Pythonのハッシュ衝突攻撃の考察で(競技プログラミング文脈で)Pythonでは辞書(dict)を衝突させるような入力を作ることは困難といいました、が嘘でした。衝突させられます。
※以下では簡単のため入力される値を$10^9$以下とし、辞書に$2^{16}個以上のデータが存在するものとします
(追記): 16ヶ月以上前に記事になっていました。Anti-hash-table test in Python。でも、せっかく書いたのでpublishします。
サマリ
以下のように競技プログラミングとして一般的な入力の範囲($10^{9}$の値のキーを$2 * 10^{5}$個程度)で辞書のキーを衝突させられます。dict, defaultdictだけでなくcollections.Counterにも対して成立します。
- Pythonの辞書はあるkeyのvalueを格納できる。各アクセス時、keyをもとに空いているindexを探し、keyを入れる場所を決める。indexが既に利用されている場合、keyと衝突したindexをもとに疑似乱数を生成して次のindex候補を探す。この疑似乱数は最初のkeyが定まれば毎回同じ遷移を行う。つまり、遷移は特定できる。
- 最初にある値xを攻撃の対象とし、その値の
最初のindexを除く遷移のindexをN個計算して辞書に入れておく。(補足:N=43000程度が良い?Nが大きすぎるとpypyではうまくいかない。おそらくdk_sizeが変わる?) - 次にxの最初のindexとなる
xではないkeyを辞書に入れておく - この準備の後、ある値xに対するアクセス(追加・更新・削除全て)に$N+1$回のindex計算が必要になる。
実例
Codeforces Round 886 (Div. 4)-Gでは多くのPythonのコードがHackされました。Hackされるようなコードの例はこれ(Submission214886952)で、Hackに用いられたコードの例はこれ(Hack #931470 by riroan)です。
体験する
MojaCoderに問題を投稿しました。defaultdictやcollections.Counterで解こうとするとおそらく落ちます。
振り返り
前の記事でPythonの辞書は疑似乱数を使ったindexを用いて実装されていることを述べました。あるkeyにアクセスする際、indexは次のように計算されます。
const size_t mask = DK_MASK(keys); /* 今のハッシュサイズ相当のマスク (例えばint32) */
size_t i = hash & mask; /* hashは最初オリジナルindex*/
Py_ssize_t ix = dictkeys_get_index(keys, i); /* 一発目の検索。これで空きが見つかれば以下のforは回らない*/
/* perturb = 疑似乱数 = index候補 */
for (size_t perturb = hash; ix >= 0;) { /* dictkeys_get_indexが0 = 空きがあたるまで検索 */
perturb >>= PERTURB_SHIFT; // PERTURB_SHIFT = 5 でstaticです
i = (i*5 + perturb + 1) & mask;
ix = dictkeys_get_index(keys, i);
}
key $x$にvalue $val$を格納したいとします。
- ind=xとし、maskでANDをとります。また、perturb=xとします。
- indがすでに使われている場合、以下の処理を行います。
- perturb >> 5(数回回るとperturbは0になります)
- ind = (ind*5 + perturb + 1) & mask
- indが未使用ならぬけます。そうでなければこのループを繰り返す。
- indは未使用のアドレスです。indにkey=$x$というラベルを貼った上でvalue=$val$を格納します。
このロジックはランダムな入力に対してうまく疑似乱数を作り出し、少ない衝突回数で空いているindを見つけることができます。[1, 100, 6, 131073]のkeyのdictに適当な値を入れたいとしたときの様子を図示します。

- 1はind = 1で未使用です。ind=1にkey=1として値を格納します
- 100, 6も同様に格納されます。(ind=100,6)
- 131073$(=2^{17}+1)$はmaskされてind=1になります。しかしind=1はkey=1で使用されています。
- 衝突したので次の候補となるind=
(1 * 5 + (131073>>5) + 1) & (2**16-1) = 131073を計算しind=4102。ind=4102は空なのでkey=131073。
衝突させる入力を作る
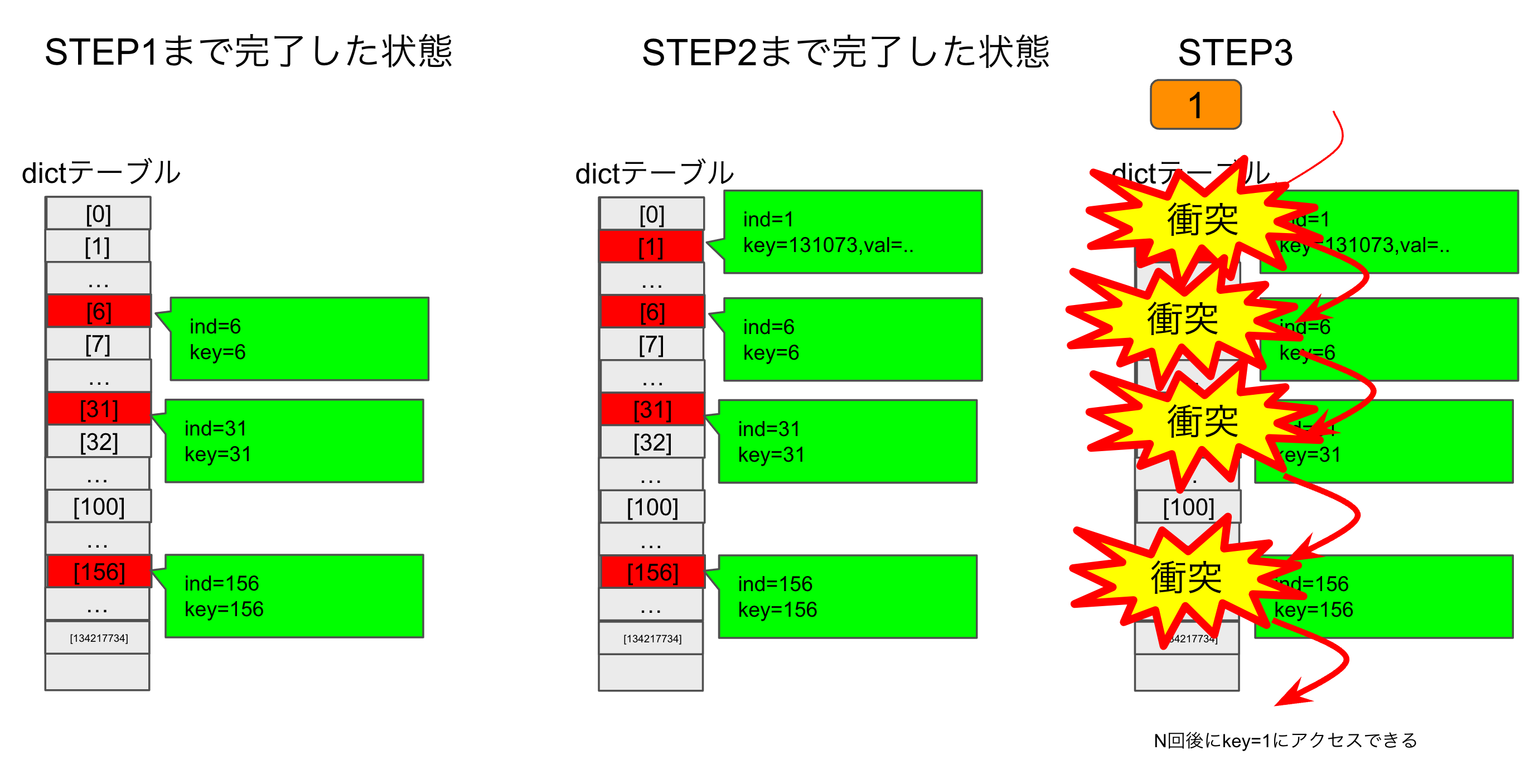
ここでは、衝突させたい対象をkey=1とします。
hackケースを生成する立場となった場合、$N=2e5$個くらいの辞書アクセスが可能であれば、例えばSTEP1を$N=43000$個, STEP2は1個, STEP3を残り(=156999個)用意した入力を用意する・。
STEP1: key=1がind=1で衝突した後の疑似乱数の遷移を用意する
- key=1を格納しようとした際、ind=1が使われていないのであればind=1にkey=1とvalを格納します。
- ind=1で衝突が起こった時に次に試行するアドレスは以下のように簡単に計算できます。
(1 * 5 + (1>>5) + 1) & (2 * * 16-1) = 6
- ind=6も使われていた場合のindexも同様に計算できます。
(6 * 5 + (1>>5>>5) + 1) & (2 * * 16-1) = 31
- key=1で衝突が発生した時の値は次のように計算できます。
mask = 2**16-1
k = 1
perturb = k
ind = k & mask
inds = []
for _ in range(10):
perturb >>= 5
ind = (ind * 5 + perturb + 1) & mask
inds.append(ind)
print(inds)
# [6, 31, 156, 781, 3906, 19531, 32120, 29529, 16574, 17335]
key=1で衝突が発生した際の値を$N$個計算計算できます。これらを全て先にdictに入れておくと、そのindを使用中になります。うまく、key=1のアクセスで衝突を発生させられれば毎回のアクセス(追加・更新・削除)で$N$回のind計算をさせることができます。(補足:N=43000程度が良い?Nが大きすぎるとpypyではうまくいかない。おそらくdk_sizeが変わる?)
STEP2: ind=1となるkey=1以外の値を入れる
STEP1ではkey=1の最初の試行であるind=1の衝突が発生した一つ後からのindを辞書に入れました。key=1で衝突させるためにはind=1にkey=1以外が格納させていなければなりません。もし、ind=1にkey=1が格納されていれば、key=1のアクセスは最初の1回目の探索で終了してしまいます。
コードをじっと眺めるとind=1となるkey=1以外の値は簡単に見つかります。key = $1 + (2^{16}よりも上のビットだけが立っている数)$の値は(16ビットでマスクされるので/これほんと?15かもしれない?)ind=1となります。先ほどの図では$1 + 2^{17} = 131073$がこれにあたります。
STEP3: 残りは1を積む
STEP1,2で適切な数のkeyとして積み込んだ後、1を積み込みます。
STEP1,2後の辞書に対するkey=1のアクセスは全て$N$回のind計算が必要になります。なぜなら、
- key=1より、ind=1を候補にします。ind=1にはすでにデータが格納されていますが、key=131073なので次のindを計算します。
- ind=6を候補にします。ところがkey=6であるため次のindを計算します。
- 以降、STEP1で計算して辞書に格納済みの$N$個のind=
6, 31, 156, 781, 3906, 19531, 32120, 29529, 16574, 17335...を候補にしますが全てkeyは1でないため、$N+1$回試行されます。 - N+2回目でようやく未使用のindが見つかるのでkey=1として値を格納します。
これらの検索は追加・更新・削除全てにおいて行われます。
これらを図に示したのが以下です。
このhackケースを防ぐにはどうすればいいですか?
どうすればいいんでしょう...
検証コード
import time
# [1, 2, 3, ...N, 1, 2, 3, ...N]というリストを作る
n = 200000
start = time.time()
listSeq = list(range(n//2))
d = dict()
for x in listSeq: d[x] = True
print("listSeq elapsed_time:{0}".format(time.time() - start) + "[sec]") # listSeq elapsed_time:0.0070133209228515625[sec]
# [2^17+1(=1), 6,31, 156]というリストを作る
d = dict()
start = time.time()
listCollision = []
mask = (1<<17) - 1 # 0xffff
listCollision.append(mask+2) # ind = 1
ind = 6 # ind = 6->31->156...
print(listCollision)
for i in range(1,43000): # key=1と衝突するキーで埋める。この値が大きすぎると環境により(pypy?)うまくぶつからない。おそらくdk_sizeが変わってしまうのか?
listCollision.append(ind)
ind = (ind * 5 + 1) & mask
print(min(listCollision), max(listCollision)) # -> 5 131073
for i in range(1, n-len(listCollision)): # 1で埋める。(各アクセスは上記で入れたkeyとぶつかる)
listCollision.append(1)
print("listColision", listCollision[:10]) # listColision [131073, 6, 31, 156, 781, 3906, 19531, 97656, 95065, 82110]
for x in listCollision: d[x] = True
print("listCollision elapsed_time:{0}".format(time.time() - start) + "[sec]") # listCollision elapsed_time:16.341837167739868[sec]
"""
/usr/bin/python3 /Users/kanai/git/PythonJunkTest/atcoder/lib/zzz3.py
listSeq elapsed_time:0.006514072418212891[sec]
[65537]
2 65537
listColision [65537, 6, 31, 156, 781, 3906, 19531, 32120, 29529, 16574]
listCollision elapsed_time:16.276437997817993[sec]
"""