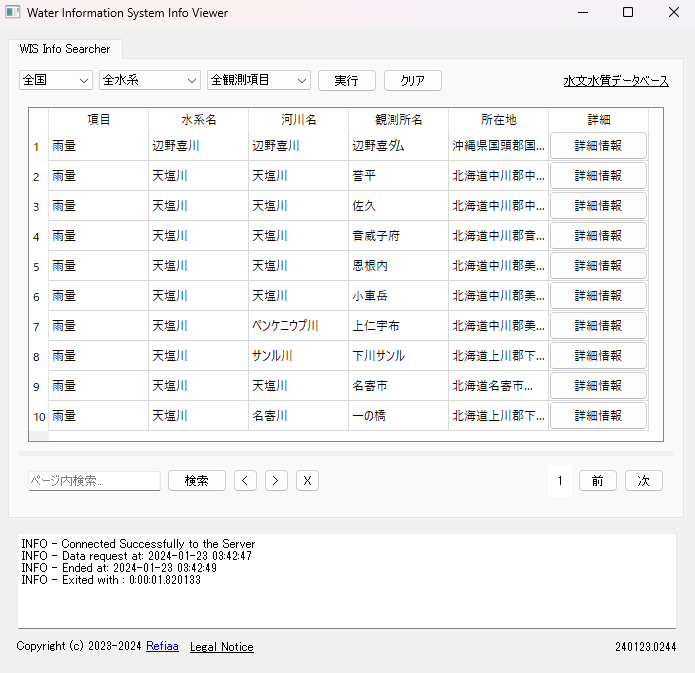
項目(KOMOKU)、水系(SUIKEI)、県(KEN)などのデータはjson化し、drop-down listで選択できるようにした。
# WIS_InfoWindow.py
def loadComboBoxData(self):
self.kenData = self.loadJsonData('./json/ken_values.json')
for ken in self.kenData:
self.kenComboBox.addItem(ken)
self.suikeiData = self.loadJsonData('./json/suikei_values.json')
for suikei in self.suikeiData:
self.suikeiComboBox.addItem(suikei)
self.komokuData = self.loadJsonData('./json/komoku_values.json')
for komoku in self.komokuData:
self.komokuComboBox.addItem(komoku)
Table上のデータの取得は、getWISInfo.py(コードの名前に関してはPEP8規約などを全く考慮せずに適当に付けました。)で行っている。
# WIS_InfoWindow.py
from getWISInfo import RiverDataScraper
また、プログラム上では表示されていないが、サイトのリスト上の各々の川ー水系の項目は次のような値を持っている。
JavaScript:SiteDetail1('101010190001010')
getWISInfo.pyはこのような情報の取得を目標とした。
サイト上では、リンクをクリックすることで、その観測所の詳細情報にアクセスできる。
また、このアクセスは、JavaScript:SiteDetailを利用することでアクセスできるようになっている。

プログラム上では、getWISInfo.pyが所得したjs_detailを利用することで、同じ内容にアクセスできようにした。
# WIS_InfoWindow.py
btn = QPushButton('詳細情報')
btn.clicked.connect(lambda checked, js_detail=javascript_detail:self.onDetailButtonClicked(js_detail))
self.tableWidget.setCellWidget(row_count, 5, btn)
row_count += 1
プログラム上では、詳細情報をクリックすると、関数onDetailButtonClickedにjs_detailが伝達され、観測所の情報にアクセスできるようにした。
・観測所の詳細情報へのアクセス
水文水質データベースのサイト上で観測所の詳細情報にアクセスした場合、次のような画面が表示される。
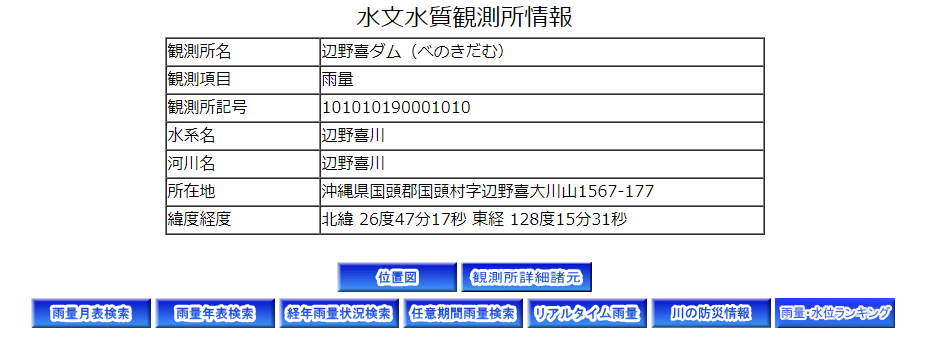
プログラム上では、このページより詳細な情報を提供することを目的としたため、次のようになっている。
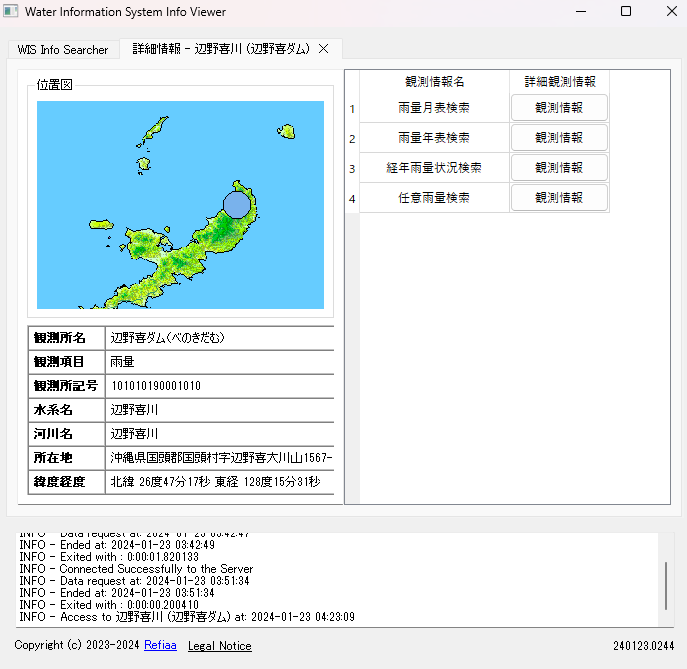
左の情報の中、位置図はサイトの位置図の項目から確認できるようになっている。
位置図の情報にアクセスするためのリンクの構造は以下のようである。

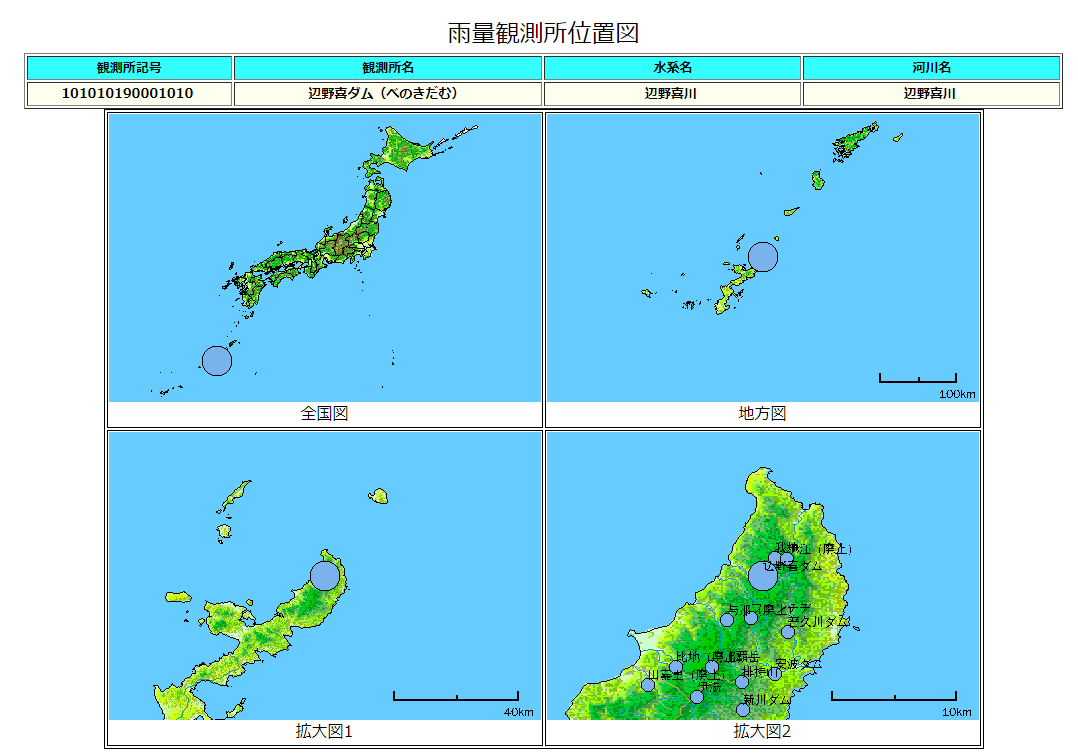
上のように、js_detail以外にも、SIDOとSKEIDOという値が使われている。
つまり、この中で実際に使われている情報は、緯度・経度・js_detailだけになる。
しかし、詳細情報のページで提供している情報は度分秒のデータであり、イメージにアクセスするためのSIDO、SKEIDOとは少し形が違う。
従って、次のようなコードを利用し、取得した移動・経度をSIDO, SKEIDOの形式に変換した。
# WIS_InfoWindow.py
@staticmethod
def extractCoords(coord_string):
degrees = [int(match) for match in re.findall(r'(\d+)度', coord_string)]
minutes = [int(match) for match in re.findall(r'(\d+)分', coord_string)]
seconds = [int(match) for match in re.findall(r'(\d+)秒', coord_string)]
latitude = f"{str(degrees[0]).zfill(3)}{str(minutes[0]).zfill(2){str(seconds[0]).zfill(2)}000"
longitude = f"{str(degrees[1]).zfill(3)}{str(minutes[1]).zfill(2){str(seconds[1]).zfill(2)}000"
return latitude, longitude
この情報はgetDetailInfo.pyのMapImageScraperに伝達され、特定の画像(拡大図1)の取得に使われた。
# getDetailInfo.py
class MapImageScraper:
def __init__(self, js_detail, latitude, longitude):
self.js_detail = js_detail
self.latitude = latitude
self.longitude = longitude
self.base_url = "http://www1.river.go.jp/cgi-bin/"
def scrape_image_url(self):
url = f"{self.base_url}DspMapPosition.exe?MODE=01&MAP=0&ID={self.js_detail}&SIDO={self.latitude}&SKEIDO={self.longitude}"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
image_element = soup.find('img', alt="拡大図1")
if image_element:
return self.base_url + image_element['src']
return None
以外の情報に対しても似たような方法で取得してページ上に表示した。
右に表示される「詳細観測情報」に関しては、一部の情報を除いて取得してくる方法を選択した。
import requests
from bs4 import BeautifulSoup
class ObservedInfoScraper:
def __init__(self, js_detail):
self.base_url = "http://www1.river.go.jp/cgi-bin/SiteInfo.exe?ID="
self.js_detail = js_detail
def scrape(self):
url = self.base_url + self.js_detail
response = requests.get(url)
response.encoding = 'EUC-JP'
soup = BeautifulSoup(response.text, 'html.parser')
data = []
for img_tag in soup.find_all('img'):
alt_text = img_tag.get('alt')
if alt_text and alt_text not in ["位置図", "観測所詳細諸元", "リアルタイム雨量", "川の防災情報", "雨量・水位ランキング検索", "リアルタイム水位", "リアルタイムダム諸量検索"]:
data.append(alt_text)
return data
位置図, 観測所詳細諸", リアルタイム雨量, 川の防災情報, 雨量・水位ランキング検索, リアルタイム水位, リアルタイムダム諸量検索を詳細観測から排除した理由は次のようである。
・位置図は既に引用していること。
・観測所詳細諸も既にプログラムの表示のために引用していること。
・それ以外の情報に関しては、水文水質データベースじゃないサイトになるか、データのアクセスが困難だった。
よって、右のtableには以上のデータを除外したものだけ表示できるようにした。
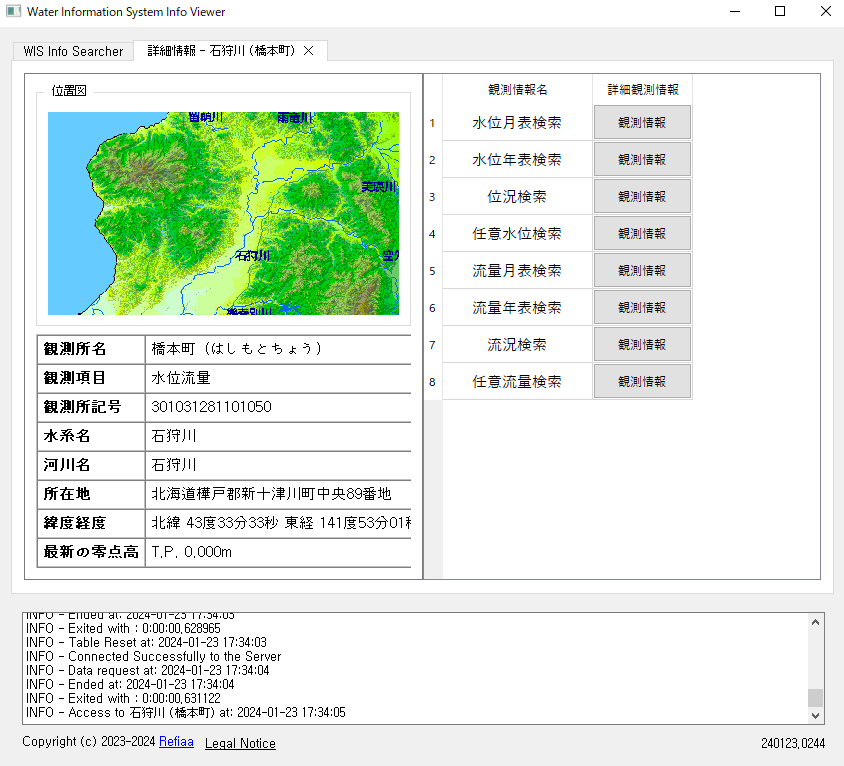
また、詳細情報ページに関してはPyQt5.WidgetsのQTabBarなどを利用しタブとして扱い、複数のページを同時に開けるようにした。
またQThreadを利用することでMulit-Threading動作ができるようにした。
上の内容以外の機能、ページ内検索や、ページ移動に関しては省略する。
詳細情報ページ (WIS_DetailInfoWindow.py)
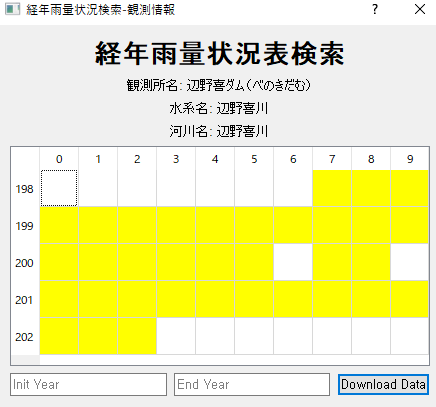
詳細観測情報をクリックすることで、上のようなページに接近することができる。
このページの作成のために主に二つの要素を考慮した。
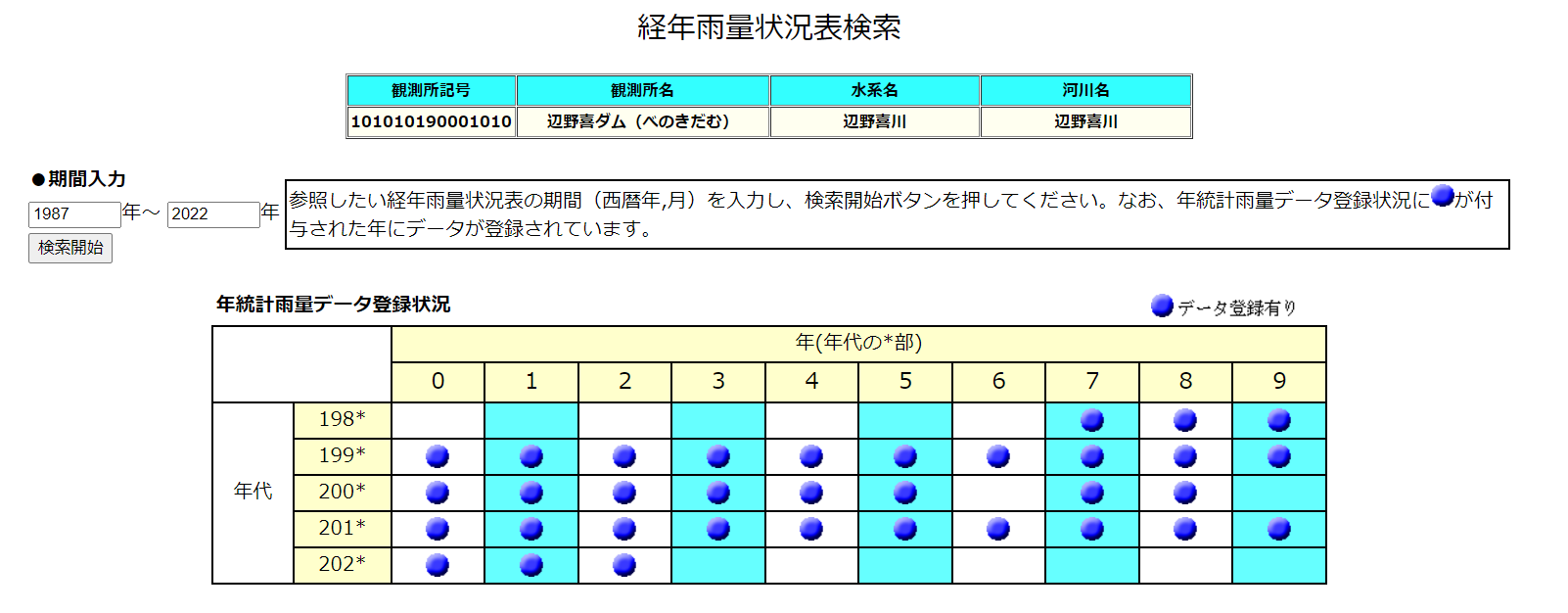
1.水文水質データベースが提供しているデータは、欠測値が存在していること。
2.時間の範囲を入力することで、その範囲のデータを自動的にダウンロードできるようにすること。
1のデータの欠測値に対応するには、データの有無をサイトでどう判断しているかをまず確認しなければならない。
htmlから確認したところ、水文水質データベースは欠測値の判断を次のような方法で行っていた。

imgがari.gifであればデータが存在している判定、nashi.gitであればデータが存在しない判定。
つまり、table上のデータからariかnashiかを判断することで欠測値・データ有無確認ができるようになる。
# SrchRainData.py
def fetch_table_data(self):
url = f"{self.BASE_URL}{self.data_type}.exe?ID={self.js_detail}&KIND{self.kind_value}&PAGE=0"
response = requests.get(url)
response.encoding = 'EUC-JP'
if response.status_code != 200:
return "Error accessing the page"
soup = BeautifulSoup(response.text, 'html.parser')
rows = soup.find_all('tr')
data_list = []
for row in rows:
cells = row.find_all('td')
for i, cell in enumerate(cells):
if cell.get('bgcolor') == "#FFFFCC":
current_year = cell.get_text(strip=True).replace('*', '')
data_cells = cells[i+1:i+11]
for j, data_cell in enumerate(data_cells):
img_tag = data_cell.find('img')
if img_tag:
img_src = img_tag['src']
status = 'ari' if 'ari.gif' in img_src else 'nashi'
year_data = f"{current_year}{j} - {status}"
data_list.append(year_data)
break
return data_list
以上のコードを利用することで、水文水質データベースのサイト上のデータの有無、つまりari.gifかnashi.gifなのかを判断した。また、html上の198*などの日付などから年度を取得し、*に0から9までの値を与えることで、ari、nashiを年度と一緒に扱えるようにした。
このデータは
# WIS_DetailInfoWindow.py
table_data = data_handler.fetch_table_data()
self.display_table_data(table_data)
に伝達され、以下のコードに伝達される。
# WIS_DetailInfoWindow.py
# tableデータを表示
def display_table_data(self, table_data):
self.table_widget = QTableWidget()
self.table_widget.setColumnCount(10)
self.table_widget.setHorizontalHeaderLabels([str(i) for i in range(10)])
self.table_widget.verticalHeader().setVisible(True)
table_dict = self.prepare_table_dict(table_data)
self.table_widget.setRowCount(len(table_dict))
# tableデータの動的処理やレイアウトサイズ決定
total_height = self.table_widget.horizontalHeader().height()
for i, (decade, statuses) in enumerate(table_dict.items()):
for j, status in enumerate(statuses):
item = QTableWidgetItem()
if status == 'ari':
item.setBackground(QColor(255, 255, 0))
item.setFlags(item.flags() & ~Qt.ItemIsEditable)
self.table_widget.setItem(i, j, item)
header_item = QTableWidgetItem(decade)
header_item.setFlags(header_item.flags() & ~Qt.ItemIsEditable)
self.table_widget.setVerticalHeaderItem(i, header_item)
total_height += self.table_widget.rowHeight(i)
layout_height = total_height + 5
self.table_widget.setFixedHeight(layout_height)
self.table_widget.horizontalHeader().setSectionResizeMode(QHeaderView.Stretch)
self.additional_container.addWidget(self.table_widget)
self.additional_container.addStretch(1)
日付の入力には簡単なロジックを適用した。
# WIS_DetailInfoWindow.py
def data_confirm(data_type):
def decorator(func):
def wrapper(self, *args, **kwargs):
start_str = self.start_input.text()
end_str = self.end_input.text()
if data_type == 'date':
if not all(char.isdigit() or char == '/' for char in start_str + end_str):
QMessageBox.warning(self, "警告", "Invalid input")
return
try:
start_year, start_month = map(int, start_str.split('/'))
end_year, end_month = map(int, end_str.split('/'))
if not (1 <= start_month <= 12) or not (1 <= end_month <= 12):
QMessageBox.warning(self, "警告", "Invalid Month")
return
if start_year > end_year or (start_year == end_year and start_month > end_month):
QMessageBox.warning(self, "警告", "Invalid range")
return
except ValueError:
QMessageBox.warning(self, "警告", "Invalid Date Format")
return
func(self, start_year, end_year, start_month, end_month)
elif data_type == 'year':
if not start_str.isdigit() or not end_str.isdigit():
QMessageBox.warning(self, "警告", "Invalid input")
return
start_year = int(start_str)
end_year = int(end_str)
if start_year > end_year:
QMessageBox.warning(self, "警告", "Invalid range")
return
func(self, start_year, end_year)
return wrapper
return decorator
また、入力した年度の範囲がdate list上に欠測値がある範囲であれば、ダウンロードが行われないように次の関数を使った。
# WIS_DetailInfoWindow.py
# dataの実際の配列での有効範囲検証
def validate_years_range(self, data_handler_class, kind_value, start_year, end_year):
data_handler = data_handler_class(self.js_detail, kind_value, start_year, end_year)
filtered_years = data_handler.filter_years()
all_years_in_range = [str(year) for year in range(start_year, end_year + 1)]
if not all(year in filtered_years for year in all_years_in_range):
QMessageBox.warning(self, "警告", "Invalid Data range")
return False
return True
正しい範囲を入力し、Downloadボタンを入力することで、ダウンロードが実行される。
# WIS_DetailInfoWindow.py
@date_input(input_type='date')
def add_date_input_fields_water_2(self):
self.confirm_button.clicked.disconnect()
self.confirm_button.clicked.connect(self.on_data_confirm_water_2)
@data_confirm(data_type='date')
def on_data_confirm_water_2(self, start_year, end_year, start_month, end_month):
if not self.validate_years_range(SrchWaterData_2, 2, start_year, end_year):
return
data_handler = SrchWaterData_2(self.js_detail, 2, start_year, start_month, end_year, end_month)
data_handler.scrape_data_for_months()
QMessageBox.information(self, "Download Complete", "Data download completed successfully.")
データの実際の取得は以下のロジックよりダウンロードされる。
# SrchWaterData.py
class SrchWaterData_3(BaseSrchWaterData):
def __init__(self, js_detail, kind_value, start_year=None, end_year=None):
super().__init__(js_detail, kind_value, "SrchWaterData")
self.start_year = start_year
self.end_year = end_year
self.station_data = self.fetch_station_data()
def scrape_data_for_years(self):
for year in range(self.start_year, self.end_year + 1):
self.scrape_data_for_year(year)
def scrape_data_for_year(self, year):
url = f"{self.BASE_URL}DspWaterData.exe?KIND={self.kind_value}&ID={self.js_detail}&BGNDATE={year}0131&ENDDATE={year}1231&KAWABOU=NO"
response = requests.get(url)
response.encoding = 'EUC-JP'
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
link_tag = soup.find('a', href=True, target="_blank")
if link_tag:
temp_number = link_tag['href'].split('/')[-1].split('.')[0]
self.download_data_file(temp_number, year)
def download_data_file(self, temp_number, year):
download_url = f"http://www1.river.go.jp/dat/dload/download/{temp_number}.dat"
response = requests.get(download_url)
if response.status_code == 200:
self.save_to_file(response.content, year)
def save_to_file(self, content, year):
if self.station_data:
directory = f"./Download/SrchWaterData_{self.kind_value}_{self.station_data.get('水系名', 'Unknown')}_{self.station_data.get('河川名', 'Unknown')}_{self.station_data.get('観測所名', 'Unknown')}"
else:
directory = f"./Download/SrchWaterData_{self.kind_value}_{self.js_detail}"
if not os.path.exists(directory):
os.makedirs(directory, exist_ok=True)
file_path = os.path.join(directory, f"{year}.dat")
with open(file_path, "wb") as file:
file.write(content)
簡略した説明であるため、細かいロジックの説明や内容は省略された。
(kind valueに対する説明、data_type_codeに対する説明など、多数)
筆者のプログラミング実力の不足により、コードが余計に長くなってしまったことも理由の一つである。
しかし、ダウンロードやデータ確認には有効に使えると思い、少し書いておいた。
もっと細かい説明に関しては後に更新する予定である。