魔法は釣りです。
そこまで使い勝手はよくないです。
概要
「日本語単語→英単語」の辞書からMicrosoft IMEの辞書を作成し、追加しただけ。
以下のような感じでできる。
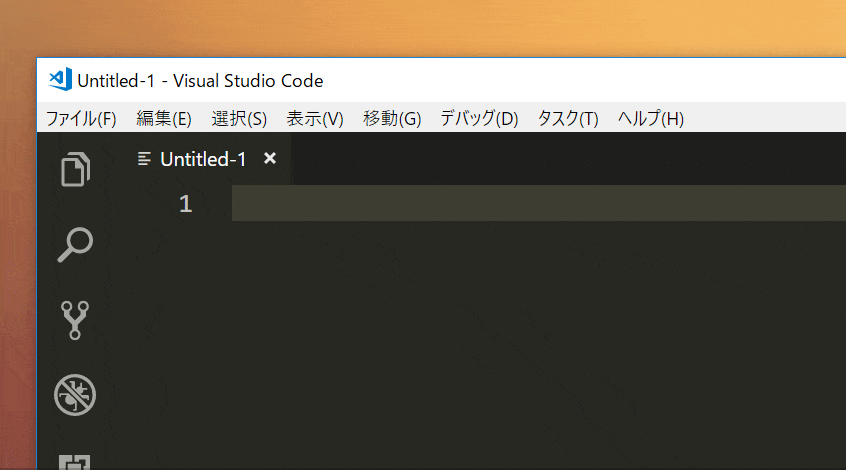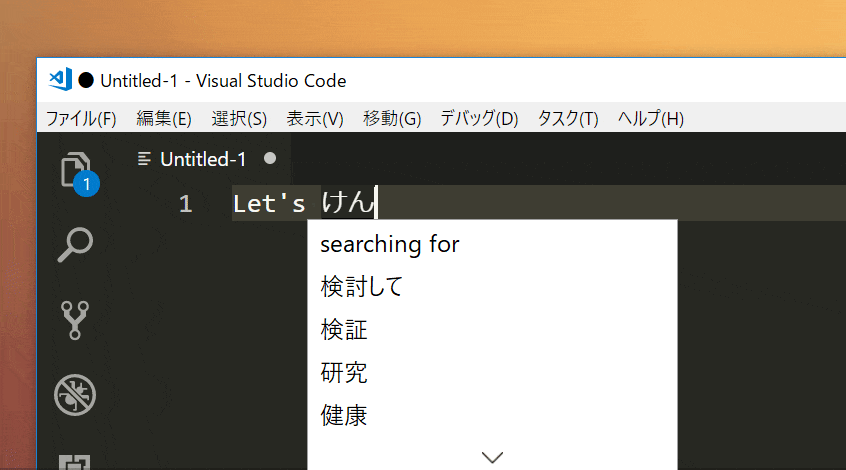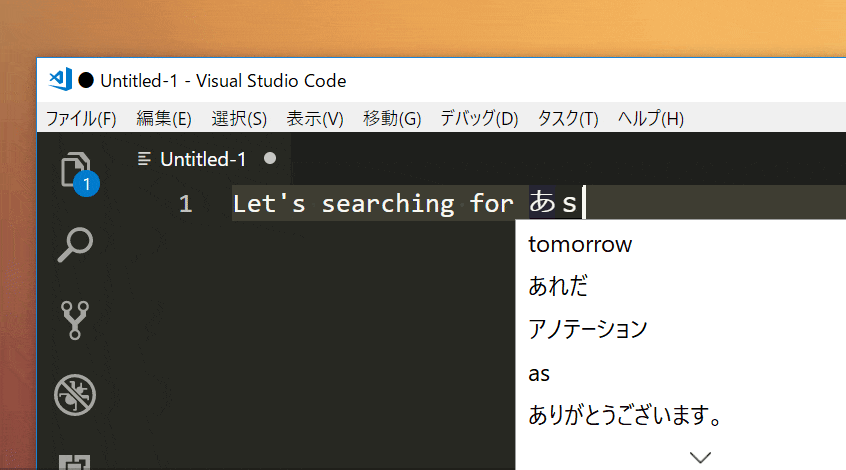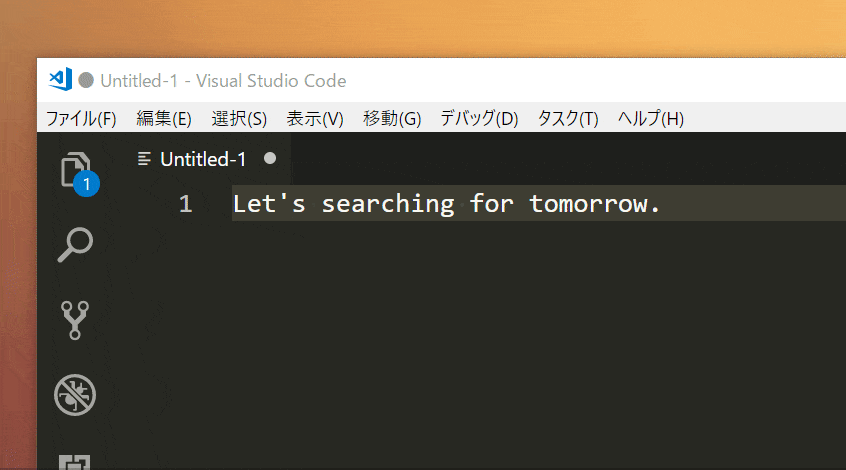
使い方
edict_for_MSIME.txt - Google ドライブから辞書データ(edict_for_MSIME.txt)をダウンロードする。
タスクバーのMicrosoft IMEを右クリックして、ユーザ辞書ツールを出す。
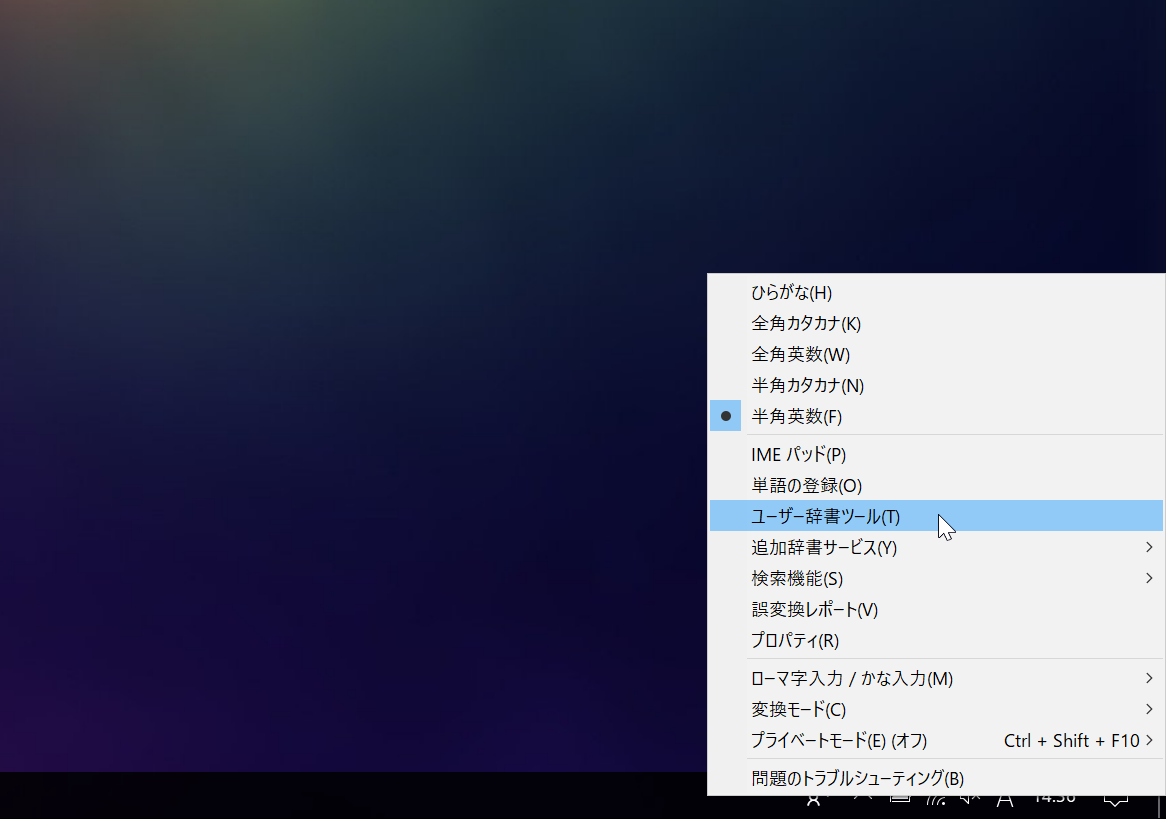
ユーザ辞書ツールの「ツール」タブから「テキストファイルからの登録」をクリック。edict_for_MSIME.txtを選択。
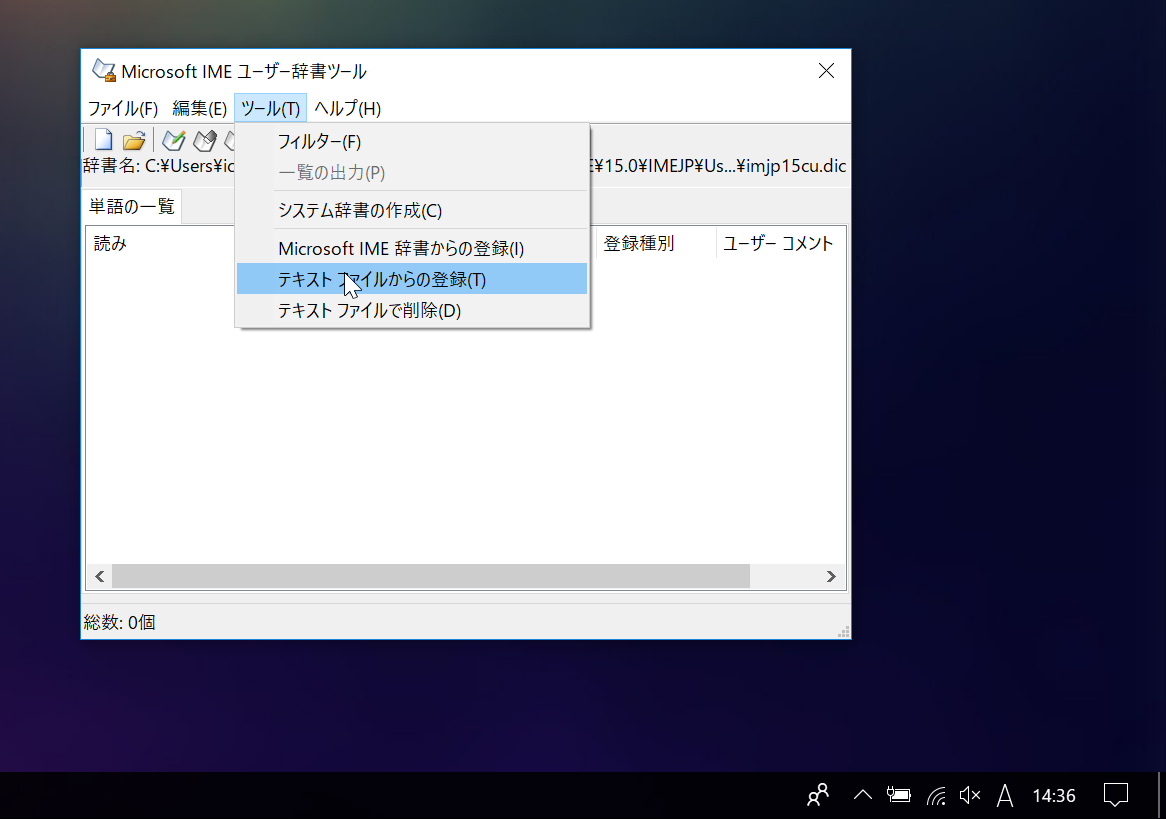
登録までに時間がかかります。289971単語登録できます。
登録中に他のソフトが不安定になるので執筆中や落ちちゃいけないソフトを動かしている人は注意!
辞書データの作成方法
EDICTといわれる公開されている和英辞書をMicrosoft IMEの形式に変更します。
EDICTはCreative Commons Attribution-ShareAlike License (V3.0)の元、利用可能です。
以上のサイトより、edict.zipを落としてedictファイル(内部はテキストファイル)を使います。
以下がedictをMicrosoft IMEの形式に変換するスクリプトです。
import codecs
import unicodedata
import jaconv
import re
from tqdm import tqdm
dic_path = "./edict"
output_path = "./edict_for_MSIME.txt"
def kana_from_edict_line(line):
yomi_text = re.search(r'\[(.*)\]', line)
if yomi_text:
return jaconv.kata2hira(yomi_text.group(1))
return False
def eng_words_from_edict_line(line):
words_text = re.search(r'\/(.*)\/', line)
if words_text:
words_list = words_text.group(0)[1:-1].split("/")
words = []
for word in words_list:
if word == "(P)": continue
m = re.search(r"(\s?\(.+\)\s?)*(?P<word>[^\(\)]+)(\s?\(.+\)\s?)*", word)
s = m.group('word').strip()
if len(s) == 0: continue
if len(s.split(" ")) >= 6: continue
words.append(s)
return words
return False
dictionary = {}
with codecs.open(dic_path, 'r', 'euc_jp') as dic_file:
print("loading...")
for line in tqdm(dic_file):
kana = kana_from_edict_line(line)
if not kana: continue
words = eng_words_from_edict_line(line)
if len(words) == 0: continue
if not kana in dictionary:
dictionary[kana] = set()
dictionary[kana].update(words)
word_count = 0
with codecs.open(output_path, 'w') as out_file:
print("creating...")
for (yomi, eng_list) in tqdm(dictionary.items()):
for eng in eng_list:
try:
out_file.write("%s\t%s\t%s\n" % (yomi, eng, "顔文字"))
word_count += 1
except: pass
print("%s (containing %d words) has been created!" % (output_path, word_count))
正規表現を久々に書いた。
Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
↑これを使うと簡単に正規表現のチェックができて便利だった。
その他
MS IMEに入れる辞書データにユーザコメントとして単語の意味とか表示すると使いやすくなると思う。
素直に文章の翻訳はGoogle翻訳を使ったほうが楽だけど、単語の入力は便利かもしれない。(?)
参考のまとめ
- 正規表現のチェックをするときにお世話になった → Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript
- ファイル読み書き file open read write | Python Snippets
- The EDICT Dictionary File
- ひらがな、カタカナ変換にお世話になった → jaconv · PyPI
- Python3での日本語変換モジュールの比較 - Qiita