この記事は何?
Pythonで書いたライブラリやコードがあったとします.これに与える変数を視覚的に変更しリアルタイムに結果を表示することが可能にします.アルゴリズムの勉強や実装の試行錯誤にとても効果的です.
イメージ: 教科書に載っているLCSを実装してテストしている様子
Notebook と Interact(ipywidgets)
主に機械学習周辺で非常に人気のあるJupyter NotebookはPythonの実行環境として便利です.この上で動くInteract(ipywidgets)というライブラリがあり,これを使うとスライダーやテキストボックスを表示して結果を描画できます.pyplotと組み合わせてグラフの操作を視覚的に行うためによく紹介されています.
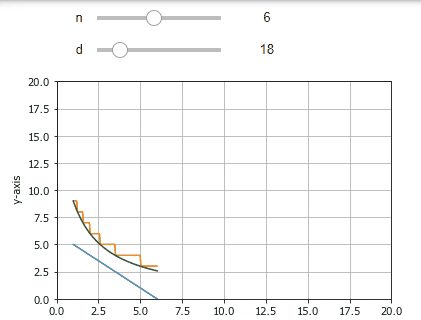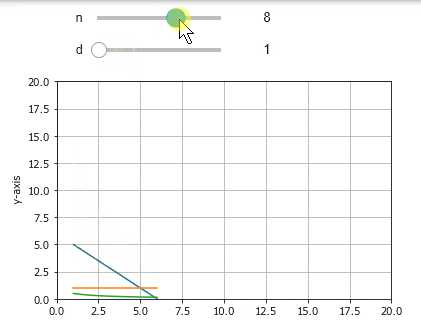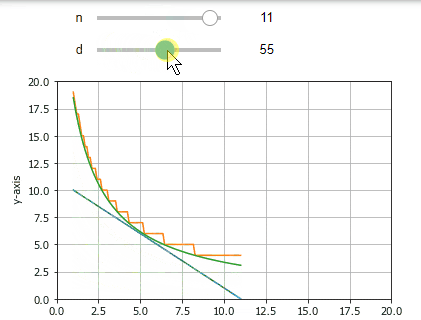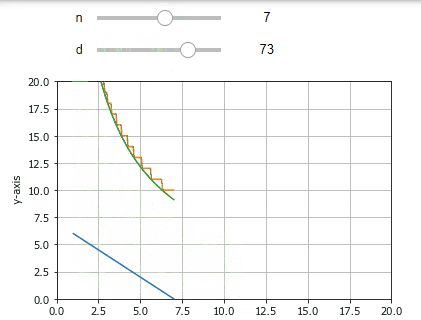
環境
以下ではAnaconda + Jypter Notebookを前提とします.
conda install -c conda-forge ipywidgets
が環境によっては必要です.
典型的なInteractの使い方
Interactの詳細の説明は他の記事に譲りますが,上のようなUIは以下のコードだけで実現できます.
%matplotlib inline
import matplotlib.pyplot as plt
from ipywidgets import interact
import numpy as np
def f(n, d):
x = np.linspace(1, n, num = 100)
y1 = [n] * 100
y2 = np.ceil(d / (x + 1) ) + (x)
y3 = d / (x + 1) + x
plt.plot(x, y1) # Blue
plt.plot(x, y2) # Green
plt.plot(x, y3) # Orange
plt.grid(True)
plt.show()
interact(f, n=(1, 20), d = (1,100))
$f()$は少し長く見えますがほぼグラフの描画のためです.最後の行のinteractでその関数に渡す$変数=(min,max)$を指定するだけでスライダーが表示されており,スライドするとグラフが再描画されます.
このように,Interactでは表示したい部分の関数をコントロールと一緒に呼び出すことで,その結果をリアルタイムに表示できます.
文字列のInteract
interactはウェジットで値が変更された際,第一引数の関数を呼びます.つまり,これはグラフでなくても構いません.
from ipywidgets import interact
def f(a):
print(a ** 2)
interact(f, a=(2, 20,2))
与えた変数aを二乗してprintするだけの関数$f()$ですが,上のコードを書くだけで以下のようなUIができます.

文字列を入力する
文字列を入力することもできます.このためには$interact.Text$でテキストボックスを用意します.
ここでは,sとtの一致しない文字数を表示してみます.時折,実行時にエラーが出ている様子が見えますがおかまいなしに実行できています.エラーの出ているコードのデバッグを行う際,IndexErrorなどで毎回停止しているのでは大変なので嬉しい動作です.

from ipywidgets import interact,Text
def solve(s, t):
print([s[i]==t[i]for i in range(len(s))].count(False))
input_s = Text(value="10", description="s:")
input_t = Text(value="10", description="t:")
interact(solve, s = input_s, t = input_t)
文字列を入力しパースする
上記では文字列を扱いましたが,適切に処理すれば数値入力として扱えます.
適切に処理と言っても難しいことではなく,競プロの一般的な処理と同じようにinputdat = Text(value="2 4 5 7 8", description="input")としてInteractで入力されたデータを,呼び出し先でdat = list(map(int, inputdat.split()))としているだけです.
以下は累積和のライブラリをテストしているイメージです.

与えた配列と閉区間$[l,r]$に対して,まず累積和の前処理(cs array)を表示して,最後にクエリ結果を表示しています.
ライブラリのチェック: エラトステネスのふるい(fromからtoまで)
これを使ってどんなことが出来るでしょうか?例えばfromからtoの閉区間の素数を列挙してlistで返す関prime_list_eratosthenes_fromを作ったとします.入力が0のとき,同じとき,開区間・閉区間が正しいか?などいろいろと値を試したくなります.次の通り,スムーズに確認できます.

Textの入力は文字列になるため,以下のようにラップする関数(例では$f()$)を作り,intに変換したり,例外の処理をしてあげるのと丁寧です.
def f(n_from, n_to):
try:
n_from, n_to = int(n_from), int(n_to)
print(prime_list_eratosthenes_from(n_from, n_to))
except:
pass
interact(f, n_from=Text(value="10"), n_to=Text(value="10"))
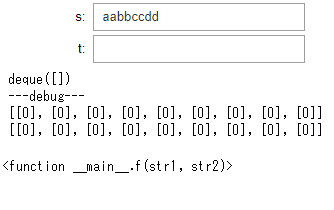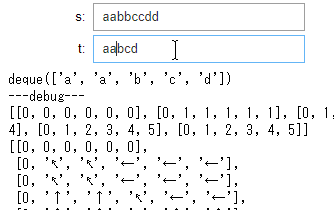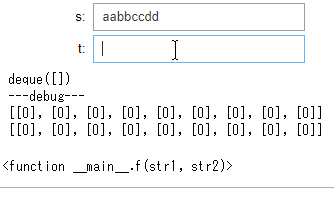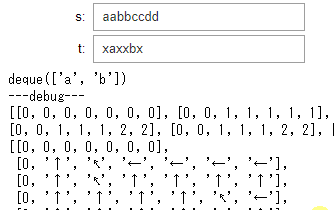
実例: LCSのテスト 最長共通部分列:Longest Common Subsequence
私がこの記事の内容を実際に活用した例です.
アルゴリズムイントロダクションを見ながらLCSを書いた際,長時間にわたってバグらせました.アルゴリズムの勉強をするときは時はいろいろと試行錯誤をしながらコードをデバッグしたくなるので非常に便利です.教科書通りに実装したので文中にある矢印を値として使ってdpしています.
サンプルコード:LCSのテスト
実例 RMQのテスト Range Min Query
セグメントツリーの例です.コンテスト中にモノイドを乗せ換えたりするときはテストケースを厳密に書くのではなく,まずあたりを付けたいことが多く,そのように際にも有用です.
コードRMQ

おまけ:アニメーション
競プロだと使いどころがあるのか怪しいのですが,スライダーを自動に動かす機能もあります.以下のサンプルはlとrを自動で動かしてその区間の素数を表示するというものです.スライダーを動かしてもテキストボックスを編集しても変更が反映されていることが分かります.

(一部抜粋)
play_b = Play(value=1, min=1, max=100, step=10, interval=300, )
slider_b = IntSlider(min=1, max=100)
input_b = Text(value="10", description="b:")
jslink((play_b, 'value'), (slider_b, 'value'))
jslink((play_b, 'value'), (input_b, 'value'))
ui = HBox([play_a, slider_a, play_b, slider_b, input_b])
out = interactive_output(prime_list_eratosthenes_from, {'n_from': slider_a, 'n_to': slider_b})
display(ui, out)
まず,Play(プレイボタンのついているコントロール),スライダ,インプットボックスを作成します.次に,jslinkを使うと,各コントロールのvalueを同期させられます.そして,HBoxで横一列に並べ,それを,interactとして表示します.
まとめ
Notebook+Interact(ipywidgets)を使って視覚的に変数を変更でき,結果をリアルタイムにさせることが出来ました.アルゴリズムの勉強の際に試行錯誤するツールとして非常に有用です.また,デバッグメッセージも一緒に表示できるため,デバッグにも非常に役立ちます.
# サンプルコード集
# コード-エラトステネスのふるいでfromからtoの値の素数を列挙する
# thanks: https://qiita.com/studio_haneya/items/adbaa01b637e7e699e75
%matplotlib inline
from ipywidgets import Text,interact
def prime_list_eratosthenes(n):
import math
if n == 1:
return []
if n == 2:
return [2]
prime = [2]
limit = math.sqrt(n)
data = [i + 1 for i in range(2, n, 2)]
while True:
p = data[0]
if limit < p:
return prime + data
prime.append(p)
data = [e for e in data if e % p != 0]
def prime_list_eratosthenes_from(n_from, n_to):
from bisect import bisect_left
data = prime_list_eratosthenes(n_to)
i = bisect_left(data, n_from)
return(data[i:])
def f(n_from, n_to):
try:
n_from, n_to = int(n_from), int(n_to)
print(prime_list_eratosthenes_from(n_from, n_to))
except:
pass
interact(f, n_from=Text(value="10"), n_to=Text(value="10"))
コード-累積和
from ipywidgets import interact, Text
import itertools
# 使い方: cssum(0, 2, [0,1,2,3])で[0,2)の区間の累積和
def cssum(l, r, dat): #
sdat = list(itertools.accumulate(itertools.chain([0], dat)))
print("input = [{0}, {1}]".format(l,r))
print("cs array = {0}".format(sdat))
return sdat[r] - sdat[l]
# interactに渡す関数
def f(str1, str2, inputdat):
try:
dat = list(map(int, inputdat.split()))
l,r = int(str1), int(str2)
res = cssum(l, r+1, dat)
print("query [{0},{1}] = {2}".format(l,r+1, res))
except:
pass
inputdat = Text(value="2 4 5 7 8", description="input")
str1 = Text(value="1", description="l(close)")
str2 = Text(value="2", description="r(close)")
interact(f, str1 = str1, str2 = str2, inputdat=inputdat)
コード-LCS
%matplotlib inline
from ipywidgets import interact, Text
# アルゴリズムイントロダクション 15.4 LCS
# bを基にもともとのinput xから共通部分を抜き出す。
def lcs_decode(b, X, i, j):
import collections
res = collections.deque([])
while True:
#print("i={0}, j={1} b={2}".format(i,j,b[i][j]))
if i == 0 or j == 0:
break
if b[i][j] == '↖':
res.appendleft(X[i-1])
i -= 1
j -= 1
elif b[i][j] == "↑":
i -= 1
continue
else:
j -= 1
continue
return res
# 適当に実装したけどあってるはず
# lcsした結果から「一致しなかった部分」を取得する
def lcs_decode_negative(b, X, i, j):
import collections
res = collections.deque([])
while True:
#print("i={0}, j={1} b={2}".format(i,j,b[i][j]))
if i == 0 or j == 0:
break
if b[i][j] == '↖':
i -= 1
j -= 1
elif b[i][j] == "↑":
res.appendleft(X[i-1])
i -= 1
continue
else:
j -= 1
continue
if i != 0:
for i in range(1,i+1):
res.appendleft(X[i-1])
return res
def lcs_print_recurcive(b, X, i, j):
if i == 0 or j == 0:
return
if b[i][j] == '↖':
lcs_decode(b, X, i - 1, j - 1)
print(X[i-1])
elif b[i][j] == "↑":
lcs_decode(b, X, i - 1, j)
else:
lcs_decode(b, X, i, j - 1)
# アルゴリズムイントロダクション 15.4 LCS
# Longest Common Subsequenceをとり、以下を返す
# b: 結果
# c: そこまでのlongestのcount(内部用)
def lcs_length(x, y):
m, n = len(x), len(y)
b = [[0 for _ in range(n+1)] for _ in range(m+1)]
c = [[0 for _ in range(n+1)] for _ in range(m+1)]
for i in range(1, m+1):
for j in range(1, n+1):
if x[i-1] == y[j-1]:
c[i][j] = c[i-1][j-1] + 1
b[i][j] = '↖'
elif c[i-1][j] >= c[i][j-1]:
c[i][j] = c[i-1][j]
b[i][j] = "↑"
else:
c[i][j] = c[i][j - 1]
b[i][j] = "←"
return c, b
from pprint import pprint
def f(str1, str2):
c, b = lcs_length(str1, str2)
print(lcs_decode(b, str1, len(str1), len(str2)))
print("---debug---")
print(c)
pprint(b)
str1 = Text(value="10", description="s:")
str2 = Text(value="10", description="t:")
interact(f, str1 = str1, str2 = str2)
コードRMQ
from ipywidgets import interact, Text
class segmentTreeMin():
# とりあえず9 * 12桁
inf = 2**31 - 1
dat = []
lenTreeList = -1
depthTreeList = 0
def __init__(self):
pass
def load(self, l):
# len(l)個よりも大きい2の二乗を得る
self.lenTreeList = 2 ** (len(l) - 1).bit_length() # len 5 なら 2^3 = 8
self.depthTreeList = (len(l) - 1).bit_length() # 木の段数(0 origin)
self.dat = [self.inf] * (self.lenTreeList * 2)
# 値のロード
for i in range(len(l)):
self.dat[self.lenTreeList - 1 + i] = l[i]
self.build()
def build(self):
for i in range(self.lenTreeList - 2, -1, -1):
self.dat[i] = min(self.dat[2 * i + 1], self.dat[2 * i + 2])
def setValue(self, i, a):
"""
set a to list[i]
"""
#print("setValue: {0}, {1}".format(i, a))
nodeId = (self.lenTreeList - 1) + i
#print(" first nodeId: {0}".format(nodeId))
self.dat[nodeId] = a
while nodeId != 0:
nodeId = (nodeId - 1) // 2
#print(" next nodeId: {0}".format(nodeId))
self.dat[nodeId] = min(self.dat[nodeId * 2 + 1], self.dat[nodeId * 2 + 2])
def querySub(self, a, b, nodeId, l, r):
"""
[a,b) 区間の親クエリに対するノードnodeへ[l, r)の探索をデリゲート
区間については、dataの添え字は0,1,2,3,4としたときに、
[0,3)なら0,1,2の結果を返す
"""
#print("querySub: a={0}, b={1}, nodeId={2}, l={3}, r={4}".format(a, b, nodeId, l, r))
if (r <= a or b <= l):
return self.inf
if a <= l and r <= b:
#print(" > return(have): {0}".format(self.dat[nodeId]))
return self.dat[nodeId]
resLeft = self.querySub(a, b, 2 * nodeId + 1, l, (l + r) // 2)
resRight = self.querySub(a, b, 2 * nodeId + 2, (l + r) // 2, r)
#print(" > return(lr): {0}".format(min(resLeft, resRight)))
return min(resLeft, resRight)
def query(self, a, b):
return self.querySub(a, b, 0, 0, self.lenTreeList)
def findLeftSub(self, x, a, b, nodeId, l, r):
"""
[a,b) 区間の中からx【以下となる】最も左のindexを返す
これは、nodeIdではなくて、元のlistのindexである
"""
if (r <= a or b <= l): # 範囲外の時 Noneを返す
return None
if self.dat[nodeId] > x: # このノードの最小がx出ないときはこのノードにxは含まれないのでNoneを返す
return None
if nodeId >= self.lenTreeList - 1: # nodeIfがノードのときは
# (nodeIndex, 値) を返す
print("hit: x={0} nodeId={1}".format(x, nodeId))
return (nodeId - self.lenTreeList + 1, self.dat[nodeId])
print("find more L: x={0} nodeId={1}".format(x, nodeId))
# それ以外の時は子を掘る必要があり、左から掘る
resLeft = self.findLeftSub(x, a, b, 2 * nodeId + 1, l, (l + r) // 2)
# 左から値が帰ってくるときは最左を返したいわけであるからその値を返す
if resLeft is not None:
return resLeft
# 左からNoneが帰ってきた場合は右側を掘る
print("find more R: x={0} nodeId={1}".format(x, nodeId))
resRight = self.findLeftSub(x, a, b, 2 * nodeId + 2, (l + r) // 2, r)
return resRight
def findLeft(self, x):
return self.findLeftSub(x, 0, self.lenTreeList, 0, 0, self.lenTreeList)
def findLeftRange(self, x, a, b):
return self.findLeftSub(x, a, b, 0, 0, self.lenTreeList)
def f(str1, str2, inputdat):
try:
st = segmentTreeMin()
l = list(map(int, inputdat.split()))
print("RMQ test")
print("inputdat = {0}".format(l))
st.load(l)
l,r = int(str1), int(str2)
print("query [{0},{1}) = {2}".format(l,r, st.query(l,r)))
except:
pass
inputdat = Text(value="2 4 5 7 8", description="input")
str1 = Text(value="1", description="l(close)")
str2 = Text(value="2", description="r(open )")
interact(f, str1 = str1, str2 = str2, inputdat=inputdat)
コード-アニメーション
# thanks: https://qiita.com/studio_haneya/items/adbaa01b637e7e699e75
%matplotlib inline
from ipywidgets import interact,Text
from ipywidgets import Play, IntSlider, jslink, HBox, interactive_output
def prime_list_eratosthenes(n):
import math
if n == 1:
return []
if n == 2:
return [2]
prime = [2]
limit = math.sqrt(n)
data = [i + 1 for i in range(2, n, 2)]
while True:
p = data[0]
if limit < p:
return prime + data
prime.append(p)
data = [e for e in data if e % p != 0]
def prime_list_eratosthenes_from(n_from, n_to):
from bisect import bisect_left
data = prime_list_eratosthenes(n_to)
i = bisect_left(data, n_from)
print(data[i:])
play_a = Play(value=1, min=0, max=100, step=5, interval=300, )
slider_a = IntSlider(min=0, max=100)
jslink((play_a, 'value'), (slider_a, 'value'))
play_b = Play(value=1, min=1, max=100, step=10, interval=300, )
slider_b = IntSlider(min=1, max=100)
input_b = Text(value="10", description="b:")
jslink((play_b, 'value'), (slider_b, 'value'))
jslink((play_b, 'value'), (input_b, 'value'))
ui = HBox([play_a, slider_a, play_b, slider_b, input_b])
out = interactive_output(prime_list_eratosthenes_from, {'n_from': slider_a, 'n_to': slider_b})
display(ui, out)