前置き
O'Reilly Japan の「PythonとJavaScriptではじめるデータビジュアライゼーション」を参考に、勉強をしています。
今回は、Scrapyを使ってWebページのクローリング、スクレイピングを実施します。
Scrapyとは
Scrapyは、スクレイピングとクローリングに有用な機能を持つアプリケーションフレームワークです。
データマイニング, 情報処理, アーカイブなどの幅広い用途に活用することができます。
Scrapyのインストール
以下のコマンドでScrapyをインストールします。
pip install scrapy
Scapyプロジェクトの作成
新しいプロジェクトを作成します。
(フォルダが作成されるので、適切なディレクトリに移動してから実行)
$ scrapy startproject akutagawa_prize
New Scrapy project 'akutagawa_prize', using template directory '/Users/Amatsuka/.pyenv/versions/3.6.1/lib/python3.6/site-packages/scrapy/templates/project', created in:
/Users/Amatsuka/dev/Python/project/akutagawa_prize
You can start your first spider with:
cd akutagawa_prize
scrapy genspider example example.com
作成されたプロジェクトのディレクトリツリーは、下記のようになっています。
$ tree
.
└── akutagawa_prize
├── akutagawa_prize
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
Scapyシェル
Scrapyはコマンドラインシェルを提供しています。URLからレスポンスコンテキストを作成し、そのコンテキスト内でxpath対象の取得を試しつつ、スクレイピングを進めることができます。
URLからレスポンスコンテキストを作成
日本文学振興会の「芥川賞受賞者一覧」ページのURLからレスポンスコンテキストを作成します。
$ scrapy shell http://www.bunshun.co.jp/shinkoukai/award/akutagawa/list.html
2017-10-07 16:28:53 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: akutagawa_prize)
2017-10-07 16:28:53 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'akutagawa_prize', 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'LOGSTATS_INTERVAL': 0, 'NEWSPIDER_MODULE': 'akutagawa_prize.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['akutagawa_prize.spiders']}
2017-10-07 16:28:53 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage']
2017-10-07 16:28:53 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-10-07 16:28:53 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-10-07 16:28:53 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-10-07 16:28:53 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6024
2017-10-07 16:28:53 [scrapy.core.engine] INFO: Spider opened
2017-10-07 16:28:53 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.bunshun.co.jp/robots.txt> (referer: None)
2017-10-07 16:28:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.bunshun.co.jp/shinkoukai/award/akutagawa/list.html> (referer: None)
2017-10-07 16:28:54 [traitlets] DEBUG: Using default logger
2017-10-07 16:28:54 [traitlets] DEBUG: Using default logger
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x102eac320>
[s] item {}
[s] request <GET http://www.bunshun.co.jp/shinkoukai/award/akutagawa/list.html>
[s] response <200 http://www.bunshun.co.jp/shinkoukai/award/akutagawa/list.html>
[s] settings <scrapy.settings.Settings object at 0x103c8fac8>
[s] spider <DefaultSpider 'default' at 0x103f326a0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
公式ドキュメントによると、IPythonがインストールされている場合、標準的なPythonコンソールの代わりにこちらが使用されるみたいです。
(コード補完やシンタックスハイライトが備わっているため、IPythonでの利用が推奨されています)
XPathでの対象指定
Scrapyのxpathクエリを使って、該当ページの全ての<h2>ヘッダを取得してみます。
ChromeのElementsタブを使って、ソースの上にマウスポインタを乗せて右クリックすると[Copy XPath]を選択できるので、xpath取得時などはこの機能を活用した方が楽かと思います。
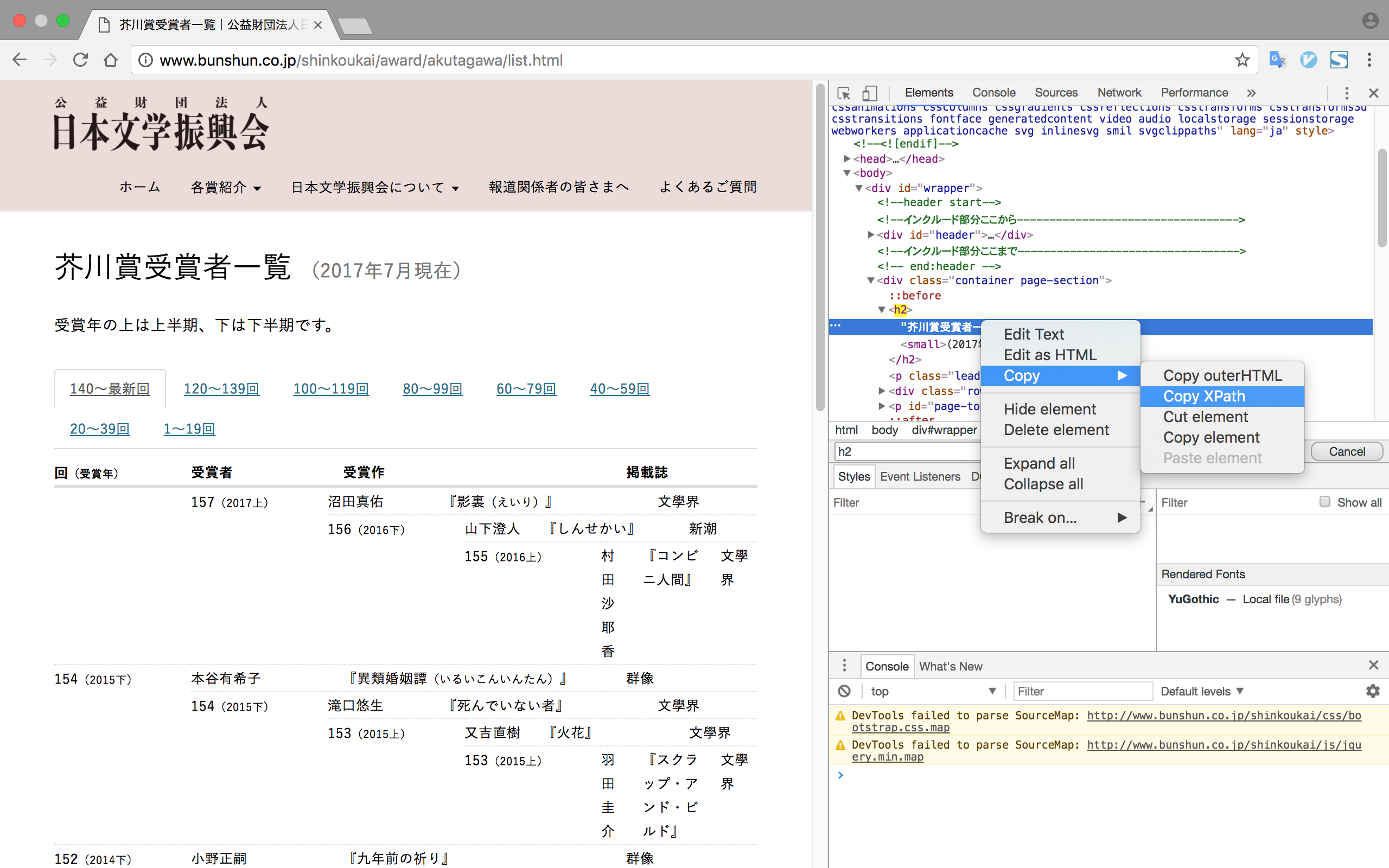
'''
該当ページの全ての<h2>ヘッダを取得する。
(h2sは、PythonのlistオブジェクトのSelectorListで取得される)
'''
In [1]: h2s = response.xpath('//h2')
In [2]: len(h2s)
Out[2]: 1
In [3]: h2s
Out[3]: [<Selector xpath='//h2' data='<h2>芥川賞受賞者一覧 <small>(2017年7月現在)</small><'>]
extractで生データを抽出
extractメソッドを使うことで、xpathセレクタの生の結果を取得することができます。
In [5]: h2s.extract()
Out[5]: ['<h2>芥川賞受賞者一覧 <small>(2017年7月現在)</small></h2>']
なお、xpathにtext()と指定することで、本文データを抽出することができます。
In [6]: h2s.xpath('text()').extract()
Out[6]: ['芥川賞受賞者一覧 ']
試しに140回以降のデータを抽出
「140〜最新」タブのデータを取得。
In [7]: content = response.xpath('//*[@id="myTabContent"]')
In [8]: no8 = content.xpath('div[@id="no8"]')
取得したデータから、「受賞者」列を抽出。
In [12]: no8.xpath('dl/*/span[@class="name"]/text()').extract()
Out[12]:
['受賞者',
'沼田真佑',
'山下澄人',
'村田沙耶香',
'本谷有希子',
'滝口悠生',
...
同様に、取得したデータから、「受賞作」列を抽出。
In [14]: no8.xpath('dl/*/span[@class="title"]/text()').extract()
Out[14]:
['影裏',
'しんせかい',
'コンビニ人間',
'異類婚姻譚',
'死んでいない者',
'火花',
...
受賞作はヘッダとデータ部のclass名が異なるため、受賞者と同様の方法では取得されませんでした。
スクレイピングの際は、DOMの構造により工夫する必要がありそうです。
In [15]: no8.xpath('dl/*/span[@class="title head"]/text()').extract()
Out[15]: ['受賞作']
Scapyスパイダー
Scapyスパイダーを作成して、WEBページのスクレイピングを行います。
Spiderクラス
SpiderクラスにWEBページをクロールして解析するための動作を定義します。
本クラスは、Scrapyプロジェクトのspidersディレクトリに配置します。
# -*- coding: utf-8 -*-
import scrapy
from akutagawa_prize.items import AkutagawaPrizeItem
# Scrapyスパイダー
class AkutagawaPrizeSpider(scrapy.Spider):
name = 'akutagawa_prize_list'
allowed_domains = ['www.bunshun.co.jp']
start_urls = ["http://www.bunshun.co.jp/shinkoukai/award/akutagawa/list.html"]
# HTTPレスポンスのパース
def parse(self, response):
contents = response.xpath('//*[@id="myTabContent"]')
tabIds = contents.xpath('div/@id').extract()
for tabId in tabIds:
# データ抽出
tab = contents.xpath('div[@id="' + tabId + '"]')
nos = remove_header(tab.xpath('dl/*/span[@class="no"]/text()').extract())
years = remove_header(tab.xpath('dl/*/span[@class="year"]/text()').extract())
names = remove_header(tab.xpath('dl/*/span[@class="name"]/text()').extract())
titles = tab.xpath('dl/*/span[@class="title"]/text()').extract()
magazines = remove_header(tab.xpath('dl/*/span[@class="magazine "]/text()').extract())
# 受賞者のない行を削除して行数を揃える
na_indexes = [i for i, val in enumerate(names) if val == "なし"]
remove_na_rows(nos, years, names, na_indexes)
# データのセット
for (_no, _year, _name, _title, _magazine) in zip(nos, years, names, titles, magazines):
yield AkutagawaPrizeItem(no=_no, year=_year, name=_name, title=_title, magazine=_magazine)
# リストのヘッダ行削除
def remove_header(items):
return items[1:]
# リストの指定行削除
def remove_na_rows(nos, years, names, indexes):
for i in sorted(indexes, reverse=True):
del nos[i], years[i], names[i]
Itemクラス
Itemクラスには、Spiderが抽出するデータの出力データフォーマットを定義します。
# -*- coding: utf-8 -*-
import scrapy
class AkutagawaPrizeItem(scrapy.Item):
no = scrapy.Field() # 開催数
year = scrapy.Field() # 受賞年
name = scrapy.Field() # 受賞者
title = scrapy.Field() # 受賞作
magazine = scrapy.Field() # 掲載誌
プロジェクト設定モジュール
Scrapyプロジェクトでは、プロジェクト用に作成された settings.py ファイルに、設定が記載されます。
デフォルトのsettings.pyのままで、日本語を含むページをクロールしてJSONファイルに出力した際、日本語の文字列が「\uXXXX」というUnicodeの文字列で出力されてしまいました。日本語で出力するためには、settings.pyに下記を追記します。
FEED_EXPORT_ENCODING='utf-8'
Scapyスパイダーの実行
利用できるスクレイピングスパイダーの確認
$ scrapy list
akutagawa_prize_list
crawlの実行
$ scrapy crawl akutagawa_prize_list -o akutagawa_prize_list.json
2017-10-08 00:11:58 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: akutagawa_prize)
2017-10-08 00:11:58 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'akutagawa_prize', 'FEED_FORMAT': 'json', 'FEED_URI': 'akutagawa_prize_list.json', 'NEWSPIDER_MODULE': 'akutagawa_prize.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['akutagawa_prize.spiders']}
2017-10-08 00:11:58 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.feedexport.FeedExporter',
'scrapy.extensions.logstats.LogStats']
2017-10-08 00:11:58 [scrapy.middleware] INFO: Enabled downloader middlewares:
...
出力されたJSONファイルの確認
[
{
"magazine": "文學界",
"name": "沼田真佑",
"no": "157",
"title": "影裏",
"year": "2017上"
},
{
"magazine": "新潮",
"name": "山下澄人",
"no": "156",
"title": "しんせかい",
"year": "2016下"
},
{
"magazine": "文學界",
"name": "村田沙耶香",
"no": "155",
"title": "コンビニ人間",
"year": "2016上"
},
...
Scapyスパイダーにより、対象Webページから目的のデータを取得することができました。
今回紹介できていませんが、Scrapyは有用な機能が多く、色々なことに応用できそうです。
参考
Scrapy 1.4 documentation
https://doc.scrapy.org/en/latest/index.html