これはPython Advent Calendar 2019の13日目の記事です。
Python要素薄めになっちゃったけど、スクレイピングの文脈でPythonよく出てくる気がするから許してください
概要
- (自分なりの)スクレイピングシステム構築方法のベストプラクティス的なものがちょっとだけ定まった
- 公開していろいろ意見を聞いてみたい
- たぶんウェブデベロッパーがスクレピングやるときに知っておくとちょっとだけ幸せになるかもしれない
- 誰かの役に立てればいいなあ(希望)
構築方法の重要な点
重要な点は以下の2点
- DOMにアクセスしてデータを取得するスクレイピングする処理部分はJavaScriptを使う(とくにウェブデベロッパーの方は)
- Chrome, ChromeDrive, Seleniumとかのスクレピング環境にはDockerとかを使う
構成図は以下のような感じです。(OSとか書いてないけど、だいたいのイメージ)
Pythonの部分は任意でSeleniumを叩ければなんでもいいです。(以下のPythonはSeleniumを使うモノとして読み替えてください)
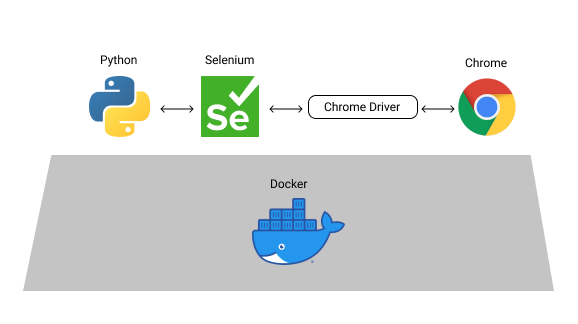
JavaScriptを使ってスクレイピング処理
スクレピング関係のシステムを作るときにめんどくさいのはライブラリ選定だったりします。
個人的にPythonは好きだったりするので、昔はPyQueryとかBeautifulSoupを触っていました。
しかし、結構かなり面倒くさいです。
どういう風にセレクタを書けばいいのかググって実行して、ミスって、修正して、...みたいな感じなります。
最終的な結論が「Chrome Developer ToolsでJSのセレクタを書いて、欲しい情報を取得するJSを書いて、それをSeleniumから実行させる」です。(これが一番楽だと思います。)
(おそらくjQueryを触ったことがある人なら一番とっつきやすいはず)
以下のようなかんじ。
res = driver.execute_script(driver, """
return (() => {
// 以下をChrome Developmer Toolsでいろいろ試して作成する
let tmp = [];
$(".sample-area li a").each( (idx, element) => tmp.push($(element).attr("href")) )
return tmp
})()
""")
Chrome Developmer Toolsは以下のようなやつ。F12とか押したらでます。(Consoleタブを開くとJSがページ内で実行できます)
簡単な話、クラス情報とか丸コピして$(".class").text()とかやるだけでデータとってこれたりします。

これをライブラリの特有の関数でいろいろやろうと思うとめんどくさいのはなんとなくわかるとおもいます。
また、スクリプトがJSなのでスクレイピングライブラリに依存せずに、移植も楽です。
Chrome, ChromeDrive, Seleniumとかのスクレピング環境にはDockerとかを使う
ChromeDriverの設定とかChromeとのバージョンの相性とかいろいろやるのは人生の無駄遣いです。
Dockerとか環境をまるっともってこれるものを使いましょう。
単純なHTML,CSSのみで構成されているサイトならcurlとかで引っ張ってきてやるのもいいと思います。(単純なウェブサイトなら←ここ重要)
サーバーサイドでレンダリングされていても、内部のJSでわりとなんかゴリゴリいじってるサイトは多いです。
Python + Chrome + ChromeDrive + Seleniumの構成のサンプルを作ってみたのでスターをつけてもらうと喜びます。↓
https://github.com/redshoga/python-selenium-container
実装の流れ
- スクレピングで取得したいデータ、場所を明確にする。
- Chrome Developer Toolsでその取得したいデータが取得できるスクリプトを作成。
- Seleniumで作ったスクリプトを動かしてデータを煮るなり焼くなりする。
おわり
マサカリダニゲロー>🐈💨💨 🔪💨